Einrichten von AutoML für das Trainieren von Modellen für maschinelles Sehen
GILT FÜR: Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
In diesem Artikel erfahren Sie, wie Sie Modelle für maschinelles Sehen mithilfe automatisierter ML anhand von Bilddaten trainieren können. Sie können Modelle mit der Azure Machine Learning CLI-Erweiterung v2 oder dem Azure Machine Learning Python SDK v2 trainieren.
Automatisiertes ML unterstützt das Modelltraining für Aufgaben für maschinelles Sehen wie Bildklassifizierung, Objekterkennung und Instanzsegmentierung. Das Erstellen von AutoML-Modellen für Aufgaben des maschinellen Sehens wird derzeit über das Python-SDK für Azure Machine Learning unterstützt. Die resultierenden Versuchsausführungen, Modelle und Ausgaben sind über die Benutzeroberfläche von Azure Machine Learning Studio zugänglich. Erfahren Sie mehr über automatisiertes ML für Aufgaben des maschinellen Sehens auf Bilddaten.
Voraussetzungen
GILT FÜRAzure CLI ML-Erweiterung v2 (aktuell)
- Ein Azure Machine Learning-Arbeitsbereich. Informationen zum Erstellen des Arbeitsbereichs finden Sie unter Schnellstart: So erstellen Sie Arbeitsbereichsressourcen, die Sie für die ersten Schritte mit Azure Machine Learning benötigen.
- Installieren Sie die CLI (v2), richten Sie sie ein, und stellen Sie dann sicher, dass Sie die
ml-Erweiterung installieren.
Auswählen des Aufgabentyps
Automatisiertes maschinelles Lernen für Bilder unterstützt die folgenden Aufgabentypen:
| Aufgabentyp | AutoML-Auftragssyntax |
|---|---|
| Bildklassifizierung | CLI v2: image_classification SDK v2: image_classification() |
| Bildklassifizierung mit mehreren Beschriftungen | CLI v2: image_classification_multilabel SDK v2: image_classification_multilabel() |
| Bildobjekterkennung | CLI v2: image_object_detection SDK v2: image_object_detection() |
| Bildinstanzsegmentierung | CLI v2: image_instance_segmentation SDK v2: image_instance_segmentation() |
GILT FÜRAzure CLI ML-Erweiterung v2 (aktuell)
Dieser Aufgabentyp ist ein erforderlicher Parameter und kann mithilfe des task-Schlüssels festgelegt werden.
Beispiel:
task: image_object_detection
Trainings- und Überprüfungsdaten
Um Modelle für maschinelles Sehen zu erstellen, müssen Sie beschriftete Bilddaten als Eingabe für das Modelltraining in Form einer MLTable bereitstellen. Sie können eine MLTable aus Trainingsdaten im JSONL-Format erstellen.
Wenn Ihre Trainingsdaten in einem anderen Format vorliegen (z. B. Pascal VOC oder COCO), können Sie die in den Beispielnotebooks enthaltenen Hilfsskripts anwenden, um die Daten in JSONL zu konvertieren. Erfahren Sie mehr darüber, wie Sie Daten für Aufgaben des maschinellen Sehens mit automatisiertem maschinellen Lernen vorbereiten.
Hinweis
Die Trainingsdaten müssen über mindestens zehn Bilder verfügen, um einen Auftrag für automatisiertes ML übermitteln zu können.
Warnung
Die Erstellung einer MLTable aus Daten im JSONL-Format wird nur unterstützt, indem das SDK oder die CLI verwendet wird. Das Erstellen der MLTable über die Benutzeroberfläche wird derzeit nicht unterstützt.
JSONL-Schemabeispiele
Die Struktur von TabularDataset hängt von der Aufgabe ab. Bei den Aufgabentypen des maschinellen Sehens besteht sie aus den folgenden Feldern:
| Feld | BESCHREIBUNG |
|---|---|
image_url |
Enthält den Dateipfad als StreamInfo-Objekt |
image_details |
Die Informationen der Bildmetadaten bestehen aus Höhe, Breite und Format. Dieses Feld ist optional und daher möglicherweise nicht vorhanden. |
label |
Eine JSON-Darstellung der Bildbeschriftung basierend auf dem Aufgabentyp. |
Der folgende Code ist eine JSONL-Beispieldatei für die Bildklassifizierung:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
Der folgende Code ist ein Beispiel für eine JSONL-Datei zur Objekterkennung:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
Nutzen von Daten
Sobald Ihre Daten im JSONL-Format vorliegen, können Sie eine Trainings- und Validierungs-MLTable erstellen, wie unten gezeigt.
paths:
- file: ./train_annotations.jsonl
transformations:
- read_json_lines:
encoding: utf8
invalid_lines: error
include_path_column: false
- convert_column_types:
- columns: image_url
column_type: stream_info
Bei Aufgaben des maschinellen Sehens unterliegt die Größe der Trainings- oder Validierungsdaten keinerlei Beschränkungen durch das automatisierte maschinelle Lernen. Die maximale Größe des Datasets wird nur durch die Ebene hinter dem Dataset (Beispiel: Blobspeicher) begrenzt. Es gibt keine Mindestanzahl von Bildern oder Bezeichnungen. Wir empfehlen jedoch, mit einem Minimum von 10–15 Stichproben pro Bezeichnung zu beginnen, um sicherzustellen, dass das Ausgabemodell ausreichend trainiert ist. Je höher die Gesamtzahl der Bezeichnungen/Klassen ist, desto mehr Stichproben benötigen Sie pro Bezeichnung.
GILT FÜRAzure CLI ML-Erweiterung v2 (aktuell)
Trainingsdaten sind ein erforderlicher Parameter und werden mithilfe des training_data-Schlüssels übergeben. Sie können optional eine andere MLtable als Validierungsdaten mit dem validation_data-Schlüssel angeben. Wenn keine Validierungsdaten angegeben werden, werden standardmäßig 20 % der Trainingsdaten für die Validierung verwendet, es sei denn, Sie übergeben ein validation_data_size-Argument mit einem anderen Wert.
Der Name der Zielspalte ist ein erforderlicher Parameter und wird als Ziel für beaufsichtigte ML-Aufgaben verwendet. Er wird mithilfe des target_column_name-Schlüssels übergeben. Beispiel:
target_column_name: label
training_data:
path: data/training-mltable-folder
type: mltable
validation_data:
path: data/validation-mltable-folder
type: mltable
Computeziel zum Ausführen des Experiments
Stellen Sie ein Computeziel für automatisiertes ML zur Durchführung des Modelltrainings bereit. Automatisierte ML-Modelle für Aufgaben des maschinellen Sehens erfordern GPU-SKUs und unterstützen NC- und ND-Familien. Für ein schnelleres Training wird die NCsv3-Serie (mit v100-GPUs) empfohlen. Ein Computeziel mit einer VM-SKU für mehrere GPUs nutzt mehrere GPUs, um das Training ebenfalls zu beschleunigen. Wenn Sie ein Computeziel mit mehreren Knoten einrichten, können Sie außerdem das Training des Modells durch Parallelität bei der Abstimmung der Hyperparameter für Ihr Modell beschleunigen.
Hinweis
Wenn Sie eine Compute-Instanz als Computeziel verwenden, stellen Sie sicher, dass nicht mehrere AutoML-Aufträge gleichzeitig ausgeführt werden. Vergewissern Sie sich außerdem, dass max_concurrent_trials in Ihren Auftragsbeschränkungen auf 1 festgelegt ist.
