Massenkopieren mehrerer Tabellen mithilfe von Azure Data Factory im Azure-Portal
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Tutorial wird das Kopieren von mehreren Tabellen aus einer Azure SQL-Datenbank in Azure Synapse Analytics veranschaulicht. Sie können dieses Muster auch in anderen Kopierszenarios anwenden. So können Sie beispielsweise Tabellen aus SQL Server/Oracle in Azure SQL-Datenbank/Azure Synapse Analytics/Azure Blob kopieren oder verschiedene Pfade aus Blob in Azure SQL-Datenbanktabellen.
Hinweis
Falls Sie noch nicht mit Azure Data Factory vertraut sind, ist es ratsam, den Artikel Einführung in Azure Data Factory zu lesen.
Das Tutorial umfasst die folgenden Schritte:
- Erstellen einer Data Factory.
- Erstellen verknüpfter Azure SQL-Datenbank-, Azure Synapse Analytics- und Azure Storage-Dienste
- Erstellen von Azure SQL-Datenbank- und Azure Synapse Analytics-Datasets
- Erstellen einer Pipeline zum Abrufen der zu kopierenden Tabellen und einer weiteren Pipeline zur Durchführung des eigentlichen Kopiervorgangs.
- Starten einer Pipelineausführung
- Überwachen der Pipeline- und Aktivitätsausführungen.
In diesem Tutorial wird das Azure-Portal verwendet. Informationen zur Verwendung von anderen Tools/SDKs zum Erstellen einer Data Factory finden Sie unter Schnellstarts.
Kompletter Workflow
In diesem Szenario verfügen Sie über mehrere Tabellen aus der Azure SQL-Datenbank-Instanz, die Sie in Azure Synapse Analytics kopieren möchten. Nachfolgend ist der logische Ablauf eines Workflows dargestellt, der in Pipelines ausgeführt wird:

- Die erste Pipeline ruft die Liste mit den Tabellen ab, die in die Senkendatenspeicher kopiert werden sollen. Sie können stattdessen auch eine Metadatentabelle mit den Tabellen verwalten, die in die Senkendatenspeicher kopiert werden sollen. Die Pipeline löst anschließend eine weitere Pipeline aus, die wiederum jede Tabelle in der Datenbank durchläuft und den Datenkopiervorgang ausführt.
- Die zweite Pipeline führt den eigentlichen Kopiervorgang aus. Dazu wird die Liste mit den Tabellen als Parameter verwendet. Kopieren Sie für jede Tabelle in der Liste die jeweilige Tabelle aus Azure SQL-Datenbank in die entsprechende Tabelle in Azure Synapse Analytics. Verwenden Sie für eine optimale Leistung das gestaffelte Kopieren über Blob Storage und PolyBase. In diesem Beispiel wird die Liste mit den Tabellen von der ersten Pipeline als Wert für den Parameter übergeben.
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Voraussetzungen
- Azure Storage-Konto. Das Azure Storage-Konto wird im Massenkopiervorgang als Staging-Blobspeicher verwendet.
- Azure SQL-Datenbank. Diese Datenbank enthält die Quelldaten. Erstellen Sie in SQL-Datenbank eine Datenbank mit den AdventureWorks LT-Beispieldaten anhand der Informationen aus dem Artikel Erstellen einer Datenbank in Azure SQL-Datenbank. In diesem Tutorial werden alle Tabellen aus der Beispieldatenbank in Azure Synapse Analytics kopiert.
- Azure Synapse Analytics: Dieses Data Warehouse enthält die Daten, die aus der SQL-Datenbank kopiert werden. Wenn Sie über keinen Azure Synapse Analytics-Arbeitsbereich verfügen, führen Sie die Schritte im Artikel Erste Schritte mit Azure Synapse Analytics aus, um einen Arbeitsbereich zu erstellen.
Azure-Dienste für den Zugriff auf SQL-Server
Gewähren Sie den Azure-Diensten sowohl für SQL-Datenbank als auch für Azure Synapse Analytics den Zugriff auf SQL Server. Stellen Sie sicher, dass die Einstellung Anderen Azure-Diensten und -Ressourcen den Zugriff auf diesen Server gestatten für Ihren Server auf EIN festgelegt ist. Mit dieser Einstellung wird dem Data Factory-Dienst erlaubt, Daten aus Ihrer Azure SQL-Datenbank-Instanz zu lesen und in Azure Synapse Analytics zu schreiben.
Wenn Sie diese Einstellung überprüfen und aktivieren möchten, navigieren Sie zu Ihrem Server >„Sicherheit“ > „Firewalls und virtuelle Netzwerke“>, und legen Sie die Option Anderen Azure-Diensten und -Ressourcen den Zugriff auf diesen Server gestatten auf EIN fest.
Erstellen einer Data Factory
Starten Sie den Webbrowser Microsoft Edge oder Google Chrome. Die Data Factory-Benutzeroberfläche wird zurzeit nur in den Webbrowsern Microsoft Edge und Google Chrome unterstützt.
Öffnen Sie das Azure-Portal.
Wählen Sie links im Azure-Portalmenü die Option Ressource erstellen>Integration>Data Factory aus.
