Migrieren eines normalisierten Datenbankschemas von Azure SQL-Datenbank zu einem denormalisierten Azure Cosmos DB-Container
In dieser Anleitung wird erläutert, wie Sie ein vorhandenes normalisiertes Datenbankschema in Azure SQL-Datenbank in ein denormalisiertes Azure Cosmos DB-Schema konvertieren können, um es in Azure Cosmos DB zu laden.
SQL-Schemas werden in der Regel mithilfe der dritten Normalform modelliert. Dies führt zu normalisierten Schemas, die eine hohe Datenintegrität mit weniger doppelten Datenwerten bereitstellen. Abfragen können Entitäten über Tabellen hinweg zum Lesen zusammenführen. Azure Cosmos DB ist für superschnelle Transaktionen und Abfragen innerhalb einer Sammlung oder eines Containers über denormalisierte Schemas mit eigenständigen Daten in einem Dokument optimiert.
Mithilfe von Azure Data Factory erstellen wir eine Pipeline, in der mit einem einzelnen Zuordnungsdatenfluss aus zwei normalisierten Azure SQL-Datenbank-Tabellen gelesen wird, die Primär- und Fremdschlüssel als Entitätsbeziehung enthalten. ADF verknüpft diese Tabellen mit der Datenfluss-Spark-Engine zu einem einzelnen Datenstrom, sammelt verknüpfte Zeilen in Arrays und erzeugt einzelne bereinigte Dokumente zum Einfügen in einen neuen Azure Cosmos DB-Container.
In diesem Leitfaden wird dynamisch ein neuer Container mit dem Namen „orders“ erstellt, der die Tabellen SalesOrderHeader und SalesOrderDetail in der standardmäßigen SQL Server-Beispieldatenbank AdventureWorks verwendet. Diese Tabellen stellen Vertriebstransaktionen dar, die durch SalesOrderID verknüpft sind. Jeder eindeutige Detaildatensatz weist seinen eigenen Primärschlüssel SalesOrderDetailID auf. Zwischen „header“ und „details“ besteht eine 1:M-Beziehung. Die Verknüpfung erfolgt über SalesOrderID in ADF. Anschließend wird dann jeder zugehörige Detaildatensatz in das Array „detail“ überführt.
Die repräsentative SQL-Abfrage für diesen Leitfaden lautet:
SELECT
o.SalesOrderID,
o.OrderDate,
o.Status,
o.ShipDate,
o.SalesOrderNumber,
o.ShipMethod,
o.SubTotal,
(select SalesOrderDetailID, UnitPrice, OrderQty from SalesLT.SalesOrderDetail od where od.SalesOrderID = o.SalesOrderID for json auto) as OrderDetails
FROM SalesLT.SalesOrderHeader o;
Der resultierende Azure Cosmos DB-Container bettet die innere Abfrage in ein einzelnes Dokument ein. Das Ergebnis sieht dann wie folgt aus:

Erstellen einer Pipeline
Wählen Sie +Neue Pipeline aus, um eine neue Pipeline zu erstellen.
Hinzufügen einer Datenflussaktivität
Wählen Sie in der Datenflussaktivität die Option für eine neue Mapping Data Flow-Instanz aus.
Wir erstellen diesen Datenflussgraphen weiter unten.
