Antimuster „Ausgelastete Datenbank“
Das Auslagern der Verarbeitung an einen Datenbankserver kann dazu führen, dass dieser Server mehr mit der Ausführung von Code beschäftigt ist, anstatt auf Anforderungen zum Speichern und Abrufen von Daten zu reagieren.
Problembeschreibung
Viele Datenbanksysteme können Code ausführen. Hierzu gehören z.B. gespeicherte Prozeduren und Trigger. Häufig ist es effizienter, diese Verarbeitung in der Nähe der Daten auszuführen, als die Daten zur Verarbeitung an eine Clientanwendung zu übertragen. Eine übermäßige Verwendung dieser Features kann jedoch aus verschiedenen Gründen die Leistung beeinträchtigen:
- Der Datenbankserver wendet zu viel Zeit für die Verarbeitung auf, anstatt neue Clientanforderungen zu akzeptieren und Daten abzurufen.
- Eine Datenbank ist üblicherweise eine gemeinsam genutzte Ressource, daher kann sie in Zeiträumen intensiver Nutzung zu einem Engpass werden.
- Die Laufzeitkosten können übermäßig hoch sein, wenn die Abrechnung für den Datenspeicher auf Verbrauchseinheiten basiert. Dies gilt insbesondere für verwaltete Datenbankdienste. Azure SQL-Datenbank berechnet beispielsweise Datenbanktransaktionseinheiten (Database Transaction Units, DTUs).
- Datenbankkapazitäten lassen sich nicht endlos zentral hochskalieren, und die horizontale Skalierung einer Datenbank ist nicht gerade einfach. Daher kann es sinnvoller sein, die Verarbeitung an eine Computeressource auszulagern, z.B. eine VM oder eine App Service-App, die sich problemlos horizontal hochskalieren lässt.
Dieses Antimuster tritt üblicherweise aus folgenden Gründen auf:
- Die Datenbank wird als Dienst betrachtet, nicht als Repository. Eine Anwendung verwendet den Datenbankserver möglicherweise, um Daten zu formatieren (z.B. zum Konvertieren in XML), Zeichenfolgendaten zu ändern oder komplexe Berechnungen auszuführen.
- Entwickler versuchen, Abfragen zu schreiben, deren Ergebnisse den Benutzern direkt angezeigt werden können. Eine Abfrage kann beispielsweise Felder kombinieren oder Datums-, Uhrzeit- und Währungswerte entsprechend dem Gebietsschema formatieren.
- Entwickler versuchen, das Antimuster Irrelevante Abrufe zu korrigieren, indem sie Berechnungen in die Datenbank verschieben.
- Gespeicherte Prozeduren werden verwendet, um Geschäftslogik zu kapseln, möglicherweise, weil sie als einfacher zu verwalten und zu aktualisieren angesehen werden.
Das folgende Beispiel ruft die 20 Bestellungen mit dem höchsten Wert für ein bestimmtes Vertriebsgebiet ab und formatiert die Ergebnisse als XML. Es verwendet Transact-SQL-Funktionen, um die Daten zu analysieren und die Ergebnisse zu XML zu konvertieren. Das vollständige Beispiel finden Sie hier.
