Trainieren Ihres professionellen Sprachmodells
In diesem Artikel erfahren Sie, wie Sie eine benutzerdefinierte neuronale Stimme über das Speech Studio-Portal trainieren.
Wichtig
Das benutzerdefinierte neuronale Stimmtraining ist aktuell nur in einigen Regionen verfügbar. Nachdem Ihr Sprachmodell in einer unterstützten Region trainiert wurde, können Sie es nach Bedarf in eine Speech-Ressource in einer anderen Region kopieren. Weitere Informationen finden Sie in den Fußnoten in der Tabelle für Azure Cognitive Service für Speech.
Die Trainingsdauer hängt von der Menge der verwendeten Daten ab. Das Trainieren einer benutzerdefinierten neuronalen Stimme dauert im Durchschnitt etwa 40 Computestunden. Benutzer mit einem Standard-Abonnement (S0) können vier Stimmen gleichzeitig trainieren. Wenn das Limit erreicht wurde, warten Sie, bis der Trainingsvorgang mindestens eines Stimmmodells beendet wurde, und versuchen Sie es dann noch mal.
Hinweis
Zwar unterscheidet sich die Gesamtanzahl der benötigten Stunden je nach Trainingsmethode, doch gilt für alle der gleiche Preis pro Einheit. Weitere Informationen finden Sie unter Preisdetails zum benutzerdefinierten neuronalen Training.
Auswählen einer Trainingsmethode
Nachdem Sie Ihre Datendateien überprüft haben, können Sie daraus Ihr benutzerdefiniertes neuronales Stimmmodell erstellen. Wenn Sie eine benutzerdefinierte neuronale Stimme erstellen, können Sie sie mit einer der folgenden Methoden trainieren:
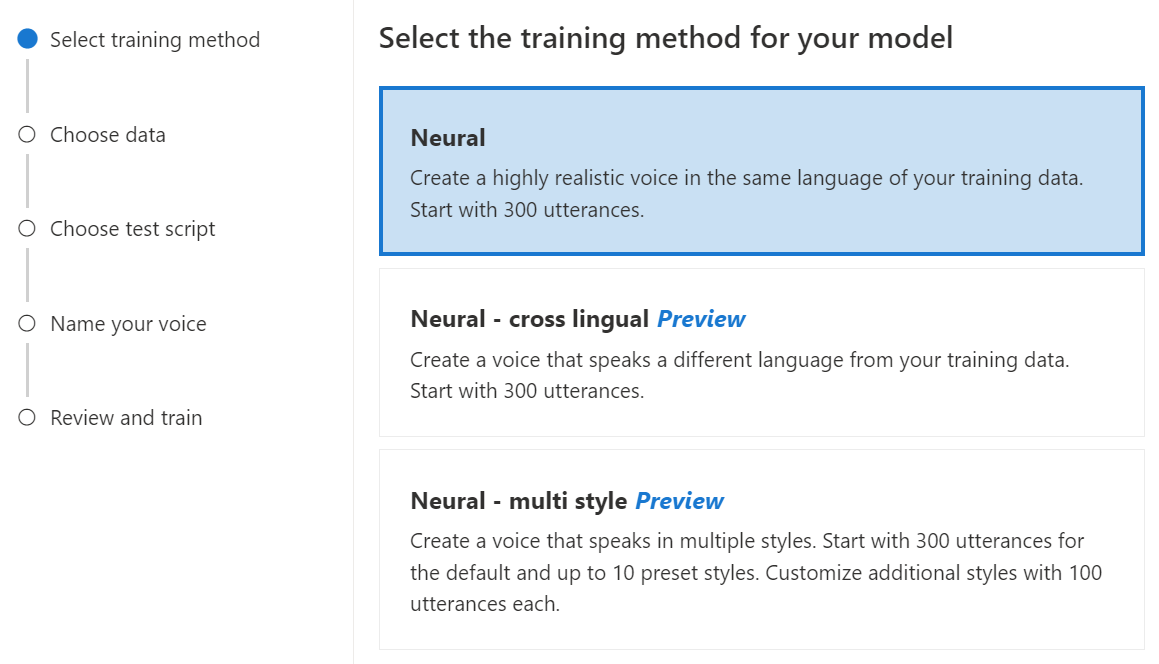
Neuronal: Erstellen einer Stimme in der Sprache Ihrer Trainingsdaten.
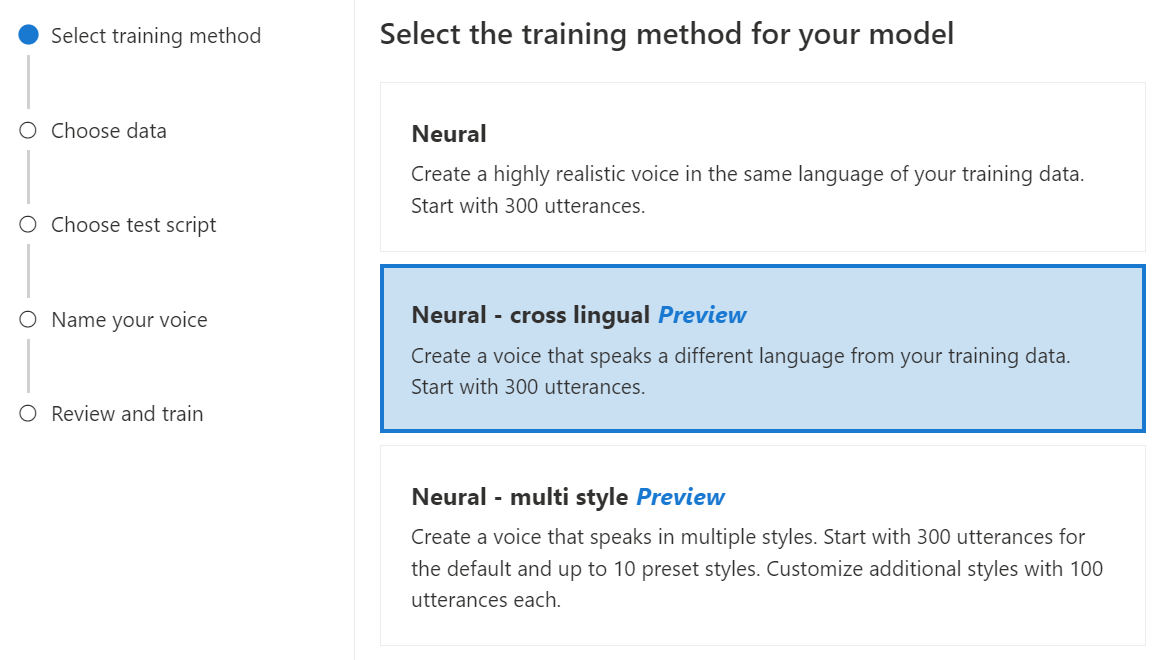
Neuronal - sprachübergreifend: Erstellen Sie eine Stimme, die eine andere Sprache spricht als Ihre Trainingsdaten. Beispielsweise können Sie mit den
zh-CNTrainingsdaten eine Stimme erstellen, dieen-USspricht.Die Sprache der Trainingsdaten und die Zielsprache müssen beide zu den Sprachen zählen, für die sprachübergreifendes Stimmtraining unterstützt wird. Sie brauchen keine Trainingsdaten in der Zielsprache vorzubereiten, aber Ihr Testskript muss in der Zielsprache abgefasst sein.
