Verwalten des horizontalen Skalierens (Aufskalieren) eines Clusters in Azure Data Explorer zur Anpassung an sich ändernden Bedarf
Die richtige Größe eines Clusters ist entscheidend für die Leistung von Azure-Daten-Explorer. Eine statische Clustergröße kann zu einer Unter- oder Überauslastung führen, was beides nicht ideal ist. Da der Bedarf für einen Cluster nicht mit absoluter Genauigkeit vorhergesagt werden kann, ist es besser, einen Cluster zu skalieren und je nach Bedarf Kapazität und CPU-Ressourcen hinzuzufügen bzw. zu entfernen.
Es gibt zwei Workflows für die Skalierung eines Azure Data Explorer-Clusters:
- Horizontales Hoch- oder Herunterskalieren
- Zentrales Hoch- oder Herunterskalieren In diesem Artikel wird der Workflow für die horizontale Skalierung beschrieben.
Konfigurieren der horizontalen Skalierung
Bei Verwendung der horizontalen Skalierung können Sie die Instanzenanzahl anhand von vordefinierten Regeln und Zeitplänen automatisch skalieren. Geben Sie die Einstellungen für die Autoskalierung für Ihren Cluster wie folgt an:
Navigieren Sie im Azure-Portal zu Ihrer Azure Data Explorer-Clusterressource. Wählen Sie unter Einstellungen die Option Aufskalieren aus.
Wählen Sie im Fenster Aufskalieren die gewünschte Methode für die Autoskalierung aus: Manuelle Skalierung, Optimierte Autoskalierung oder Benutzerdefinierte Autoskalierung.
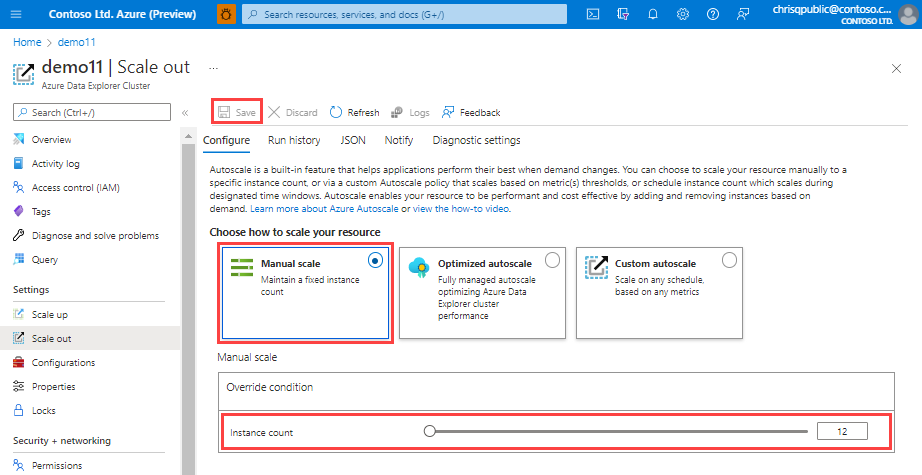
Manuelles Skalieren
In der Manuellen Skalierungsoption verfügt der Cluster über eine statische Kapazität, die sich nicht automatisch ändert. Wählen Sie die statische Kapazität mithilfe der Instanzanzahlsleiste aus . Die Skalierung des Clusters bleibt bei der ausgewählten Einstellung, bis sie geändert wird.
Optimierte automatische Skalierung (empfohlene Option)
Die optimierte automatische Skalierung ist die Standardeinstellung während der Clustererstellung und die empfohlene Skalierungsmethode. Mit dieser Methode werden die Leistung und die Kosten des Clusters in folgender Weise optimiert:
- Wenn der Cluster nicht ausgelastet ist, wird er auf niedrigere Kosten skaliert, ohne die erforderliche Leistung zu beeinträchtigen.
- Wenn der Cluster überlastet ist, wird er aufskaliert, um stets eine optimale Leistung zu erzielen.
So konfigurieren Sie die optimierte Autoskalierung:
Wählen Sie Optimierte Autoskalierung.
Geben Sie eine Mindestanzahl und eine Höchstanzahl von Instanzen an. Die automatische Skalierung des Clusters bewegt sich dann je nach Last zwischen diesen Werten.
Wählen Sie Speichern aus.

Die optimierte automatische Skalierung beginnt mit der Arbeit. Ihre Aktionen können im Aktivitätsprotokoll des Clusters in Azure angezeigt werden.
Logik der optimierten Autoskalierung
Die optimierte Autoskalierung wird entweder durch Vorhersagelogik oder durch reaktive Logik verwaltet. Die Vorhersagelogik verfolgt das Nutzungsmuster des Clusters nach und verwaltet die Skalierung des Clusters, wenn sie mit hoher Konfidenz Saisonalität erkennt. Andernfalls wird reaktive Logik verwendet, die die tatsächliche Nutzung des Clusters verfolgt, um Entscheidungen zu Skalierungsvorgängen des Clusters auf der Grundlage des aktuellen Niveaus der Ressourcennutzung zu treffen.
