Diese Referenzarchitektur veranschaulicht, wie Sie ein Empfehlungsmodell mit Azure Databricks trainieren und dann unter Verwendung von Azure Cosmos DB, Azure Machine Learning und Azure Kubernetes Service (AKS) als API bereitstellen. Eine Referenzimplementierung dieser Architektur finden Sie unter Erstellen einer Echtzeitempfehlungs-API auf GitHub.
Aufbau
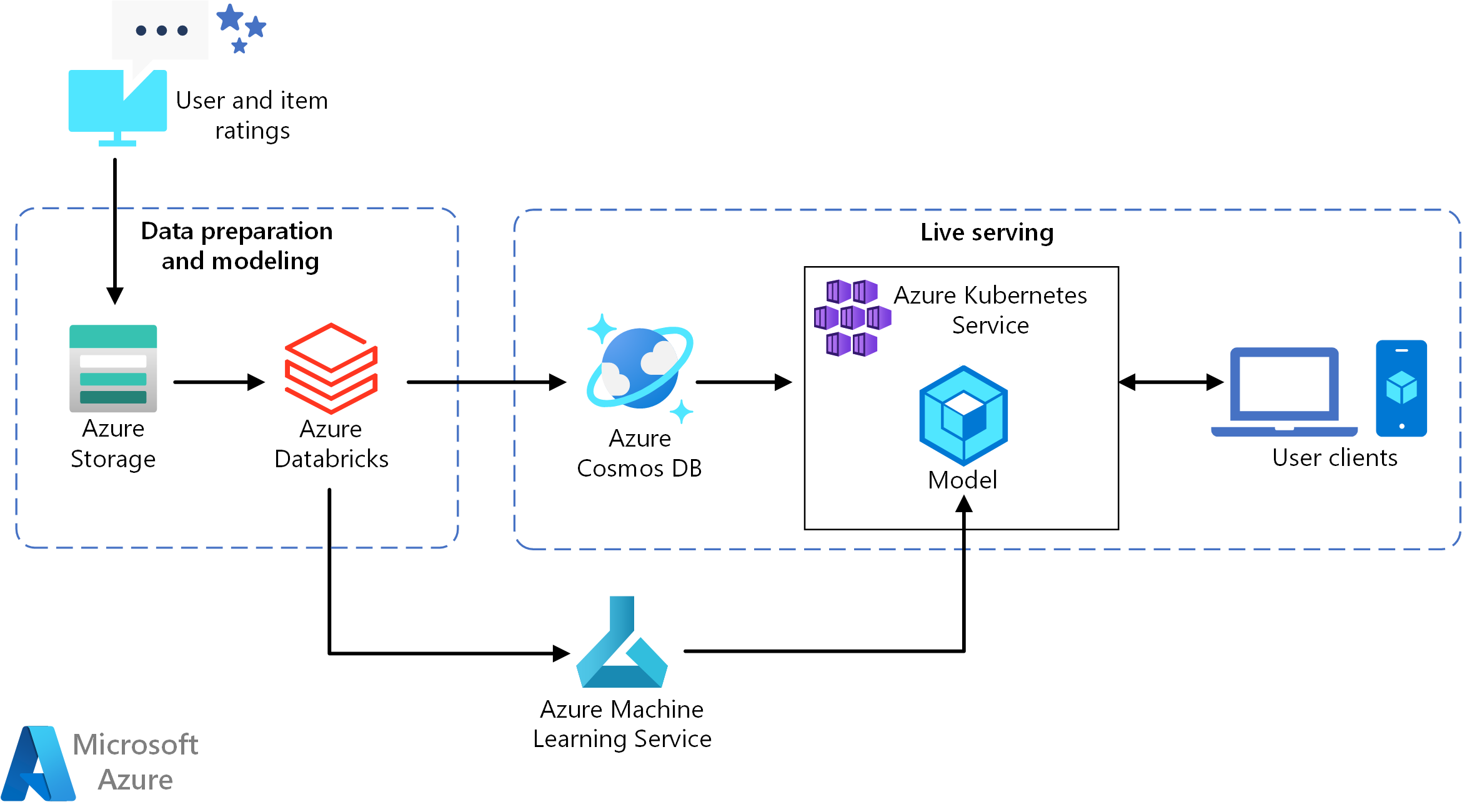
Laden Sie eine Visio-Datei dieser Architektur herunter.