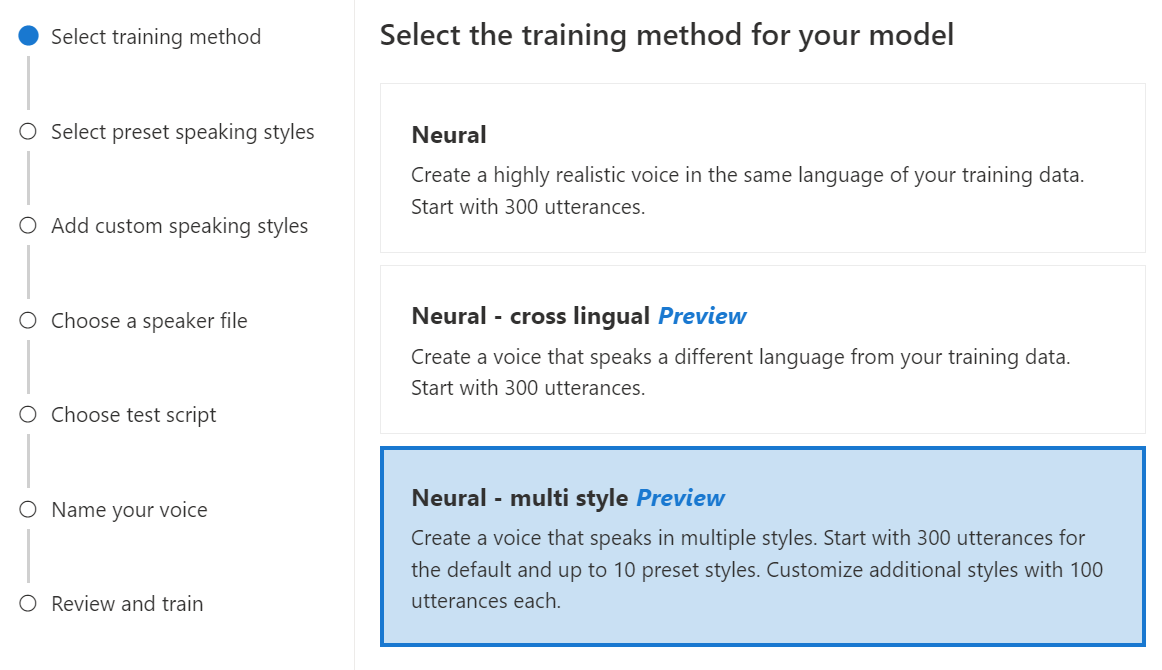
Neuronal – mehrformatig: Erstellen Sie eine benutzerdefinierte neuronale Stimme, die in mehreren Stillagen und Emotionen spricht, ohne neue Trainingsdaten hinzuzufügen. Stimmen mit mehreren Stilen eignen sich für Videospielfiguren, Konversations-Chatbots, Hörbücher, Inhaltslesemodule und mehr.
Um eine Stimme mit mehreren Stilen zu erstellen, müssen Sie allgemeine Trainingsdaten vorbereiten, die mindestens 300 Äußerungen umfassen. Wählen Sie mindestens einen voreingestellten Zielsprechstil aus. Sie können auch mehrere benutzerdefinierte Stile erstellen, indem Sie für dieselbe Stimme Stilbeispiele mit mindestens 100 Äußerungen pro Stil als zusätzliche Trainingsdaten bereitstellen. Die unterstützten voreingestellten Stile variieren je nach Sprache. Weitere Informationen finden Sie unter Verfügbare voreingestellte Stile für verschiedene Sprachen.
Die Sprache der Trainingsdaten muss zu den unterstützten Sprachen für das Training zählen, das benutzerdefinierte neuronale Stimmen betrifft, sprachübergreifend ist oder mehrere Stile umfasst.
Trainieren Ihres benutzerdefinierten neuronalen Stimmmodells
Führen Sie zum Erstellen einer benutzerdefinierten neuronalen Stimme in Speech Studio diese Schritte für eine der folgenden Methoden aus:
Melden Sie sich in Speech Studio an.
Wählen Sie Custom Voice><Name Ihres Projekts>>Trainingsmodell>Neues Modell trainieren aus.
Wählen Sie Neuronal als Trainingsmethode für Ihr Modell aus, und wählen Sie dann Weiter aus. Informationen zur Verwendung einer anderen Trainingsmethode finden Sie unter Neuronal – sprachübergreifend oder Neuronal – mehrformatig.
Wählen Sie eine Version des Trainingsrezepts für Ihr Modell aus. Die neueste Version ist standardmäßig ausgewählt. Die unterstützten Features und die Trainingszeit können sich je nach Version unterscheiden. Normalerweise wird die aktuelle Version empfohlen. In einigen Fällen können Sie eine frühere Version auswählen, um die Trainingsdauer zu verkürzen. Weitere Informationen zu zweisprachigem Training und zu Unterschieden zwischen Gebietsschemas finden Sie unter Zweisprachiges Training.
Wählen Sie die Daten aus, die Sie für das Training verwenden möchten. Doppelte Audionamen werden aus dem Training entfernt. Stellen Sie sicher, dass die ausgewählten Daten nicht die gleichen Audionamen in mehreren ZIP-Dateien enthalten.
Sie können für das Training nur erfolgreich verarbeitete Datasets auswählen. Überprüfen Sie den Datenverarbeitungsstatus, wenn Ihr Trainingssatz nicht in der Liste angezeigt wird.