SELECT TOP 20
soh.[SalesOrderNumber] AS '@OrderNumber',
soh.[Status] AS '@Status',
soh.[ShipDate] AS '@ShipDate',
YEAR(soh.[OrderDate]) AS '@OrderDateYear',
MONTH(soh.[OrderDate]) AS '@OrderDateMonth',
soh.[DueDate] AS '@DueDate',
FORMAT(ROUND(soh.[SubTotal],2),'C')
AS '@SubTotal',
FORMAT(ROUND(soh.[TaxAmt],2),'C')
AS '@TaxAmt',
FORMAT(ROUND(soh.[TotalDue],2),'C')
AS '@TotalDue',
CASE WHEN soh.[TotalDue] > 5000 THEN 'Y' ELSE 'N' END
AS '@ReviewRequired',
(
SELECT
c.[AccountNumber] AS '@AccountNumber',
UPPER(LTRIM(RTRIM(REPLACE(
CONCAT( p.[Title], ' ', p.[FirstName], ' ', p.[MiddleName], ' ', p.[LastName], ' ', p.[Suffix]),
' ', ' ')))) AS '@FullName'
FROM [Sales].[Customer] c
INNER JOIN [Person].[Person] p
ON c.[PersonID] = p.[BusinessEntityID]
WHERE c.[CustomerID] = soh.[CustomerID]
FOR XML PATH ('Customer'), TYPE
),
(
SELECT
sod.[OrderQty] AS '@Quantity',
FORMAT(sod.[UnitPrice],'C')
AS '@UnitPrice',
FORMAT(ROUND(sod.[LineTotal],2),'C')
AS '@LineTotal',
sod.[ProductID] AS '@ProductId',
CASE WHEN (sod.[ProductID] >= 710) AND (sod.[ProductID] <= 720) AND (sod.[OrderQty] >= 5) THEN 'Y' ELSE 'N' END
AS '@InventoryCheckRequired'
FROM [Sales].[SalesOrderDetail] sod
WHERE sod.[SalesOrderID] = soh.[SalesOrderID]
ORDER BY sod.[SalesOrderDetailID]
FOR XML PATH ('LineItem'), TYPE, ROOT('OrderLineItems')
)
FROM [Sales].[SalesOrderHeader] soh
WHERE soh.[TerritoryId] = @TerritoryId
ORDER BY soh.[TotalDue] DESC
FOR XML PATH ('Order'), ROOT('Orders')
Dies ist zweifellos eine komplexe Abfrage. Wie wir später sehen werden, benötigt sie eine erhebliche Menge an Verarbeitungsressourcen auf dem Datenbankserver.
Beheben des Problems
Verschieben Sie Verarbeitungsvorgänge vom Datenbankserver auf andere Logikschichten. Idealerweise sollten Sie die Datenbank auf die Ausführung von Datenzugriffsvorgängen beschränken, sodass nur die Funktionalitäten verwendet werden, für die die Datenbank optimiert wurde – z.B. die Aggregation in einem Managementsystem für relationale Datenbanken (RDBMS).
Der oben stehende Transact-SQL-Code kann z.B. durch eine Anweisung ersetzt werden, die einfach die zu verarbeitenden Daten abruft.
SELECT
soh.[SalesOrderNumber] AS [OrderNumber],
soh.[Status] AS [Status],
soh.[OrderDate] AS [OrderDate],
soh.[DueDate] AS [DueDate],
soh.[ShipDate] AS [ShipDate],
soh.[SubTotal] AS [SubTotal],
soh.[TaxAmt] AS [TaxAmt],
soh.[TotalDue] AS [TotalDue],
c.[AccountNumber] AS [AccountNumber],
p.[Title] AS [CustomerTitle],
p.[FirstName] AS [CustomerFirstName],
p.[MiddleName] AS [CustomerMiddleName],
p.[LastName] AS [CustomerLastName],
p.[Suffix] AS [CustomerSuffix],
sod.[OrderQty] AS [Quantity],
sod.[UnitPrice] AS [UnitPrice],
sod.[LineTotal] AS [LineTotal],
sod.[ProductID] AS [ProductId]
FROM [Sales].[SalesOrderHeader] soh
INNER JOIN [Sales].[Customer] c ON soh.[CustomerID] = c.[CustomerID]
INNER JOIN [Person].[Person] p ON c.[PersonID] = p.[BusinessEntityID]
INNER JOIN [Sales].[SalesOrderDetail] sod ON soh.[SalesOrderID] = sod.[SalesOrderID]
WHERE soh.[TerritoryId] = @TerritoryId
AND soh.[SalesOrderId] IN (
SELECT TOP 20 SalesOrderId
FROM [Sales].[SalesOrderHeader] soh
WHERE soh.[TerritoryId] = @TerritoryId
ORDER BY soh.[TotalDue] DESC)
ORDER BY soh.[TotalDue] DESC, sod.[SalesOrderDetailID]
Die Anwendung verwendet dann die .NET Framework-System.Xml.Linq-APIs, um die Ergebnisse als XML zu formatieren.
