Wiederholungssturm-Antimuster („Retry Storm“)
Wenn ein Dienst nicht verfügbar oder ausgelastet ist, können zu häufige Versuche von Clients, die Verbindung wiederherzustellen, dazu führen, dass der Dienst Probleme bekommt, wieder verfügbar zu werden, wodurch das eigentliche Problem noch verstärkt wird. Es ist auch nicht sinnvoll, unendliche Wiederholungsversuche durchzuführen, da Anforderungen in der Regel nur für einen definierten Zeitraum gültig sind.
Problembeschreibung
In der Cloud treten bei Diensten manchmal Probleme auf, wodurch sie für Clients nicht mehr verfügbar sind, oder sie müssen ihre Clients drosseln oder deren Übertragungsrate einschränken. Zwar ist es eine bewährte Vorgehensweise von Clients, fehlgeschlagene Verbindungen mit Diensten erneut zu versuchen, doch ist es wichtig, dass sie dies nicht zu häufig oder zu lange versuchen. Es ist unwahrscheinlich, dass Wiederholungsversuche innerhalb eines kurzen Zeitraums erfolgreich sind, weil die Dienste wahrscheinlich keine Zeit hatten, wieder verfügbar zu werden. Außerdem können Dienste noch stärker belastet werden, wenn während eines Wiederherstellungsversuchs zahlreiche Verbindungsversuche unternommen werden, und wiederholte Verbindungsversuche können den Dienst sogar so stark überfordern, dass sich das zugrunde liegende Problem verschlimmert.
Das folgende Beispiel veranschaulicht ein Szenario, in dem ein Client eine Verbindung mit einer serverbasierten API herstellt. Wenn die Anforderung nicht erfolgreich ist, versucht es der Client sofort noch mal und wird es immer wieder versuchen. Häufig ist diese Art von Verhalten subtiler als in diesem Beispiel, aber es gilt dasselbe Prinzip.
public async Task<string> GetDataFromServer()
{
while(true)
{
var result = await httpClient.GetAsync(string.Format("http://{0}:8080/api/...", hostName));
if (result.IsSuccessStatusCode) break;
}
// ... Process result.
}
Beheben des Problems
Clientanwendungen sollten einige bewährte Methoden befolgen, um die Verursachung eines Wiederholungssturms zu vermeiden.
- Begrenzen Sie die Anzahl von Wiederholungsversuchen, und führen Sie nicht über einen längeren Zeitraum Wiederholungsversuche durch. Auch wenn es leicht erscheinen mag, eine
while(true)-Schleife zu schreiben, möchten Sie doch wahrscheinlich eher nicht über einen längeren Zeitraum hinweg Wiederholungsversuche ausführen, da sich die Situation, die zur Veranlassung der Anforderung geführt hat, wahrscheinlich geändert hat. In den meisten Anwendungen ist es ausreichend, Wiederholungen für einige Sekunden oder Minuten zu versuchen. - Machen Sie zwischen Wiederholungsversuchen Pausen. Wenn ein Dienst nicht verfügbar ist, ist es unwahrscheinlich, dass ein sofortiger Wiederholungsversuch erfolgreich sein wird. Erhöhen Sie schrittweise die Wartezeit zwischen einzelnen Versuchen, z. B. durch die Verwendung einer exponentiellen Backoff-Strategie.
- Behandeln Sie Fehler ordnungsgemäß. Wenn der Dienst nicht reagiert, sollten Sie überlegen, ob es sinnvoll ist, den Versuch abzubrechen und einen Fehler an den Benutzer oder den Aufrufer der Komponente zurückzugeben. Erwägen Sie diese Fehlerszenarien, wenn Sie Ihre Anwendung entwerfen.
- Erwägen Sie die Verwendung des Verbindungsunterbrechungs-Musters („Ciruit Breaker“), das speziell für die Vermeidung von Wiederholungsstürmen entwickelt wurde.