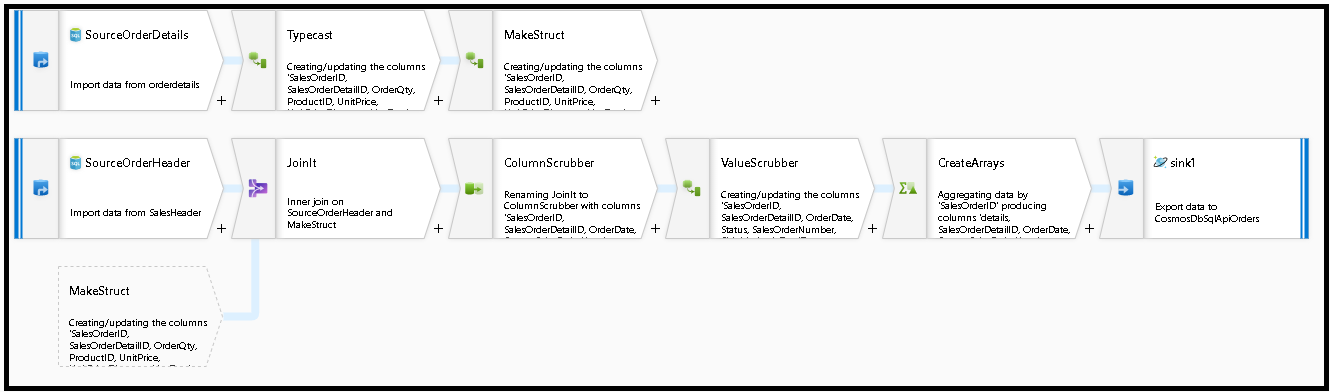
Definieren Sie die Quelle für „SourceOrderDetails“. Erstellen Sie ein neues Azure SQL-Datenbank-Dataset, das auf die Tabelle
SalesOrderDetailzeigt.Definieren Sie die Quelle für „SourceOrderHeader“. Erstellen Sie ein neues Azure SQL-Datenbank-Dataset, das auf die Tabelle
SalesOrderHeaderzeigt.Fügen Sie in der obersten Quelle nach „SourceOrderDetails“ eine Transformation für abgeleitete Spalten hinzu. Geben Sie der neuen Transformation den Namen „TypeCast“. Sie müssen für Azure Cosmos DB die Spalte
UnitPricerunden und in den Datentyp „Double“ umwandeln. Legen Sie die Formel folgendermaßen fest:toDouble(round(UnitPrice,2)).Fügen Sie eine weitere abgeleitete Spalte hinzu, und geben Sie ihr den Namen „MakeStruct“. Hier erstellen Sie eine hierarchische Struktur zum Speichern der Werte aus der Tabelle „details“. Denken Sie daran, dass „details“ in einer
M:1-Beziehung zu „header“ steht. Geben Sie der neuen Struktur den Namenorderdetailsstruct, und erstellen Sie die Hierarchie auf diese Weise, indem Sie jede Unterspalte auf den Namen der eingehenden Spalte festlegen: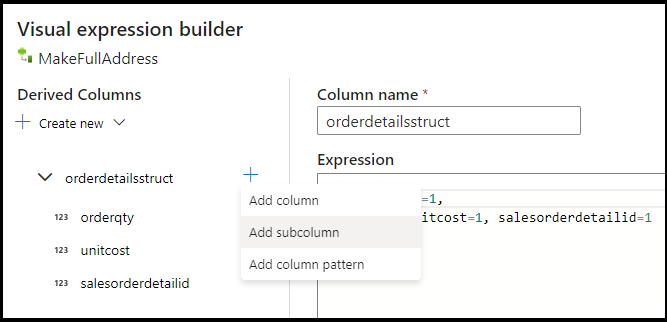
