Verbessern Ihres Custom Vision-Modells
In diesem Leitfaden erfahren Sie, wie Sie die Qualität Ihres Modells für Custom Vision verbessern. Die Qualität Ihrer Klassifizierung oder Objekterkennung hängt von der Menge, Qualität und Vielseitigkeit der von Ihnen bereitgestellten getaggten Daten sowie von der Ausgewogenheit des gesamten Datasets ab. Ein gutes Modell verfügt über ein ausgewogenes Trainingsdataset, das repräsentativ für das ist, was an das Modell übermittelt wird. Solche Modelle werden iterativ erstellt. Üblicherweise werden einige Trainingsrunden durchlaufen, um die erwarteten Ergebnisse zu erzielen.
Im Folgenden wird ein allgemeines Muster erläutert, das Ihnen dabei hilft, ein genaueres Modell zu trainieren:
- Erste Trainingsrunde
- Hinzufügen weiterer Bilder und Ausgleichen von Daten; erneutes Trainieren
- Hinzufügen von Bildern mit Unterschieden hinsichtlich Hintergrund, Beleuchtung, Objektgröße, Kamerawinkel und Ausführung; erneutes Trainieren
- Verwenden neuer Bilder, um Vorhersagen zu testen
- Ändern der vorhandenen Trainingsdaten gemäß der Vorhersageergebnisse
Verhindern der Überanpassung
Manchmal lernt ein Modell, Vorhersagen basierend auf zufälligen Merkmalen zu treffen, die Ihre Bilder gemeinsam haben. Wenn Sie z.B. eine Klassifizierung zur Unterscheidung von Äpfeln und Zitrusfrüchten erstellen und dafür Bilder von Äpfeln in Händen und Zitrusfrüchten auf weißen Tellern verwendet haben, wird die Klassifizierung möglicherweise dem Unterschied zwischen Händen und weißen Tellern gegenüber dem Unterschied zwischen Äpfeln und Zitrusfrüchten einen ungerechtfertigten Schwerpunkt einräumen.
Stellen Sie zum Beheben dieses Problems Bilder mit verschiedenen Blickwinkeln, Hintergründen, Objektgrößen, Gruppen und anderen Variationen bereit. In den folgenden Abschnitten werden diese Konzepte näher erläutert.
Datenmenge
Die Anzahl der Trainingsbilder ist der wichtigste Faktor für Ihr Dataset. Es sollten mindestens 50 Bilder pro Bezeichnung als Ausgangspunkt verwendet werden. Mit weniger Bildern besteht ein höheres Risiko der Überanpassung, und während Ihre Leistungszahlen vermeintlich auf gute Qualität hindeuten, könnte Ihr Modell mit echten Daten im Konflikt stehen.
Datenausgleich
Sie müssen auch die relativen Mengen Ihrer Trainingsdaten berücksichtigen. Beispielsweise hat die Verwendung von 500 Bildern für eine Bezeichnung und 50 Bildern für eine andere Bezeichnung ein unausgeglichenes Trainingsdataset zur Folge. Dadurch ist das Modell bei der Vorhersage einer Bezeichnung genauer als bei der Vorhersage einer anderen. Die besten Ergebnisse werden Sie wahrscheinlich erzielen, wenn zwischen der Bezeichnung mit den wenigsten Bildern und der Bezeichnung mit den meisten Bildern ein Verhältnis von 1:2 besteht. Wenn z.B. für die Bezeichnung mit den meisten Bildern 500 Bilder vorhanden sind, sollte die Bezeichnung mit der geringsten Bildanzahl mindestens 250 Bilder für das Training enthalten.
Datenvielzahl
Verwenden Sie unbedingt Bilder, die für die Elemente repräsentativ sind, die während der normalen Nutzung an die Klassifizierung übermittelt werden. Andernfalls könnte Ihr Modell lernen, Vorhersagen basierend auf zufälligen Merkmalen zu treffen, die Ihre Bilder gemeinsam haben. Wenn Sie z.B. eine Klassifizierung zur Unterscheidung von Äpfeln und Zitrusfrüchten erstellen und dafür Bilder von Äpfeln in Händen und Zitrusfrüchten auf weißen Tellern verwendet haben, wird die Klassifizierung möglicherweise dem Unterschied zwischen Händen und weißen Tellern gegenüber dem Unterschied zwischen Äpfeln und Zitrusfrüchten einen ungerechtfertigten Schwerpunkt einräumen.