Dies sind die wichtigsten Metriken für Vorhersage- und reaktive Datenflüsse:
- CPU
- Cacheauslastungsfaktor
- Datenerfassungsauslastung
Sowohl Vorhersagelogik als auch reaktive Logik sind an die Größengrenzen des Clusters gebunden, die Mindest- und Höchstanzahl von Instanzen, wie in der Konfiguration der optimierten Autoskalierung definiert. Häufige Aufskalierungs- und Abskalierungsvorgänge des Clusters sind aufgrund der Auswirkungen auf die Ressourcen des Clusters und der benötigten Zeit zum Hinzufügen oder Entfernen von Instanzen sowie des erneuten Ausgleichs des heißen Caches zwischen allen Knoten unerwünscht.
Vorhersagbare Autoskalierung
Vorhersagelogik prognostiziert die Nutzung des Clusters für den nächsten Tag auf der Grundlage seiner Nutzungsmuster in den letzten Wochen. Die Vorhersage wird verwendet, um einen Zeitplan für Aufskalierungs- oder Abskalierungsvorgänge zu erstellen, um die Größe des Clusters im Voraus anzupassen. Auf diese Weise können die Clusterskalierung und der erneute Ausgleich der Daten rechtzeitig vor einer Änderung der Auslastung abgeschlossen werden. Diese Logik ist besonders effektiv für saisonale Muster, z. B. tägliche oder wöchentliche Nutzungsspitzen.
In Szenarien mit einer einmaligen Auslastungsspitze, die die Vorhersage übertrifft, greift die optimierte Autoskalierung jedoch auf reaktive Logik zurück. Wenn dies geschieht, werden die Abskalierungs- und Aufskalierungsvorgänge ad hoc auf der Grundlage des aktuellsten Niveaus der Ressourcennutzung ausgeführt.
Reaktive Autoskalierung
Aufskalieren
Wenn sich der Cluster einem Zustand der Überauslastung nähert, erfolgt ein Aufskalierungsvorgang, um weiterhin optimale Leistung zu bieten. Ein Aufskalieren wird ausgeführt, wenn mindestens eine der folgenden Bedingungen auftritt:
- Die Cacheauslastung ist länger als eine Stunde sehr hoch
- Die CPU-Auslastung ist für mehr als eine Stunde hoch
- Die Erfassungsauslastung ist länger als eine Stunde hoch
Abskalieren
Wenn der Cluster nicht ausgelastet ist, wird eine Abskalierung durchgeführt, um die Kosten zu senken und zugleich optimale Leistung aufrecht zu erhalten. Es werden mehrere Metriken verwendet, um zu überprüfen, ob das Abskalieren des Clusters sicher ist.
Damit sichergestellt ist, dass keine Ressourcen überlastet werden, werden vor einem Abskalieren die folgenden Metriken überprüft:
- Die Cacheauslastung ist nicht hoch.
- Die CPU-Auslastung liegt unter dem Durchschnitt.
- Die Erfassungsauslastung liegt unter dem Durchschnitt.
- Wenn Streamingerfassung verwendet wird, ist deren Auslastung nicht hoch
- Die Keep-Alive-Metrik liegt über einem definierten Minimum, wird ordnungsgemäß und zeitgerecht verarbeitet, was anzeigt, dass der Cluster reaktionsfähig ist
- Es tritt keine Drosselung von Abfragen auf
- Die Anzahl der fehlerhaften Abfragen liegt unter einem definierten Mindestwert
Hinweis
Die Logik zum Abskalieren erfordert derzeit eine eintägige Auswertung, bevor eine optimierte Abskalierung implementiert wird. Diese Auswertung erfolgt einmal pro Stunde. Ist eine sofortige Änderung erforderlich, nutzen Sie die manuelle Skalierung.
Benutzerdefinierte Autoskalierung
Obwohl eine optimierte automatische Skalierung die empfohlene Skalierungsoption ist, wird auch die benutzerdefinierte Azure-Autoskalierung unterstützt. Bei Verwendung der benutzerdefinierten Autoskalierung können Sie Ihren Cluster basierend auf den von Ihnen angegebenen Metriken dynamisch skalieren. Verwenden Sie die folgenden Schritte, um die benutzerdefinierte Autoskalierung zu konfigurieren.