Wählen Sie eine Sprecherdatei mit der Darbietung Ihres Sprechers aus, die dem Sprecher in Ihren Trainingsdaten entspricht.
Wählen Sie Weiter aus.
Bei jedem Training werden automatisch 100 Beispielaudiodateien generiert, damit Sie das Modell mit einem Standardskript testen können.
Optional können Sie auch Eigenes Testskript hinzufügen aktivieren und Ihr eigenes Testskript mit bis zu 100 Äußerungen bereitstellen, um das Modell ohne zusätzliche Kosten zu testen. Die generierten Audiodateien sind eine Kombination aus den automatischen Testskripts und benutzerdefinierten Testskripts. Weitere Informationen finden Sie unter Testskriptanforderungen.
Geben Sie einen Namen ein, um das Modell zu identifizieren. Wählen Sie den Namen sorgfältig aus. Der Modellname wird als Name der Stimme für Ihre Sprachsyntheseanforderung in der SDK- und SSML-Eingabe verwendet. Zulässig sind nur Buchstaben, Zahlen und einige wenige Satzzeichen. Verwenden Sie unterschiedliche Namen für unterschiedliche neuronale Stimmmodelle.
Geben Sie optional die Beschreibung ein, um das Modell leichter identifizieren zu können. Eine gängige Nutzung der Beschreibung besteht darin, die Namen der Daten festzuhalten, die Sie zum Erstellen des Modells verwendet haben.
Wählen Sie Weiter aus.
Überprüfen Sie die Einstellungen, und aktivieren Sie das Kontrollkästchen, um die Nutzungsbedingungen zu akzeptieren.
Wählen Sie Übermitteln aus, um mit dem Trainieren des Modells zu beginnen.
Zweisprachiges Training
Wenn Sie den Trainingstyp Neuronal auswählen, können Sie eine Stimme darauf trainieren, in mehreren Sprachen zu sprechen. Die Gebietsschemas zh-CN und zh-TW unterstützen das zweisprachige Training, sodass die Stimme sowohl Chinesisch als auch Englisch sprechen kann. Teilweise in Abhängigkeit von den Trainingsdaten kann die synthetisierte Stimme Englisch mit einem nativen englischen Akzent oder Englisch mit demselben Akzent wie die Trainingsdaten sprechen.
Hinweis
Um zu ermöglichen, dass eine Stimme im Gebietsschema zh-CN Englisch mit demselben Akzent wie in den Beispieldaten spricht, sollten Sie beim Erstellen eines Projekts Chinese (Mandarin, Simplified), English bilingual auswählen oder das Gebietsschema zh-CN (English bilingual) für die Trainingssatzdaten über die REST-API angeben.
Die folgende Tabelle enthält die Unterschiede zwischen den beiden Gebietsschemas:
| Speech Studio-Gebietsschema | REST-API-Gebietsschema | Unterstützung für zweisprachige Vorgänge |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Wenn Ihre Beispieldaten Englisch enthalten, spricht die synthetisierte Stimme Englisch mit einem nativen englischen Akzent anstelle desselben Akzents wie die Beispieldaten, unabhängig von der Menge der englischen Daten. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Wenn die synthetisierte Stimme Englisch mit demselben Akzent wie in den Beispieldaten sprechen soll, wird empfohlen, mehr als 10 % Daten in englischer Sprache in Ihren Trainingssatz einzuschließen. Andernfalls fällt der englische Sprachakzent möglicherweise nicht ideal aus. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Wenn Sie eine synthetisierte Stimme trainieren möchten, die Englisch mit demselben Akzent wie in Ihren Beispieldaten sprechen kann, stellen Sie sicher, mehr als 10 % Daten in englischer Sprache in Ihrem Trainingssatz bereitstellen. Andernfalls wird standardmäßig ein nativer englischer Akzent verwendet. Der Schwellenwert von 10 % wird basierend auf den Daten berechnet, die nach dem erfolgreichen Hochladen akzeptiert werden, nicht auf den Daten vor dem Hochladen. Wenn einige hochgeladene Daten in englischer Sprache aufgrund von Fehlern abgelehnt werden und der Schwellenwert von 10 % nicht erfüllt wird, erhält die synthetisierte Stimme standardmäßig einen nativen englischen Akzent. |
Verfügbare voreingestellte Stile für verschiedene Sprachen
In der folgenden Tabelle sind die verschiedenen voreingestellten Stile gemäß den verschiedenen Sprachen zusammengefasst.
| Sprechweise | Sprache (lokal) |
|---|---|
| Wütend | Englisch (Nordamerika) (en-US)Japanisch (Japan) ( ja-JP) 1Chinesisch (Mandarin, vereinfacht) ( zh-CN) 1 |
| Ruhig | Chinesisch (Mandarin, vereinfacht) (zh-CN) 1 |
| Chat | Chinesisch (Mandarin, vereinfacht) (zh-CN) 1 |
| Fröhlich | Englisch (Nordamerika) (en-US)Japanisch (Japan) ( ja-JP) 1Chinesisch (Mandarin, vereinfacht) ( zh-CN) 1 |
| Verärgert | Chinesisch (Mandarin, vereinfacht) (zh-CN) 1 |
| Aufgeregt | Englisch (Nordamerika) (en-US) |
| Ängstlich | Chinesisch (Mandarin, vereinfacht) (zh-CN) 1 |
| Freundlich | Englisch (Nordamerika) (en-US) |
| Hoffnungsvoll | Englisch (Nordamerika) (en-US) |
| Traurig | Englisch (Nordamerika) (en-US)Japanisch (Japan) ( ja-JP) 1Chinesisch (Mandarin, vereinfacht) ( zh-CN) 1 |
| Schreiend | Englisch (Nordamerika) (en-US) |
| Ernst | Chinesisch (Mandarin, vereinfacht) (zh-CN) 1 |
| Verängstigt | Englisch (Nordamerika) (en-US) |
| unfreundlich | Englisch (Nordamerika) (en-US) |
| Flüsternd | Englisch (Nordamerika) (en-US) |
1 Die neuronale Stimme ist in der öffentlichen Vorschau verfügbar. Stimmen in der öffentlichen Vorschauversion sind nur in drei Dienstregionen verfügbar: USA, Osten, Europa, Westen und Asien, Südosten.
