Antimuster „Zu viele E/A-Vorgänge“
Der kumulative Effekt einer hohen Anzahl von E/A-Anforderungen kann sich massiv auf die Leistung und die Reaktionsfähigkeit auswirken.
Problembeschreibung
Netzwerkaufrufe und andere E/A-Vorgänge sind im Vergleich zu Computingtasks von Natur aus langsamer. Jede E/A-Anforderung führt in der Regel zu einem erheblichen Overhead, und der kumulative Effekt einer hohen Zahl von E/A-Vorgängen kann das System verlangsamen. Im Folgenden finden Sie einige häufige Gründe für eine zu hohe Anzahl von E/A-Vorgängen.
Lesen und Schreiben einzelner Datensätze in einer Datenbank in unterschiedlichen Anforderungen
Das folgende Beispiel liest Daten aus einer Produktdatenbank. Es gibt drei Tabellen: Product, ProductSubcategory und ProductPriceListHistory. Der Code ruft mithilfe einer Reihe von Abfragen alle Produkte in einer Unterkategorie zusammen mit den zugehörigen Preisinformationen ab:
- Die Unterkategorie wird aus der Tabelle
ProductSubcategoryabgefragt. - Durch Abfragen der Tabelle
Productwerden alle Produkte in dieser Unterkategorie gesucht. - Für jedes Produkt werden die Preisdaten aus der Tabelle
ProductPriceListHistoryabgefragt.
Die Anwendung verwendet das Entity Framework zum Abfragen der Datenbank. Das vollständige Beispiel finden Sie hier.
public async Task<IHttpActionResult> GetProductsInSubCategoryAsync(int subcategoryId)
{
using (var context = GetContext())
{
// Get product subcategory.
var productSubcategory = await context.ProductSubcategories
.Where(psc => psc.ProductSubcategoryId == subcategoryId)
.FirstOrDefaultAsync();
// Find products in that category.
productSubcategory.Product = await context.Products
.Where(p => subcategoryId == p.ProductSubcategoryId)
.ToListAsync();
// Find price history for each product.
foreach (var prod in productSubcategory.Product)
{
int productId = prod.ProductId;
var productListPriceHistory = await context.ProductListPriceHistory
.Where(pl => pl.ProductId == productId)
.ToListAsync();
prod.ProductListPriceHistory = productListPriceHistory;
}
return Ok(productSubcategory);
}
}
Dieses Beispiel veranschaulicht das Problem explizit, aber manchmal maskiert eine objektrelationale Abbildung (Object Relational Mapping, O/RM) das Problem, wenn untergeordnete Datensätze implizit nacheinander abgerufen werden. Diese wird als „N+1-Problem“ bezeichnet.
Implementieren eines einzigen logischen Vorgangs als Serie von HTTP-Anforderungen
Dies passiert häufig, wenn Entwickler versuchen, einem objektorientierten Paradigma zu folgen und Remoteobjekte so behandeln, als wären es lokale Objekte im Arbeitsspeicher. Die kann zu einer zu hohen Anzahl von Netzwerkroundtrips führen. Ein Beispiel: Die folgende Web-API macht die einzelnen Eigenschaften von User-Objekten über einzelne HTTP GET-Methoden verfügbar.
public class UserController : ApiController
{
[HttpGet]
[Route("users/{id:int}/username")]
public HttpResponseMessage GetUserName(int id)
{
...
}
[HttpGet]
[Route("users/{id:int}/gender")]
public HttpResponseMessage GetGender(int id)
{
...
}
[HttpGet]
[Route("users/{id:int}/dateofbirth")]
public HttpResponseMessage GetDateOfBirth(int id)
{
...
}
}
Rein technisch ist dieser Ansatz völlig in Ordnung, allerdings werden die meisten Clients wahrscheinlich verschiedene Eigenschaften für jedes User-Objekt abrufen müssen, sodass der Clientcode in etwa folgendermaßen aussieht.
HttpResponseMessage response = await client.GetAsync("users/1/username");
response.EnsureSuccessStatusCode();
var userName = await response.Content.ReadAsStringAsync();
response = await client.GetAsync("users/1/gender");
response.EnsureSuccessStatusCode();
var gender = await response.Content.ReadAsStringAsync();
response = await client.GetAsync("users/1/dateofbirth");
response.EnsureSuccessStatusCode();
var dob = await response.Content.ReadAsStringAsync();
Lesen und Schreiben in einer Datei auf einem Datenträger
Datei-E/A-Vorgänge umfassen das Öffnen einer Datei und das Springen an den geeigneten Punkt, bevor Daten gelesen oder geschrieben werden. Wenn der Vorgang abgeschlossen wurde, kann die Datei geschlossen werden, um Systemressourcen einzusparen. Eine Anwendung, die kontinuierlich kleine Mengen von Informationen in einer Datei liest oder schreibt, generiert einen erheblichen E/A-Overhead. Schreibanforderungen für geringe Datenmengen können auch zur Fragmentierung von Dateien führen und damit nachfolgende E/A-Vorgänge noch weiter verlangsamen.