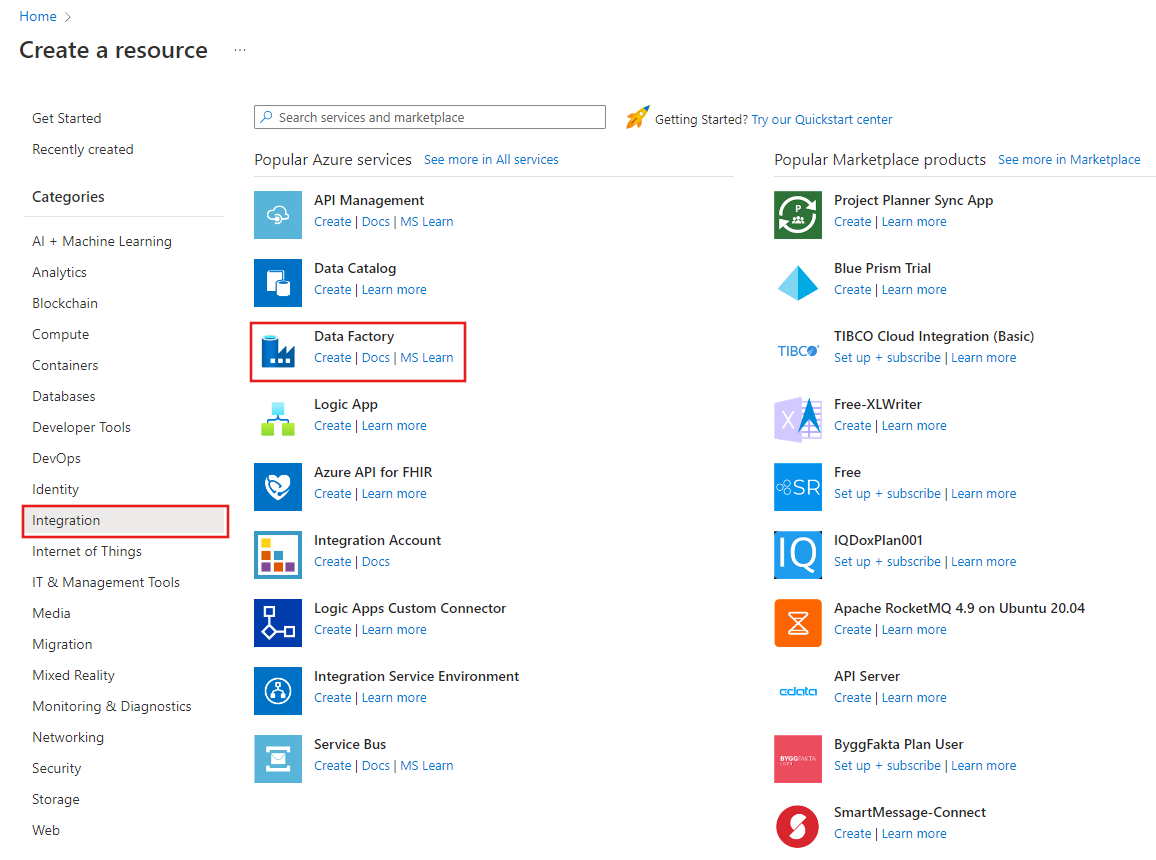
Geben Sie auf der Seite Neue Data Factory unter Name die Zeichenfolge ADFTutorialBulkCopyDF ein.
Der Name der Azure Data Factory muss global eindeutigsein. Sollte der unten angegebene Fehler für das Feld „Name“ auftreten, ändern Sie den Namen der Data Factory (beispielsweise in „
ADFTutorialBulkCopyDF“). Benennungsregeln für Data Factory-Artefakte finden Sie im Artikel Azure Data Factory – Benennungsregeln. Data factory name "ADFTutorialBulkCopyDF" is not availableWählen Sie Ihr Azure-Abonnement aus, in dem die Data Factory erstellt werden soll.
Führen Sie für die Ressourcengruppe einen der folgenden Schritte aus:
Wählen Sie die Option Use existing(Vorhandene verwenden) und dann in der Dropdownliste eine vorhandene Ressourcengruppe.
Wählen Sie Neu erstellen, und geben Sie den Namen einer Ressourcengruppe ein.
Weitere Informationen über Ressourcengruppen finden Sie unter Verwenden von Ressourcengruppen zum Verwalten von Azure-Ressourcen.
Wählen Sie V2 als Version aus.
Wählen Sie den Standort für die Data Factory aus. Eine Liste der Azure-Regionen, in denen Data Factory derzeit verfügbar ist, finden Sie, indem Sie die für Sie interessanten Regionen auf der folgenden Seite auswählen und dann Analysen erweitern, um Data Factory zu finden: Verfügbare Produkte nach Region. Die von der Data Factory verwendeten Datenspeicher (Azure Storage, Azure SQL-Datenbank usw.) und Computedienste (HDInsight usw.) können sich in anderen Regionen befinden.
Klicken Sie auf Erstellen.
Wählen Sie nach der Erstellung Zu Ressource wechseln aus, um zur Seite Data Factory zu navigieren.
Klicken Sie auf der Kachel Open Azure Data Factory Studio auf Öffnen, um die Data Factory-UI-Anwendung in einer separaten Registerkarte zu starten.
Erstellen von verknüpften Diensten
Sie erstellen verknüpfte Dienste, um Ihre Datenspeicher und Computes mit einer Data Factory zu verknüpfen. Ein verknüpfter Dienst enthält die Verbindungsinformationen, die der Data Factory-Dienst zur Laufzeit zum Herstellen der Verbindung mit dem Datenspeicher verwendet.
In diesem Tutorial verknüpfen Sie Ihre Azure SQL-Datenbank-, Azure Synapse Analytics- und Azure Blob Storage-Datenspeicher mit Ihrer Data Factory. Die Azure SQL-Datenbank ist der Quelldatenspeicher. Azure Synapse Analytics ist der Senken- bzw. Zieldatenspeicher. Azure Blob Storage dient zum Bereitstellen der Daten per Staging, bevor sie mithilfe von PolyBase in die Azure Synapse Analytics-Instanz geladen werden.