Nun geht es mit der Quelle für den Vertriebsheader weiter. Fügen Sie eine Jointransformation hinzu. Wählen Sie für die rechte Seite „MakeStruct“ aus. Legen Sie sie auf den inneren Join festgelegt, und wählen Sie für beide Seiten der Joinbedingung
SalesOrderIDaus.Klicken Sie im neu hinzugefügten Join auf die Registerkarte „Datenvorschau“, damit Sie die Ergebnisse bis zu diesem Punkt sehen können. Es sollten alle Headerzeilen verknüpft mit den Detailzeilen angezeigt werden. Dies ist das Ergebnis des aus der
SalesOrderIDgebildeten Joins. Als Nächstes kombinieren Sie die Details aus den gemeinsamen Zeilen in die Struktur „details“ und aggregieren die gemeinsamen Zeilen.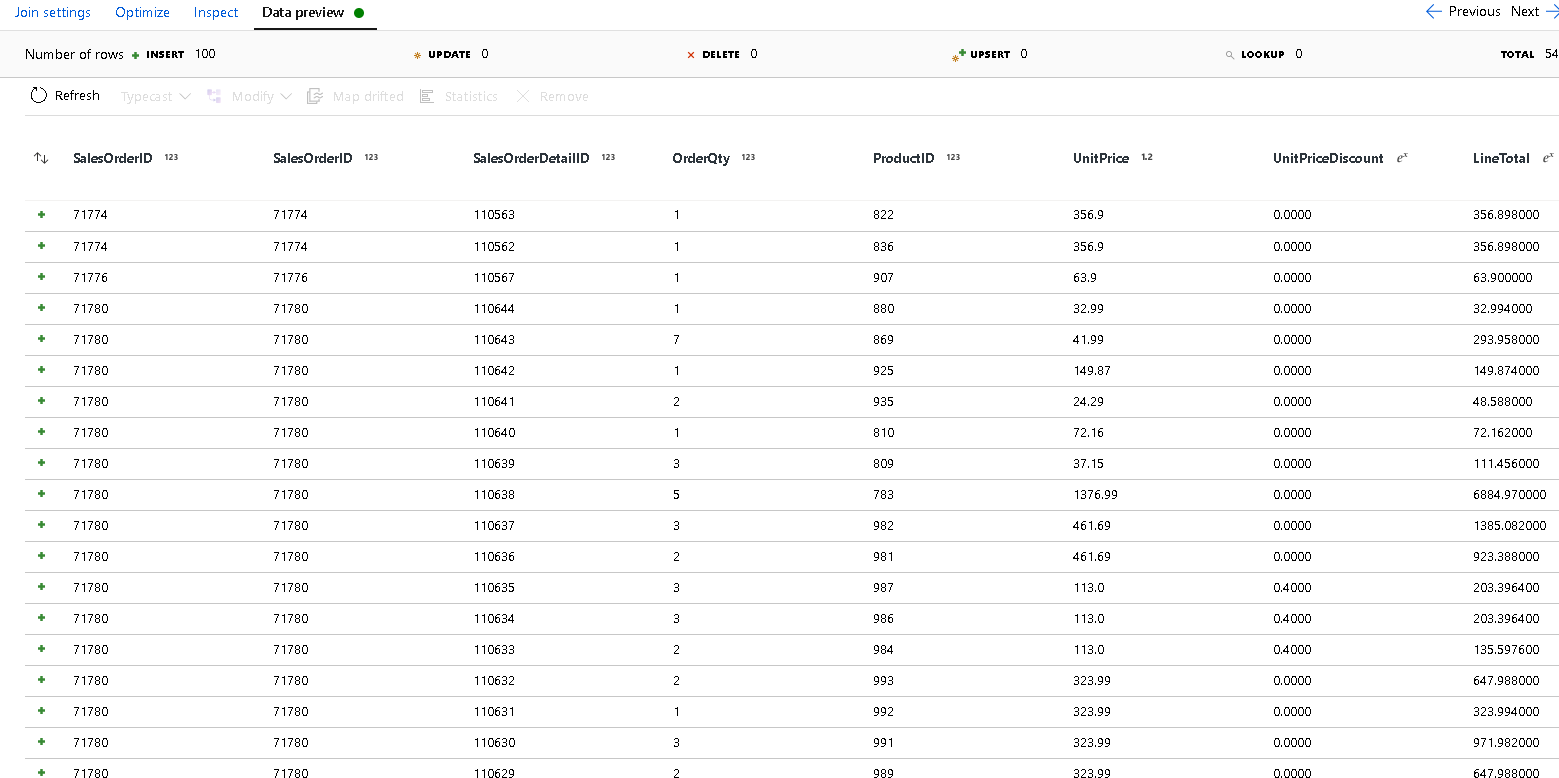
Bevor Sie die Arrays zum Denormalisieren dieser Zeilen erstellen können, müssen Sie zunächst unerwünschte Spalten entfernen und sicherstellen, dass die Datenwerte den Azure Cosmos DB-Datentypen entsprechen.