Das folgende Beispiel verwendet ein FileStream-Objekt, um ein Customer-Objekt in eine Datei zu schreiben. Durch Erstellen des FileStream-Objekts wird die Datei geöffnet, durch Löschen des Objekts wird sie wieder geschlossen. (Die using-Anweisung löscht das FileStream-Objekt automatisch.) Wenn die Anwendung diese Methode wiederholt aufruft, wenn neue Kunden hinzugefügt werden, kann der E/A-Overhead schnell anwachsen.
private async Task SaveCustomerToFileAsync(Customer customer)
{
using (Stream fileStream = new FileStream(CustomersFileName, FileMode.Append))
{
BinaryFormatter formatter = new BinaryFormatter();
byte [] data = null;
using (MemoryStream memStream = new MemoryStream())
{
formatter.Serialize(memStream, customer);
data = memStream.ToArray();
}
await fileStream.WriteAsync(data, 0, data.Length);
}
}
Beheben des Problems
Reduzieren Sie die Anzahl von E/A-Anforderungen, indem Sie die Daten in größere, weniger häufig auftretende Anforderungen packen.
Rufen Sie Daten in einer einzigen Abfrage aus einer Datenbank ab, nicht in mehreren kleinen Abfragen. Im Folgenden sehen Sie eine überarbeitete Version des Codes, der Produktinformationen abruft.
public async Task<IHttpActionResult> GetProductCategoryDetailsAsync(int subCategoryId)
{
using (var context = GetContext())
{
var subCategory = await context.ProductSubcategories
.Where(psc => psc.ProductSubcategoryId == subCategoryId)
.Include("Product.ProductListPriceHistory")
.FirstOrDefaultAsync();
if (subCategory == null)
return NotFound();
return Ok(subCategory);
}
}
Befolgen Sie die REST-Entwurfsprinzipien für Web-APIs. Nachfolgend sehen Sie eine überarbeitete Version der Web-API aus dem vorherigen Beispiel. Statt separater GET-Methoden für jede Eigenschaft wird eine einzige GET-Methode verwendet, die das User-Objekt zurückgibt. Dadurch wird für jede Anforderung ein längerer Antworttext zurückgegeben, aber die einzelnen Clients werden wahrscheinlich weniger API-Aufrufe durchführen.
public class UserController : ApiController
{
[HttpGet]
[Route("users/{id:int}")]
public HttpResponseMessage GetUser(int id)
{
...
}
}
// Client code
HttpResponseMessage response = await client.GetAsync("users/1");
response.EnsureSuccessStatusCode();
var user = await response.Content.ReadAsStringAsync();
Erwägen Sie bei Datei-E/A-Vorgängen, Daten im Arbeitsspeicher zu puffern und die gepufferten Daten dann in einem einzigen Vorgang in eine Datei zu schreiben. Mit dieser Vorgehensweise reduzieren Sie den Overhead, der durch häufiges Öffnen und Schließen der Datei entsteht, und verringern zudem die Fragmentierung der Datei auf dem Datenträger.
// Save a list of customer objects to a file
private async Task SaveCustomerListToFileAsync(List<Customer> customers)
{
using (Stream fileStream = new FileStream(CustomersFileName, FileMode.Append))
{
BinaryFormatter formatter = new BinaryFormatter();
foreach (var customer in customers)
{
byte[] data = null;
using (MemoryStream memStream = new MemoryStream())
{
formatter.Serialize(memStream, customer);
data = memStream.ToArray();
}
await fileStream.WriteAsync(data, 0, data.Length);
}
}
}
// In-memory buffer for customers.
List<Customer> customers = new List<Customers>();
// Create a new customer and add it to the buffer
var customer = new Customer(...);
customers.Add(customer);
// Add more customers to the list as they are created
...
// Save the contents of the list, writing all customers in a single operation
await SaveCustomerListToFileAsync(customers);
Überlegungen
Die ersten beiden Beispiele führen weniger E/A-Aufrufe durch, jedes empfängt dadurch aber mehr Informationen. Diese beiden Faktoren müssen gegeneinander abgewogen werden. Die richtige Antwort hängt von den tatsächlichen Nutzungsmustern ab. Im Web-API-Beispiel könnte sich etwa herausstellen, dass Clients häufig nur den Benutzernamen benötigen. In diesem Fall ist es sinnvoll, diesen mit einem separaten API-Aufruf verfügbar zu machen. Weitere Informationen finden Sie im Antimuster Irrelevante Abrufe.
Entwerfen Sie beim Lesen von Daten keine zu umfangreichen E/A-Anforderungen. Eine Anwendung sollte nur die Daten abrufen, die sie wahrscheinlich benötigt.
Manchmal hilft es, die Informationen für ein Objekt in zwei Blöcke zu unterteilen: Daten, auf die häufig zugegriffen wird und die für die meisten Anforderungen relevant sind, und Daten, auf die weniger häufig zugegriffen wird und die entsprechend seltener benötigt werden. Häufig machen die Daten, auf die am häufigsten zugegriffen wird, einen relativ geringen Teil der Gesamtdatenmenge für ein Objekt aus, sodass sich der E/A-Overhead erheblich senken lässt, indem nur dieser Teil zurückgegeben wird.
Vermeiden Sie es beim Schreiben von Daten, Ressourcen länger als notwendig zu sperren, um das Risiko von Konflikten während eines Vorgangs mit langer Ausführungsdauer zu mindern. Wenn ein Schreibvorgang mehrere Datenspeicher, Dateien oder Dienste umfasst, wenden Sie einen letztlich konsistenten Ansatz an. Weitere Informationen finden Sie im Leitfaden zur Datenkonsistenz.