Erstellen des verknüpften Quelldiensts Azure SQL-Datenbank
In diesem Schritt erstellen Sie einen verknüpften Dienst zum Verknüpfen Ihrer Datenbank in Azure SQL-Datenbank mit der Data Factory.
Öffnen Sie im linken Bereich die Registerkarte Verwalten.
Wählen Sie auf der Seite „Verknüpfte Dienste“ die Option +Neu aus, um einen neuen verknüpften Dienst zu erstellen.
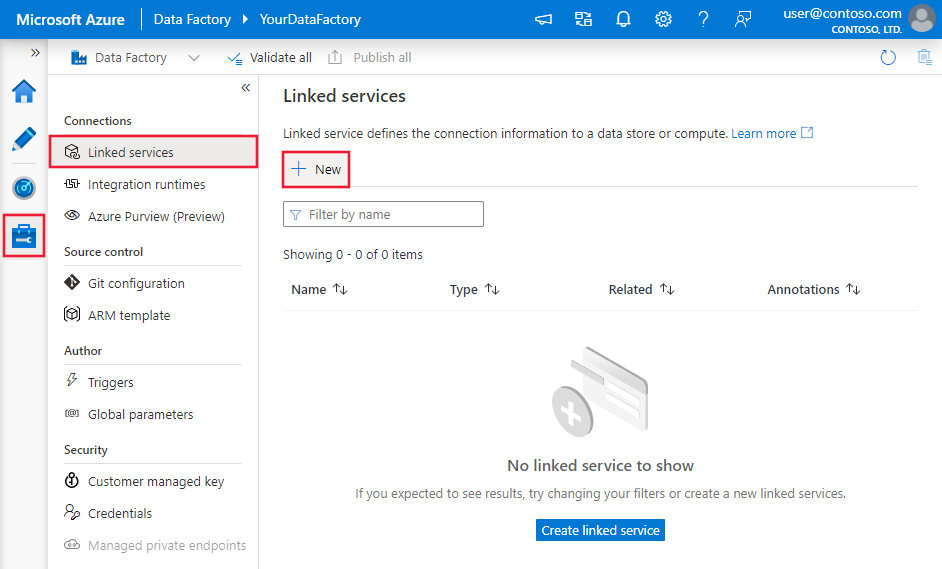
Wählen Sie im Fenster New Linked Service (Neuer verknüpfter Dienst) die Option Azure SQL-Datenbank, und klicken Sie auf Weiter.
Führen Sie im Fenster New Linked Service (Azure SQL Database) (Neuer verknüpfter Dienst (Azure SQL-Datenbank)) die folgenden Schritte aus:
a. Geben Sie unter Name den Namen AzureSqlDatabaseLinkedService ein.
b. Wählen Sie unter Servername Ihren Server aus.
c. Wählen Sie unter Datenbankname Ihre Datenbank aus.
d. Geben Sie den Namen des Benutzers ein, um eine Verbindung mit Ihrer Datenbank herzustellen.
e. Geben Sie das Kennwort für den Benutzer ein.
f. Klicken Sie auf Verbindung testen, um die Verbindung mit Ihrer Datenbank anhand der angegebenen Informationen zu testen.
g. Klicken Sie auf Erstellen, um den verknüpften Dienst zu speichern.
Erstellen des verknüpften Diensts für die Azure Synapse Analytics-Senke
Klicken Sie auf der Registerkarte Verbindungen in der Symbolleiste erneut auf + Neu.
Wählen Sie im Fenster New Linked Service (Neuer verknüpfter Dienst) die Option Azure Synapse Analytics aus, und klicken Sie auf Weiter.
Führen Sie im Fenster New Linked Service (Azure Synapse Analytics) (Neuer verknüpfter Dienst (Azure Synapse Analytics)) die folgenden Schritte aus:
a. Geben Sie unter Name den Namen AzureSqlDWLinkedService ein.
b. Wählen Sie unter Servername Ihren Server aus.
c. Wählen Sie unter Datenbankname Ihre Datenbank aus.
d. Geben Sie den Benutzernamen ein, um eine Verbindung mit Ihrer Datenbank herzustellen.
e. Geben Sie das Kennwort für den Benutzer ein.
f. Klicken Sie auf Verbindung testen, um die Verbindung mit Ihrer Datenbank anhand der angegebenen Informationen zu testen.
g. Klicken Sie auf Erstellen.
Erstellen des verknüpften Stagingdiensts Azure Storage
In diesem Tutorial wird Azure Blob Storage als vorläufiger Stagingbereich zur Aktivierung von PolyBase verwendet, um eine bessere Leistung zu erzielen.
Klicken Sie auf der Registerkarte Verbindungen in der Symbolleiste erneut auf + Neu.
Wählen Sie im Fenster New Linked Service (Neuer verknüpfter Dienst) die Option Azure Blob Storage, und klicken Sie dann auf Weiter.
Führen Sie im Fenster New Linked Service (Azure Blob Storage) (Neuer verknüpfter Dienst (Azure Blob Storage)) die folgenden Schritte aus:
a. Geben Sie unter Name die Zeichenfolge AzureStorageLinkedService ein.
b. Wählen Sie unter Speicherkontoname Ihr Azure Storage-Konto aus.c. Klicken Sie auf Erstellen.
Erstellen von Datasets
In diesem Tutorial werden Quell- und Senkendatasets erstellt, die den Speicherort der Daten angeben.
Das Eingabedataset AzureSqlDatabaseDataset verweist auf AzureSqlDatabaseLinkedService. Der verknüpfte Dienst gibt die Verbindungszeichenfolge für die Herstellung der Verbindung mit der Datenbank an. Das Dataset gibt den Namen der Datenbank und die Tabelle an, in der die Quelldaten enthalten sind.