Das Computeziel wird mithilfe des compute-Parameters übergeben. Beispiel:
GILT FÜRAzure CLI ML-Erweiterung v2 (aktuell)
compute: azureml:gpu-cluster
Konfigurieren von Experimenten
Für Aufgaben für maschinelles Sehen können Sie entweder einzelne Tests, manuelle Sweeps oder automatische Sweeps starten. Es wird empfohlen, mit einem automatischen Sweep zu beginnen, um ein erstes Baselinemodell zu erhalten. Anschließend können Sie einzelne Tests mit bestimmten Modellen und Hyperparameterkonfigurationen ausprobieren. Schließlich können Sie mit manuellen Sweeps mehrere Hyperparameterwerte in der Nähe der vielversprechenderen Modelle und Hyperparameterkonfigurationen untersuchen. Dieser Workflow in drei Schritten (automatischer Sweep, einzelne Tests, manuelle Sweeps) vermeidet das Durchsuchen des gesamten Hyperparameterbereichs, der exponentiell in der Anzahl von Hyperparametern zunimmt.
Automatische Sweeps können für viele Datasets zu wettbewerbsfähigen Ergebnissen führen. Darüber hinaus erfordern sie keine fortgeschrittenen Kenntnisse über Modellarchitekturen, berücksichtigen Hyperparameterkorrelationen und funktionieren nahtlos über verschiedene Hardwaresetups hinweg. All diese Gründe machen sie zu einer guten Option für die Anfangsphase Ihres Experimentierprozesses.
Primary metric (Primäre Metrik)
Ein AutoML-Trainingsauftrag verwendet eine primäre Metrik für die Modelloptimierung und Hyperparameteroptimierung. Die primäre Metrik hängt vom Aufgabentyp ab, wie unten gezeigt. Andere primäre Metrikwerte werden derzeit nicht unterstützt.
- Genauigkeit für Bildklassifizierung
- Schnittmenge über Vereinigungsmenge für Bildklassifizierung (Multitagklassifizierung)
- Arithmetisches Mittel der Genauigkeit für die Bildobjekterkennung
- Arithmetisches Mittel der Genauigkeit für die Bildinstanzsegmentierung
Auftragsgrenzwerte
Sie können den Ressourcenverbrauch für Ihren AutoML-Auftrag zum Bildtraining kontrollieren, indem Sie die timeout_minutes, max_trials und max_concurrent_trials für den Auftrag in den Grenzwerteinstellungen festlegen, wie im folgenden Beispiel beschrieben.
| Parameter | Detail |
|---|---|
max_trials |
Parameter für die maximale Anzahl der Tests, für die der Sweep durchgeführt wird. Muss eine ganze Zahl zwischen 1 und 1000 sein. Wenn Sie nur die Standardhyperparameter für eine bestimmte Modellarchitektur untersuchen, legen Sie diesen Parameter auf 1 fest. Der Standardwert ist 1. |
max_concurrent_trials |
Maximale Anzahl von Tests, die gleichzeitig ausgeführt werden können. Wenn dieser Wert angegeben wird, muss es sich dabei um eine ganze Zahl zwischen 1 und 100 handeln. Der Standardwert ist 1. HINWEIS: max_concurrent_trials ist intern auf max_trials begrenzt. Wenn der Benutzer z. B. max_concurrent_trials=4, max_trials=2 festlegt, werden die Werte intern auf max_concurrent_trials=2, max_trials=2 aktualisiert. |
timeout_minutes |
Die Zeitspanne in Minuten, bevor das Experiment beendet wird. Ohne eine Angabe beträgt der standardmäßige timeout_minutes-Wert für Experimente sieben Tage (maximal 60 Tage). |
GILT FÜRAzure CLI ML-Erweiterung v2 (aktuell)
limits:
timeout_minutes: 60
max_trials: 10
max_concurrent_trials: 2
Automatisches Sweeping von Modellhyperparametern (Automodus)
Wichtig
Dieses Feature ist zurzeit als öffentliche Preview verfügbar. Diese Vorschauversion wird ohne Vereinbarung zum Servicelevel bereitgestellt. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar. Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
Es ist schwierig, die beste Modellarchitektur und die besten Hyperparameter für ein Dataset vorherzusagen. Außerdem kann die für die Optimierung von Hyperparametern vorgesehene Zeit in einigen Fällen begrenzt sein. Für Aufgaben für maschinelles Sehen können Sie eine beliebige Anzahl von Tests angeben, und das System bestimmt automatisch den Bereich des Hyperparameterraums für den Sweep. Sie müssen keinen Suchbereich für Hyperparameter, keine Samplingmethode und keine Richtlinie für vorzeitiges Beenden festlegen.
Auslösen des Automodus
Sie können automatische Sweeps ausführen, indem Sie max_trials auf einen Wert größer 1 in limits festlegen und keinen Suchbereich, keine Samplingmethode und keine Beendigungsrichtlinie angeben. Wir nennen diese Funktionalität „AutoMode“. Betrachten Sie das folgende Beispiel.
GILT FÜRAzure CLI ML-Erweiterung v2 (aktuell)
limits:
max_trials: 10
max_concurrent_trials: 2
Eine Anzahl von 10 bis 20 Tests ist für viele Datasets geeignet. Das Zeitbudget für den AutoML-Auftrag kann weiterhin festgelegt werden. Dies wird jedoch nur empfohlen, wenn die einzelnen Versuche jeweils lange dauern können.
Warnung
Das Starten automatischer Sweeps über die Benutzeroberfläche wird derzeit nicht unterstützt.
Einzeltests
In einzelnen Tests steuern Sie direkt die Modellarchitektur und die Hyperparameter. Der Modellarchitektur wird über den model_name-Parameter übergeben.
Unterstützte Modellarchitekturen
In der folgenden Tabelle sind die unterstützten Modelle für jede Aufgabe des maschinellen Sehens zusammengefasst. Wenn Sie nur diese Legacymodelle verwenden, werden Ausführungen mit der Legacyruntime ausgelöst. Hierbei wird jede einzelne Ausführung oder Testversion als Befehlsauftrag übermittelt. Informationen zur Unterstützung von HuggingFace und MMDetection finden Sie weiter unten.
| Aufgabe | Modellarchitekturen | Syntax des Zeichenfolgenliteralsdefault_model* bezeichnet mit * |
|---|---|---|
| Bildklassifizierung (mehrere Klassen und mehrere Bezeichnungen) |
MobileNet: Einfache Modelle für mobile Anwendungen ResNet: Verbleibende Netzwerke ResNeSt: Netzwerke mit geteilter Aufmerksamkeit SE-ResNeXt50: Squeeze-and-Excitation-Netzwerke ViT: Vision-Transformer-Netzwerke |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224 (klein) vitb16r224* (Basis) vitl16r224 (groß) |
| Objekterkennung | YOLOv5: Einstufiges Objekterkennungsmodell Faster RCNN ResNet FPN: Zweistufige Objekterkennungsmodelle RetinaNet ResNet FPN: Klassenungleichgewicht mit Fokusverlust beheben Hinweis: YOLOv5-Modellgrößen finden Sie unter model_size-Hyperparameter. |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| Instanzsegmentierung | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn |
Unterstützte Modellarchitekturen: Hugging Face und MMDetection (Vorschau)
Mit dem neuen Back-End, das in Azure Machine Learning-Pipelines ausgeführt wird, können Sie zusätzlich alle Bildklassifizierungsmodelle aus dem Hugging Face-Hub verwenden, der Teil der Transformers-Bibliothek ist (z. B. „microsoft/beit-base-patch16-224“), sowie alle Objekterkennungs- oder Instanzsegmentierungsmodelle aus dem Model Zoo von MMDetection Version 3.1.0 (z. B. atss_r50_fpn_1x_coco).