Wenn Sie Daten vor dem Schreiben im Arbeitsspeicher puffern, sind die Daten gefährdet, wenn der Prozess abstürzt. Wenn die Datenrate in der Regel verhältnismäßig gering ist oder Lastspitzen aufweist, ist es möglicherweise sicherer, die Daten in einer externen dauerhaften Warteschlange wie z.B. Event Hubs zu puffern.
Erwägen Sie, Daten, die Sie aus einem Dienst oder einer Datenbank abrufen, zwischenzuspeichern. So lässt sich die Menge an E/A-Vorgängen verringern, da wiederholte Anforderungen für die gleichen Daten vermieden werden. Weitere Informationen finden Sie in den bewährten Methoden für das Caching.
Erkennen des Problems
Zu den Symptomen einer zu hohen Anzahl von E/A-Vorgängen gehören eine hohe Latenz und ein geringer Durchsatz. Endbenutzer berichten vermutlich von längeren Antwortzeiten oder Fehlern aufgrund von Diensten, bei denen ein Timeout auftritt. Diese Probleme entstehen durch einen immer größeren Konflikt bei E/A-Ressourcen.
Sie können die folgenden Schritte ausführen, um die Ursache solcher Probleme zu identifizieren:
- Führen Sie eine Prozessüberwachung des Produktionssystems durch, um Vorgänge mit unzureichenden Antwortzeiten zu identifizieren.
- Führen Sie für jeden im vorherigen Schritt identifizierten Vorgang einen Auslastungstest durch.
- Sammeln Sie während der Auslastungstests Telemetriedaten über die Datenzugriffsanforderungen jedes Vorgangs.
- Erfassen Sie detaillierte Statistiken für jede an einen Datenspeicher gesendete Anforderung.
- Erstellen Sie ein Profil für die Anwendung in der Testumgebung, um herauszufinden, wo möglich E/A-Engpässe auftreten können.
Suchen Sie nach folgenden Symptomen:
- Eine große Anzahl von kleinen E/A-Anforderungen für die gleiche Datei
- Eine große Anzahl von kleinen Netzwerkanforderungen, die von einer Anwendungsinstanz an den gleichen Dienst gesendet werden
- Eine große Anzahl von kleinen Anforderungen, die von einer Anwendungsinstanz an den gleichen Datenspeicher gesendet werden
- Anwendungen und Dienste, die zunehmend E/A-gebunden sind
Beispieldiagnose
In den folgenden Abschnitten werden diese Schritte auf das oben gezeigte Beispiel angewendet, das eine Datenbank abfragt.
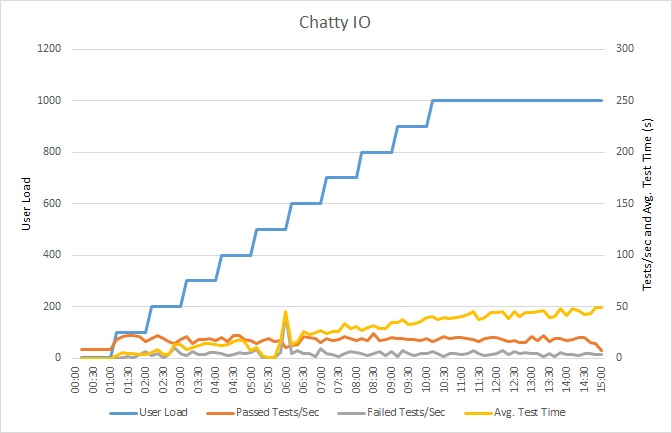
Auslastungstest der Anwendung
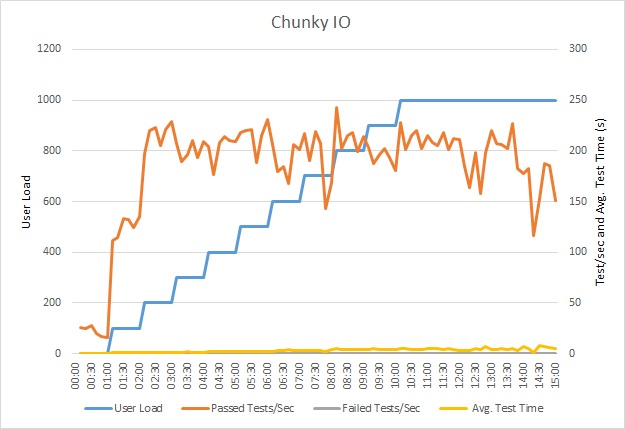
Dieses Diagramm zeigt die Ergebnisse der Auslastungstests. Der Medianwert der Antwortzeit wird in Zehntelsekunden pro Anforderung gemessen. Das Diagramm zeigt eine sehr hohe Latenz. Bei einer Last von 1.000 Benutzern muss ein Benutzer möglicherweise fast eine Minute auf die Ergebnisse einer Abfrage warten.
Hinweis
Die Anwendung wurde als Azure App Service-Web-App bereitgestellt und verwendet Azure SQL-Datenbank. Der Auslastungstest wurde mit einer simulierten schrittbasierten Workload von bis zu 1.000 gleichzeitigen Benutzern durchgeführt. Die Datenbank war mit einem Verbindungspool konfiguriert, der bis zu 1.000 gleichzeitige Verbindungen unterstützte, um das Risiko zu reduzieren, dass Verbindungskonflikte sich auf die Ergebnisse auswirken.