Diese Referenzarchitektur ist für das Trainieren und Bereitstellen einer Echtzeitempfehlungs-API konzipiert, mit der Benutzer*innen die Top 10 der Filmempfehlungen angezeigt werden können.
Datenfluss
- Das Benutzerverhalten wird nachverfolgt. Beispielsweise kann von einem Back-End-Dienst protokolliert werden, wenn Benutzer*innen einen Film bewerten oder auf ein Produkt oder einen Nachrichtenartikel klicken.
- Laden Sie die Daten aus einer verfügbaren Datenquelle in Azure Databricks.
- Bereiten Sie die Daten auf, und unterteilen Sie sie in Trainings- und Testsätze, um das Modell zu trainieren. (In dieser Anleitung werden Optionen zum Unterteilen von Daten beschrieben.)
- Passen Sie das Spark-Modell für das kombinierte Filtern an die Daten an.
- Werten Sie die Qualität des Modells aus, indem Sie Metriken für die Bewertung und die Rangfolge verwenden. (Diese Anleitung enthält ausführliche Informationen zu den Metriken, mit denen Sie Ihr Empfehlungssystem bewerten können.)
- Berechnen Sie die Top 10 der Empfehlungen pro Benutzer voraus, und speichern Sie das Ergebnis als Cachedaten in Azure Cosmos DB.
- Stellen Sie einen API-Dienst für AKS bereit, indem Sie die Machine Learning-APIs zum Containerisieren und Bereitstellen der API verwenden.
- Wenn der Back-End-Dienst eine Anforderung von Benutzer*innen erhält, können Sie die in AKS gehostete Empfehlungs-API aufrufen, um die Top 10 der Empfehlungen abzurufen und für die Benutzer*innen anzuzeigen.
Komponenten
- Azure Databricks: Databricks ist eine Entwicklungsumgebung, die zum Aufbereiten von Eingabedaten und Trainieren des Empfehlungssystemmodells in einem Spark-Cluster genutzt wird. Mit Azure Databricks wird auch ein interaktiver Arbeitsbereich zum Ausführen von Notebooks und zum damit verbundenen gemeinsamen Durchführen der Datenverarbeitung oder von Machine Learning-Aufgaben bereitgestellt.
- Azure Kubernetes Service (AKS): AKS wird verwendet, um eine Machine Learning-Modelldienst-API in einem Kubernetes-Cluster bereitzustellen und zu operationalisieren. AKS hostet das Containermodell und sorgt für eine Skalierbarkeit, mit der Ihre Durchsatzanforderungen erfüllt werden, sowie für die Identitäts- und Zugriffsverwaltung und die Protokollierung und Systemüberwachung.
- Azure Cosmos DB. Azure Cosmos DB ist ein global verteilter Datenbankdienst zum Speichern der empfohlenen Top-10-Filme für jeden Benutzer. Azure Cosmos DB ist für dieses Szenario gut geeignet, da das Lesen der empfohlenen Artikel für einen Benutzer nur mit einer geringen Latenz verbunden ist (10 ms, 99. Perzentil).
- Maschinelles Lernen. Dieser Dienst wird verwendet, um Machine Learning-Modelle nachzuverfolgen und zu verwalten und diese dann zu verpacken und in einer skalierbaren AKS-Umgebung bereitzustellen.
- Microsoft Recommenders: Dieses Open-Source-Repository enthält Hilfsprogrammcode und Beispiele, um Benutzer beim Einstieg in das Erstellen, Evaluieren und Operationalisieren eines Empfehlungssystems zu unterstützen.
Szenariodetails
Diese Architektur kann für die meisten Empfehlungsmodulszenarien generalisiert werden, z.B. Empfehlungen für Produkte, Filme und Nachrichten.
Mögliche Anwendungsfälle
Szenario: Ein Medienunternehmen möchte für seine Benutzer Empfehlungen zu Filmen bzw. Videos bereitstellen. Durch die Bereitstellung von personalisierten Empfehlungen kann die Organisation mehrere Geschäftsziele wie höhere Durchklickraten, bessere Kundenbindung auf der Website und höhere Kundenzufriedenheit erreichen.
Diese Lösung ist für den Einzelhandel sowie für die Medien- und Unterhaltungsbranche optimiert.