Das Ausgabedataset AzureSqlDWDataset verweist auf AzureSqlDWLinkedService. Der verknüpfte Dienst gibt die Verbindungszeichenfolge an, die mit Azure Synapse Analytics verbunden werden soll. Das Dataset gibt die Datenbank und die Tabelle an, in die die Daten kopiert werden.
In diesem Tutorial sind die SQL-Quell- und -Zieltabellen in den Datasetdefinitionen nicht hartcodiert. Stattdessen übergibt die ForEach-Aktivität den Namen der Tabelle zur Laufzeit an die Copy-Aktivität.
Erstellen eines Datasets für die SQL-Quelldatenbank
Wählen Sie im linken Bereich die Registerkarte Autor aus.
Wählen Sie im linken Bereich + (Plus) und dann Datasetaus.
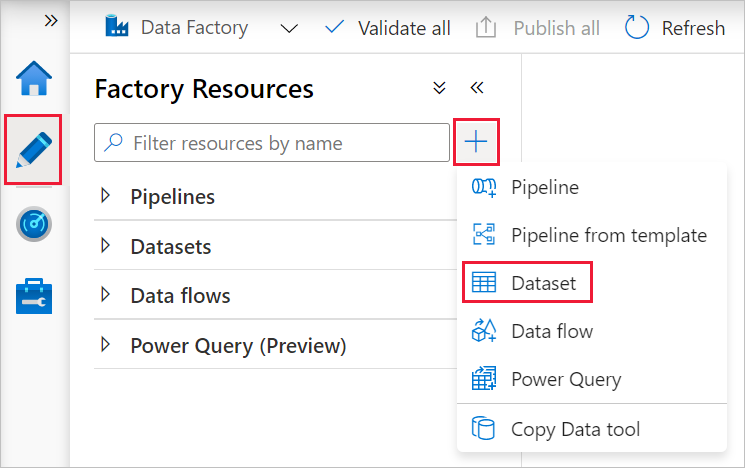
Wählen Sie im Fenster Neues Dataset die Option Azure SQL-Datenbank aus, und klicken Sie dann auf Weiter.
Geben Sie im Fenster Eigenschaften festlegen unter Name den Namen AzureSqlDatabaseDataset ein. Wählen Sie unter Verknüpfter Dienst die Option AzureSqlDatabaseLinkedService aus. Klicken Sie dann auf OK.
Wechseln Sie zur Registerkarte Verbindung, und wählen Sie unter Tabelle eine beliebige Tabelle aus. Diese Tabelle ist eine Dummytabelle. Sie geben beim Erstellen einer Pipeline im Quelldataset eine Abfrage ein. Die Abfrage wird zum Extrahieren von Daten aus Ihrer Datenbank verwendet. Alternativ hierzu können Sie auf das Kontrollkästchen Bearbeiten klicken und als Tabellenname dbo.dummyName eingeben.
Erstellen eines Datasets für die Azure Synapse Analytics-Senke
Klicken Sie im Bereich auf der linken Seite auf + (Pluszeichen) und dann auf Dataset.
Wählen Sie im Fenster Neues Dataset die Option Azure Synapse Analytics aus, und klicken Sie auf Weiter.
Geben Sie im Fenster Eigenschaften festlegen unter Name den Namen AzureSqlDWDataset ein. Wählen Sie unter Verknüpfter Dienst die Option AzureSqlDWLinkedService aus. Klicken Sie dann auf OK.
Wechseln Sie zur Registerkarte Parameter, klicken Sie auf + Neu, und geben Sie DWTableName als Parameternamen ein. Klicken Sie wieder auf + Neu, und geben Sie DWSchema als Parameternamen ein. Sorgen Sie beim Kopieren (und Einfügen) dieses Namens von der Seite dafür, dass es am Ende von DWTableName und DWSchema kein nachgestelltes Leerzeichen gibt.
Wechseln Sie zur Registerkarte Verbindung.
Aktivieren Sie für Tabelle die Option Bearbeiten. Wählen Sie das erste Eingabefeld aus, und klicken Sie unten auf den Link Dynamischen Inhalt hinzufügen. Klicken Sie auf der Seite Dynamischen Inhalt hinzufügen unter Parameter auf DWSchema. Dadurch wird das oberste Textfeld
@dataset().DWSchemafür Ausdrücke automatisch gefüllt. Klicken Sie dann auf Fertig stellen.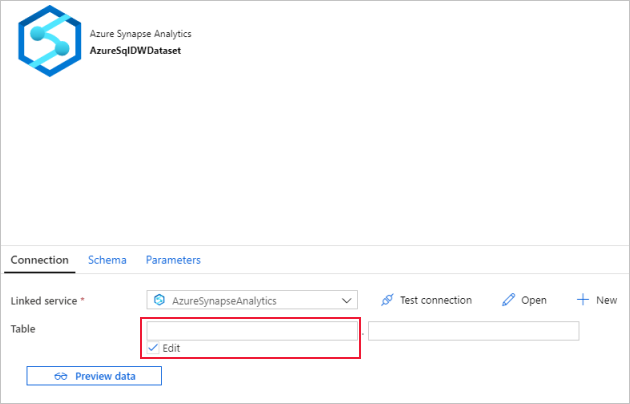
Wählen Sie das zweite Eingabefeld aus, und klicken Sie unten auf den Link Dynamischen Inhalt hinzufügen. Klicken Sie auf der Seite Dynamischen Inhalt hinzufügen unter Parameter auf DWTableName. Dadurch wird das oberste Textfeld
@dataset().DWTableNamefür Ausdrücke automatisch gefüllt. Klicken Sie dann auf Fertig stellen.Die Eigenschaft tableName des Datasets wird auf die Werte festgelegt, die als Argumente für die Parameter DWSchema und DWTableName übergeben werden. Die ForEach-Aktivität durchläuft eine Liste mit Tabellen und übergibt diese einzeln an die Copy-Aktivität.