Zusätzlich zur Unterstützung aller Modelle aus Hugging Face Transfomers und MMDetection 3.1.0 bieten wir auch eine Liste zusammengestellter Modelle aus diesen Bibliotheken in der Azure ML-Registrierung an. Diese zusammengestellten Modelle wurden gründlich getestet und verwenden in einem umfangreichen Benchmarking ausgewählte Standardhyperparameter, um ein effektives Training sicherzustellen. In der folgenden Tabelle werden diese zusammengestellten Modelle aufgeführt und kurz beschrieben.
| Aufgabe | Modellarchitekturen | Syntax des Zeichenfolgenliterals |
|---|---|---|
| Bildklassifizierung (mehrere Klassen und mehrere Bezeichnungen) |
BEiT ViT DeiT SwinV2 |
microsoft/beit-base-patch16-224-pt22k-ft22kgoogle/vit-base-patch16-224facebook/deit-base-patch16-224microsoft/swinv2-base-patch4-window12-192-22k |
| Objekterkennung | Sparse R-CNN Deformable DETR VFNet YOLOF Swin |
mmd-3x-sparse-rcnn_r50_fpn_300-proposals_crop-ms-480-800-3x_cocommd-3x-sparse-rcnn_r101_fpn_300-proposals_crop-ms-480-800-3x_coco mmd-3x-deformable-detr_refine_twostage_r50_16xb2-50e_coco mmd-3x-vfnet_r50-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-vfnet_x101-64x4d-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-yolof_r50_c5_8x8_1x_coco |
| Instanzsegmentierung | Swin | mmd-3x-mask-rcnn_swin-t-p4-w7_fpn_1x_coco |
Die Liste der zusammengestellten Modelle wird ständig aktualisiert. Sie können die aktuellste Liste der zusammengestellten Modelle für eine bestimmte Aufgabe mit dem Python SDK abrufen:
credential = DefaultAzureCredential()
ml_client = MLClient(credential, registry_name="azureml")
models = ml_client.models.list()
classification_models = []
for model in models:
model = ml_client.models.get(model.name, label="latest")
if model.tags['task'] == 'image-classification': # choose an image task
classification_models.append(model.name)
classification_models
Ausgabe:
['google-vit-base-patch16-224',
'microsoft-swinv2-base-patch4-window12-192-22k',
'facebook-deit-base-patch16-224',
'microsoft-beit-base-patch16-224-pt22k-ft22k']
Wenn Sie ein Hugging Face oder MMDetection-Modell verwenden, werden Ausführungen mithilfe von Pipelinekomponenten ausgelöst. Werden sowohl Legacy- als auch Hugging Face/MMdetection-Modelle verwendet, werden alle Ausführungen/Testversionen mithilfe von Komponenten ausgelöst.
Zusätzlich zur Steuerung der Modellarchitektur können Sie auch Hyperparameter optimieren, die für das Modelltraining verwendet werden. Während viele der verfügbar gemachten Hyperparameter modellunabhängig sind, gibt es Instanzen, in denen Hyperparameter aufgaben- oder modellspezifisch sind. Hier erfahren Sie mehr über die verfügbaren Hyperparameter für diese Instanzen.
GILT FÜRAzure CLI ML-Erweiterung v2 (aktuell)
Wenn Sie die Standard-Hyperparameterwerte für eine bestimmte Architektur (z. B. yolov5) verwenden möchten, können Sie diese mithilfe des Schlüssels „model_name“ im Abschnitt „training_parameters“ angeben. Beispiel:
training_parameters:
model_name: yolov5
Manuelles Sweepen von Modellhyperparametern
Beim Training von Modellen für maschinelles Sehen hängt die Leistung des Modells stark von den gewählten Hyperparametern ab. Häufig möchten Sie vielleicht die Hyperparameter abstimmen, um eine optimale Leistung zu erzielen. Bei Aufgaben für maschinelles Sehen können Sie für Hyperparameter einen Sweep durchführen, um die optimalen Einstellungen für Ihr Modell zu ermitteln. Dieses Feature wendet Abstimmungsfunktionen für Hyperparameter in Azure Machine Learning an. Erfahren Sie, wie Sie Hyperparameter abstimmen.
GILT FÜRAzure CLI ML-Erweiterung v2 (aktuell)
search_space:
- model_name:
type: choice
values: [yolov5]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.01
model_size:
type: choice
values: [small, medium]
- model_name:
type: choice
values: [fasterrcnn_resnet50_fpn]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.001
optimizer:
type: choice
values: [sgd, adam, adamw]
min_size:
type: choice
values: [600, 800]
Definieren des Suchbereichs für Parameter
Sie können die Modellarchitekturen und Hyperparameter definieren, die im Parameterraum durchsucht werden sollen. Sie können entweder eine einzelne Modellarchitektur oder mehrere angeben.
- Unter Individual trials (Einzelne Tests) finden Sie die Liste der unterstützten Modellarchitekturen für jeden Aufgabentyp.
- Unter Hyperparameter für Aufgaben des maschinellen Sehens finden Sie die Hyperparameter für jeden Aufgabentyp des maschinellen Sehens.
- Weitere Informationen finden Sie unter Details zu unterstützten Verteilungen für diskrete und kontinuierliche Hyperparameter.
Samplingmethoden für den Sweep
Beim Sweepen von Hyperparametern müssen Sie die Samplingmethode angeben, die für das Sweepen über den definierten Parameterraum verwendet werden soll. Derzeit werden die folgenden Samplingmethoden mit dem sampling_algorithm-Parameter unterstützt:
| Stichprobentyp | AutoML-Auftragssyntax |
|---|---|
| Zufällige Stichprobenentnahme | random |
| Rastersampling | grid |
| Bayessches Sampling | bayesian |
Hinweis
Derzeit unterstützen nur das zufällige und das Rastersampling bedingte Hyperparameterräume.
Richtlinien zum vorzeitigen Beenden
Sie können Tests mit schlechter Leistung mit einer Richtlinie für vorzeitige Beendigung automatisch beenden. Eine vorzeitige Beendigung verbessert die Effizienz der Berechnungen und spart Computeressourcen, die sonst für weniger vielversprechende Tests verwendet worden wären. Automatisiertes ML für Bilder unterstützt die folgenden Richtlinien zur vorzeitigen Beendigung mithilfe des early_termination-Parameters. Wenn keine Richtlinie für die Beendigung angegeben wird, werden alle Tests bis zum Ende ausgeführt.
| Richtlinie für vorzeitige Beendigung | AutoML-Auftragssyntax |
|---|---|
| Banditenrichtlinie | CLI v2: bandit SDK v2: BanditPolicy() |
| Medianstopprichtlinie | CLI v2: median_stopping SDK v2: MedianStoppingPolicy() |
| Kürzungsauswahlrichtlinie | CLI v2: truncation_selection SDK v2: TruncationSelectionPolicy() |
Erfahren Sie mehr darüber, wie Sie die Richtlinie für die vorzeitige Beendigung Ihres Hyperparameter-Sweeps konfigurieren.
Hinweis
Ein vollständiges Beispiel für die Sweep-Konfiguration finden Sie in diesem Tutorial.