- Wenn der Server einen
retry-after-Antwortheader bereitstellt, stellen Sie sicher, dass Sie nicht versuchen, den Vorgang zu wiederholen, bevor der angegebene Zeitraum verstrichen ist. - Verwenden Sie offizielle SDKs bei der Kommunikation mit Azure-Diensten. Diese SKDs verfügen in der Regel über integrierte Wiederholungsrichtlinien und Schutzmaßnahmen vor der Verursachung von oder dem Beitragen zu Wiederholungsstürmen. Wenn Sie mit einem Dienst kommunizieren, der über kein SDK verfügt, oder wenn das SDK die Wiederholungslogik nicht ordnungsgemäß verarbeitet, sollten Sie die Verwendung einer Bibliothek wie Polly (für .NET) oder retry (für JavaScript) in Erwägung ziehen, um Ihre Wiederholungslogik ordnungsgemäß zu verarbeiten und den Code nicht selbst schreiben zu müssen.
- Verwenden Sie bei der Ausführung in einer Umgebung, die dies unterstützt, ein Dienstmesh (oder eine andere Abstraktionsschicht) zum Senden ausgehender Aufrufe. In der Regel unterstützen diese Tools (etwa Dapr) Wiederholungsrichtlinien und befolgen automatisch bewährte Methoden, z. B. das Sichern nach wiederholten Versuchen. Dieser Ansatz bedeutet, dass Sie keinen Wiederholungscode selbst schreiben müssen.
- Erwägen Sie, Anforderungen batchweise zu verarbeiten und, wo möglich, Anforderungspooling zu verwenden. Viele SDKs verarbeiten die Batchverarbeitung von Anforderungen und Verbindungspooling in Ihrem Auftrag, wodurch sich die Gesamtzahl der ausgehenden Verbindungsversuche, die Ihre Anwendung ausführt, verringert, obgleich Sie weiterhin vorsichtig sein müssen, dass Sie diese Verbindungsversuche nicht zu häufig wiederholen.
Dienste sollten sich auch selbst vor Wiederholungsstürmen schützen.
- Fügen Sie eine Gatewayschicht hinzu, damit Sie Verbindungen während eines Vorfalls unterbrechen können. Dies ist eine Beispiel für das Bulkhead-Muster. Azure bietet viele verschiedene Gatewaydienste für unterschiedliche Lösungstypen, einschließlich Front-Door, Application Gateway und API Management.
- Drosseln Sie Anforderungen auf Ihrem Gateway, wodurch sichergestellt wird, dass Sie nicht so viele Anforderungen akzeptieren, dass Ihre Back-End-Komponenten nicht mehr funktionsfähig bleiben.
- Wenn Sie eine Drosselung durchführen, senden Sie einen
retry-after-Header zurück, um Clients zu verstehen zu geben, wann sie ihre Verbindungsversuche wiederholen sollten.
Überlegungen
- Clients sollten den Typ des zurückgegebenen Fehlers berücksichtigen. Einige Fehlertypen weisen nicht auf einen Fehler des Diensts hin, sondern darauf, dass der Client eine ungültige Anforderung gesendet hat. Wenn eine Clientanwendung beispielsweise eine
400 Bad Request-Fehlerantwort erhält, wird die Wiederholung derselben Anforderung wahrscheinlich nicht hilfreich sein, da der Server mitteilt, dass Ihre Anforderung ungültig ist. - Clients sollten die Zeitspanne berücksichtigen, die für erneute Verbindungsversuche sinnvoll ist. Die Zeitspanne, über die Sie Wiederholungsversuche durchführen sollten, hängt von Ihren geschäftlichen Anforderungen sowie davon ab, ob Sie einen Fehler sinnvoll an einen Benutzer oder Aufrufer zurückgeben können. In den meisten Anwendungen ist es ausreichend, Wiederholungen für einige Sekunden oder Minuten zu versuchen.
Erkennen des Problems
Aus Sicht des Clients können Symptome dieses Problems sehr lange Antwort- oder Verarbeitungszeiten zusammen mit Telemetriedaten enthalten, die wiederholte Verbindungsversuche anzeigen.
Aus Sicht des Diensts können Symptome dieses Problems eine große Anzahl von Anforderungen von einem Client innerhalb eines kurzen Zeitraums oder eine große Anzahl von Anforderungen von einem einzelnen Client während der Wiederherstellung nach Ausfällen enthalten. Die Symptome können auch Schwierigkeiten bei der Wiederherstellung des Diensts umfassen oder laufende kaskadierende Fehler des Diensts, direkt nachdem ein Fehler behoben wurde.