Überwachen der Anwendung
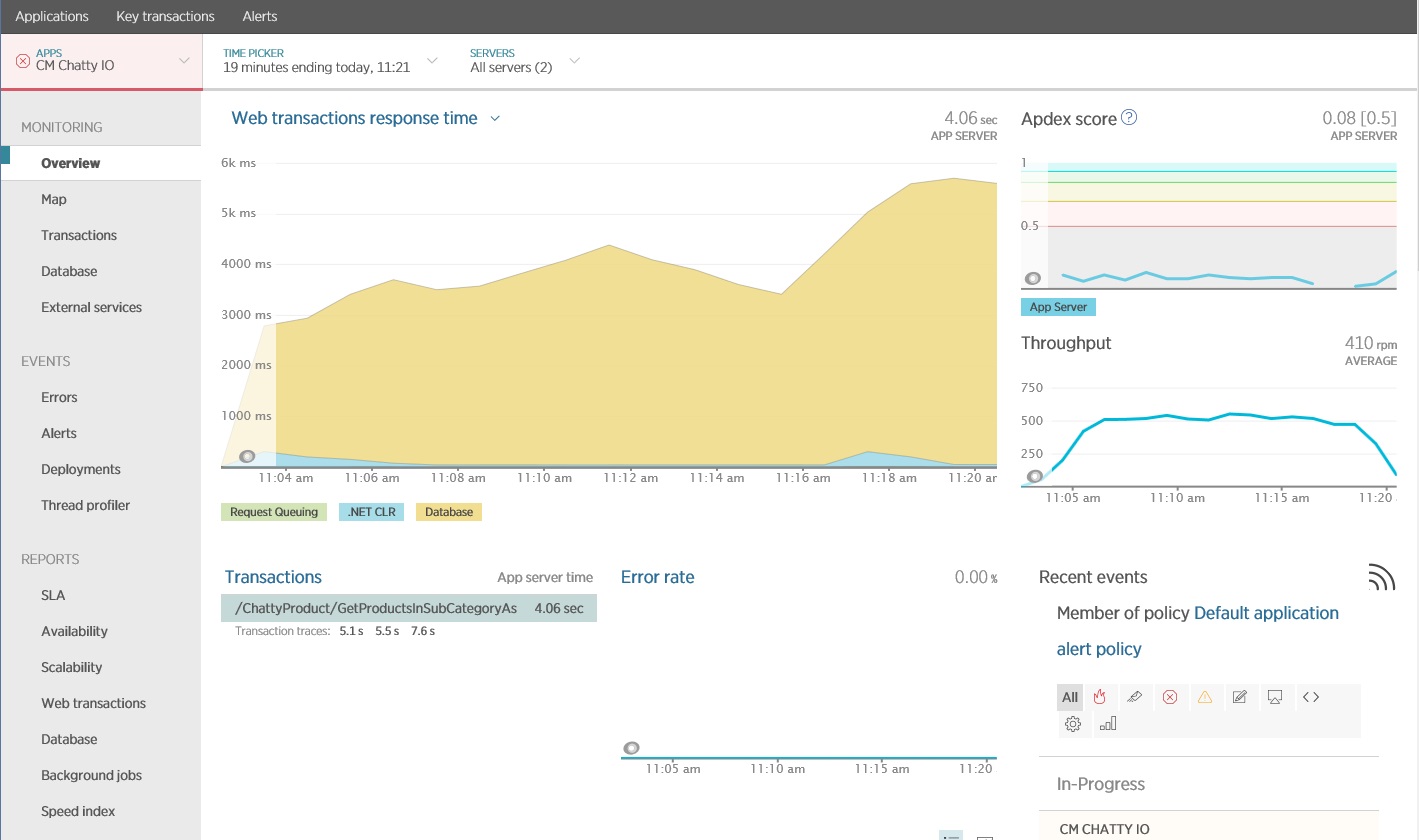
Sie können ein Paket für die Überwachung der Anwendungsleistung (Application Performance Monitoring, APM) verwenden, um die wichtigsten Metriken zu erfassen und zu analysieren, die eine zu hohe Anzahl von E/A-Vorgängen identifizieren können. Welche Metriken wichtig sind, richtet sich nach der E/A-Workload. In diesem Beispiel waren die Datenbankabfragen die interessantesten E/A-Anforderungen.