Sie können alle Sweeping-bezogenen Parameter wie im folgenden Beispiel dargestellt konfigurieren.
GILT FÜRAzure CLI ML-Erweiterung v2 (aktuell)
sweep:
sampling_algorithm: random
early_termination:
type: bandit
evaluation_interval: 2
slack_factor: 0.2
delay_evaluation: 6
Feste Einstellungen
Sie können feste Einstellungen oder Parameter, die sich während der Durchführung des Sweepings des Parameterraums nicht ändern, übergeben (wie im folgenden Beispiel gezeigt).
GILT FÜRAzure CLI ML-Erweiterung v2 (aktuell)
training_parameters:
early_stopping: True
evaluation_frequency: 1
Datenerweiterung
Im Allgemeinen kann die Leistung von Deep-Learning-Modellen mit mehr Daten verbessert werden. Die Datenerweiterung ist ein praktisches Verfahren zur Vergrößerung des Datenumfangs und der Variabilität eines Datasets, das dazu beiträgt, eine Überanpassung zu verhindern und die Generalisierungsfähigkeit des Modells auf unbekannte Daten zu verbessern. Automatisiertes ML wendet je nach Aufgabe des maschinellen Sehens verschiedene Verfahren zur Datenerweiterung an, bevor die Eingabebilder dem Modell zugeführt werden. Derzeit gibt es keine Hyperparameter zur Steuerung von Datenerweiterungen.
| Aufgabe | Betroffenes Dataset | Angewendete Verfahren zur Datenerweiterung |
|---|---|---|
| Bildklassifizierung (mehrere Klassen und mehrere Beschriftungen) | Weiterbildung Validierung und Test |
Zufällige Größenänderung und Zuschnitt, horizontales Spiegeln, Farbverschiebung (Helligkeit, Kontrast, Sättigung und Farbton), Normalisierung unter Verwendung des Mittelwerts und der Standardabweichung von ImageNet nach Kanälen Größenänderung, zentraler Zuschnitt, Normalisierung |
| Objekterkennung, Instanzsegmentierung | Weiterbildung Validierung und Test |
Zufälliger Zuschnitt um Begrenzungsrahmen, Erweiterung, horizontale Spiegelung, Normalisierung, Größenänderung Normalisierung, Größenänderung |
| Objekterkennung mit yolov5 | Weiterbildung Validierung und Test |
Mosaik, zufällige Affinität (Rotation, Übersetzung, Skalierung, Neigung), horizontale Spiegelung Größenänderung für Letterbox |
Derzeit werden die oben definierten Erweiterungen standardmäßig auf einen Auftrag für automatisiertes maschinelles Lernen für Bilder angewendet. Eine Steuerung der Erweiterungen ist über zwei Flags möglich, die vom automatisierten maschinellen Lernen für Bilder verfügbar gemacht werden und zum Deaktivieren bestimmter Erweiterungen dienen. Aktuell werden diese Flags nur für Aufgaben zur Objekterkennung und Instanzsegmentierung unterstützt.
- apply_mosaic_for_yolo: Dieses Flag ist nur für das Yolo-Modell spezifisch. Wenn es auf False festgelegt ist, ist die Mosaikdatenerweiterung deaktiviert, die zur Trainingszeit angewendet wird.
- apply_automl_train_augmentations: Durch das Festlegen dieses Flags auf False wird die während der Trainingszeit angewendete Erweiterung für die Modelle zur Objekterkennung und Instanzsegmentierung deaktiviert. Informationen zu Erweiterungen finden Sie in den Details in der Tabelle oben.
- Bei Modellen zur Objekterkennung und Instanzsegmentierung, die nicht auf Yolo basieren, deaktiviert dieses Flag nur die ersten drei Erweiterungen. Beispiel: Zufälliger Zuschnitt um Begrenzungsrahmen, Erweiterung, horizontales Kippen. Die Erweiterungen zur Normalisierung und Größenänderung werden unabhängig von diesem Flag weiterhin angewendet.
- Für das Yolo-Modell deaktiviert dieses Flag die zufälligen affinen und horizontalen Kipperweiterungen.
Diese beiden Flags werden über advanced_settings unter training_parameters unterstützt und können wie folgt gesteuert werden.
GILT FÜRAzure CLI ML-Erweiterung v2 (aktuell)
training_parameters:
advanced_settings: >
{"apply_mosaic_for_yolo": false}
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false}
Beachten Sie, dass diese beiden Flags unabhängig voneinander sind und mit den folgenden Einstellungen auch in Kombination verwendet werden können.
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false, "apply_mosaic_for_yolo": false}
In unseren Experimenten haben wir festgestellt, dass diese Erweiterungen dem Modell helfen, besser zu generalisieren. Wenn diese Erweiterungen deaktiviert sind, empfehlen wir den Benutzern daher, sie mit anderen Offlineerweiterungen zu kombinieren, um bessere Ergebnisse zu erzielen.
Inkrementelles Training (optional)
Nachdem der Trainingsauftrag durchgeführt wurde, haben Sie die Möglichkeit, das Modell weiter zu trainieren, indem Sie den Prüfpunkt des trainierten Modells laden. Sie können entweder das gleiche Dataset oder ein anderes Dataset für das inkrementelle Training verwenden. Wenn Sie mit dem Modell zufrieden sind, können Sie das Training beenden und das aktuelle Modell verwenden.
Übergeben des Prüfpunkts über die Auftrags-ID
Sie können die Auftrags-ID übergeben, aus der Sie den Prüfpunkt laden möchten.
GILT FÜRAzure CLI ML-Erweiterung v2 (aktuell)
training_parameters:
checkpoint_run_id : "target_checkpoint_run_id"
Übermitteln des AutoML-Auftrags
GILT FÜRAzure CLI ML-Erweiterung v2 (aktuell)
Zum Übermitteln Ihres AutoML-Auftrags führen Sie den folgenden CLI v2-Befehl mit dem Pfad zu Ihrer YML-Datei, dem Arbeitsbereichsnamen, der Ressourcengruppe und der Abonnement-ID aus.
az ml job create --file ./hello-automl-job-basic.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Ausgaben und Auswertungsmetriken
Die automatisierten ML-Trainingsaufträge generieren Ausgabemodelldateien, Auswertungsmetriken, Protokolle und Bereitstellungsartefakte wie die Bewertungsdatei und die Umgebungsdatei. Diese Dateien und Metriken können auf der Registerkarte „Ausgaben und Protokolle und Metriken“ der untergeordneten Aufträge angezeigt werden.
Tipp
Prüfen Sie im Abschnitt Anzeigen von Auftragsergebnissen, wie Sie zu den Auftragsergebnissen navigieren können.
Definitionen und Beispiele für die Leistungsdiagramme und Metriken, die für jeden Auftrag bereitgestellt werden, finden Sie unter Auswerten der Ergebnisse von Experimenten des automatisierten maschinellen Lernens.
Registrieren und Bereitstellen von Modellen
Nach Abschluss des Auftrags können Sie das Modell registrieren, das aus dem besten Test erstellt wurde (Konfiguration, die zur besten primären Metrik führte). Sie können das Modell entweder nach dem Herunterladen registrieren oder indem Sie den azureml-Pfad mit der entsprechenden Auftrags-ID angeben. Hinweis: Wenn Sie die unten beschriebenen Einstellungen für den Rückschluss ändern möchten, müssen Sie das Modell herunterladen und die Datei „settings.json“ ändern und die Registrierung mithilfe des aktualisierten Modellordners durchführen.