In der Tabelle Modell trainieren wird ein neuer Eintrag angezeigt, der diesem neu erstellten Modell entspricht. Der Status gibt Aufschluss über den Fortschritt bei der Konvertierung Ihrer Daten in ein Stimmmodell, wie in dieser Tabelle beschrieben:
| State | Bedeutung |
|---|---|
| Verarbeitung | Ihr Stimmmodell wird erstellt. |
| Erfolgreich | Ihr Stimmmodell wurde erstellt und kann bereitgestellt werden. |
| Fehler | Beim Trainieren Ihres Stimmmodells ist ein Fehler aufgetreten. Die Ursache für den Fehler liegt möglicherweise in unerkannten Daten- oder Netzwerkproblemen. |
| Canceled | Das Training Ihres Stimmmodells wurde abgebrochen. |
Solange der Modellstatus In Bearbeitung ist, können Sie Training abbrechen auswählen, um das Training Ihres Stimmmodells abzubrechen. Dieses abgebrochene Training wird Ihnen nicht in Rechnung gestellt.
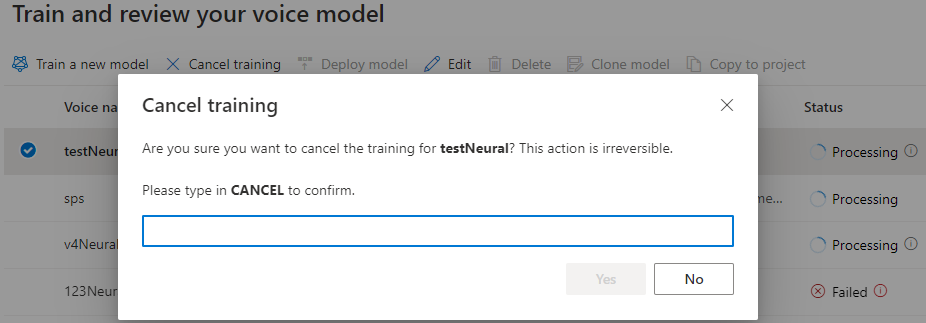
Nachdem Sie das Training des Modells erfolgreich abgeschlossen haben, können Sie die Modelldetails überprüfen und Ihr Stimmmodell testen.
Sie können das Tool Audioinhaltserstellung in Speech Studio verwenden, um Audioclips zu erstellen und Ihre bereitgestellte Stimme zu optimieren. Wenn dies für Ihre Stimme zutrifft, können Sie einen von mehreren Stilen auswählen.
Umbenennen des Modells
Wenn Sie das erstellte Modell umbenennen möchten, wählen Sie Modell klonen aus, um im aktuellen Projekt einen Klon des Modells mit einem anderen Namen zu erstellen.
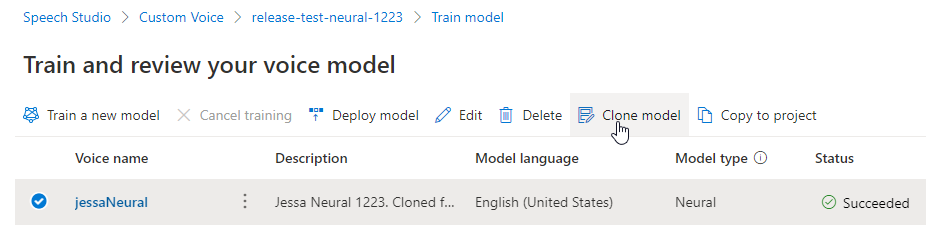
Geben Sie im Fenster Stimmmodell klonen den neuen Namen ein, und klicken Sie dann auf Übermitteln. Der Text Neuronal wird dem neuen Modellnamen automatisch als Suffix hinzugefügt.
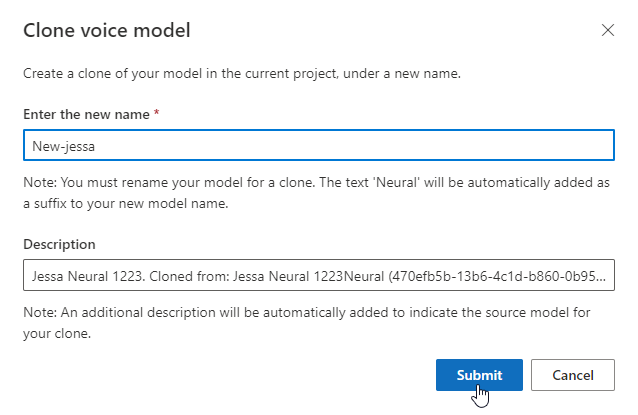
Testen Ihres Stimmmodells
Nach der erfolgreichen Erstellung des Stimmmodells können Sie die generierten Beispielaudiodateien verwenden, um es vor der Bereitstellung zu testen.
Die Qualität des Stimmmodells basiert auf zahlreichen Faktoren, wie etwa:
- der Größe der Trainingsdaten
- der Qualität der Aufzeichnung
- der Genauigkeit der Transkriptdatei
- der Eignung der aufgezeichneten Stimme in den Trainingsdaten für die gewünschte Persönlichkeit der Stimme im jeweiligen Anwendungsfall
Wählen Sie DefaultTests unter Testen aus, um sich die Beispielaudiodateien anzuhören. Die Standardtestbeispiele umfassen 100 Beispielaudiodateien, die während des Trainings automatisch generiert werden, um Sie beim Testen des Modells zu unterstützen. Zusätzlich zu diesen standardmäßig bereitgestellten 100 Audioclips werden die Äußerungen in Ihrem eigenen Testskript ebenfalls der Gruppe DefaultTests hinzugefügt. Dieser Zusatz umfasst höchstens 100 Äußerungen. Die Tests mit DefaultTests werden Ihnen nicht in Rechnung gestellt.
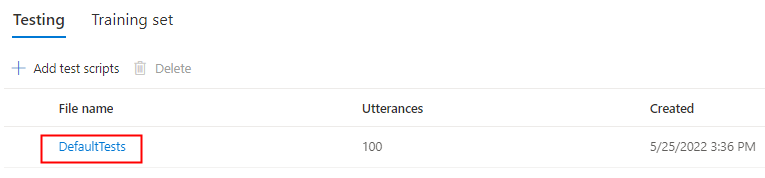
Wenn Sie Ihre eigenen Testskripts hochladen möchten, um Ihr Modell weiter zu testen, wählen Sie Testskripts hinzufügen aus, um ihr eigenes Testskript hochzuladen.