// Create a new SqlCommand to run the Transact-SQL query
using (var command = new SqlCommand(...))
{
command.Parameters.AddWithValue("@TerritoryId", id);
// Run the query and create the initial XML document
using (var reader = await command.ExecuteReaderAsync())
{
var lastOrderNumber = string.Empty;
var doc = new XDocument();
var orders = new XElement("Orders");
doc.Add(orders);
XElement lineItems = null;
// Fetch each row in turn, format the results as XML, and add them to the XML document
while (await reader.ReadAsync())
{
var orderNumber = reader["OrderNumber"].ToString();
if (orderNumber != lastOrderNumber)
{
lastOrderNumber = orderNumber;
var order = new XElement("Order");
orders.Add(order);
var customer = new XElement("Customer");
lineItems = new XElement("OrderLineItems");
order.Add(customer, lineItems);
var orderDate = (DateTime)reader["OrderDate"];
var totalDue = (Decimal)reader["TotalDue"];
var reviewRequired = totalDue > 5000 ? 'Y' : 'N';
order.Add(
new XAttribute("OrderNumber", orderNumber),
new XAttribute("Status", reader["Status"]),
new XAttribute("ShipDate", reader["ShipDate"]),
... // More attributes, not shown.
var fullName = string.Join(" ",
reader["CustomerTitle"],
reader["CustomerFirstName"],
reader["CustomerMiddleName"],
reader["CustomerLastName"],
reader["CustomerSuffix"]
)
.Replace(" ", " ") //remove double spaces
.Trim()
.ToUpper();
customer.Add(
new XAttribute("AccountNumber", reader["AccountNumber"]),
new XAttribute("FullName", fullName));
}
var productId = (int)reader["ProductID"];
var quantity = (short)reader["Quantity"];
var inventoryCheckRequired = (productId >= 710 && productId <= 720 && quantity >= 5) ? 'Y' : 'N';
lineItems.Add(
new XElement("LineItem",
new XAttribute("Quantity", quantity),
new XAttribute("UnitPrice", ((Decimal)reader["UnitPrice"]).ToString("C")),
new XAttribute("LineTotal", RoundAndFormat(reader["LineTotal"])),
new XAttribute("ProductId", productId),
new XAttribute("InventoryCheckRequired", inventoryCheckRequired)
));
}
// Match the exact formatting of the XML returned from SQL
var xml = doc
.ToString(SaveOptions.DisableFormatting)
.Replace(" />", "/>");
}
}
Hinweis
Dieser Code ist einigermaßen komplex. In einer neuen Anwendung sollten Sie eher eine Serialisierungsbibliothek verwenden. Hier geht es jedoch darum, dass das Entwicklungsteam ein Refactoring für eine vorhandene Anwendung durchführt. Daher muss die Methode exakt das gleiche Format zurückgeben wie der ursprüngliche Code.
Überlegungen
Viele Datenbanksysteme sind in hohem Maß für bestimmte Arten der Datenverarbeitung optimiert, beispielsweise für die Berechnung von Aggregatwerten in großen Datasets. Lagern Sie diese Datenverarbeitungsarten nicht aus der Datenbank aus.
Verlagern Sie Verarbeitungsprozesse nicht, wenn in diesem Fall die Datenbank weitaus mehr Daten über das Netzwerk übertragen müsste. Weitere Informationen finden Sie unter Antimuster „Extraneous Fetching“ (Irrelevante Abrufe).
Wenn Sie die Verarbeitung auf eine Logikschicht verlagern, muss diese Schicht möglicherweise horizontal hochskaliert werden, um die zusätzliche Verarbeitung auszuführen.
Erkennen des Problems
Zu den Symptomen einer ausgelasteten Datenbank gehört ein unverhältnismäßiges Absinken der Durchsatzwerte und Antwortzeiten bei Vorgängen, die auf die Datenbank zugreifen.