Fügen Sie als Nächstes eine Auswahltransformation hinzu, und legen Sie die Feldzuordnung wie folgt fest:
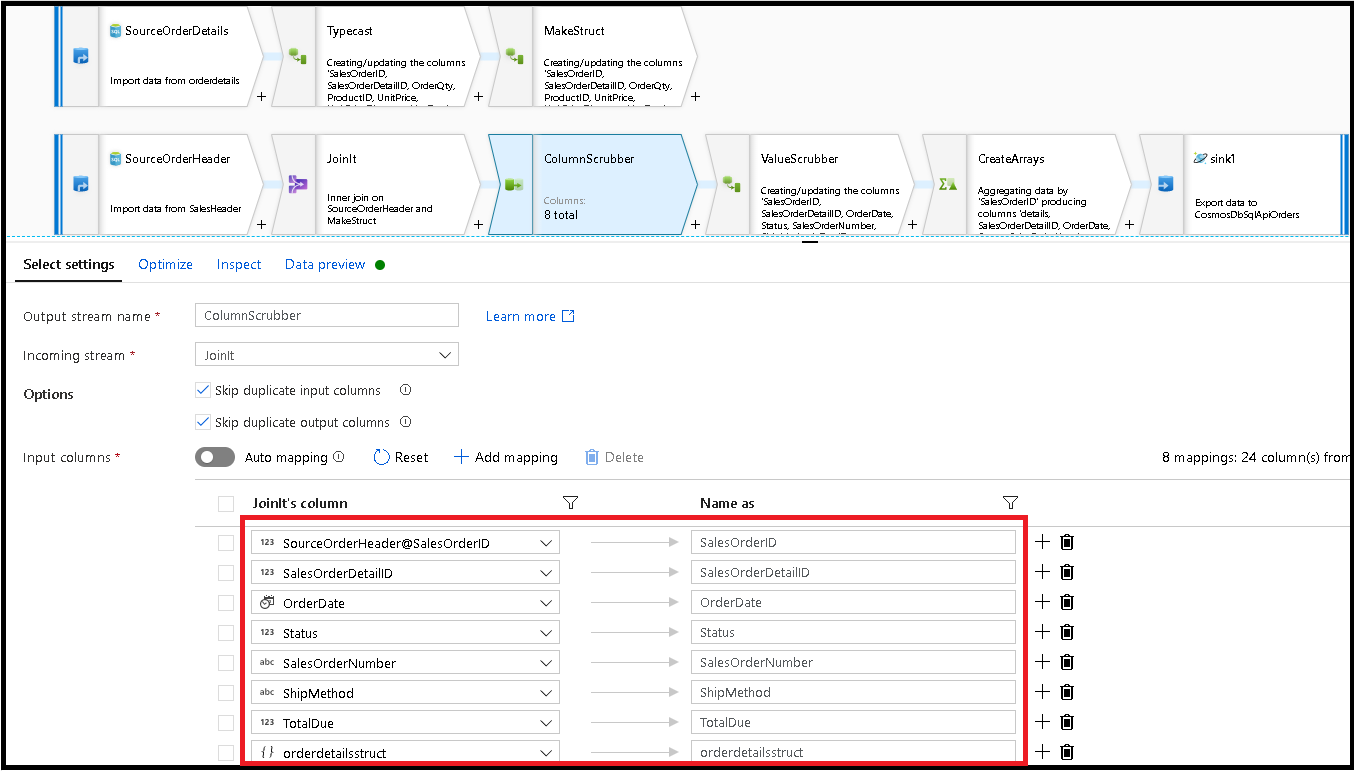
Nun fügen Sie eine Währungsspalte ein:
TotalDue. Legen Sie wie oben in Schritt 7 die Formel auftoDouble(round(TotalDue,2))fest.Hier denormalisieren Sie die Zeilen, indem Sie sie nach dem gemeinsamen Schlüssel
SalesOrderIDgruppieren. Fügen Sie eine Aggregationstransformation hinzu, und legen Sie die Gruppierung aufSalesOrderIDfest.Fügen Sie in der Aggregationsformel eine neue Spalte mit dem Namen „details“ hinzu, und verwenden Sie diese Formel, um die Werte in der zuvor erstellten Struktur
orderdetailsstructzu erfassen:collect(orderdetailsstruct).Die Aggregationstransformation gibt nur Spalten aus, die ein Teil von „aggregate“- oder „group by“-Formeln sind. Daher müssen Sie auch die Spalten aus dem Vertriebsheader einschließen. Fügen Sie zu diesem Zweck ein