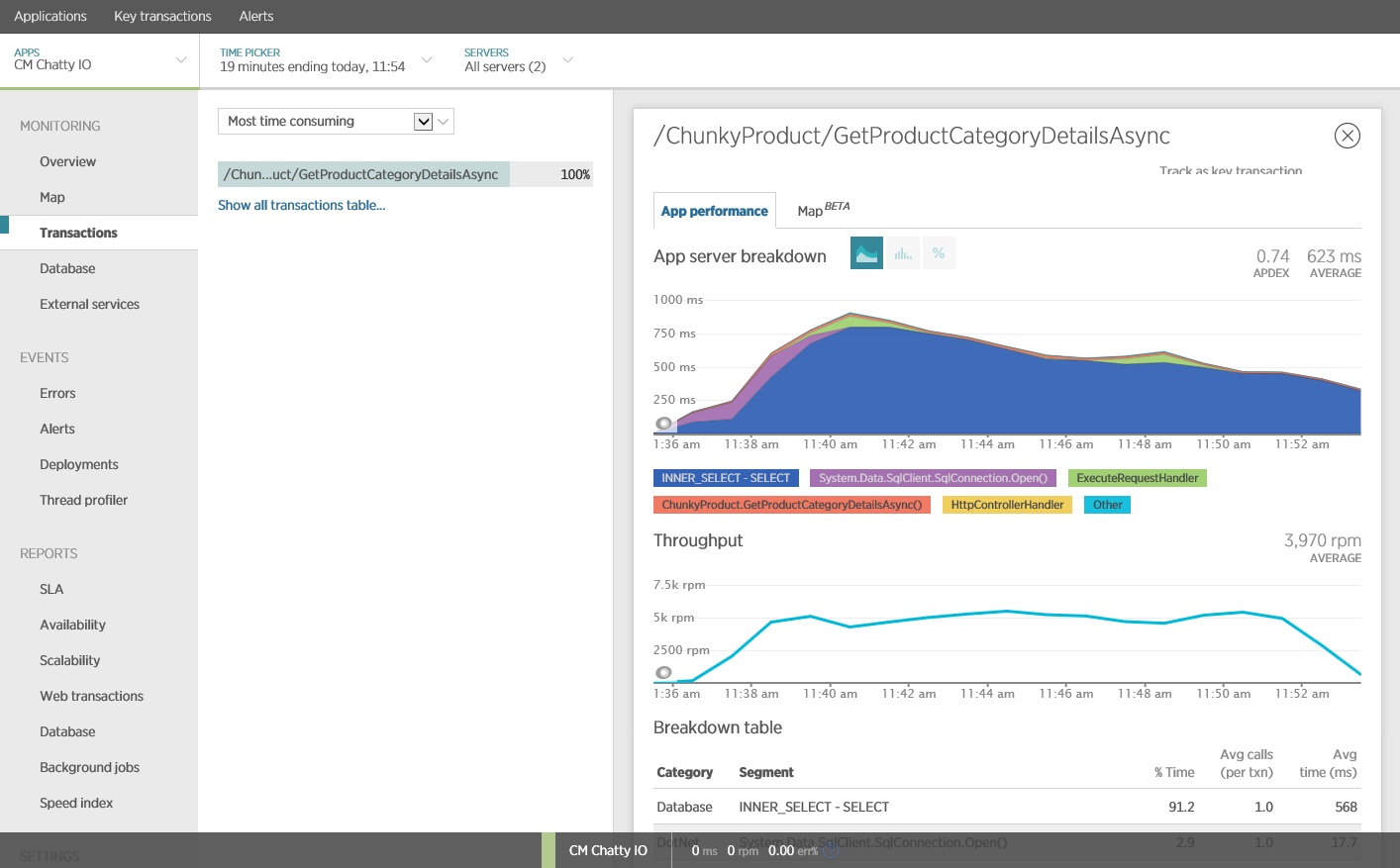
Die folgende Abbildung zeigt Ergebnisse, die mithilfe von New Relic APM generiert wurden. Der Spitzenwert der durchschnittlichen Datenbankantwortzeit lag während der maximalen Workload bei ca. 5,6 Sekunden pro Anforderung. Das System konnte während des gesamten Tests durchschnittlich 410 Anforderungen pro Minute unterstützen.
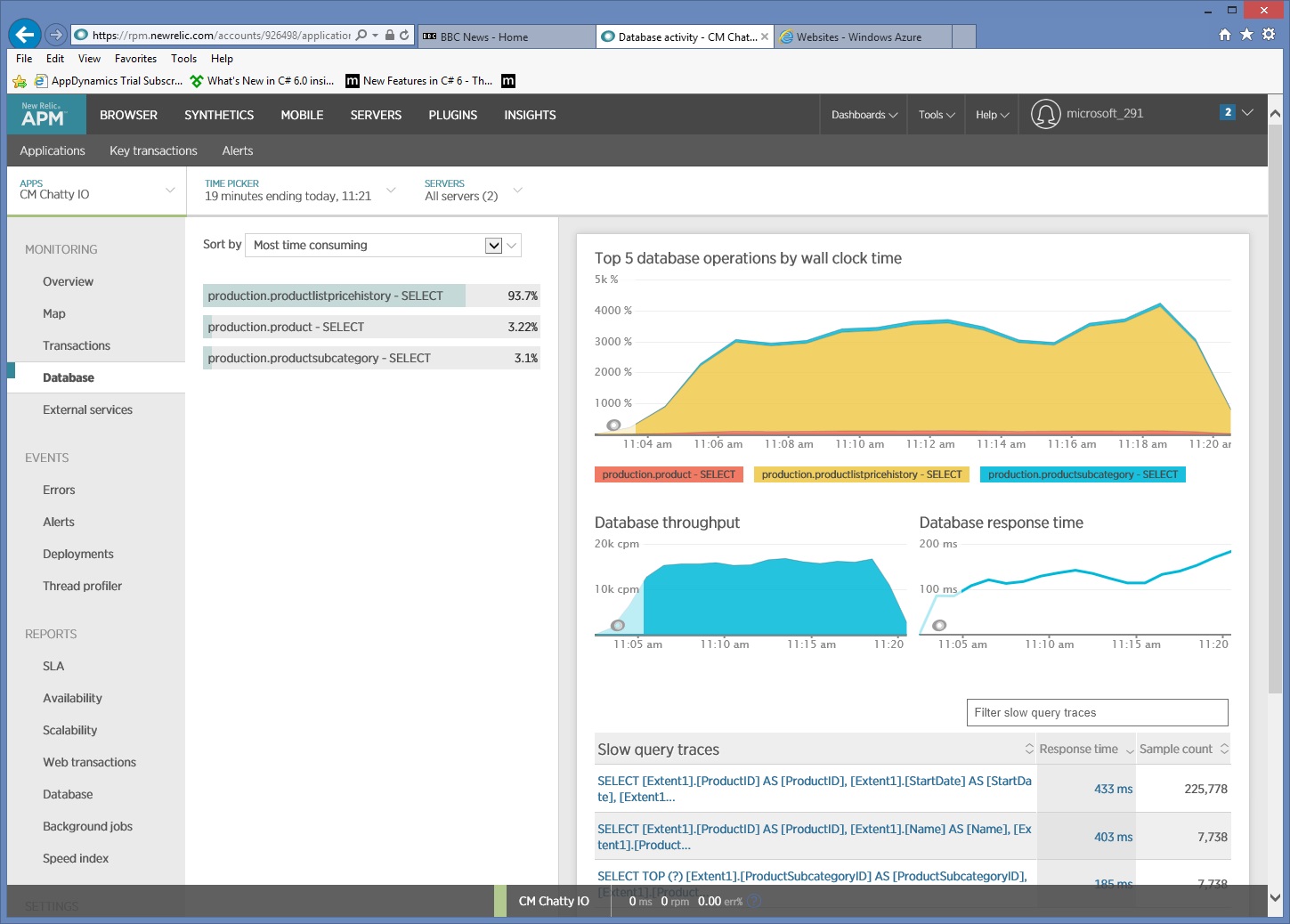
Erfassen detaillierter Informationen über den Datenzugriff
Ein genauerer Blick auf die Überwachungsdaten zeigt, dass die Anwendung drei verschiedene SQL SELECT-Anweisungen ausgeführt hat. Diese entsprechen den Anforderungen, die von Entity Framework generiert wurden, um Daten aus den Tabellen ProductListPriceHistory, Product und ProductSubcategory abzurufen. Darüber hinaus ist die Abfrage, die Daten aus der Tabelle ProductListPriceHistory abruft, die bei weitem am häufigsten ausgeführte SELECT-Anweisung.