Beziehen Sie zum Beheben dieses Problems eine große Vielfalt von Bildern ein, um sicherzustellen, dass Ihr Modell gut generalisieren kann. Im Folgenden finden Sie einige Möglichkeiten, um Ihren Trainingssatz vielseitiger zu machen:
Hintergrund: Stellen Sie die Bilder Ihres Objekts vor andere Hintergründe. Fotos in natürlichen Kontexten eignen sich besser als Fotos vor neutralen Hintergründen, da erstere weitere Informationen für die Klassifizierung bereitstellen.

Beleuchtung: Stellen Sie Bilder mit unterschiedlicher Beleuchtung bereit (also mit Blitz, hohem Belichtungswert usw.), insbesondere dann, wenn die für die Vorhersage verwendeten Bilder unterschiedlich ausgeleuchtet sind. Es ist auch hilfreich, Bilder mit unterschiedlichen Werten hinsichtlich Sättigung, Farbton und Helligkeit zu verwenden.

Objektgröße: Stellen Sie Bilder bereit, in denen die Objekte in Größe und Anzahl variieren (z.B. ein Foto eines Bündels Bananen und eine Nahaufnahme einer einzelnen Banane). Durch unterschiedliche Objektgrößen kann die Klassifizierung besser generalisieren.

Kamerawinkel: Stellen Sie Bilder bereit, die aus verschiedenen Kamerawinkeln aufgenommen wurden. Wenn alternativ all Ihre Fotos mit fest montierten Kameras (beispielsweise Überwachungskameras) aufgenommen werden müssen, stellen Sie zur Vermeidung einer Überanpassung sicher, dass Sie jedem regelmäßig auftretenden Objekt eine andere Bezeichnung zuweisen – wobei unabhängige Objekte (wie z. B. Laternenpfähle) als Schlüsselmerkmal interpretiert werden.

Ausführung: Stellen Sie Bilder verschiedener Ausführungen der gleichen Klasse bereit (z.B. unterschiedliche Varianten der gleichen Frucht). Wenn Sie jedoch über Objekte in erheblich unterschiedlichen Ausführungen verfügen (z.B. Micky Maus und eine echte Maus), sollten Sie diese als separate Klassen bezeichnen, um ihre unterschiedlichen Merkmale besser darzustellen.

Als negativ klassifizierte Bilder (nur Klassifizierung)
Wenn Sie eine Bildklassifizierung verwenden, müssen Sie möglicherweise Negativbeispiele hinzufügen, um die Genauigkeit Ihrer Klassifizierung zu verbessern. Negativbeispiele sind Bilder, die zu keinen der anderen Tags passen. Wenn Sie diese Bilder hochladen, wenden Sie die spezielle Negativ-Bezeichnung auf sie an.
Objekterkennungen verarbeiten Negativbeispiele automatisch, da alle Bildbereiche außerhalb der festgelegten Begrenzungsrahmen als negativ angesehen werden.
Hinweis
Der Custom Vision Service unterstützt teilweise die automatische Verarbeitung von negativen Bildern. Wenn Sie beispielsweise eine Klassifizierung zur Unterscheidung von Trauben und Bananen erstellen und ein Bild eines Schuhs für die Vorhersage übermitteln, sollte die Klassifizierung dieses Bild in Bezug auf Trauben und Bananen mit nahezu 0 % bewerten.