Erstellen von Pipelines
In diesem Tutorial werden zwei Pipelines erstellt: IterateAndCopySQLTables und GetTableListAndTriggerCopyData.
Die Pipeline GetTableListAndTriggerCopyData führt zwei Aktionen aus:
- Abrufen der Systemtabelle für die Azure SQL-Datenbank, um die Liste mit den Tabellen abzurufen, die kopiert werden sollen.
- Auslösen der Pipeline IterateAndCopySQLTables, um den eigentlichen Kopiervorgang der Daten durchzuführen.
Die Pipeline IterateAndCopySQLTables akzeptiert eine Liste von Tabellen als Parameter. Für jede Tabelle in der Liste werden Daten aus der Tabelle in Azure SQL-Datenbank nach Azure Synapse Analytics kopiert. Dazu wird das gestaffelte Kopieren und PolyBase verwendet.
Erstellen der Pipeline „IterateAndCopySQLTables“
Klicken Sie im linken Bereich auf + (Pluszeichen) und dann auf Pipeline.
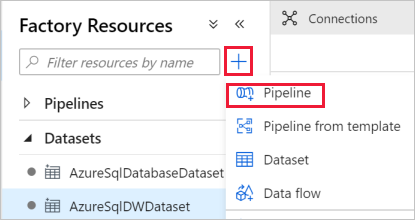
Geben Sie im Bereich „Allgemein“ unter Eigenschaften die Eigenschaft IterateAndCopySQLTables für Name an. Reduzieren Sie dann den Bereich, indem Sie in der oberen rechten Ecke auf das Symbol „Eigenschaften“ klicken.
Wechseln Sie zur Registerkarte Parameter, und führen Sie die folgenden Aktionen durch:
a. Klicken Sie auf + NEU.
b. Geben Sie tableList für den Parameter Name ein.
c. Wählen Sie unter Typ die Option Array.
Erweitern Sie in der Toolbox Aktivitäten die Option Iteration & Conditions (Iteration und Bedingungen), und ziehen Sie die ForEach-Aktivität in die Oberfläche zum Entwerfen von Pipelines. Sie können in der Toolbox Aktivitäten auch nach Aktivitäten suchen.
a. Geben Sie unten auf der Registerkarte Allgemein unter Name den Namen IterateSQLTables ein.
b. Wechseln Sie auf die Registerkarte Einstellungen, klicken Sie auf das Eingabefeld für Elemente, und klicken Sie anschließend unten auf den Link Dynamischen Inhalt hinzufügen.
c. Reduzieren Sie auf der Seite Dynamischen Inhalt hinzufügen die Abschnitte Systemvariablen und Funktionen, und klicken Sie unter Parameter auf tableList. Das oberste Textfeld für Ausdrücke wird automatisch mit
@pipeline().parameter.tableListgefüllt. Klicken Sie auf Fertig stellen.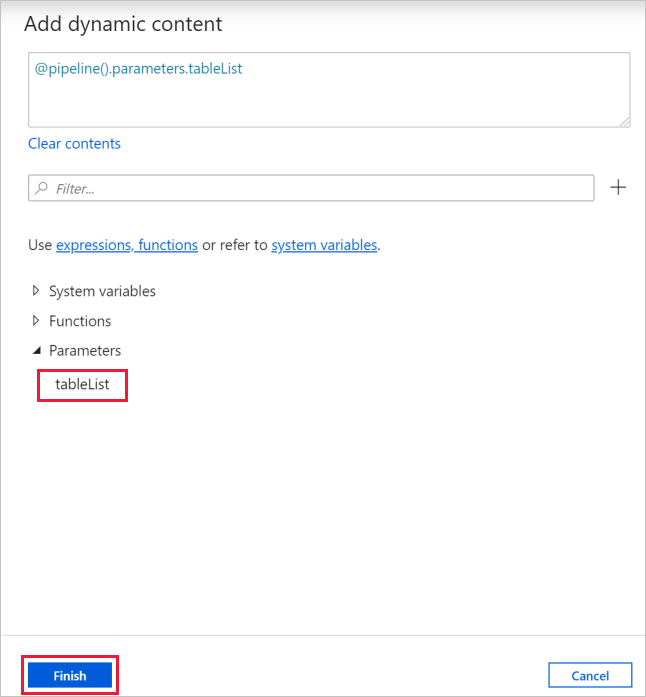
d. Wechseln Sie zur Registerkarte Aktivitäten, und klicken Sie auf das Stiftsymbol, um der Aktivität ForEach eine untergeordnete Aktivität hinzuzufügen.
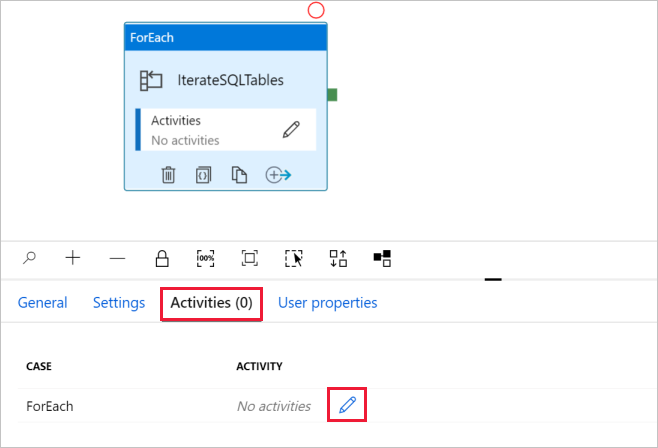
Erweitern Sie in der Toolbox Aktivitäten die Option Move & Transfer (Verschieben und übertragen), und ziehen Sie die Copy Data-Aktivität auf die Oberfläche des Pipeline-Designers. Beachten Sie das Breadcrumb-Menü im oberen Bereich. IterateAndCopySQLTable ist der Pipelinename, und IterateSQLTables ist der Name der ForEach-Aktivität. Der Designer ist Teil des Aktivitätsbereichs. Sie können im Breadcrumb-Menü auf den Link klicken, um vom ForEach-Editor zurück zum Pipeline-Editor zu wechseln.