Abrufen des besten Tests
GILT FÜRAzure CLI ML-Erweiterung v2 (aktuell)
CLI example not available, please use Python SDK.
Registrieren des Modells
Registrieren Sie das Modell entweder mithilfe des azureml-Pfads oder Ihres lokal heruntergeladenen Pfads.
GILT FÜRAzure CLI ML-Erweiterung v2 (aktuell)
az ml model create --name od-fridge-items-mlflow-model --version 1 --path azureml://jobs/$best_run/outputs/artifacts/outputs/mlflow-model/ --type mlflow_model --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Nachdem Sie das Modell, das Sie verwenden möchten, registriert haben, können Sie es mithilfe des verwalteten Onlineendpunkts deploy-managed-online-endpoint bereitstellen.
Konfigurieren des Online-Endpunkts
GILT FÜRAzure CLI ML-Erweiterung v2 (aktuell)
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: od-fridge-items-endpoint
auth_mode: key
Erstellen des Endpunkts
Mit dem zuvor erstellten MLClient erstellen wir jetzt den Endpunkt im Arbeitsbereich. Dieser Befehl startet die Endpunkterstellung und gibt eine Bestätigungsantwort zurück, während die Endpunkterstellung fortgesetzt wird.
GILT FÜRAzure CLI ML-Erweiterung v2 (aktuell)
az ml online-endpoint create --file .\create_endpoint.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Konfigurieren der Onlinebereitstellung
Eine Einrichtung ist ein Satz von Ressourcen, die für das Hosting des Modells erforderlich sind, das die eigentliche Inferenz durchführt. Wir erstellen eine Bereitstellung für unseren Endpunkt mithilfe der ManagedOnlineDeployment Klasse. Sie können entweder GPU- oder CPU-VM-SKUs für Ihren Bereitstellungscluster verwenden.
GILT FÜRAzure CLI ML-Erweiterung v2 (aktuell)
name: od-fridge-items-mlflow-deploy
endpoint_name: od-fridge-items-endpoint
model: azureml:od-fridge-items-mlflow-model@latest
instance_type: Standard_DS3_v2
instance_count: 1
liveness_probe:
failure_threshold: 30
success_threshold: 1
timeout: 2
period: 10
initial_delay: 2000
readiness_probe:
failure_threshold: 10
success_threshold: 1
timeout: 10
period: 10
initial_delay: 2000
Erstellen der Bereitstellung
Mit der MLClient zuvor erstellten Version erstellen wir nun die Bereitstellung im Arbeitsbereich. Dieser Befehl startet die Bereitstellungserstellung und gibt eine Bestätigungsantwort zurück, während die Bereitstellungserstellung fortgesetzt wird.
GILT FÜRAzure CLI ML-Erweiterung v2 (aktuell)
az ml online-deployment create --file .\create_deployment.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Datenverkehr aktualisieren:
Standardmäßig ist die aktuelle Bereitstellung so festgelegt, dass sie 0 % Datenverkehr empfängt. können Sie den Prozentsatz des Datenverkehrs festlegen, den die aktuelle Bereitstellung erhalten soll. Die Summe der prozentualen Anteile des Datenverkehrs aller Bereitstellungen mit einem Endpunkt sollte 100 % nicht überschreiten.
GILT FÜRAzure CLI ML-Erweiterung v2 (aktuell)