Beispieldiagnose
In den folgenden Abschnitten wird ein Ansatz zum Erkennen eines möglichen Wiederholungssturms veranschaulicht, und zwar auf Clientseite und auf Dienstseite.
Identifizieren aus Clienttelemetrie
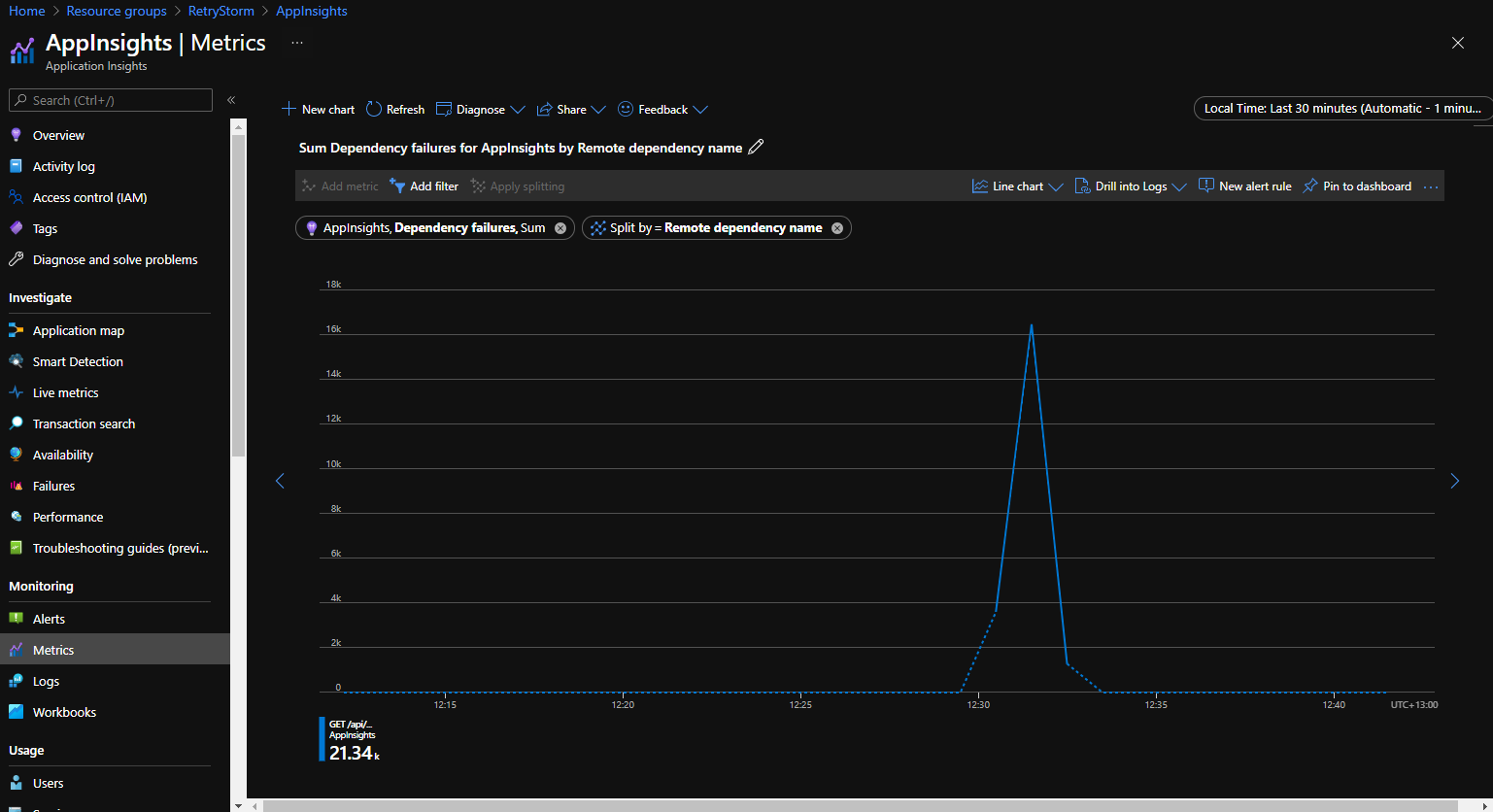
Azure Application Insights zeichnet Telemetriedaten von Anwendungen auf und stellt die Daten für Abfragen und Visualisierungen zur Verfügung. Ausgehende Verbindungen werden als Abhängigkeiten verfolgt, und Informationen zu diesen sind zugänglich und lassen sich grafisch darstellen, um zu ermitteln, wenn ein Client eine große Anzahl von ausgehenden Anforderungen an denselben Dienst sendet.