Überlegungen
Diese Überlegungen beruhen auf den Säulen des Azure Well-Architected Frameworks, d. h. einer Reihe von Grundsätzen, mit denen die Qualität von Workloads verbessert werden kann. Weitere Informationen finden Sie unter Microsoft Azure Well-Architected Framework.
Im Artikel Batchbewertung von Spark-Modellen in Azure Databricks wird eine Referenzarchitektur beschrieben, die Spark und Azure Databricks zum Ausführen geplanter Batchbewertungsprozesse verwendet. Es wird empfohlen, diesen Ansatz zum Generieren neuer Empfehlungen zu verwenden.
Effiziente Leistung
Leistungseffizienz ist die Fähigkeit Ihrer Workload, auf effiziente Weise eine den Anforderungen der Benutzer entsprechende Skalierung auszuführen. Weitere Informationen finden Sie unter Übersicht über die Säule „Leistungseffizienz“.
Die Leistung ist für Echtzeitempfehlungen ein wichtiger Aspekt, da sich Empfehlungen normalerweise auf dem kritischen Pfad einer Benutzeranforderung auf Ihrer Website befinden.
Dank der Kombination aus AKS und Azure Cosmos DB stellt diese Architektur einen guten Ausgangspunkt zum Bereitstellen von Empfehlungen für eine mittlere Workload bei minimalem Mehraufwand dar. Bei einem Auslastungstest mit 200 gleichzeitigen Benutzern werden bei dieser Architektur Empfehlungen mit einer durchschnittlichen Latenz von ca. 60 ms bereitgestellt, und der Durchsatz erreicht 180 Anforderungen pro Sekunde. Der Auslastungstest wurde mit der Standardkonfiguration für die Bereitstellung durchgeführt (drei AKS-Cluster vom Typ „D3 v2“ mit 12 vCPUs, 42 GB Arbeitsspeicher und 11.000 Anforderungseinheiten (Request Units, RUs) pro Sekunde für Azure Cosmos DB).
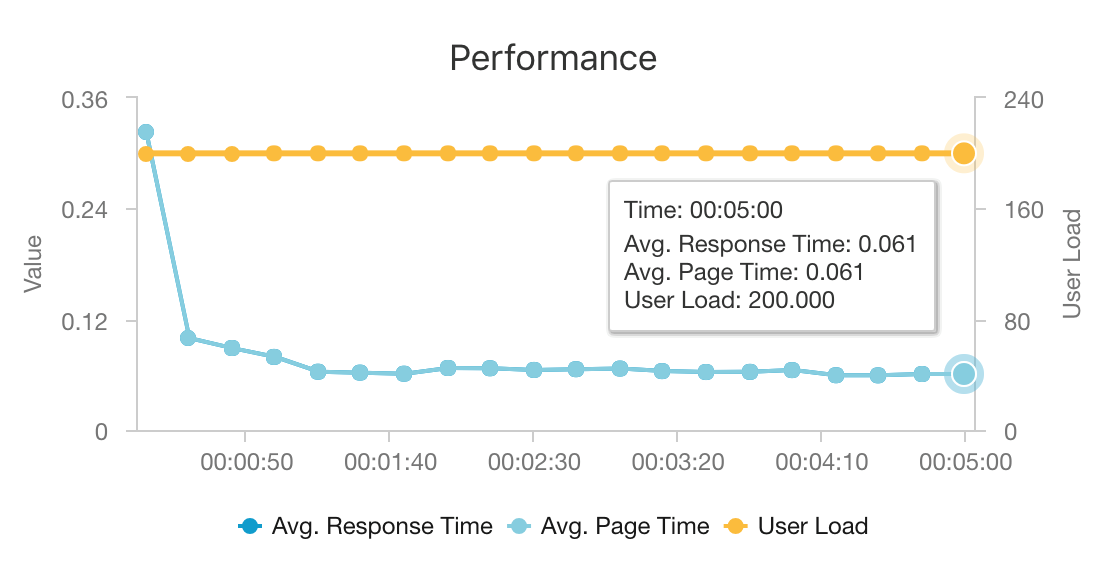
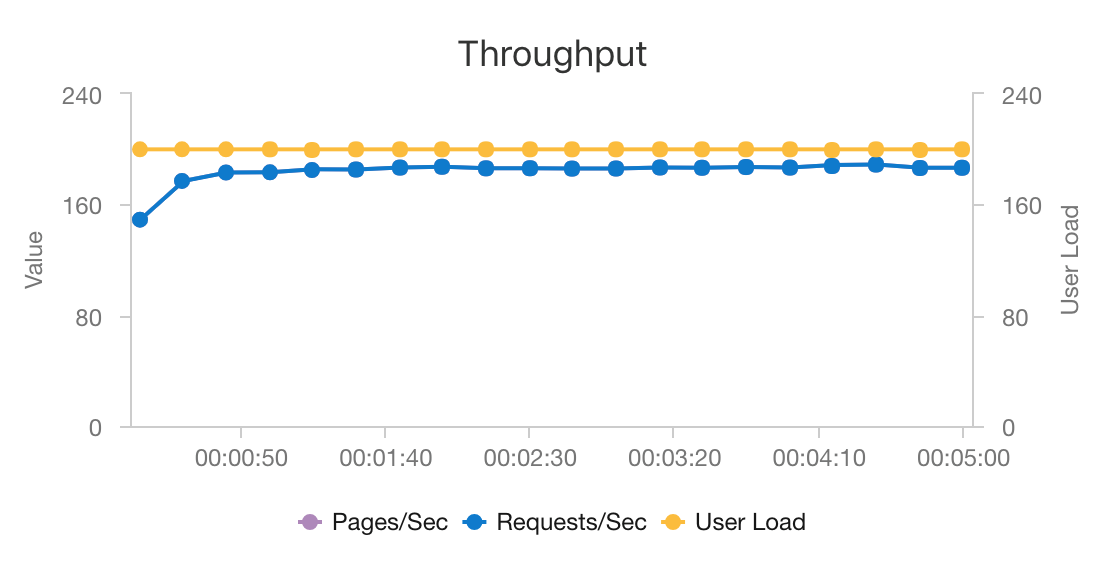
Der Einsatz von Azure Cosmos DB wird empfohlen, weil dieser Dienst sofort global verteilt werden kann und nützlich ist, um alle Datenbankanforderungen Ihrer App zu erfüllen. Wenn Sie die Latenz leicht reduzieren möchten, können Sie anstelle von Azure Cosmos DB auch die Nutzung von Azure Cache for Redis für die Bereitstellung der Suche erwägen. Mit Azure Cache for Redis kann die Leistung von Systemen verbessert werden, für die eine starke Abhängigkeit von Daten in Back-End-Speichern besteht.