Sie können die folgenden Schritte durchführen, um dieses Problem zu identifizieren:
Verwenden Sie die Leistungsüberwachung, um zu ermitteln, wie viel Zeit das Produktionssystem für die Ausführung von Datenbankaktivitäten aufwendet.
Untersuchen Sie die Vorgänge, die in diesen Zeiträumen von der Datenbank ausgeführt werden.
Wenn Sie den Verdacht hegen, dass bestimmte Vorgänge übermäßige Datenbankaktivitäten nach sich ziehen, führen Sie in einer kontrollierten Umgebung einen Auslastungstest durch. Jeder Test sollte eine Kombination der verdächtigen Vorgänge mit einer variablen Benutzerauslastung ausführen. Untersuchen Sie die Telemetriedaten der Auslastungstests, um herauszufinden, wie die Datenbank verwendet wird.
Wenn die Datenbankaktivität eine erhebliche Verarbeitungslast, aber wenig Datenverkehr zeigt, untersuchen Sie den Quellcode, um festzustellen, ob die Verarbeitung besser an anderer Stelle erfolgen sollte.
Wenn der Umfang der Datenbankaktivität gering ist oder die Antwortzeiten relativ kurz sind, ist eine ausgelastete Datenbank wahrscheinlich kein Leistungsproblem.
Beispieldiagnose
In den folgenden Abschnitten werden diese Schritte auf die zuvor beschriebene Beispielanwendung angewendet.
Überwachen des Umfangs der Datenbankaktivität
Das folgende Diagramm zeigt die Ergebnisse eines Auslastungstests, der für die Beispielanwendung mit einer Schrittauslastung von bis zu 50 gleichzeitigen Benutzern ausgeführt wurde. Der Umfang der Anforderungen erreicht schnell einen Maximalwert und bleibt auf diesem Niveau. Die durchschnittliche Antwortzeit dagegen steigt stetig. Für diese beiden Metriken wird eine logarithmische Skalierung verwendet.
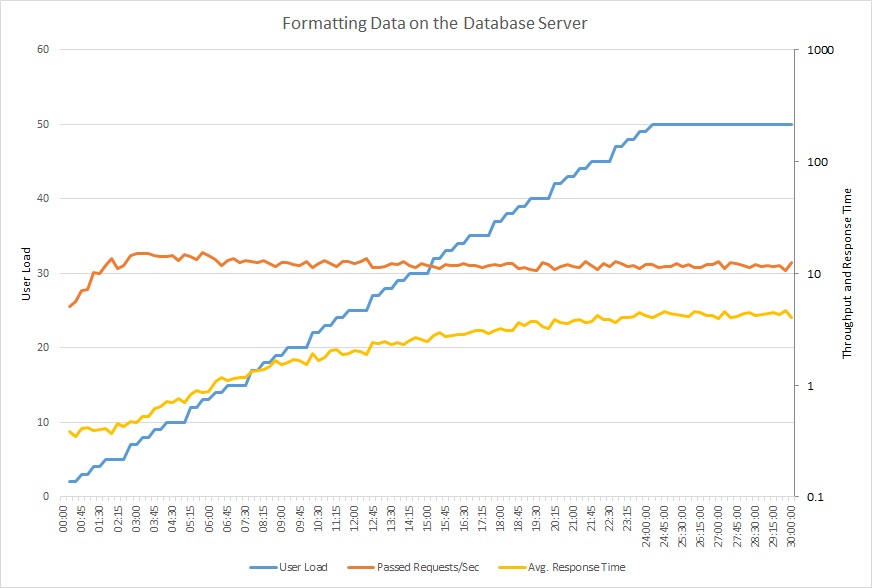
Dieses Liniendiagramm enthält die Benutzerauslastung, Anforderungen pro Sekunde und die durchschnittliche Antwortzeit. Das Diagramm zeigt, dass sich die Reaktionszeit erhöht, wenn die Auslastung zunimmt.
Das nächste Diagramm zeigt CPU-Auslastung und DTUs als Prozentsatz des Dienstkontingents. DTUs bieten ein Maß dafür, wie viel Verarbeitung die Datenbank leistet. Das Diagramm zeigt, dass sowohl die CPU- als auch die DTU-Auslastung schnell 100 % erreichten.