az ml online-endpoint update --name 'od-fridge-items-endpoint' --traffic 'od-fridge-items-mlflow-deploy=100' --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Alternativ können Sie das Modell über die Azure Machine Learning Studio-Benutzeroberfläche bereitstellen. Navigieren Sie auf der Registerkarte Modelle des Auftrags für automatisiertes ML zu dem Modell, das Sie bereitstellen möchten, und wählen Sie Bereitstellen und dann Auf Echtzeitendpunkt bereitstellen aus.
 .
.
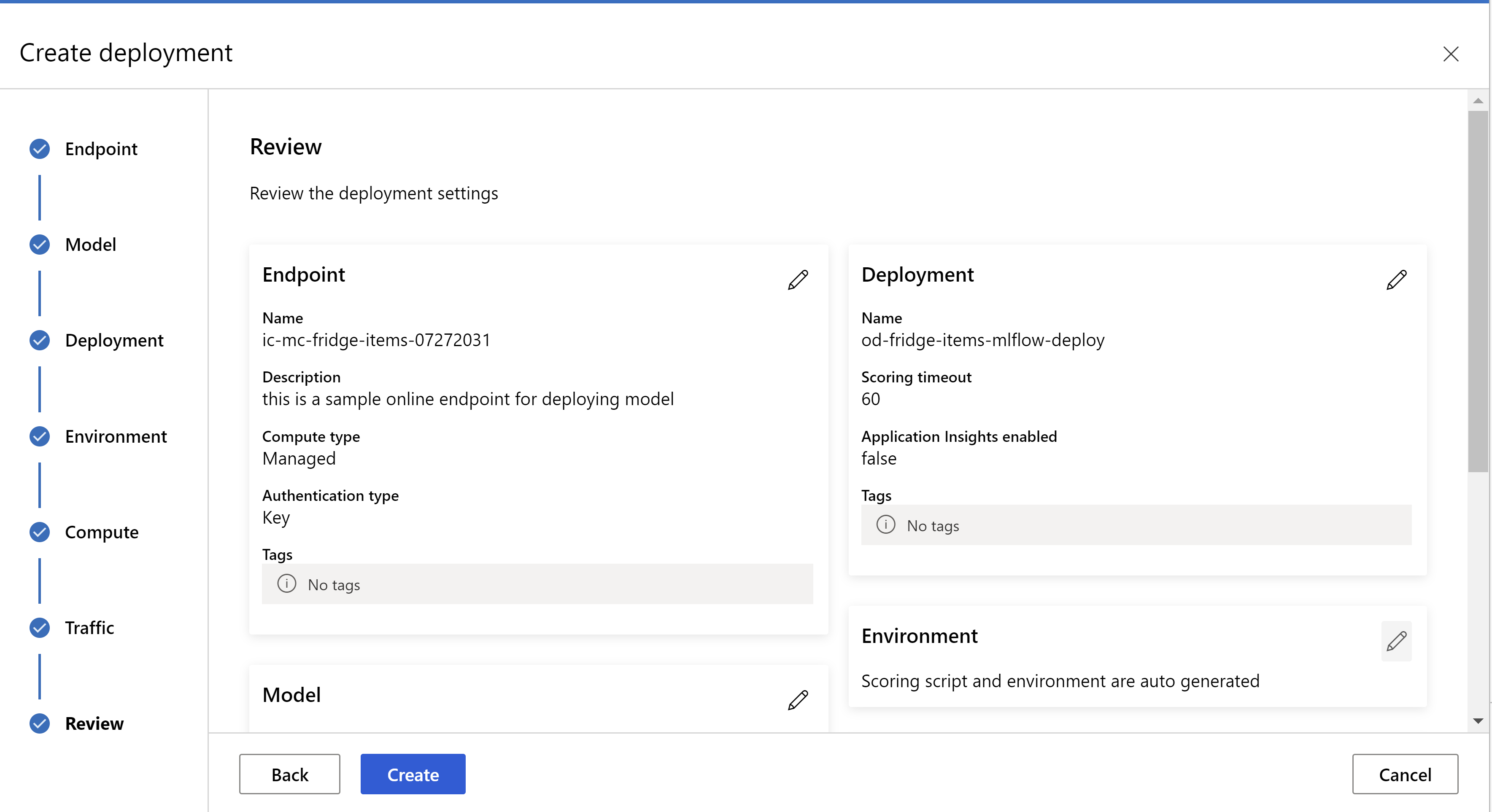
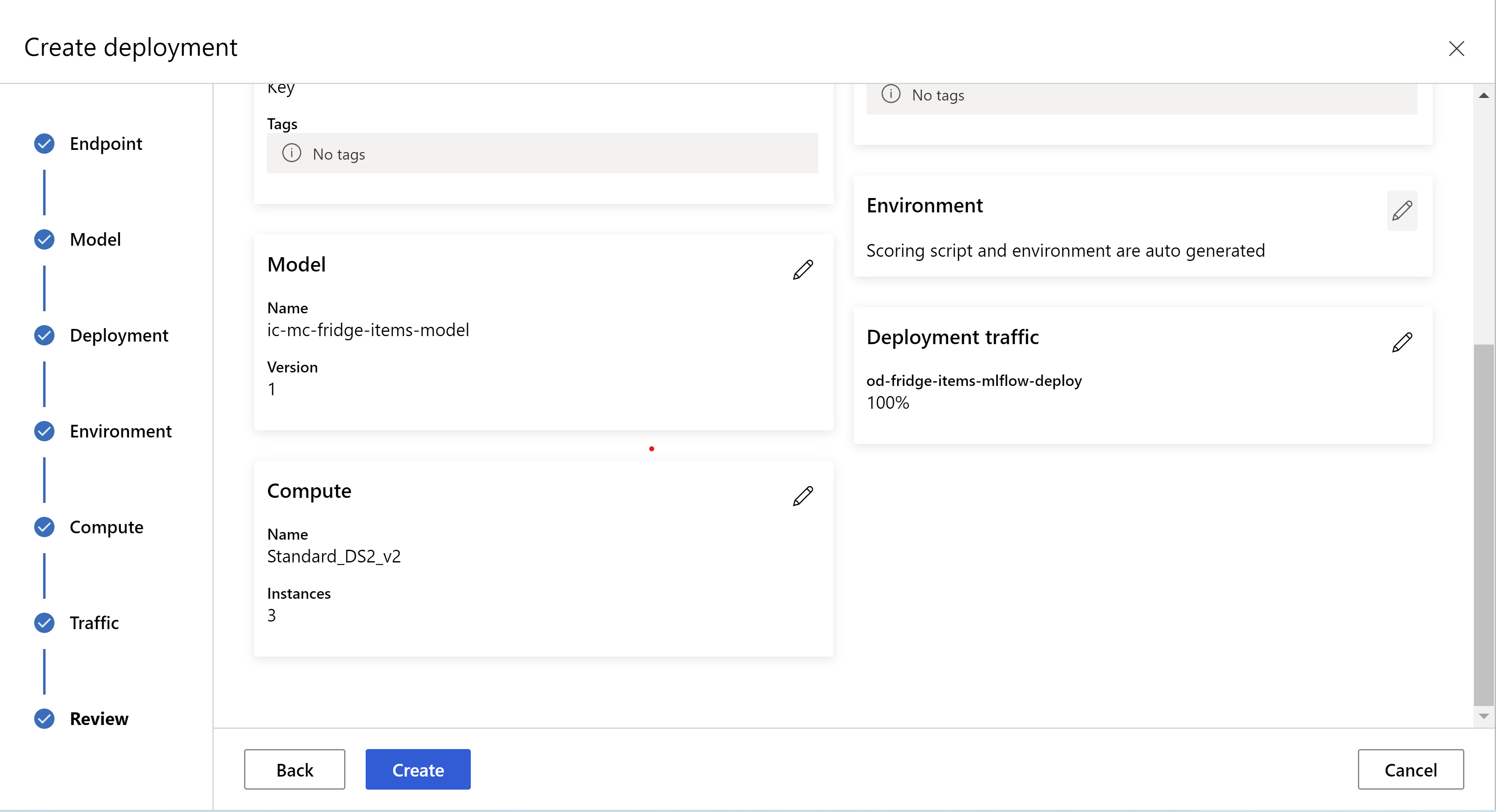
So sieht Ihre Überprüfungsseite aus. Wir können den Instanztyp und die Anzahl der Instanzen auswählen und den Prozentsatz des Datenverkehrs für die aktuelle Bereitstellung festlegen.
 .
.
 .
.
Aktualisieren der Rückschlusseinstellungen
Im vorherigen Schritt haben wir eine Datei mlflow-model/artifacts/settings.json des besten Modells heruntergeladen. Sie können diese verwenden, um die Einstellungen für den Rückschluss zu aktualisieren, bevor Sie das Modell registrieren. Es wird jedoch empfohlen, die gleichen Parameter wie beim Training zu verwenden, um die beste Leistung zu erzielen.
Jede der Aufgaben (und einige Modelle) verfügt über eine Reihe von Parametern. Standardmäßig verwenden wir dieselben Werte für die Parameter, die während des Trainings und der Validierung verwendet wurden. Abhängig vom Verhalten, das beim Verwenden des Modells für Rückschlüsse benötigt wird, können wir diese Parameter ändern. Im Folgenden finden Sie eine Liste der Parameter für jeden Aufgabentyp und jedes Modell.
| Aufgabe | Parametername | Standard |
|---|---|---|
| Bildklassifizierung (mehrere Klassen und mehrere Beschriftungen) | valid_resize_sizevalid_crop_size |
256 224 |
| Objekterkennung | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0,3 0.5 100 |
Objekterkennung mit yolov5 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 mittel 0,1 0.5 |
| Instanzsegmentierung | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0,3 0.5 100 0.5 100 False JPG |
Eine ausführliche Beschreibung zu aufgabenspezifischen Hyperparametern finden Sie unter Hyperparameter für Aufgaben im Bereich maschinelles Sehen beim automatisierten maschinellen Lernen.
Wenn Sie Kacheln verwenden und das Kachelverhalten steuern möchten, sind die folgenden Parameter verfügbar: tile_grid_size, tile_overlap_ratio und tile_predictions_nms_thresh. Weitere Informationen zu diesen Parametern finden Sie unter Trainieren eines Erkennungsmodells für kleine Objekte mit AutoML.
Testen der Bereitstellung
Lesen Sie die Informationen in diesem Abschnitt Testen der Bereitstellung, um die Bereitstellung zu testen und die Erkennungen aus dem Modell zu visualisieren.
Generieren von Erklärungen für Vorhersagen
Wichtig
Diese Einstellungen sind derzeit in der öffentlichen Vorschau. Sie werden ohne Vereinbarung zum Servicelevel bereitgestellt. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar. Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
Warnung
Die Modellerklärbarkeit wird nur für die Klassifizierung mit mehreren Klassen und die Klassifizierung mit mehreren Bezeichnungen unterstützt.