Das folgende Diagramm stammt von der Registerkarte „Metriken“ im Application Insights-Portal und zeigt die Metrik Abhängigkeitsfehler, aufgeschlüsselt nach Remoteabhängigkeitsname. Dies veranschaulicht ein Szenario, in dem eine große Anzahl (über 21.000) fehlgeschlagener Verbindungsversuche innerhalb eines kurzen Zeitraums aufgetreten ist.
Identifizieren aus Servertelemetrie
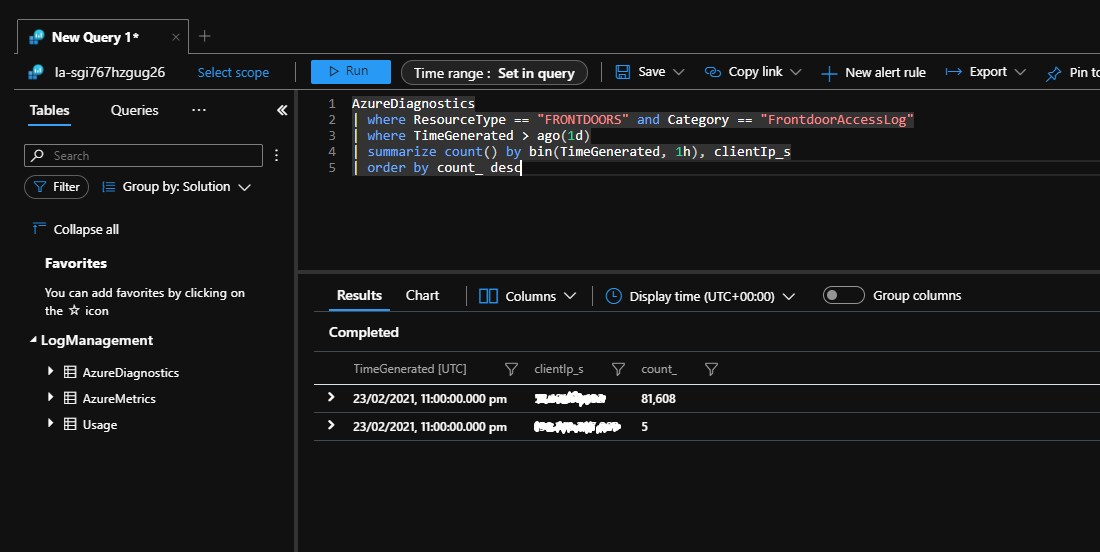
Serveranwendungen können möglicherweise eine große Anzahl von Verbindungen von einem einzelnen Client aus erkennen. Im folgenden Beispiel fungiert Azure Front Door als Gateway für eine Anwendung und wurde so konfiguriert, dass alle Anforderungen in einem Log Analytics-Arbeitsbereich protokolliert werden.
Die folgende Kusto-Abfrage kann an Log Analytics gesendet werden. Dabei werden Client-IP-Adressen identifiziert, die innerhalb des letzten Tages eine große Anzahl von Anforderungen an die Anwendung gesendet haben.
AzureDiagnostics
| where ResourceType == "FRONTDOORS" and Category == "FrontdoorAccessLog"
| where TimeGenerated > ago(1d)
| summarize count() by bin(TimeGenerated, 1h), clientIp_s
| order by count_ desc
Wenn Sie diese Abfrage während eines Wiederholungssturms ausführen, wird eine große Anzahl von Verbindungsversuchen von einer einzelnen IP-Adresse angezeigt.
Zugehörige Ressourcen
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für