Es zeigt sich, dass die oben gezeigte GetProductsInSubCategoryAsync-Methode 45 SELECT-Abfragen durchführt. Jede Abfrage führt dazu, dass die Anwendung eine neue SQL-Verbindung öffnet.
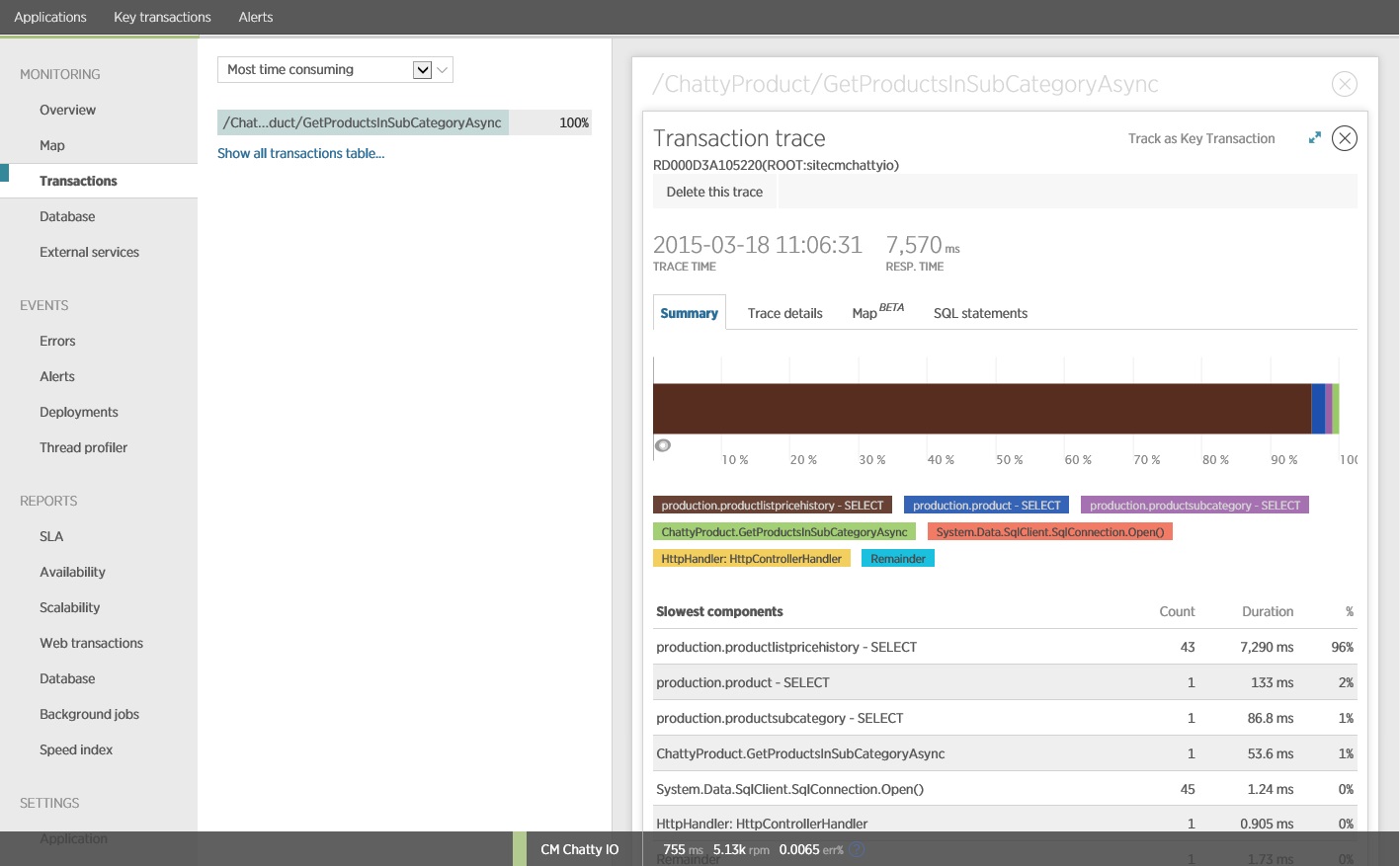
Hinweis
Diese Abbildung zeigt Ablaufverfolgungsinformationen für die langsamste Instanz des GetProductsInSubCategoryAsync-Vorgangs im Auslastungstest. In einer Produktionsumgebung ist es sehr hilfreich, die Ablaufverfolgungen der langsamsten Instanzen zu untersuchen, um festzustellen, ob ein Muster vorliegt, das auf ein Problem hinweist. Wenn Sie nur die Durchschnittswerte betrachten, entgehen Ihnen möglicherweise Probleme, die unter hoher Last erheblich schlimmer werden.