Einige Vorteile der Verwendung von erklärbarer KI (Explainable AI, XAI) in AutoML for Images:
- Verbessert die Transparenz in Vorhersagen komplexer Vision-Modelle
- Hilft den Benutzern, die wichtigen Features/Pixel im Eingabebild zu verstehen, die zu den Modellvorhersagen beitragen
- Hilft bei der Problembehandlung für Modelle
- Hilft bei der Ermittlung von Trends
Erklärungen
Erklärungen sind Featurezuordnungen oder Gewichtungen, die jedem Pixel im Eingabebild basierend auf seinem Beitrag zur Vorhersage des Modells zugewiesen werden. Jede Gewichtung kann negativ (negative Korrelation mit der Vorhersage) oder positiv (positive Korrelation mit der Vorhersage) sein. Diese Zuordnungen werden für die vorhergesagte Klasse berechnet. Bei der Klassifizierung mit mehreren Klassen wird pro Stichprobe genau eine Zuordnungsmatrix der Größe [3, valid_crop_size, valid_crop_size] generiert, während für die Klassifizierung mit mehreren Bezeichnungen die Zuordnungsmatrix der Größe [3, valid_crop_size, valid_crop_size] für jede vorhergesagte Bezeichnung/Klasse für jede Stichprobe generiert wird.
Mithilfe von erklärbarer KI in AutoML for Images auf dem bereitgestellten Endpunkt können Benutzer Visualisierungen von Erklärungen (Zuordnungen, die ein Eingabebild überlagern) und/oder Zuordnungen (mehrdimensionales Array der Größe [3, valid_crop_size, valid_crop_size]) für jedes Bild abrufen. Neben Visualisierungen können Benutzer auch Zuordnungsmatrizen abrufen, um mehr Kontrolle über die Erklärungen zu erhalten (z. B. das Generieren benutzerdefinierter Visualisierungen mithilfe von Zuordnungen oder das Überprüfen von Zuordnungssegmenten). Alle Erklärungsalgorithmen verwenden zugeschnittene quadratische Bilder der Größe valid_crop_size zum Generieren von Zuordnungen.
Erklärungen können entweder vom Onlineendpunkt oder vom Batchendpunkt generiert werden. Sobald die Bereitstellung abgeschlossen ist, kann dieser Endpunkt verwendet werden, um die Erklärungen für Vorhersagen zu generieren. Stellen Sie bei einer Onlinebereitstellung sicher, dass Sie den Parameter request_settings = OnlineRequestSettings(request_timeout_ms=90000) an ManagedOnlineDeployment übergeben und request_timeout_ms auf den Höchstwert festlegen, um Timeoutprobleme beim Generieren von Erklärungen zu vermeiden (siehe Abschnitt Registrieren und Bereitstellen von Modellen). Einige der Erklärbarkeitsmethoden (Explainability, XAI) wie xrai benötigen mehr Zeit (insbesondere für die Klassifizierung mit mehreren Bezeichnungen, da wir Zuordnungen und/oder Visualisierungen für jede vorhergesagte Bezeichnung generieren müssen). Wir empfehlen daher eine GPU-Instanz für schnellere Erklärungen. Weitere Informationen zum Eingabe- und Ausgabeschema zum Generieren von Erklärungen finden Sie in der Schemadokumentation.
Wir unterstützen die folgenden hochmodernen Erklärungsalgorithmen in AutoML for Images:
- XRAI (xrai)
- Integrierte Gradienten (integrated_gradients)
- Gesteuerte GradCAM (guided_gradcam)
- Gesteuerte BackPropagation (guided_backprop)
In der folgenden Tabelle werden die spezifischen Optimierungsparameter des Erklärungsalgorithmus für XRAI und integrierte Gradienten beschrieben. Für gesteuerte Backpropagation und GradCAM sind keine Optimierungsparameter erforderlich.
| XAI-Algorithmus | Algorithmusspezifische Parameter | Standardwerte |
|---|---|---|
xrai |
1. n_steps: Die Anzahl der Schritte, die von der Annäherungsmethode verwendet werden. Eine größere Anzahl von Schritten führt zu besseren Annäherungen an die Zuordnungen (Erklärungen). Der Bereich von n_steps ist [2, inf), aber die Leistung von Zuordnungen beginnt nach 50 Schritten zu konvergieren. Optional, Int 2. xrai_fast: Gibt an, ob eine schnellere Version von XRAI verwendet werden soll. Bei True ist die Berechnungszeit für Erklärungen kürzer, führt jedoch zu weniger genauen Erklärungen (Zuordnungen). Optional, Bool |
n_steps = 50 xrai_fast = True |
integrated_gradients |
1. n_steps: Die Anzahl der Schritte, die von der Annäherungsmethode verwendet werden. Eine größere Anzahl von Schritten führt zu besseren Zuordnungen (Erklärungen). Der Bereich von n_steps ist [2, inf), aber die Leistung von Zuordnungen beginnt nach 50 Schritten zu konvergieren.Optional, Int 2. approximation_method: Methode zur Annäherung an das Integral. Verfügbare Annäherungsmethoden sind riemann_middle und gausslegendre.Optional, String |
n_steps = 50 approximation_method = riemann_middle |
Intern verwendet der XRAI-Algorithmus integrierte Gradienten. Daher ist der Parameter n_steps sowohl für integrierte Gradienten als auch für XRAI-Algorithmen erforderlich. Eine größere Anzahl von Schritten benötigt mehr Zeit für die Annäherung an die Erklärungen, und dies kann zu Timeoutproblemen auf dem Onlineendpunkt führen.
Für bessere Erklärungen wird die folgende Reihenfolge der Algorithmen empfohlen: XRAI > Gesteuerte GradCAM > Integrierte Gradienten > Gesteuerte BackPropagation. Für schnellere Erklärungen empfiehlt sich hingegen die folgende Reihenfolge: Gesteuerte BackPropagation > Gesteuerte GradCAM > Integrierte Gradienten > XRAI.
Eine Beispielanforderung an den Onlineendpunkt sieht wie unten gezeigt aus. Diese Anforderung generiert Erklärungen, wenn model_explainability auf True festgelegt ist. Die folgende Anforderung generiert Visualisierungen und Zuordnungen mithilfe einer schnelleren Version des XRAI-Algorithmus mit 50 Schritten.
import base64
import json
def read_image(image_path):
with open(image_path, "rb") as f:
return f.read()
sample_image = "./test_image.jpg"
# Define explainability (XAI) parameters
model_explainability = True
xai_parameters = {"xai_algorithm": "xrai",
"n_steps": 50,
"xrai_fast": True,
"visualizations": True,
"attributions": True}
# Create request json
request_json = {"input_data": {"columns": ["image"],
"data": [json.dumps({"image_base64": base64.encodebytes(read_image(sample_image)).decode("utf-8"),
"model_explainability": model_explainability,
"xai_parameters": xai_parameters})],
}
}
request_file_name = "sample_request_data.json"
with open(request_file_name, "w") as request_file:
json.dump(request_json, request_file)
resp = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name=deployment.name,
request_file=request_file_name,
)
predictions = json.loads(resp)
Weitere Informationen zum Generieren von Erklärungen finden Sie im GitHub-Notebook-Repository für Beispiele zum automatisierten maschinellen Lernen.
Interpretieren von Visualisierungen
Der bereitgestellte Endpunkt gibt eine Base64-codierte Imagezeichenfolge zurück, wenn sowohl model_explainability als auch visualizations auf True festgelegt sind. Decodieren Sie die Base64-Zeichenfolge wie unter Notebooks beschrieben, oder verwenden Sie den folgenden Code, um die Base64-Bildzeichenfolgen in der Vorhersage zu decodieren und zu visualisieren.
import base64
from io import BytesIO
from PIL import Image
def base64_to_img(base64_img_str):
base64_img = base64_img_str.encode("utf-8")
decoded_img = base64.b64decode(base64_img)
return BytesIO(decoded_img).getvalue()
# For Multi-class classification:
# Decode and visualize base64 image string for explanations for first input image
# img_bytes = base64_to_img(predictions[0]["visualizations"])
# For Multi-label classification:
# Decode and visualize base64 image string for explanations for first input image against one of the classes
img_bytes = base64_to_img(predictions[0]["visualizations"][0])
image = Image.open(BytesIO(img_bytes))
Die folgende Abbildung beschreibt die Visualisierung von Erklärungen für ein Beispieleingabebild.