Skalierbarkeit
Wenn Sie die Verwendung von Spark nicht eingeplant haben oder über eine kleinere Workload verfügen, für die keine Verteilung erforderlich ist, können Sie auch überlegen, eine Data Science Virtual Machine-Instanz (DSVM) anstelle von Azure Databricks zu verwenden. Eine DSVM-Instanz ist ein virtueller Azure-Computer mit Deep Learning-Frameworks und -Tools für maschinelles Lernen und Data Science. Wie bei Azure Databricks können alle Modelle, die Sie auf einer DSVM-Instanz erstellen, über Machine Learning als Dienst in AKS operationalisiert werden.
Stellen Sie während des Trainings in Azure Databricks einen größeren Spark-Cluster mit fester Größe bereit, oder konfigurieren Sie die automatische Skalierung. Wenn die automatische Skalierung aktiviert ist, überwacht Databricks die Auslastung Ihres Clusters und skaliert bei Bedarf hoch oder herunter. Stellen Sie einen größeren Cluster bereit bzw. skalieren Sie auf, falls Sie über eine hohe Datengröße verfügen und die Verarbeitungsdauer in Bezug auf die Datenaufbereitungs- oder Modellierungsaufgaben verringern möchten.
Skalieren Sie den AKS-Cluster, um Ihre Anforderungen an die Leistung und den Durchsatz zu erfüllen. Achten Sie darauf, dass Sie die Anzahl von Pods hochskalieren, um den Cluster vollständig zu nutzen, und die Knoten des Clusters zu skalieren, um den Bedarf Ihres Diensts zu erfüllen. Sie können die automatische Skalierung auch für einen AKS-Cluster festlegen. Weitere Informationen finden Sie im Cluster Bereitstellen eines Modells in einem Azure Kubernetes Service.
Schätzen Sie zum Verwalten der Azure Cosmos DB-Leistung die Anzahl von Lesevorgängen pro Sekunde, und stellen Sie die erforderliche Anzahl von RUs pro Sekunde (Durchsatz) bereit. Befolgen Sie die bewährten Methoden für Partitionierung und horizontale Skalierung.