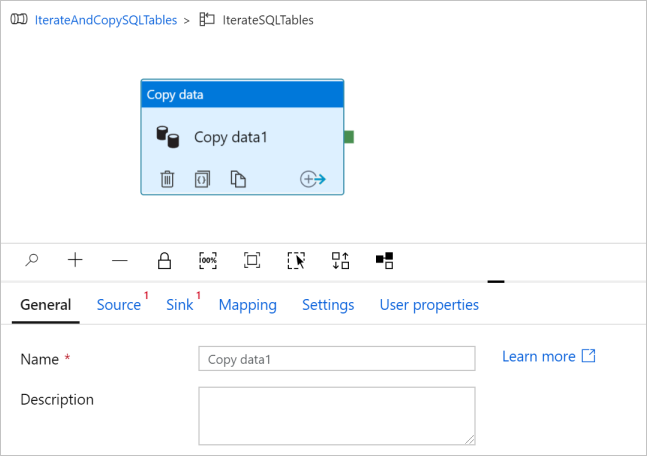
Wechseln Sie zur Registerkarte Quelle, und führen Sie die folgenden Schritte aus:
Wählen Sie unter Source Dataset (Quelldataset) die Option AzureSqlDatabaseDataset.
Wählen Sie unter Abfrage verwenden die Option Abfrage aus.
Klicken Sie auf das Eingabefeld Abfrage, >wählen Sie unten die Option Dynamischen Inhalt hinzufügen, >geben Sie den folgenden Ausdruck für Abfrage ein, und > wählen Sie Fertig stellen.
SELECT * FROM [@{item().TABLE_SCHEMA}].[@{item().TABLE_NAME}]
Wechseln Sie zur Registerkarte Senke, und führen Sie die folgenden Schritte aus:
Wählen Sie unter Sink Dataset (Senkendataset) die Option AzureSqlDWDataset.
Klicken Sie auf das Eingabefeld für den Wert (VALUE) des Parameters „DWTableName“, > wählen Sie unten die Option Dynamischen Inhalt hinzufügen aus, geben Sie den
@item().TABLE_NAMEAusdruck als Skript ein, und > wählen Sie Fertig stellen aus.Klicken Sie auf das Eingabefeld für den Wert (VALUE) des Parameters „DWSchema“, > wählen Sie unten die Option Dynamischen Inhalt hinzufügen aus, geben Sie den Ausdruck als Skript ein, und
@item().TABLE_SCHEMAwählen Sie Fertig stellen aus.Wählen Sie als Kopiermethode PolyBase aus.
Deaktivieren Sie die Option Use Type default (Typstandard verwenden).
Für „Tabellenoption“ lautet die Standardeinstellung „Keine“. Werden in der Azure Synapse Analytics-Senke keine Tabellen vorab erstellt, aktivieren Sie die Option Auto create table (Tabelle automatisch erstellen). Die Copy-Aktivität erstellt dann auf der Grundlage der Quelldaten automatisch Tabellen für Sie. Ausführliche Informationen finden Sie unter Automatisches Erstellen von Senkentabellen.
Klicken Sie auf das Eingabefeld Pre-copy Script (Skript für Vorabkopieren), > wählen Sie unten die Option Dynamischen Inhalt hinzufügen, > geben Sie den folgenden Ausdruck als Skript ein, und > wählen Sie Fertig stellen.
IF EXISTS (SELECT * FROM [@{item().TABLE_SCHEMA}].[@{item().TABLE_NAME}]) TRUNCATE TABLE [@{item().TABLE_SCHEMA}].[@{item().TABLE_NAME}]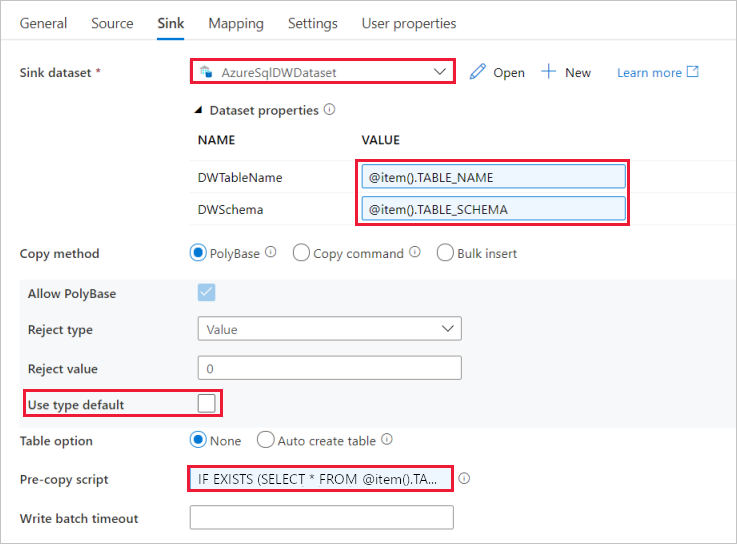
Wechseln Sie zur Registerkarte Einstellungen, und führen Sie die folgenden Schritte aus:
- Aktivieren Sie das Kontrollkästchen für Enable Staging (Staging aktivieren).