Die nächste Abbildung zeigt die tatsächlich ausgegebenen SQL-Anweisungen. Die Abfrage, die Preisinformationen abruft, wird für jedes einzelne Produkt in der Unterkategorie der Produkte ausgeführt. Mithilfe eines Joins ließe sich die Anzahl von Datenbankaufrufen deutlich reduzieren.
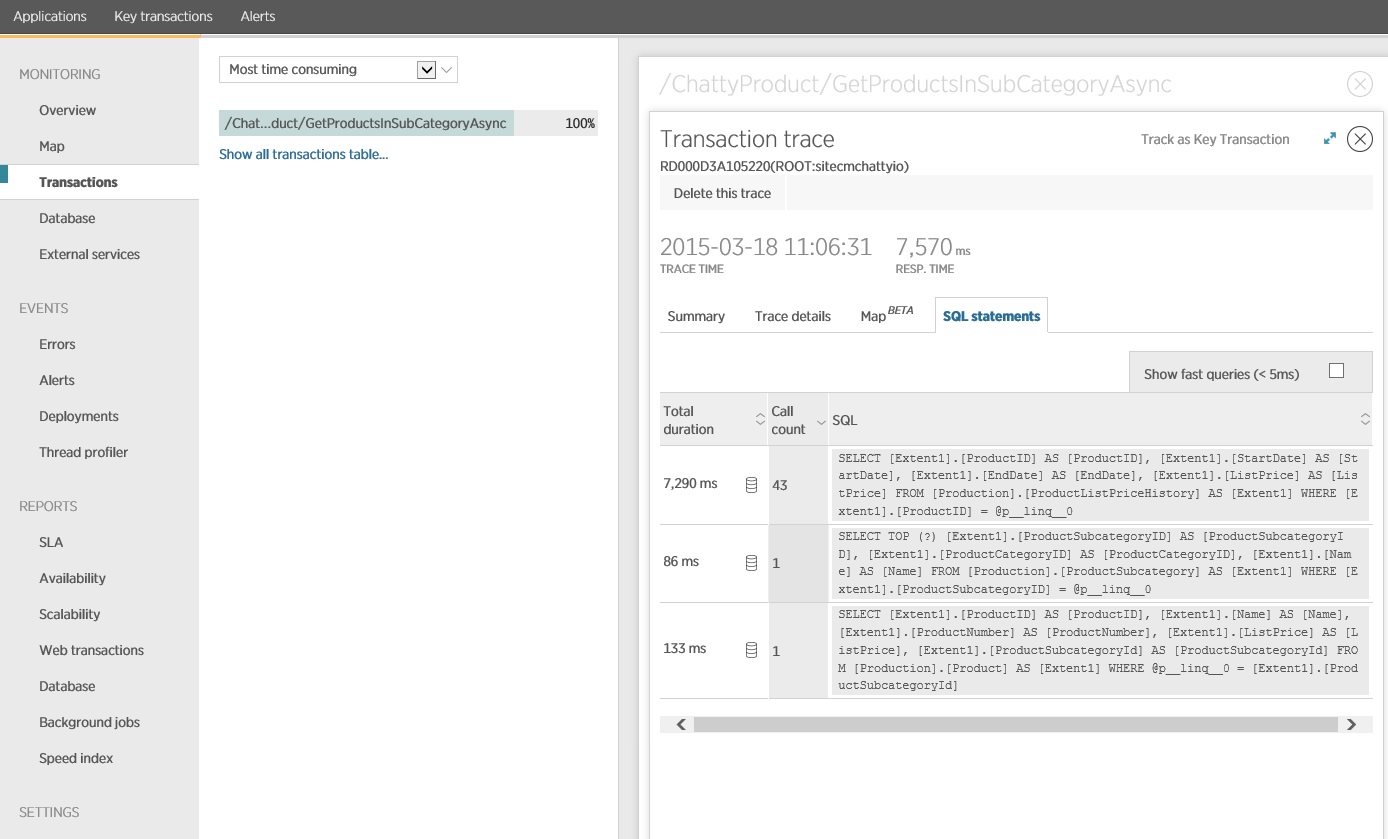
Wenn Sie eine objektrelationale Abbildung wie z.B. Entity Framework verwenden, kann eine Ablaufverfolgung der SQL-Abfragen Einblicke dazu liefern, wie die objektrelationale Abbildung die programmgesteuerten Aufrufe in SQL-Anweisungen übersetzt. Gleichzeitig können Bereiche aufgezeigt werden, in denen sich der Datenzugriff optimieren lässt.