Andererseits ist es in Fällen, in denen die negativen Bilder nur eine Variation der im Training verwendeten Bilder sind, wahrscheinlich, dass das Modell die negativen Bilder aufgrund der großen Ähnlichkeiten als eine bezeichnete Klasse klassifiziert. Falls Sie eine Klassifizierung zur Unterscheidung von Orangen und Grapefruits verwenden und ein Bild einer Clementine übermitteln, wird die Clementine ggf. als Orange eingestuft, da sich die Merkmale von Clementinen und Orangen stark ähneln. Wenn Ihre negativen Bilder dieser Art sind, raten wir Ihnen, mindestens ein zusätzliches Tag (z. B. Sonstiges) zu erstellen und die negativen Bilder während des Trainings mit diesem Tag zu bezeichnen, damit das Modell besser zwischen diesen Klassen unterscheiden kann.
Berücksichtigen von Verdeckung und Abschneiden (nur Objekterkennung)
Wenn Sie möchten, dass Ihre Objekterkennung abgeschnittene Objekte (Objekt ist teilweise nicht mehr im Bild) oder verdeckte Objekte (Objekt wird von einem anderen Objekt im Bild teilweise verdeckt) erkennt, müssen Sie Trainingsbilder einschließen, die diese Fälle abdecken.
Hinweis
Das Problem, dass Objekte von anderen Objekten verdeckt werden, ist nicht mit dem Überlappungsschwellenwert zu verwechseln, bei dem es sich um einen Parameter für die Bewertung der Modellleistung handelt. Der Schieberegler Overlap Threshold (Überlappungsschwellenwert) auf der Custom Vision-Website gibt an, wie stark sich ein vorhergesagter Begrenzungsrahmen und der richtige Begrenzungsrahmen überlappen müssen, damit eine Vorhersage als richtig angesehen wird.
Verwenden Sie Vorhersagebilder für das weitere Training
Wenn Sie Bilder an den Vorhersageendpunkt übermitteln, um das Modell zu verwenden oder zu testen, speichert der Custom Vision-Dienst diese Bilder. Sie können sie dann verwenden, um das Modell zu verbessern.
Öffnen Sie die Custom Vision-Webseite, navigieren Sie zu Ihrem Projekt, und klicken Sie auf die Registerkarte Predictions (Vorhersagen), um an die Klassifizierung übermittelte Bilder anzuzeigen. In der Standardansicht werden Bilder aus der aktuellen Iteration angezeigt. Sie können das Dropdownmenü Iteration verwenden, um Bilder anzuzeigen, die während früherer Iterationen gesendet wurden.
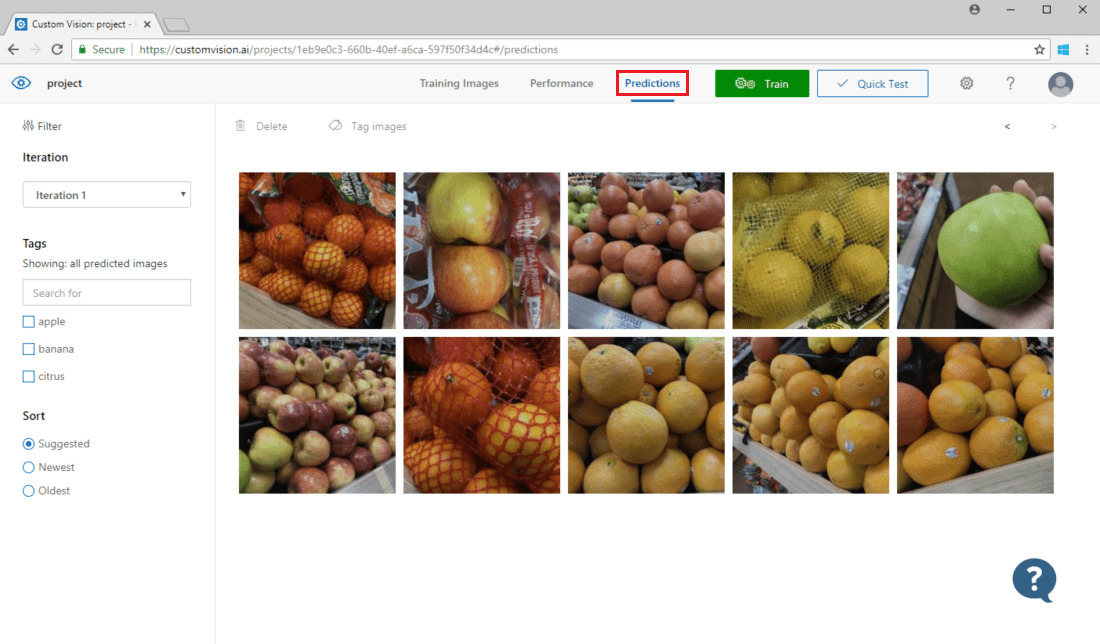
Zeigen Sie auf ein Bild, um die vom Modell vorhergesagten Tags anzuzeigen. Die Bilder sind so sortiert, dass diejenigen, die am meisten zur Verbesserung des Modells beitragen können, oben sind. Um eine andere Sortiermethode zu verwenden, nehmen Sie eine Auswahl im Abschnitt Sort vor.