- Wählen Sie unter Store Account Linked Service (Verknüpfter Dienst des Speicherkontos) die Option AzureStorageLinkedService.
Klicken Sie zum Überprüfen der Pipelineeinstellungen auf der Symbolleiste für die Pipeline auf Überprüfen. Vergewissern Sie sich, dass keine Validierungsfehler vorliegen. Klicken Sie zum Schließen des Pipelineüberprüfungsberichts auf die doppelten spitzen Klammern >>.
Erstellen der Pipeline „GetTableListAndTriggerCopyData“
Diese Pipeline führt zwei Aktionen aus:
- Abrufen der Systemtabelle für die Azure SQL-Datenbank, um die Liste mit den Tabellen abzurufen, die kopiert werden sollen.
- Auslösen der Pipeline „IterateAndCopySQLTables“, um den eigentlichen Kopiervorgang der Daten auszuführen.
Dies sind die Schritte zum Erstellen der Pipeline:
Klicken Sie im linken Bereich auf + (Pluszeichen) und dann auf Pipeline.
Ändern Sie im Bereich „Allgemein“ unter Eigenschaften den Namen der Pipeline in GetTableListAndTriggerCopyData.
Erweitern Sie in der Toolbox Aktivitäten die Option Allgemein, und ziehen Sie die Lookup-Aktivität auf die Oberfläche des Pipeline-Designers. Führen Sie anschließend die folgenden Schritte aus:
- Geben Sie unter Name den Namen LookupTableList ein.
- Geben Sie unter Beschreibung den Text Retrieve the table list from my database (Tabellenliste aus meiner Datenbank abrufen) ein.
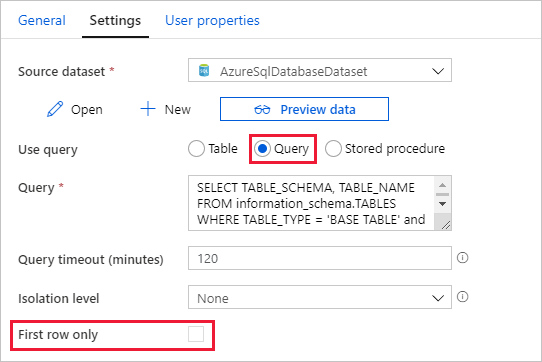
Wechseln Sie zur Registerkarte Einstellungen, und führen Sie die folgenden Schritte aus:
Wählen Sie unter Source Dataset (Quelldataset) die Option AzureSqlDatabaseDataset.
Wählen Sie unter Abfrage verwenden die Option Abfrage aus.
Geben Sie unter Abfrage die folgende SQL-Abfrage ein:
SELECT TABLE_SCHEMA, TABLE_NAME FROM information_schema.TABLES WHERE TABLE_TYPE = 'BASE TABLE' and TABLE_SCHEMA = 'SalesLT' and TABLE_NAME <> 'ProductModel'Deaktivieren Sie das Kontrollkästchen für das Feld First row only (Nur erste Zeile).
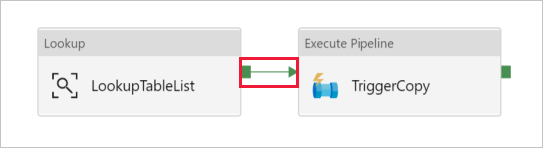
Ziehen Sie die Execute Pipeline-Aktivität aus der Toolbox „Aktivitäten“ auf die Oberfläche des Pipeline-Designers, und legen Sie den Namen auf TriggerCopy fest.
Verbinden Sie die Lookup-Aktivität mit der Execute Pipeline-Aktivität, indem Sie das grüne Feld, das der Lookup-Aktivität zugeordnet ist, in den Bereich links von der Execute Pipeline-Aktivität ziehen.
Wechseln Sie zur Registerkarte Einstellungen der Aktivität Execute Pipeline (Pipeline ausführen), und führen Sie die folgenden Schritte aus:
Wählen Sie unter Invoked pipeline (Aufgerufene Pipeline) die Option IterateAndCopySQLTables.
Deaktivieren Sie das Kontrollkästchen für Wait on completion (Auf Abschluss warten).
Klicken Sie im Abschnitt Parameter auf das Eingabefeld unter VALUE (Wert)>, wählen Sie unten die Option Dynamischen Inhalt hinzufügen aus, > geben Sie
@activity('LookupTableList').output.valueals Wert für den Tabellennamen ein, und > wählen Sie Fertigstellen aus. Sie legen die Ergebnisliste der Lookup-Aktivität als Eingabe für die zweite Pipeline fest. Die Ergebnisliste enthält die Liste mit den Tabellen, deren Daten auf das Ziel kopiert werden müssen.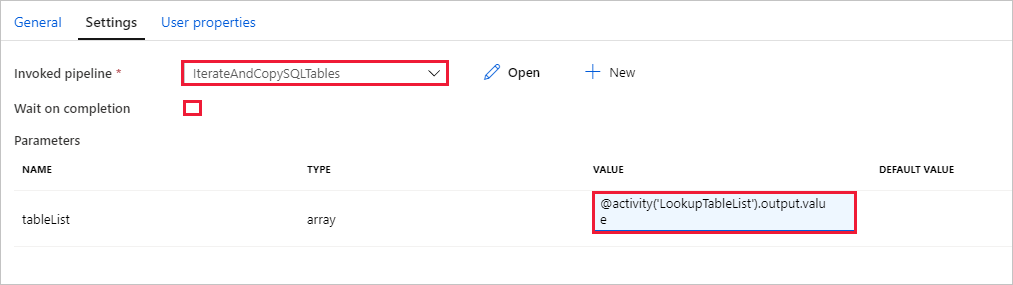
Klicken Sie zum Überprüfen der Pipeline in der Symbolleiste auf Überprüfen. Vergewissern Sie sich, dass keine Validierungsfehler vorliegen. Klicken Sie zum Schließen des Pipelineüberprüfungsberichts (Pipeline Validation Report) auf >>.