Überprüfen Sie vor dem Hochladen des Testskripts die Testskriptanforderungen. Die zusätzlichen Tests mit der Batchsynthese werden Ihnen auf der Grundlage der Anzahl der abrechenbaren Zeichen in Rechnung gestellt. Weitere Informationen finden Sie unter Preise für Azure KI Speech.
Wählen Sie unter Testskripts hinzufügen die Option Nach einer Datei suchen aus, um Ihr eigenes Skript auszuwählen, und wählen Sie dann Hinzufügen aus, um es hochzuladen.
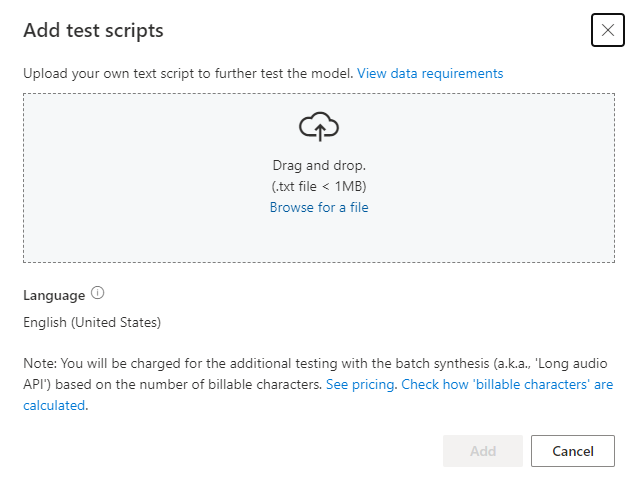
Testen von Skriptanforderungen
Das Testskript muss eine TXT-Datei und kleiner als 1 MB sein. Unterstützte Codierungsformate sind z. B. ANSI/ASCII, UTF-8, UTF-8-BOM, UTF-16-LE oder UTF-16-BE.
Im Gegensatz zu den Trainingstranskriptionsdateien sollte das Testskript keine Äußerungs-IDs enthalten. Dabei handelt es sich um die Dateinamen der einzelnen Äußerungen. Andernfalls werden die IDs ausgesprochen.
Hier sehen Sie ein Beispiel für Äußerungen in einer TXT-Datei:
This is the waistline, and it's falling.
We have trouble scoring.
It was Janet Maslin.
Jeder Absatz der Äußerung ergibt eine separate Audiodatei. Wenn Sie alle Sätze in einer Audiodatei kombinieren möchten, fügen Sie sie in einem einzigen Absatz zusammen.
Hinweis
Die generierten Audiodateien sind eine Kombination aus den automatischen Testskripts und benutzerdefinierten Testskripts.
Aktualisieren der Modulversion für Ihr Stimmmodell
Sprachsynthese-Engines von Azure werden regelmäßig aktualisiert, um das neueste Sprachmodell zu erfassen, das die Aussprache der Sprache definiert. Nachdem Sie Ihre Stimme trainiert haben, können Sie sie auf das neue Sprachmodell anwenden, indem Sie auf die neueste Engine-Version aktualisieren.
Wenn ein neues Modul verfügbar ist, werden Sie aufgefordert, Ihr neuronales Stimmmodell zu aktualisieren.

Wechseln Sie zur Modelldetailseite, und befolgen Sie die Anweisungen auf dem Bildschirm, um die neueste Engine zu installieren.
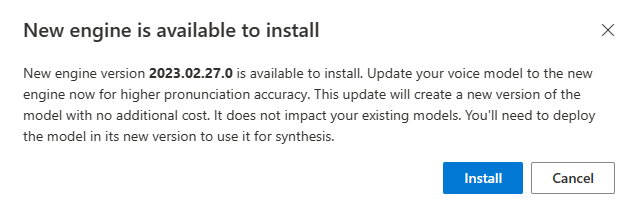
Wählen Sie alternativ später Installieren des aktuellen Moduls aus, um Ihr Modell auf die neueste Version der Engine zu aktualisieren.
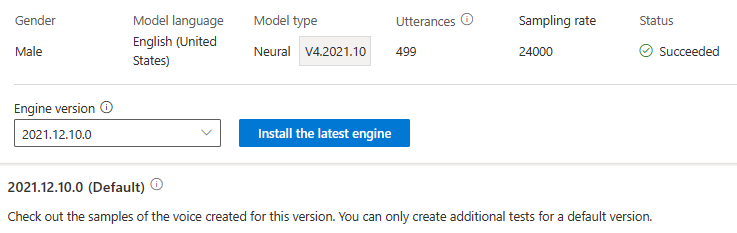
Das Modulupdate wird Ihnen nicht berechnet. Die vorherigen Versionen bleiben weiterhin erhalten.
Sie können alle Engine-Versionen für das Modell in der Dropdownliste Modulversion aktivieren oder eine entfernen, wenn Sie sie nicht mehr benötigen.
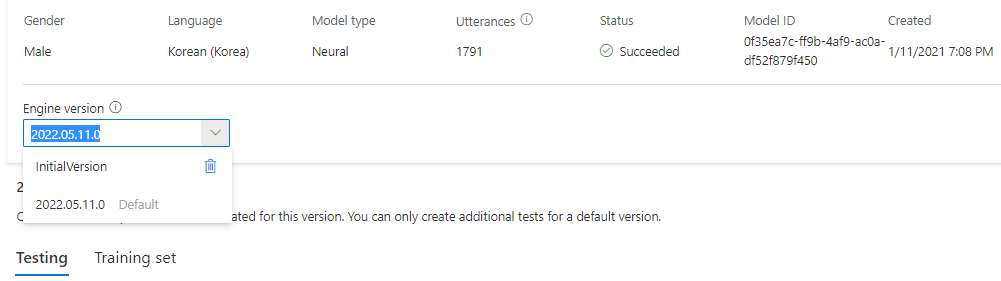
Die aktualisierte Version wird automatisch als Standard festgelegt. Sie können die Standardversion jedoch ändern, indem Sie eine Version aus der Dropdownliste und dann Als Standard festlegen auswählen.