Implementieren der Lösung und Überprüfen des Ergebnisses
Ein Umschreiben des Aufrufs von Entity Framework generiert die folgenden Ergebnisse.
Dieser Auslastungstest wurde mit dem gleichen Auslastungsprofil in der gleichen Bereitstellung ausgeführt. Dieses Mal zeigt das Diagramm eine viel niedrigere Latenz. Die durchschnittliche Anforderungszeit bei 1.000 Benutzern liegt zwischen 5 und 6 Sekunden – zuvor lag sie bei fast einer Minute.
Dieses Mal unterstützte das System durchschnittlich 3.970 Anforderungen pro Minute, im Vergleich zu 410 im vorherigen Test.
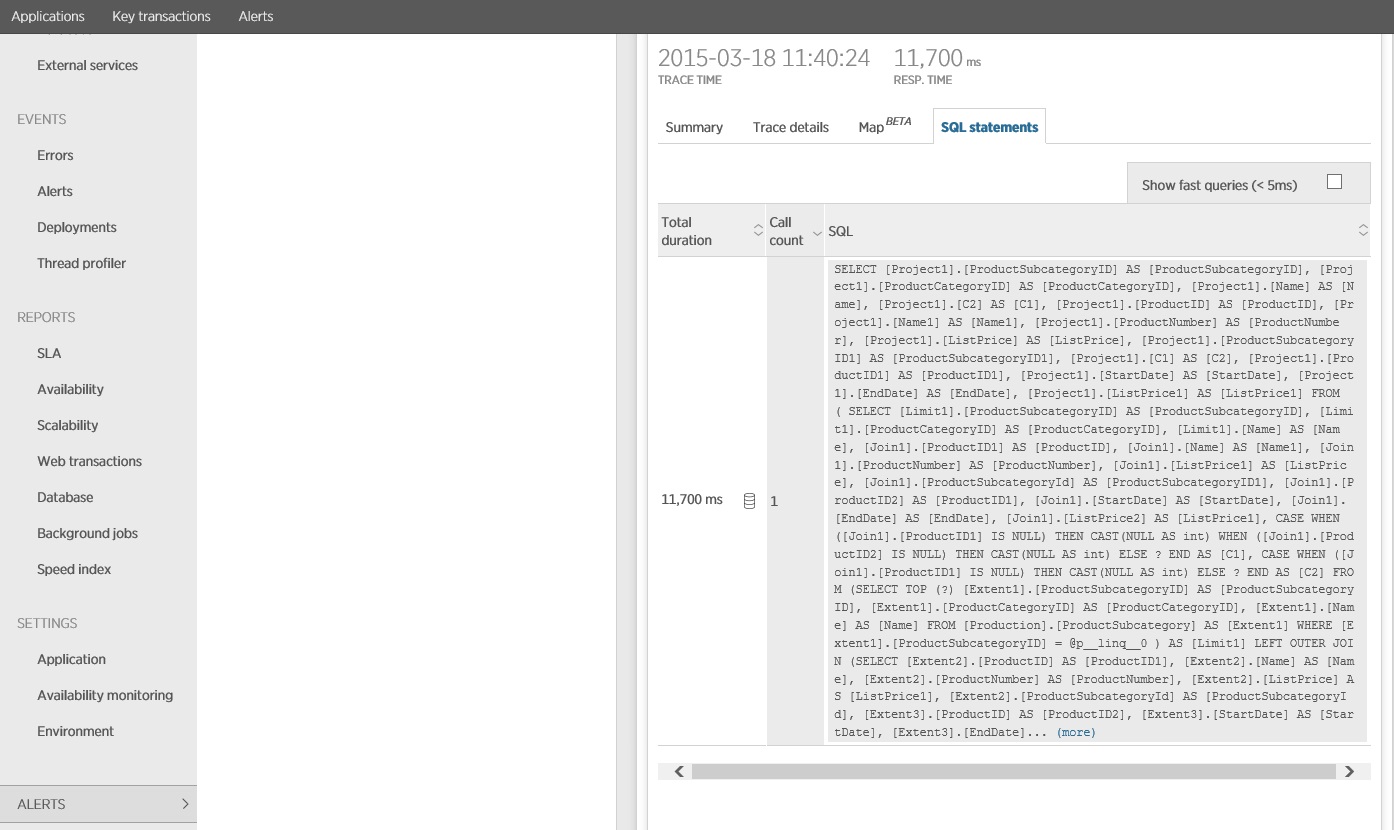
Die Ablaufverfolgung der SQL-Anweisung zeigt, dass alle Daten in einer einzigen SELECT-Anweisung abgerufen werden. Diese Abfrage ist zwar deutlich komplexer, wird dafür aber nur einmal pro Vorgang ausgeführt. Und während komplexe Joins teuer werden können, sind relationale Datenbanksysteme für diese Art von Abfragen optimiert.
Zugehörige Ressourcen
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für