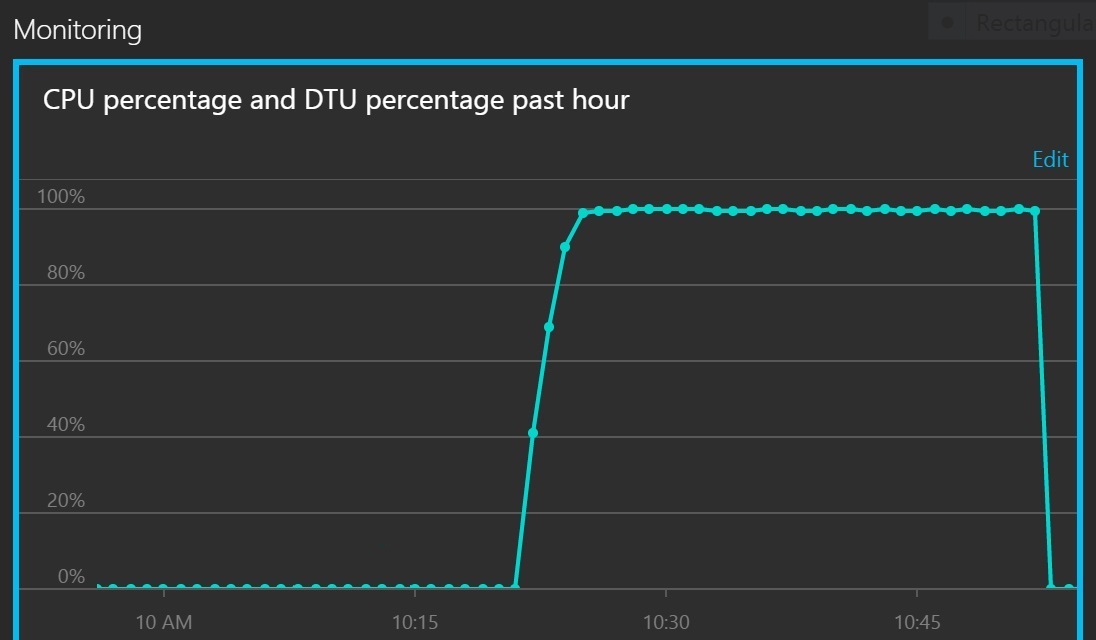
Dieses Liniendiagramm zeigt den CPU-Prozentsatz und den DTU-Prozentsatz im Zeitverlauf an. Das Diagramm zeigt, dass beide Werte schnell 100 Prozent erreichen.
Untersuchen der von der Datenbank ausgeführten Vorgänge
Bei den von der Datenbank ausgeführten Tasks kann es sich um echte Datenzugriffsvorgänge handeln, nicht um Verarbeitungstasks. Daher müssen Sie die SQL-Anweisungen verstehen, die ausgeführt werden, während die Datenbank beschäftigt ist. Überwachen Sie das System, um den SQL-Datenverkehr zu erfassen, und korrelieren Sie die SQL-Vorgänge mit Anwendungsanforderungen.
Wenn es sich bei den Datenbankvorgängen um reine Zugriffsvorgänge ohne große Verarbeitungslast handelt, kann das Problem durch irrelevante Abrufe verursacht werden.
Implementieren der Lösung und Überprüfen des Ergebnisses
Das folgende Diagramm zeigt einen Auslastungstest mit dem aktualisierten Code. Der Durchsatz ist erheblich höher: über 400 Anforderungen pro Sekunde im Vergleich zu 12 in der vorherigen Version. Die durchschnittliche Antwortzeit ist ebenfalls wesentlich niedriger: knapp über 0,1 Sekunden im Vergleich zu 4 Sekunden.