Spaltenmuster in derselben Aggregattransformation hinzu. Dieses Muster schließt alle anderen Spalten in die Ausgabe ein, mit Ausnahme der unten aufgeführten (OrderQty, UnitPrice, SalesOrderID):
instr(name,'OrderQty')==0&&instr(name,'UnitPrice')==0&&instr(name,'SalesOrderID')==0
Verwenden Sie die „this“-Syntax ($$) in den anderen Eigenschaften, um dieselben Spaltennamen beizubehalten, und verwenden Sie die
first()-Funktion als Aggregat. Dadurch wird Azure Data Factory aufgefordert, den ersten übereinstimmenden Wert beizubehalten: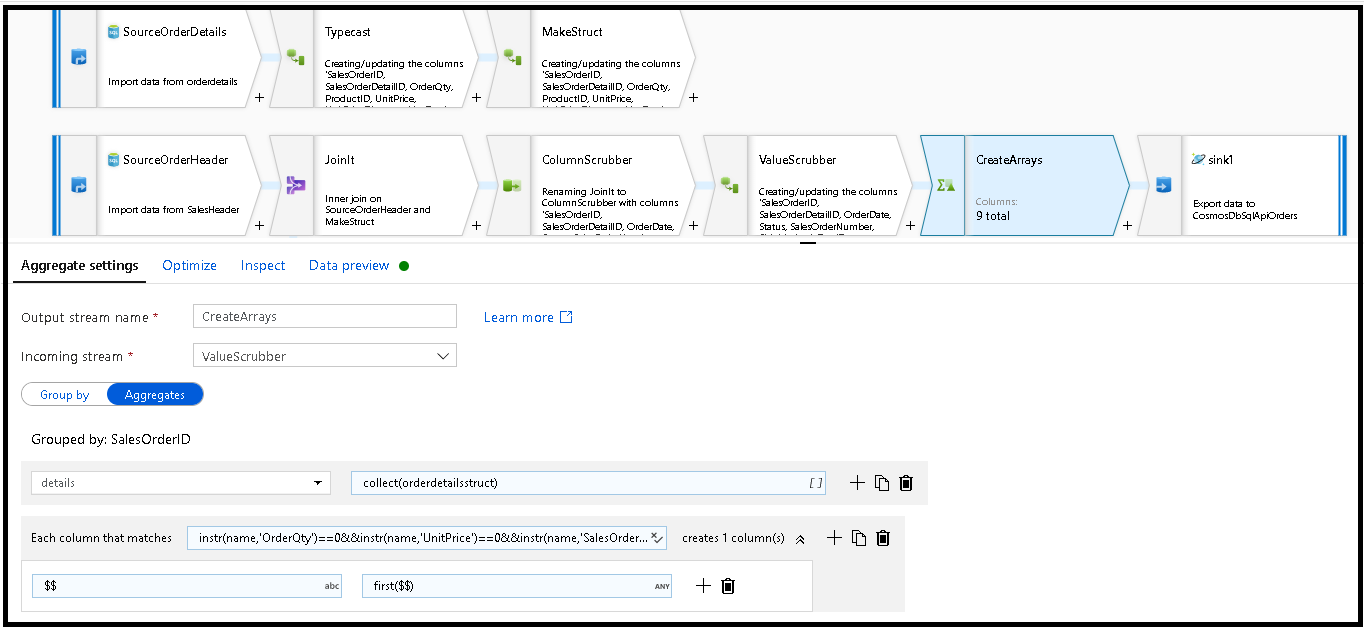
Sie sind bereit, den Migrationsflow durch Hinzufügen einer Senkentransformation abzuschließen. Klicken Sie neben dem Dataset auf „Neu“, und fügen Sie ein Azure Cosmos DB-Dataset hinzu, das auf Ihre Azure Cosmos DB-Datenbank verweist. Für die Sammlung nennen Sie es „orders“. Es weist kein Schema und keine Dokumente auf, da es dynamisch erstellt wird.