Kostenoptimierung
Bei der Kostenoptimierung geht es um die Suche nach Möglichkeiten, unnötige Ausgaben zu reduzieren und die Betriebseffizienz zu verbessern. Weitere Informationen finden Sie unter Übersicht über die Säule „Kostenoptimierung“.
Die Hauptkostenpunkte dieses Szenarios sind:
- Die Azure Databricks-Clustergröße, die für das Training benötigt wird.
- Die AKS-Clustergröße, die für die Erfüllung Ihrer Leistungsanforderungen erforderlich ist.
- Azure Cosmos DB-Anforderungseinheiten zur Erfüllung Ihrer Leistungsanforderungen.
Behalten Sie die Azure Databricks-Kosten im Griff, indem Sie weniger häufig erneut trainieren und den Spark-Cluster deaktivieren, wenn er nicht benötigt wird. Die Kosten für AKS und Azure Cosmos DB richten sich nach dem Durchsatz und der Leistung Ihrer Website und fallen je nach Datenverkehr auf Ihrer Website höher oder niedriger aus.
Bereitstellen dieses Szenarios
Stellen Sie diese Architektur gemäß den Azure Databricks-Anweisungen im Einrichtungsdokument bereit. Dazu sind kurz gesagt folgende Schritte erforderlich:
- Erstellen Sie einen Azure Databricks-Arbeitsbereich.
- Erstellen Sie in Azure Databricks einen neuen Cluster mit der folgenden Konfiguration:
- Clustermodus: Standard
- Databricks-Runtimeversion: 4.3 (enthält Apache Spark 2.3.1 und Scala 2.11)
- Python-Version: 3
- Treibertyp: Standard_DS3_v2
- Workertyp: Standard_DS3_v2 (Minimum und Maximum je nach Bedarf)
- Automatische Beendigung: (gemäß Anforderung)
- Spark-Konfiguration: (gemäß Anforderung)
- Umgebungsvariablen: (gemäß Anforderung)
- Erstellen Sie ein persönliches Zugriffstoken innerhalb des Azure Databricks-Arbeitsbereichs. Ausführliche Informationen finden Sie in der Dokumentation zur Azure Databricks-Authentifizierung.
- Klonen Sie das Repository Microsoft Recommenders in einer Umgebung, in der Sie Skripts ausführen können (z. B. auf Ihrem lokalen Computer).
- Gehen Sie gemäß den Setupanweisungen für die Schnellinstallation vor, um in Azure Databricks die relevanten Bibliotheken zu installieren.
- Gehen Sie gemäß den Setupanweisungen für die Schnellinstallation vor, um Azure Databricks für die Operationalisierung vorzubereiten.
- Importieren Sie das Notebook „ALS Movie Operationalization“ in Ihren Arbeitsbereich. Führen Sie nach der Anmeldung bei Ihrem Azure Databricks-Arbeitsbereich die folgenden Schritte aus:
- Klicken Sie auf der linken Seite des Arbeitsbereichs auf Home.
- Klicken Sie in Ihrem Basisverzeichnis mit der rechten Maustaste auf den weißen Bereich. Wählen Sie Importieren aus.
- Wählen Sie URL aus, und fügen Sie Folgendes in das Textfeld ein:
https://github.com/Microsoft/Recommenders/blob/main/examples/05_operationalize/als_movie_o16n.ipynb - Klicken Sie auf Importieren.
- Öffnen Sie das Notebook in Azure Databricks, und fügen Sie den konfigurierten Cluster an.
- Führen Sie das Notebook aus, um die für die Erstellung einer Empfehlungs-API erforderlichen Azure-Ressourcen zu erstellen. Über die API werden die zehn besten Filmempfehlungen für einen Benutzer bereitgestellt.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautoren:
- Miguel Fierro | Principal Data Scientist Manager
- Nikhil Joglekar | Product Manager, Azure-Algorithmen und Data Science
Melden Sie sich bei LinkedIn an, um nicht öffentliche LinkedIn-Profile anzuzeigen.
Nächste Schritte
- Erstellen einer Echtzeitempfehlungs-API
- Was ist Azure Databricks?
- Azure Kubernetes Service (AKS)
- Willkommen bei Azure Cosmos DB
- Was ist Azure Machine Learning?