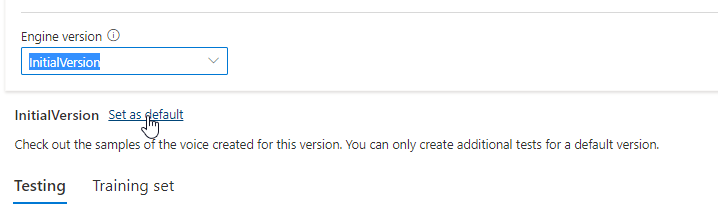

Wenn Sie jede Engine-Version Ihres Stimmmodells testen möchten, können Sie eine Version in der Liste und dann DefaultTests unter Testen auswählen, um sich die Beispielaudiodateien anzuhören. Wenn Sie Ihre eigenen Testskripts hochladen möchten, um die aktuelle Engine-Version weiter zu testen, stellen Sie zunächst sicher, dass die Version als Standard festgelegt ist, und führen Sie dann die Schritte unter Testen Ihres Stimmmodells aus.
Beim Aktualisieren der Engine wird ohne zusätzliche Kosten eine neue Version des Modells erstellt. Nachdem Sie die Engine-Version für Ihr Sprachmodell aktualisiert haben, müssen Sie die neue Version bereitstellen, um einen neuen Endpunkt zu erstellen. Sie können nur die Standardversion bereitstellen.
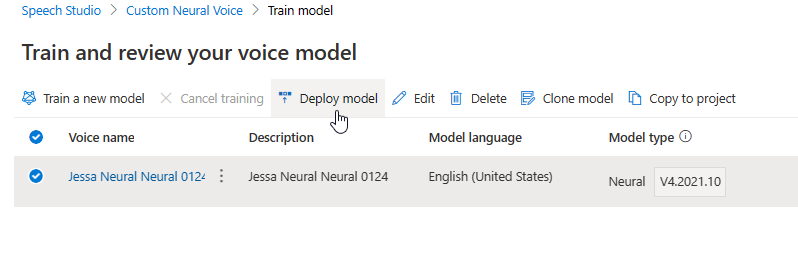
Wenn Sie einen neuen Endpunkt erstellt haben, müssen Sie den Datenverkehr an den neuen Endpunkt in Ihrem Produkt übertragen.
Weitere Informationen zu den Funktionen und Grenzen dieses Features sowie zu den bewährten Methoden zur Verbesserung der Modellqualität finden Sie unter Merkmale und Einschränkungen bei der Verwendung der benutzerdefinierten neuronalen Stimme.
Kopieren Ihres Stimmmodells in ein anderes Projekt
Sie können Ihr Stimmmodell in ein anderes Projekt für dieselbe Region oder eine andere Region kopieren. Beispielsweise können Sie ein neuronales Stimmmodell, das in einer Region trainiert wurde, in ein Projekt für eine andere Region kopieren.
Hinweis
Das benutzerdefinierte neuronale Stimmtraining ist aktuell nur in einigen Regionen verfügbar. Sie können ein neuronales Stimmmodell aus diesen Regionen in andere Regionen kopieren. Weitere Informationen finden Sie in der Liste der Regionen für benutzerdefinierte neuronale Stimmen.
So kopieren Sie Ihr benutzerdefiniertes neuronales Stimmmodell in ein anderes Projekt
Wählen Sie auf der Registerkarte Modell trainieren ein Stimmmodell aus, das Sie kopieren möchten, und klicken Sie dann auf In Projekt kopieren.
Wählen Sie die Region, die Sprachressource und das Projekt aus, in das Sie das Modell kopieren möchten. Sie benötigen eine Sprachressource und ein Projekt in der Zielregion. Gegebenenfalls müssen Sie diese Elemente zunächst erstellen.
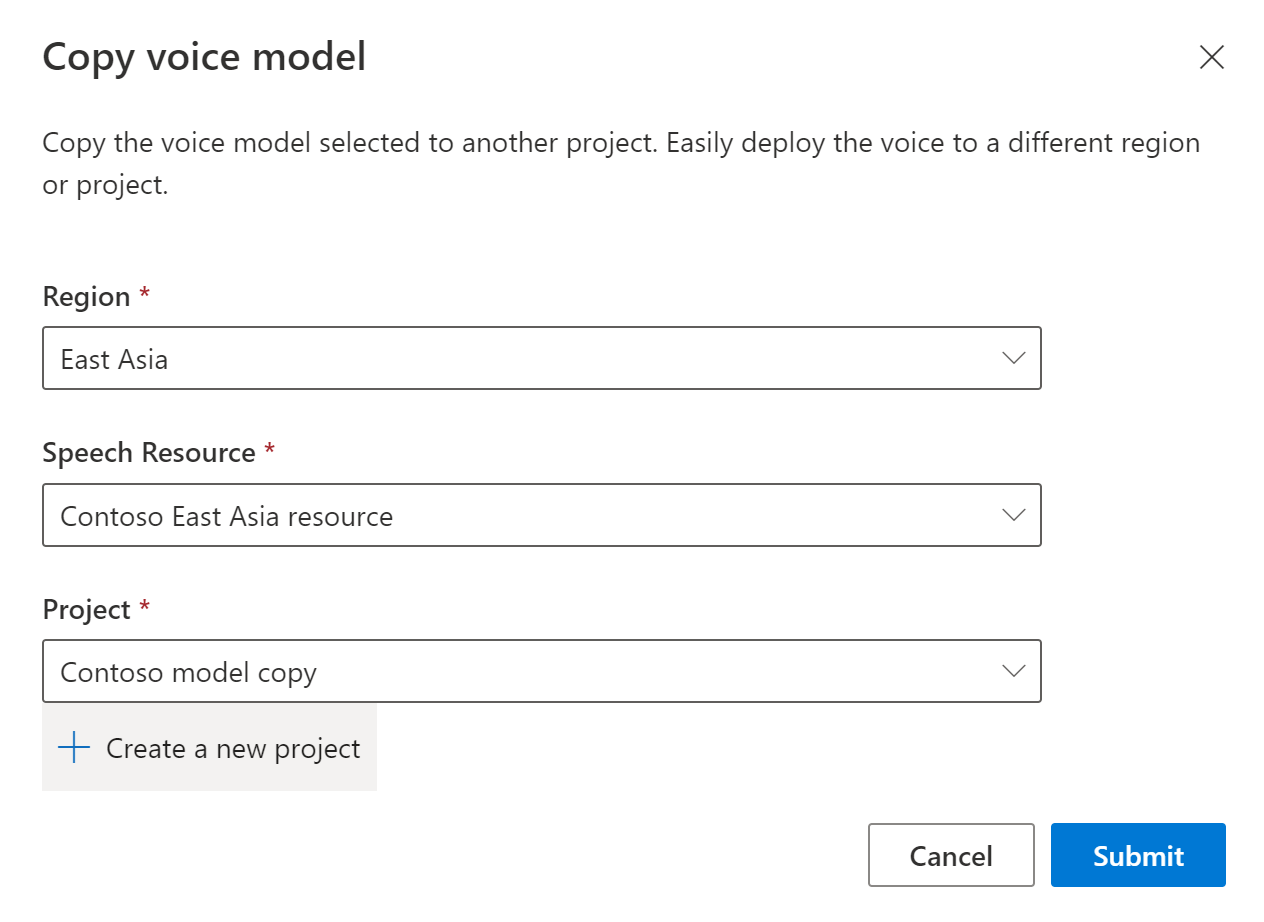
Wählen Sie Übermitteln aus, um das Modell zu kopieren.