Legen Sie in den Einstellungen für die Senke den Partitionsschlüssel auf
/SalesOrderIDund die Sammlungsaktion auf „recreate“ fest. Stellen Sie sicher, dass die Registerkarte der Zuordnung wie folgt aussieht: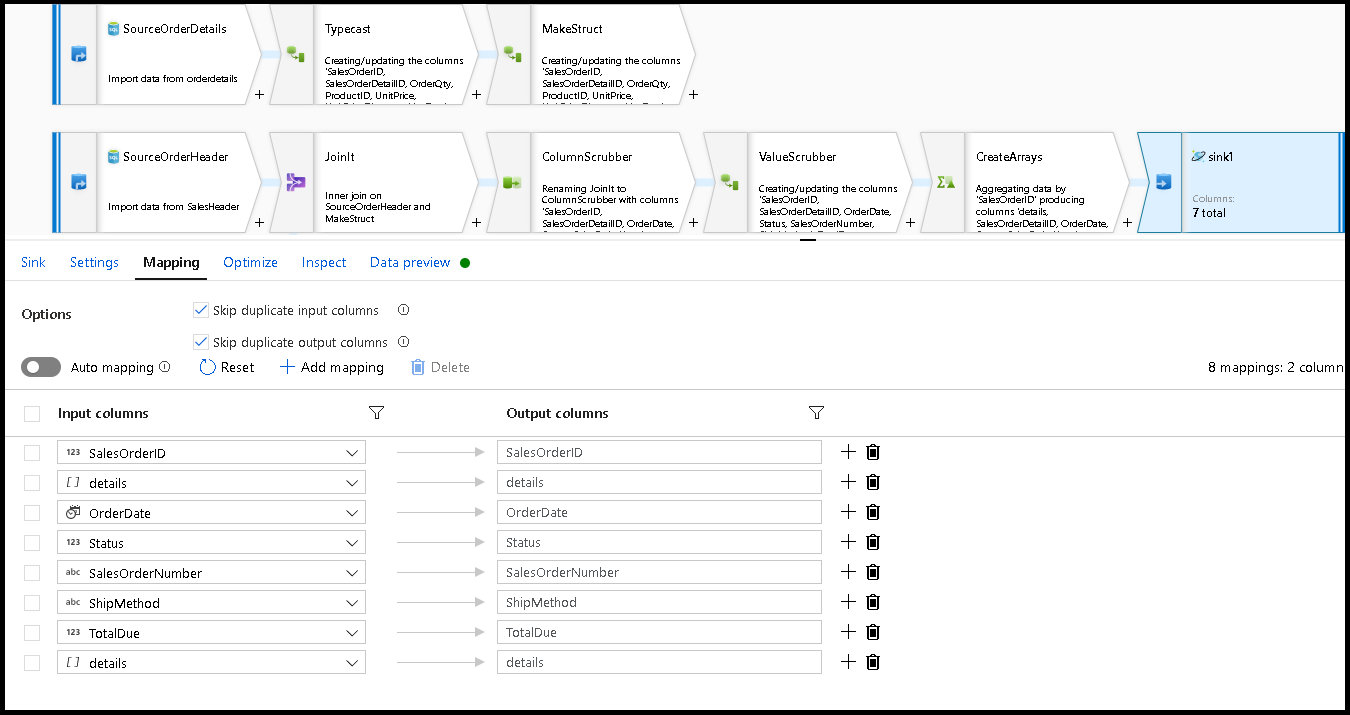
Klicken Sie auf „Datenvorschau“, um sicherzustellen, dass diese 32 Zeilen, die als neue Dokumente in Ihren neuen Container eingefügt werden sollen, angezeigt werden:
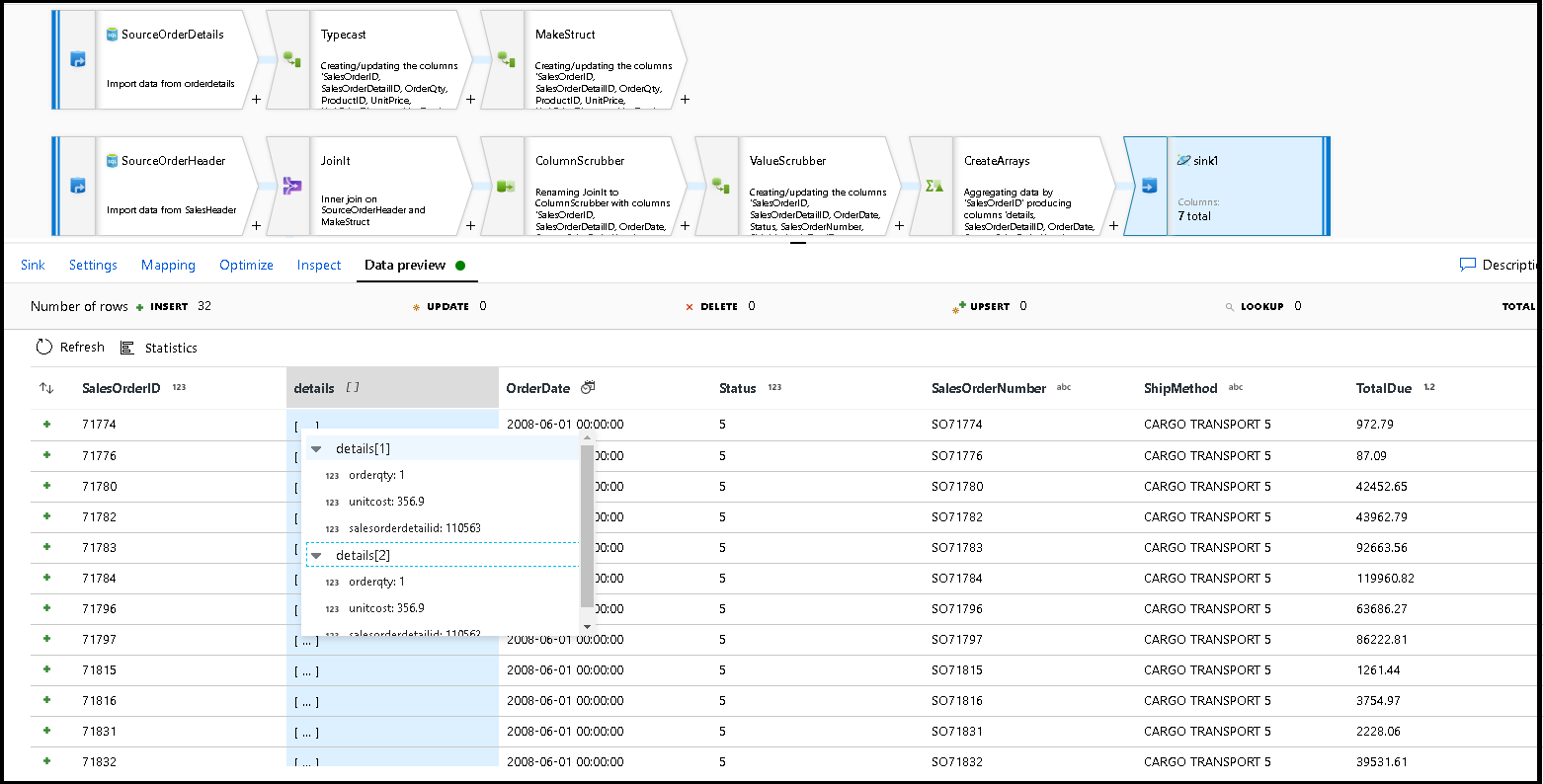
Wenn alles gut aussieht, können Sie jetzt eine neue Pipeline erstellen, ihr diese Datenflussaktivität hinzufügen und sie ausführen. Die Ausführung kann aus dem Debuggen oder einer ausgelösten Ausführung erfolgen. Nach einigen Minuten sollten Sie in Ihrer Azure Cosmos DB-Datenbank über einen neuen denormalisierten Container für Bestellungen mit dem Namen „orders“ verfügen.
Zugehöriger Inhalt
- Erstellen Sie die restliche Datenflusslogik mithilfe von Mapping Data Flow-Transformationen.
- Laden Sie die fertige Pipelinevorlage für dieses Tutorial herunter, und importieren Sie die Vorlage in Ihre Factory.