Klicken Sie zum Veröffentlichen von Entitäten (Datasets, Pipelines usw.) im Data Factory-Dienst oben im Fenster auf Alle veröffentlichen. Warten Sie, bis die Veröffentlichung erfolgreich durchgeführt wurde.
Auslösen einer Pipelineausführung
Navigieren Sie zur Pipeline GetTableListAndTriggerCopyData, und klicken Sie in der oberen Symbolleiste der Pipeline auf Add Trigger (Trigger hinzufügen) und dann auf Trigger Now (Jetzt auslösen).
Bestätigen Sie die Ausführung auf der Seite Pipeline run (Pipelineausführung), und wählen Sie dann Finish (Beenden) aus.
Überwachen der Pipelineausführung
Wechseln Sie zur Registerkarte Überwachen. Klicken Sie auf Aktualisieren, bis Ausführungen für beide Pipelines Ihrer Lösung angezeigt werden. Fahren Sie mit dem Aktualisieren der Liste fort, bis der Status Erfolgreich angezeigt wird.
Klicken Sie unter dem Link „Pipelinename“ für diese Pipeline, um die Aktivitätsausführungen anzuzeigen, die der Pipeline GetTableListAndTriggerCopyData zugeordnet sind. Es sollten zwei Aktivitätsausführungen für diese Pipelineausführung angezeigt werden.
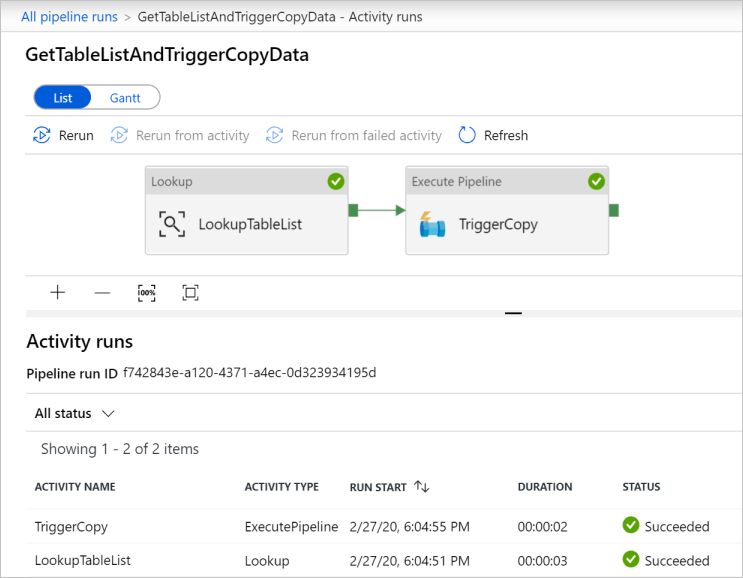
Wenn Sie die Ausgabe der Aktivität Lookup (Suche) anzeigen möchten, klicken Sie auf den Link Output (Ausgabe) neben der Aktivität in der Spalte ACTIVITY NAME (AKTIVITÄTSNAME). Sie können das Fenster Ausgabe maximieren und wiederherstellen. Klicken Sie auf X, nachdem Sie die Prüfung durchgeführt haben, um das Fenster Ausgabe zu schließen.
{ "count": 9, "value": [ { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "Customer" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "ProductDescription" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "Product" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "ProductModelProductDescription" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "ProductCategory" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "Address" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "CustomerAddress" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "SalesOrderDetail" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "SalesOrderHeader" } ], "effectiveIntegrationRuntime": "DefaultIntegrationRuntime (East US)", "effectiveIntegrationRuntimes": [ { "name": "DefaultIntegrationRuntime", "type": "Managed", "location": "East US", "billedDuration": 0, "nodes": null } ] }Durch Wählen des Links Alle Pipelineausführungen im oberen Bereich des Breadcrumb-Menüs können Sie zur Ansicht Pipeline Runs (Pipelineausführungen) zurückkehren. Klicken Sie auf den Link IterateAndCopySQLTables (in der Spalte PIPELINE NAME (PIPELINENAME)), um die Aktivitätsausführungen der Pipeline anzuzeigen. Beachten Sie, dass für jede Tabelle in der Ausgabe der Lookup-Aktivität eine Ausführung der Copy-Aktivität enthalten ist.
Vergewissern Sie sich, dass die Daten in die Azure Synapse Analytics-Zielinstanz kopiert wurden, die Sie in diesem Tutorial verwendet haben.
Zugehöriger Inhalt
In diesem Tutorial haben Sie die folgenden Schritte ausgeführt:
- Erstellen einer Data Factory.
- Erstellen verknüpfter Azure SQL-Datenbank-, Azure Synapse Analytics- und Azure Storage-Dienste
- Erstellen von Azure SQL-Datenbank- und Azure Synapse Analytics-Datasets
- Erstellen einer Pipeline zum Abrufen der zu kopierenden Tabellen und einer weiteren Pipeline zur Durchführung des eigentlichen Kopiervorgangs.
- Starten einer Pipelineausführung
- Überwachen der Pipeline- und Aktivitätsausführungen.
Fahren Sie nun mit dem folgenden Tutorial fort, um mehr über das inkrementelle Kopieren von Daten aus einer Quelle in ein Ziel zu erfahren: