Die Zuverlässigkeitsbewertung einer Antwort
Wenn eine Benutzerabfrage mit einer Wissensdatenbank abgeglichen wird, gibt QnA Maker relevante Antworten zusammen mit einer Zuverlässigkeitsbewertung zurück. Diese Bewertung zeigt die Zuverlässigkeit dafür an, dass die Antwort die richtige Übereinstimmung für die jeweilige Benutzerabfrage ist.
Die Zuverlässigkeitsbewertung ist eine Zahl zwischen 0 und 100. Eine Bewertung von 100 ist wahrscheinlich eine genaue Übereinstimmung, während eine Bewertung von 0 bedeutet, dass keine passende Antwort gefunden wurde. Je höher die Bewertung, desto größer die Zuverlässigkeit der Antwort. Für eine bestimmte Abfrage können mehrere Antworten zurückgegeben werden. In diesem Fall werden die Antworten in der Reihenfolge abnehmender Zuverlässigkeitsbewertungen zurückgegeben.
Im folgenden Beispiel sehen Sie eine Fragen-und-Antworten-Entität mit 2 Fragen.

Für das oben genannte Beispiel können Sie Bewertungen wie den unten gezeigten Beispielbewertungsbereich für verschiedene Arten von Benutzerabfragen erwarten:
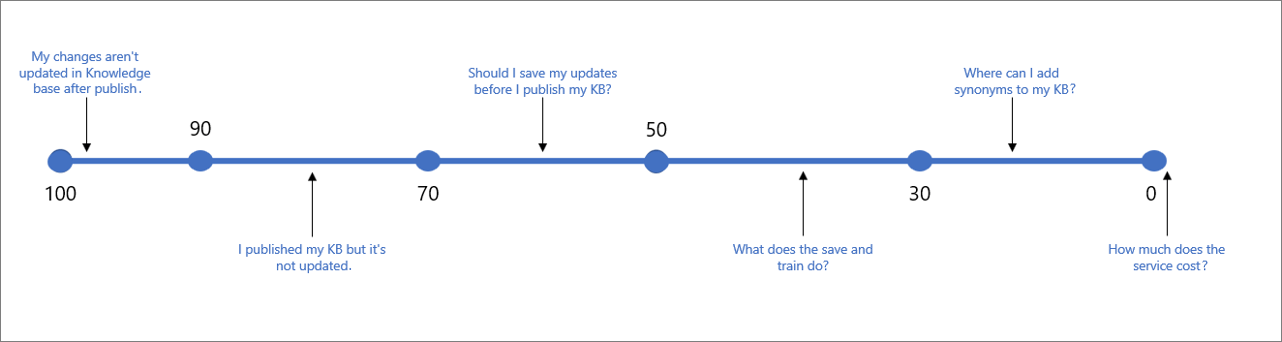
Die folgende Tabelle zeigt typische Zuverlässigkeit, die mit einer bestimmten Bewertung verknüpft ist.
| Bewertungswert | Bewertungsbedeutung | Beispielabfrage |
|---|---|---|
| 90–100 | Eine fast genaue Übereinstimmung von Benutzerabfrage und Wissensdatenbankfrage. | „Meine Änderungen werden in der Wissensdatenbank nach der Veröffentlichung nicht aktualisiert.“ |
| > 70 | Hohe Zuverlässigkeit – in der Regel eine gute Antwort, die die Abfrage des Benutzers vollständig beantwortet. | „Ich habe meine Wissensdatenbank veröffentlicht, aber sie wurde nicht aktualisiert.“ |
| 50–70 | Mittlere Zuverlässigkeit – in der Regel eine recht gute Antwort, die die Hauptabsicht der Benutzerabfrage beantworten sollte. | „Sollte ich meine Updates speichern, bevor ich meine Wissensdatenbank veröffentliche?“ |
| 30–50 | Niedrige Zuverlässigkeit – in der Regel eine relevante Antwort, die die Absicht des Benutzers teilweise beantwortet. | „Was macht ‚Speichern und trainieren‘?“ |
| < 30 | Sehr niedrige Zuverlässigkeit – beantwortet in der Regel nicht die Abfrage des Benutzers, enthält aber übereinstimmende Wörter oder Ausdrücke. | „Wo kann ich meiner Wissensdatenbank Synonyme hinzufügen?“ |
| 0 | Keine Übereinstimmung, weshalb die Antwort nicht zurückgegeben wird. | „Wie viel kostet der Dienst?“ |
Auswählen eines Bewertungsschwellenwerts
Die obigen Tabelle zeigt die Bewertungen, die in den meisten Wissensdatenbanken erwartet werden. Da aber jede Wissensdatenbank anders ist, verschiedene Typen von Wörtern enthält und mit unterschiedlichen Absichten und Zielen angelegt wird, empfehlen wir Ihnen, die Schwellenwerte zu testen und den auszuwählen, der für Sie am besten funktioniert. Standardmäßig ist der Schwellenwert auf 0 festgelegt, sodass alle möglichen Antworten zurückgegeben werden. Der empfohlene Schwellenwert, der mit den meisten Wissensdatenbanken funktionieren sollte, ist 50.
Bei der Auswahl Ihres Schwellenwerts sollten Sie die Ausgewogenheit zwischen Genauigkeit und Abdeckung berücksichtigen und Ihren Schwellenwert auf Grundlage Ihrer Anforderungen optimieren.