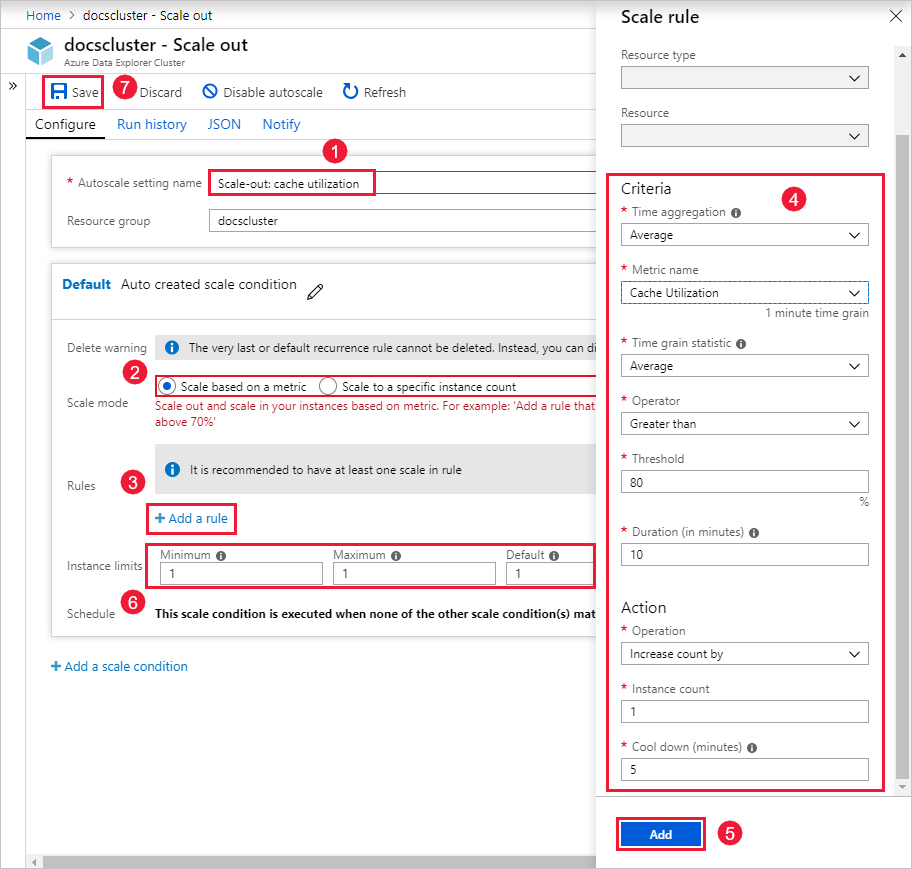
Geben Sie im Feld Name der Einstellung für die Autoskalierung einen Namen ein, z. B. Horizontale Skalierung: Cacheauslastung.
Wählen Sie unter Skalierungsmodus die Option Basierend auf einer Metrik skalieren aus. Dieser Modus ermöglicht die dynamische Skalierung. Sie können auch Auf eine bestimmte Anzahl von Instanzen skalieren auswählen.
Wählen Sie + Regel hinzufügen aus.
Geben Sie im Abschnitt Skalierungsregel auf der rechten Seite Werte für jede Einstellung ein.
Kriterien
Einstellung Beschreibung und Wert Zeitaggregation Wählen Sie ein Aggregationskriterium aus, z. B. Durchschnitt. Metrikname Wählen Sie die Metrik aus, auf der der Skalierungsvorgang basieren soll, z. B. Cacheauslastung. Statistik zum Aggregationsintervall Wählen Sie zwischen Durchschnitt, Minimum, Maximum und Summe aus. Operator Wählen Sie die entsprechende Option aus, z. B. Größer als oder gleich. Schwellenwert Wählen Sie einen passenden Wert aus. Für die Cacheauslastung ist beispielsweise ist 80 % ein guter Ausgangspunkt. Dauer (in Minuten) Wählen Sie eine angemessene Zeitspanne, die das System bei der Berechnung von Metriken berücksichtigt. Beginnen Sie mit dem Standardwert von 10 Minuten. Aktion
Einstellung Beschreibung und Wert Vorgang Wählen Sie die entsprechende Option zum Auf- oder Abskalieren aus. Anzahl der Instanzen Wählen Sie die Anzahl von Knoten oder Instanzen aus, die hinzugefügt oder entfernt werden sollen, wenn eine Metrikbedingung erfüllt ist. Abkühlen (Minuten) Wählen Sie ein geeignetes Intervall für die Zeit zwischen den einzelnen Skalierungsvorgängen. Beginnen Sie mit dem Standardwert von 5 Minuten. Wählen Sie Hinzufügen.
Geben Sie im Abschnitt Instanzgrenzwerte auf der linken Seite Werte für jede Einstellung ein.
Einstellung Beschreibung und Wert Mindestanforderungen Die Anzahl der Instanzen, unter die Ihr Cluster unabhängig von der Auslastung nicht herunterskaliert wird. Maximum Die Anzahl der Instanzen, über die Ihr Cluster unabhängig von der Auslastung nicht hochskaliert wird. Standard Die Standardanzahl von Instanzen. Diese Einstellung wird verwendet, wenn Probleme beim Lesen der Ressourcenmetriken auftreten. Wählen Sie Speichern aus.
Sie haben nun die horizontale Skalierung für Ihren Azure Data Explorer-Cluster konfiguriert. Fügen Sie eine weitere Regel für die vertikale Skalierung hinzu. Wenn Sie Hilfe bei Clusterskalierungsproblemen benötigen, erstellen Sie im Azure-Portal eine Supportanfrage.
Verwandte Inhalte
- Überwachen der Azure Data Explorer-Leistung, -Integrität und -Auslastung mit Metriken
- Manage cluster vertical scaling (scale up) in Azure Data Explorer to accommodate changing demand (Verwalten der vertikalen Clusterskalierung (Hochskalieren) in Azure Data Explorer bei sich änderndem Bedarf)
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für