Wählen Sie unterhalb der Benachrichtigung zum erfolgreichen Kopiervorgang Modell anzeigen aus.
Navigieren Sie zu dem Projekt, in das Sie das Modell kopiert haben, um die Modellkopie bereitzustellen.
Nächste Schritte
In diesem Artikel erfahren Sie, wie Sie eine benutzerdefinierte neuronale Stimme über die benutzerdefinierte Sprach-API trainieren können.
Wichtig
Das benutzerdefinierte neuronale Stimmtraining ist aktuell nur in einigen Regionen verfügbar. Nachdem Ihr Sprachmodell in einer unterstützten Region trainiert wurde, können Sie es nach Bedarf in eine Speech-Ressource in einer anderen Region kopieren. Weitere Informationen finden Sie in den Fußnoten in der Tabelle für Azure Cognitive Service für Speech.
Die Trainingsdauer hängt von der Menge der verwendeten Daten ab. Das Trainieren einer benutzerdefinierten neuronalen Stimme dauert im Durchschnitt etwa 40 Computestunden. Benutzer mit einem Standard-Abonnement (S0) können vier Stimmen gleichzeitig trainieren. Wenn das Limit erreicht wurde, warten Sie, bis der Trainingsvorgang mindestens eines Stimmmodells beendet wurde, und versuchen Sie es dann noch mal.
Hinweis
Zwar unterscheidet sich die Gesamtanzahl der benötigten Stunden je nach Trainingsmethode, doch gilt für alle der gleiche Preis pro Einheit. Weitere Informationen finden Sie unter Preisdetails zum benutzerdefinierten neuronalen Training.
Auswählen einer Trainingsmethode
Nachdem Sie Ihre Datendateien überprüft haben, können Sie daraus Ihr benutzerdefiniertes neuronales Stimmmodell erstellen. Wenn Sie eine benutzerdefinierte neuronale Stimme erstellen, können Sie sie mit einer der folgenden Methoden trainieren:
Neuronal: Erstellen einer Stimme in der Sprache Ihrer Trainingsdaten.
Neuronal - sprachübergreifend: Erstellen Sie eine Stimme, die eine andere Sprache spricht als Ihre Trainingsdaten. Beispielsweise können Sie mit den
fr-FRTrainingsdaten eine Stimme erstellen, dieen-USspricht.Die Sprache der Trainingsdaten und die Zielsprache müssen beide zu den Sprachen zählen, für die sprachübergreifendes Stimmtraining unterstützt wird. Sie brauchen keine Trainingsdaten in der Zielsprache vorzubereiten, aber Ihr Testskript muss in der Zielsprache abgefasst sein.
Neuronal – mehrformatig: Erstellen Sie eine benutzerdefinierte neuronale Stimme, die in mehreren Stillagen und Emotionen spricht, ohne neue Trainingsdaten hinzuzufügen. Stimmen mit mehreren Stilen eignen sich für Videospielfiguren, Konversations-Chatbots, Hörbücher, Inhaltslesemodule und mehr.
Um eine Stimme mit mehreren Stilen zu erstellen, müssen Sie allgemeine Trainingsdaten vorbereiten, die mindestens 300 Äußerungen umfassen. Wählen Sie mindestens einen voreingestellten Zielsprechstil aus. Sie können auch mehrere benutzerdefinierte Stile erstellen, indem Sie für dieselbe Stimme Stilbeispiele mit mindestens 100 Äußerungen pro Stil als zusätzliche Trainingsdaten bereitstellen. Die unterstützten voreingestellten Stile variieren je nach Sprache. Weitere Informationen finden Sie unter Verfügbare voreingestellte Stile für verschiedene Sprachen.
Die Sprache der Trainingsdaten muss zu den unterstützten Sprachen für das Training zählen, das benutzerdefinierte neuronale Stimmen betrifft, sprachübergreifend ist oder mehrere Stile umfasst.
Erstellen eines VoIP-Modells
Um eine neuronale Stimme zu erstellen, verwenden Sie den Vorgang Models_Create der benutzerdefinierten Sprach-API. Erstellen Sie den Anforderungstext gemäß den folgenden Anweisungen:
- Legen Sie die erforderliche
projectId-Eigenschaft fest. Siehe Erstellen eines Projekts. - Legen Sie die erforderliche
consentId-Eigenschaft fest. Siehe VoIP-Talentzustimmung hinzufügen. - Legen Sie die erforderliche
trainingSetId-Eigenschaft fest. Siehe Erstellen eines Trainingssatzes. - Legen Sie die erforderliche
kindRezepteigenschaft fürDefaultneurale Sprachtraining fest. Die Rezeptart gibt die Trainingsmethode an und kann später nicht geändert werden. Informationen zur Verwendung einer anderen Trainingsmethode finden Sie unter Neuronal – sprachübergreifend oder Neuronal – mehrformatig. Weitere Informationen zu zweisprachigem Training und zu Unterschieden zwischen Gebietsschemas finden Sie unter Zweisprachiges Training. - Legen Sie die erforderliche
voiceName-Eigenschaft fest. Der Sprachname muss mit "Neural" enden und kann später nicht geändert werden. Wählen Sie den Namen sorgfältig aus. Der Sprachename wird als Name der Stimme für Ihre Sprachsyntheseanforderung in der SDK- und SSML-Eingabe verwendet. Zulässig sind nur Buchstaben, Zahlen und einige wenige Satzzeichen. Verwenden Sie unterschiedliche Namen für unterschiedliche neuronale Stimmmodelle. - Legen Sie optional die
description-Eigenschaft für die Sprachbeschreibung fest. Die Sprachbeschreibung kann später geändert werden.
Stellen Sie eine HTTP PUT-Anforderung unter Verwendung der URI, wie im folgenden Beispiel Models_Create gezeigt.