Die decodierte Base64-Abbildung weist vier Bildabschnitte innerhalb eines Rasters von 2 x 2 auf.
- Das Bild oben links (0, 0) ist das zugeschnittene Eingabebild.
- Das Bild oben rechts (0, 1) ist das Wärmebild der Zuordnungen auf einer Farbskala vom Typ BGYW (Blue, Green, Yellow, White; Blau, Grün, Gelb, Weiß), wobei der Anteil der weißen Pixel in der vorhergesagten Klasse am höchsten und der Anteil der blauen Pixel am geringsten ist.
- Das Bild unten links (1, 0) ist ein gemischtes Wärmebild der Zuordnungen im zugeschnittenen Eingabebild.
- Das Bild unten rechts (1, 1) ist das zugeschnittene Eingabebild mit den oberen 30 Prozent der Pixel basierend auf Zuordnungsbewertungen.
Interpretieren von Zuordnungen
Der bereitgestellte Endpunkt gibt Zuordnungen zurück, wenn model_explainability und attributions auf True festgelegt sind. Weitere Informationen finden Sie unter Notebooks für Klassifizierung mit mehreren Klassen und Klassifizierung mit mehreren Bezeichnungen .
Diese Zuordnungen geben den Benutzern mehr Kontrolle, um benutzerdefinierte Visualisierungen zu generieren oder Bewertungen der Zuordnung auf Pixelebene zu überprüfen. Der unten gezeigte Codeausschnitt beschreibt eine Möglichkeit zum Generieren benutzerdefinierter Visualisierungen mithilfe der Zuordnungsmatrix. Weitere Informationen zum Schema der Zuordnungen für die Klassifizierung mit mehreren Klassen und die Klassifizierung mit mehreren Bezeichnungen finden Sie in der Schemadokumentation.
Verwenden Sie die exakten valid_resize_size- und valid_crop_size-Werte des ausgewählten Modells, um die Erklärungen zu generieren (Standardwerte sind 256 bzw. 224). Der folgende Code verwendet die Visualisierungsfunktionalität Captum, um benutzerdefinierte Visualisierungen zu generieren. Benutzer können jede andere Bibliothek zum Generieren von Visualisierungen verwenden. Ausführlichere Informationen finden Sie in den Hilfsprogrammen zur Captum-Visualisierung.
import colorcet as cc
import numpy as np
from captum.attr import visualization as viz
from PIL import Image
from torchvision import transforms
def get_common_valid_transforms(resize_to=256, crop_size=224):
return transforms.Compose([
transforms.Resize(resize_to),
transforms.CenterCrop(crop_size)
])
# Load the image
valid_resize_size = 256
valid_crop_size = 224
sample_image = "./test_image.jpg"
image = Image.open(sample_image)
# Perform common validation transforms to get the image used to generate attributions
common_transforms = get_common_valid_transforms(resize_to=valid_resize_size,
crop_size=valid_crop_size)
input_tensor = common_transforms(image)
# Convert output attributions to numpy array
# For Multi-class classification:
# Selecting attribution matrix for first input image
# attributions = np.array(predictions[0]["attributions"])
# For Multi-label classification:
# Selecting first attribution matrix against one of the classes for first input image
attributions = np.array(predictions[0]["attributions"][0])
# visualize results
viz.visualize_image_attr_multiple(np.transpose(attributions, (1, 2, 0)),
np.array(input_tensor),
["original_image", "blended_heat_map"],
["all", "absolute_value"],
show_colorbar=True,
cmap=cc.cm.bgyw,
titles=["original_image", "heatmap"],
fig_size=(12, 12))
Große Datasets
Wenn Sie AutoML zum Training von großen Datasets verwenden, gibt es einige experimentelle Einstellungen, die nützlich sein können.
Wichtig
Diese Einstellungen sind derzeit in der öffentlichen Vorschau. Sie werden ohne Vereinbarung zum Servicelevel bereitgestellt. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar. Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
Training mit mehreren GPUs und mehreren Knoten
Standardmäßig wird jedes Modell auf einer einzelnen VM trainiert. Wenn das Training eines Modells zu viel Zeit in Anspruch nimmt, kann die Verwendung von VMs, die mehrere GPUs enthalten, helfen. Die Zeit für das Training eines Modells für große Datasets sollte in etwa linear mit der Anzahl der verwendeten GPUs abnehmen. (Beispielsweise sollte ein Modell auf einer VM mit zwei GPUs etwa doppelt so schnell trainiert werden wie auf einer VM mit einer GPU). Wenn die Zeit zum Trainieren eines Modells auf einer VM mit mehreren GPUs immer noch hoch ist, können Sie die Anzahl der VMs, die zum Trainieren der einzelnen Modelle verwendet werden, erhöhen. Ähnlich wie beim Training mit mehreren GPUs sollte auch die Zeit für das Training eines Modells für große Datasets in etwa linear mit der Anzahl der verwendeten VMs abnehmen. Wenn Sie ein Modell über mehrere VMs hinweg trainieren, sollten Sie eine Compute-SKU verwenden, die InfiniBand unterstützt, um optimale Ergebnisse zu erzielen. Sie können die Anzahl der für das Training eines einzelnen Modells verwendeten VMs konfigurieren, indem Sie die Eigenschaft node_count_per_trial des AutoML-Auftrags festlegen.
GILT FÜRAzure CLI ML-Erweiterung v2 (aktuell)
properties:
node_count_per_trial: "2"
Streamen von Bilddateien aus dem Speicher
Standardmäßig werden alle Bilddateien vor dem Modelltraining auf den Datenträger heruntergeladen. Wenn die Größe der Bilddateien größer als der verfügbare Speicherplatz ist, tritt beim Auftrag ein Fehler auf. Anstatt alle Bilder auf einen Datenträger herunterzuladen, können Sie festlegen, dass die Bilddateien aus dem Azure-Speicher gestreamt werden, wenn sie während des Trainings benötigt werden. Bilddateien werden direkt vom Azure-Speicher in den Systemspeicher übertragen, um Datenträger zu umgehen. Gleichzeitig werden so viele Dateien wie möglich aus dem Speicher auf dem Datenträger zwischengespeichert, um die Anzahl der Anforderungen an den Speicher zu minimieren.
Hinweis
Wenn das Streaming aktiviert ist, stellen Sie sicher, dass sich das Azure-Speicherkonto in derselben Region wie die Compute-Instanz befindet, um Kosten und Wartezeiten zu minimieren.
GILT FÜRAzure CLI ML-Erweiterung v2 (aktuell)
training_parameters:
advanced_settings: >
{"stream_image_files": true}
Beispielnotebooks
Überprüfen Sie detaillierte Codebeispiele und Anwendungsfälle im GitHub-Notebook-Repository für Beispiele zum automatisierten maschinellen Lernen. Überprüfen Sie die Ordner mit dem Präfix „automl-image-“ auf spezifische Beispiele für die Erstellung von Modellen für maschinelles Sehen.
Codebeispiele
Überprüfen Sie detaillierte Codebeispiele und Anwendungsfälle im GitHub-Repository „azureml-examples“ für Beispiele zum automatisierten maschinellen Lernen.