Um Ihren vorhandenen Trainingsdaten ein Bild hinzuzufügen, wählen Sie das Bild und die richtigen Tags aus und klicken Sie auf Speichern und schließen. Das Bild wird aus dem Bereich Predictions (Vorhersagen) entfernt und dem Trainingsbildersatz hinzugefügt. Sie können es anzeigen, indem Sie die Registerkarte Training Images (Trainingsbilder) auswählen.
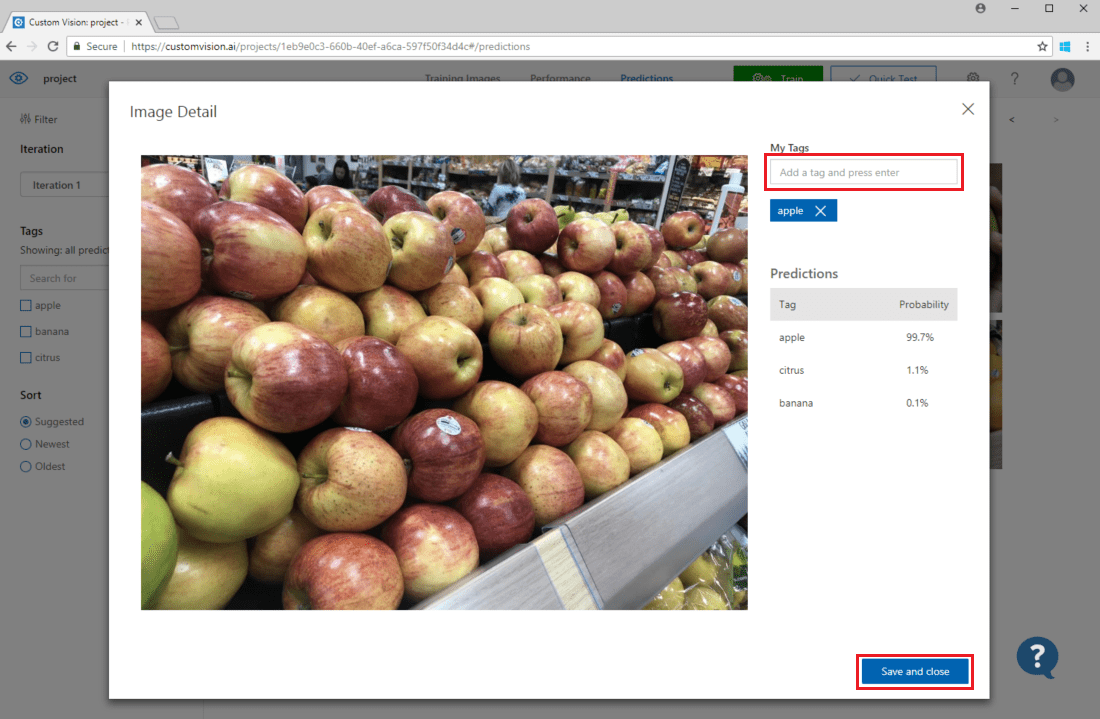
Klicken Sie dann auf Trainieren, um das Modell erneut zu trainieren.