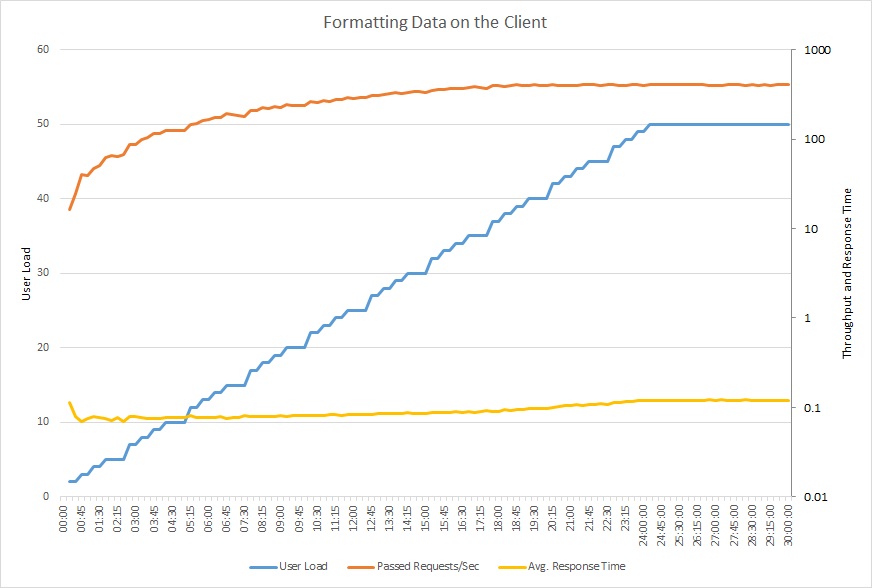
Dieses Liniendiagramm enthält die Benutzerauslastung, Anforderungen pro Sekunde und die durchschnittliche Antwortzeit. Das Diagramm zeigt, dass die Antwortzeit während des Auslastungstests einigermaßen konstant bleibt.
Die CPU- und DTU-Auslastung zeigt, dass es trotz erhöhten Durchsatzes länger gedauert hat, bis das System ausgelastet war.
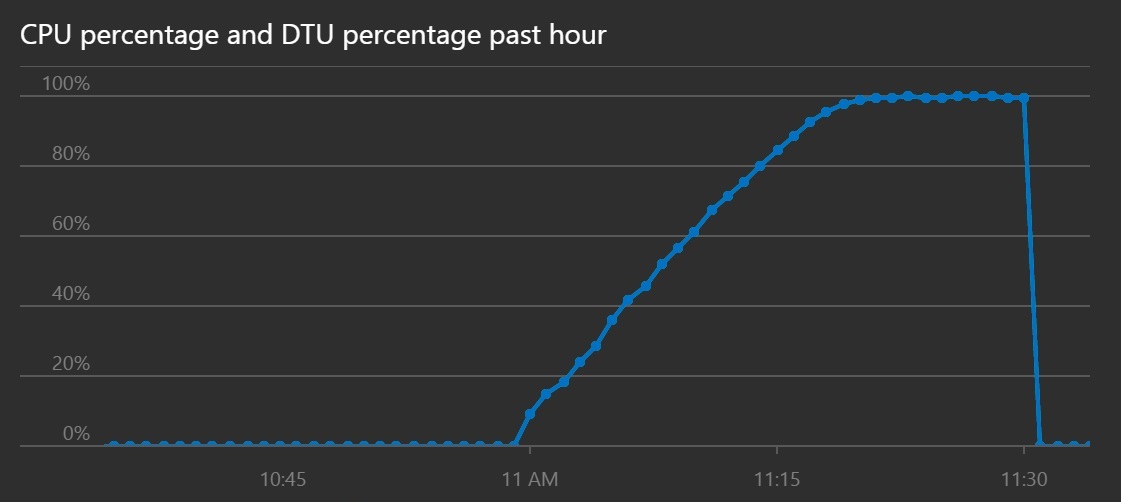
Dieses Liniendiagramm zeigt den CPU-Prozentsatz und den DTU-Prozentsatz im Zeitverlauf an. Im Diagramm wird gezeigt, dass es länger als zuvor dauert, bis CPU und DTU 100 Prozent erreichen.
Zugehörige Ressourcen
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für