Wenn Genauigkeit (oder Exaktheit) für Ihr Szenario wichtiger ist, dann erhöhen Sie den Schwellenwert. Auf diese Weise ist jede von Ihnen zurückgegebene Antwort ein wesentlich ZUVERLÄSSIGERER Fall, und es ist wesentlich wahrscheinlicher, dass es die vom Benutzer gesuchte Antwort ist. In diesem Fall bleiben aber eventuell mehr Fragen unbeantwortet. Beispiel: Wenn Sie den Schwellenwert auf 70 festlegen, verpassen Sie möglicherweise einige doppeldeutige Beispiele wie „Was ist ‚Speichern und trainieren‘?“.
Wenn die Abdeckung (oder Abruf) wichtiger ist, und Sie so viele Fragen wie möglich beantworten möchten, auch wenn es nur einen partiellen Bezug zur Frage des Benutzers gibt, SENKEN Sie den Schwellenwert. Das bedeutet, dass möglicherweise mehr Fälle auftreten, bei denen die Antwort nicht die eigentliche Abfrage des Benutzers beantwortet, aber zumindest eine andere, immer noch relevante Antwort gibt. Beispiel: Wenn Sie den Schwellenwert auf 30 festlegen, geben Sie möglicherweise Antworten auf Abfragen wie „Wo kann ich meine Wissensdatenbank bearbeiten?“.
Hinweis
Neuere Versionen von QnA Maker beinhalten Verbesserungen der Bewertungslogik und wirken sich möglicherweise auf Ihren Schwellenwert aus. Achten Sie bei jeder Aktualisierung des Diensts darauf, den Schwellenwert ggf. zu testen und anzupassen. Sie können die Version Ihres QnA-Diensts hier überprüfen, und hier erfahren Sie, wie Sie die neuesten Updates erhalten.
Festlegen des Schwellenwerts
Sie legen den Schwellenwert als eine Eigenschaft im JSON-Code der GenerateAnswer-API fest. Das bedeutet, dass Sie ihn für jeden Aufruf von GenerateAnswer festlegen müssen.
Im Bot Framework legen Sie die Bewertung als Teil des options-Objekts mit C# oder Node.js fest.
Verbessern von Zuverlässigkeitsbewertungen
Um die Zuverlässigkeitsbewertung einer bestimmten Antwort auf eine Benutzerabfrage zu verbessern, können Sie der Wissensdatenbank die Benutzerabfrage als alternative Frage für diese Antwort hinzufügen. Sie können auch Wortvarianten verwenden, bei denen die Groß- und Kleinschreibung nicht berücksichtigt wird, um Ihrer Wissensdatenbank Synonyme für Schlüsselwörter hinzuzufügen.
Ähnliche Zuverlässigkeitsbewertungen
Wenn mehrere Antworten eine ähnliche Zuverlässigkeitsbewertung aufweisen, ist es wahrscheinlich, dass die Abfrage zu allgemein war und daher mit gleicher Wahrscheinlichkeit mit mehreren Antworten übereinstimmt. Versuchen Sie, Ihre Fragen und Antworten (Questions and Answers, QnAs) besser zu strukturieren, damit jede QnA-Entität eine eindeutige Absicht ausdrückt.
Unterschiede bei der Zuverlässigkeitsbewertung zwischen Test und Produktion
Die Zuverlässigkeitsbewertung einer Antwort kann zwischen der Testversion und der veröffentlichten Version der Wissensdatenbank geringfügig variieren, auch wenn der Inhalt identisch ist. Das liegt daran, dass sich die Inhalte der Test- und der veröffentlichten Wissensdatenbank in verschiedenen Azure KI Search-Indizes befinden.
Der Testindex enthält alle QnA-Paare Ihrer Wissensdatenbanken. Wenn Sie den Testindex abfragen, gilt die Abfrage für den gesamten Index, und die Ergebnisse sind auf die Partition für diese spezifische Wissensdatenbank beschränkt. Wenn die Ergebnisse der Testabfrage negative Auswirkungen auf die Fähigkeit zum Überprüfen der Wissensdatenbank haben, können Sie Folgendes tun:
- Organisieren Sie Ihre Wissensdatenbank wie folgt:
- 1 Ressource beschränkt auf 1 KB: Beschränken Sie Ihre einzelne QnA-Ressource (und den resultierenden Azure KI Search-Testindex) auf eine einzelne Wissensdatenbank.
- 2 Ressourcen – 1 für Tests, 1 für die Produktion: Nutzen Sie zwei QnA Maker-Ressourcen, eine für Tests (mit eigenen Test- und Produktionsindizes) und eine für das Produkt (ebenfalls mit eigenen Test- und Produktionsindizes).
- Verwenden Sie immer dieselben Parameter, z. B. top, wenn Sie Ihre Test- und Produktionswissensdatenbank abfragen.
Wenn Sie eine Wissensdatenbank veröffentlichen, werden die Frage-Antwort-Inhalte Ihrer Wissensdatenbank aus dem Testindex in einen Produktionsindex in Azure Search verschoben. Sehen Sie sich an, wie der Vorgang Veröffentlichen funktioniert.
Wenn Sie über eine Wissensdatenbank in verschiedenen Regionen verfügen, verwendet jede Region einen eigenen Azure KI Search-Index. Da verschiedene Indizes verwendet werden, werden die Ergebnisse nicht genau gleich sein.
Keine Übereinstimmung gefunden
Wenn das Rangfolgemodul keine gute Übereinstimmung findet, wird die Zuverlässigkeitsbewertung „0,0“ oder „Keine“ zurückgegeben, und die Standardantwort lautet „Keine gute Übereinstimmung in der KB gefunden“. Sie können diese Standardantwort im Bot- oder Anwendungscode, der den Endpunkt aufruft, überschreiben. Alternativ können Sie die überschriebene Antwort auch in Azure festlegen, wodurch die Standardeinstellung für alle in einem bestimmten QnA Maker-Dienst bereitgestellten Wissensdatenbanken geändert wird.