- Ersetzen Sie
YourResourceKeydurch Ihren Speech-Ressourcenschlüssel. - Ersetzen Sie
YourResourceRegiondurch Ihren Speech-Ressourcenschlüssel. - Ersetzen Sie
JessicaModelIddurch eine Modell-ID Ihrer Wahl. Die ID für Groß-/Kleinschreibung wird im URI des Modells verwendet und kann später nicht geändert werden.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2023-12-01-preview"
Sie sollten einen Antworttext im folgenden Format erhalten:
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "NotStarted",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Zweisprachiges Training
Wenn Sie den Trainingstyp Neuronal auswählen, können Sie eine Stimme darauf trainieren, in mehreren Sprachen zu sprechen. Die Gebietsschemas zh-CN und zh-TW unterstützen das zweisprachige Training, sodass die Stimme sowohl Chinesisch als auch Englisch sprechen kann. Teilweise in Abhängigkeit von den Trainingsdaten kann die synthetisierte Stimme Englisch mit einem nativen englischen Akzent oder Englisch mit demselben Akzent wie die Trainingsdaten sprechen.
Hinweis
Um zu ermöglichen, dass eine Stimme im Gebietsschema zh-CN Englisch mit demselben Akzent wie in den Beispieldaten spricht, sollten Sie beim Erstellen eines Projekts Chinese (Mandarin, Simplified), English bilingual auswählen oder das Gebietsschema zh-CN (English bilingual) für die Trainingssatzdaten über die REST-API angeben.
Die folgende Tabelle enthält die Unterschiede zwischen den beiden Gebietsschemas:
| Speech Studio-Gebietsschema | REST-API-Gebietsschema | Unterstützung für zweisprachige Vorgänge |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Wenn Ihre Beispieldaten Englisch enthalten, spricht die synthetisierte Stimme Englisch mit einem nativen englischen Akzent anstelle desselben Akzents wie die Beispieldaten, unabhängig von der Menge der englischen Daten. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Wenn die synthetisierte Stimme Englisch mit demselben Akzent wie in den Beispieldaten sprechen soll, wird empfohlen, mehr als 10 % Daten in englischer Sprache in Ihren Trainingssatz einzuschließen. Andernfalls fällt der englische Sprachakzent möglicherweise nicht ideal aus. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Wenn Sie eine synthetisierte Stimme trainieren möchten, die Englisch mit demselben Akzent wie in Ihren Beispieldaten sprechen kann, stellen Sie sicher, mehr als 10 % Daten in englischer Sprache in Ihrem Trainingssatz bereitstellen. Andernfalls wird standardmäßig ein nativer englischer Akzent verwendet. Der Schwellenwert von 10 % wird basierend auf den Daten berechnet, die nach dem erfolgreichen Hochladen akzeptiert werden, nicht auf den Daten vor dem Hochladen. Wenn einige hochgeladene Daten in englischer Sprache aufgrund von Fehlern abgelehnt werden und der Schwellenwert von 10 % nicht erfüllt wird, erhält die synthetisierte Stimme standardmäßig einen nativen englischen Akzent. |
Verfügbare voreingestellte Stile für verschiedene Sprachen
In der folgenden Tabelle sind die verschiedenen voreingestellten Stile gemäß den verschiedenen Sprachen zusammengefasst.
| Sprechweise | Sprache (lokal) |
|---|---|
| Wütend | Englisch (Nordamerika) (en-US)Japanisch (Japan) ( ja-JP) 1Chinesisch (Mandarin, vereinfacht) ( zh-CN) 1 |
| Ruhig | Chinesisch (Mandarin, vereinfacht) (zh-CN) 1 |
| Chat | Chinesisch (Mandarin, vereinfacht) (zh-CN) 1 |
| Fröhlich | Englisch (Nordamerika) (en-US)Japanisch (Japan) ( ja-JP) 1Chinesisch (Mandarin, vereinfacht) ( zh-CN) 1 |
| Verärgert | Chinesisch (Mandarin, vereinfacht) (zh-CN) 1 |
| Aufgeregt | Englisch (Nordamerika) (en-US) |
| Ängstlich | Chinesisch (Mandarin, vereinfacht) (zh-CN) 1 |
| Freundlich | Englisch (Nordamerika) (en-US) |
| Hoffnungsvoll | Englisch (Nordamerika) (en-US) |
| Traurig | Englisch (Nordamerika) (en-US)Japanisch (Japan) ( ja-JP) 1Chinesisch (Mandarin, vereinfacht) ( zh-CN) 1 |
| Schreiend | Englisch (Nordamerika) (en-US) |
| Ernst | Chinesisch (Mandarin, vereinfacht) (zh-CN) 1 |
| Verängstigt | Englisch (Nordamerika) (en-US) |
| unfreundlich | Englisch (Nordamerika) (en-US) |
| Flüsternd | Englisch (Nordamerika) (en-US) |
1 Die neuronale Stimme ist in der öffentlichen Vorschau verfügbar. Stimmen in der öffentlichen Vorschauversion sind nur in drei Dienstregionen verfügbar: USA, Osten, Europa, Westen und Asien, Südosten.
Abrufen des Trainingsstatus
Um den Trainingsstatus eines Sprachmodells abzurufen, verwenden Sie den Vorgang Models_Get der benutzerdefinierten Sprach-API. Erstellen Sie den Anforderungstext wie folgt:
Stellen Sie eine HTTP-GET-Anforderung unter Verwendung der URI, wie im folgenden Beispiel Models_Get gezeigt.
- Ersetzen Sie
YourResourceKeydurch Ihren Speech-Ressourcenschlüssel. - Ersetzen Sie
YourResourceRegiondurch Ihren Speech-Ressourcenschlüssel. - Ersetzen Sie
JessicaModelId, wenn Sie im vorherigen Schritt eine andere Modell-ID angegeben haben.
curl -v -X GET "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2023-12-01-preview" -H "Ocp-Apim-Subscription-Key: YourResourceKey"
Sie sollten einen Antworttext im folgenden Format erhalten:
Hinweis
Das Rezept kind und andere Eigenschaften hängen davon ab, wie Sie die Stimmetrainiert haben. In diesem Beispiel ist Default die Rezeptart für neurale Sprachtrainings vorgesehen.
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Möglicherweise müssen Sie mehrere Minuten warten, bevor das Training abgeschlossen ist. Schließlich ändert sich der Status in entweder Succeeded oder Failed.