Visuelle Überprüfung von Vorhersagen
Um Bildvorhersagen zu überprüfen, wechseln Sie zur Registerkarte Training Images (Trainingsbilder) , wählen Sie Ihre vorherige Trainingsiteration im Dropdownmenü Iteration aus, und überprüfen Sie eines oder mehrere Tags im Abschnitt Tags. In der Ansicht sollten nun die Bilder rot umrahmt sein, für die das Modell das angegebene Tag nicht ordnungsgemäß vorhergesagt hat.
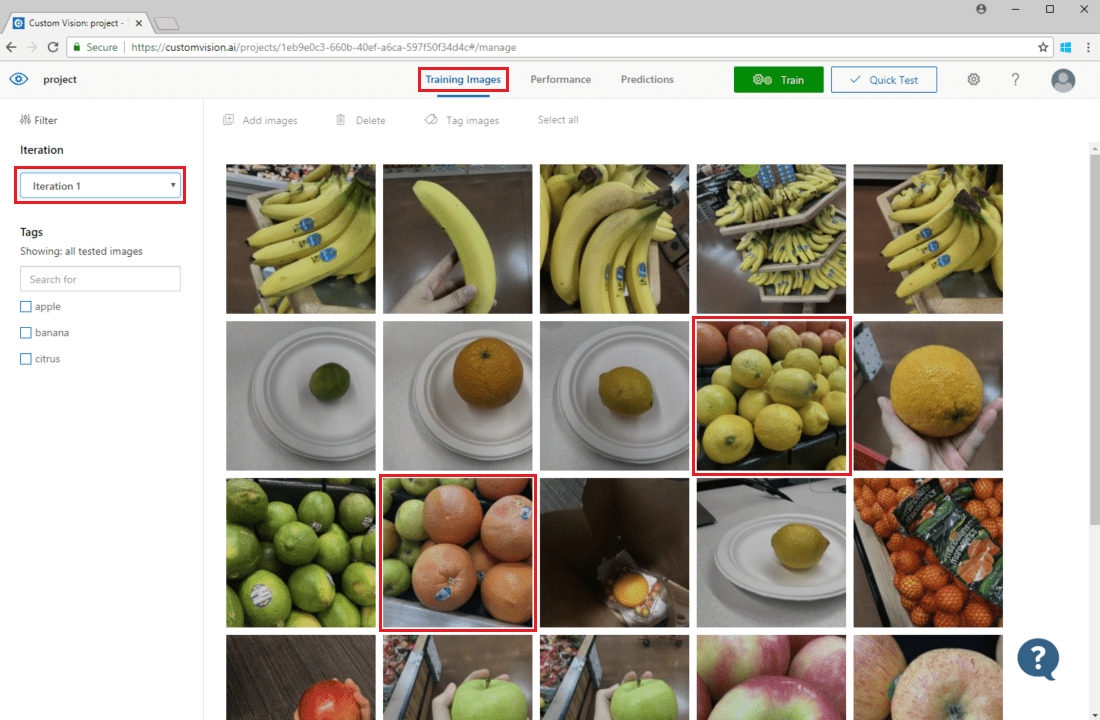
Bei der visuellen Untersuchung werden ggf. Muster identifiziert, die Sie dann korrigieren können, indem Sie zusätzliche Trainingsdaten hinzufügen oder vorhandene Trainingsdaten ändern. Ein Beispiel: Eine Klassifizierung zur Unterscheidung von Äpfeln und Limetten bezeichnet fälschlicherweise alle grünen Äpfel als Limetten. Sie können dieses Problem dann korrigieren, indem Sie Trainingsdaten hinzufügen und bereitstellen, die mit Tags versehene Bilder von grünen Äpfeln enthalten.
Nächste Schritte
In diesem Leitfaden haben Sie einige Verfahren kennengelernt, mit denen Sie die Genauigkeit Ihres benutzerdefinierten Bildklassifizierungsmodells oder Objekterkennungsmodells verbessern können. Finden Sie als Nächstes heraus, wie Sie Bilder programmgesteuert testen, indem Sie sie an die Vorhersage-API senden.