DevOps für eine Datenerfassungspipeline
In den meisten Szenarien ist eine Datenerfassungslösung eine Kombination aus Skripts, Dienstaufrufen und einer Pipeline, die alle Aktivitäten orchestriert. In diesem Artikel erfahren Sie, wie Sie DevOps-Methoden auf den Entwicklungslebenszyklus einer allgemeinen Datenerfassungspipeline anwenden können, die Daten für das Machine Learning-Modelltraining vorbereitet. Die Pipeline wird unter Verwendung der folgenden Azure-Dienste erstellt:
- Azure Data Factory: Liest die Rohdaten und orchestriert die Datenvorbereitung.
- Azure Databricks: Führt ein Python-Notebook aus, das die Daten transformiert.
- Azure Pipelines: Automatisiert einen kontinuierlichen Integrations- und Entwicklungsprozess.
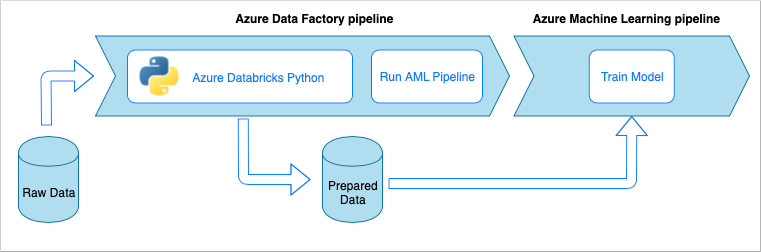
Pipelineworkflow für die Datenerfassung
Die Datenerfassungspipeline implementiert den folgenden Workflow:
- Rohdaten werden in eine ADF-Pipeline (Azure Data Factory) eingelesen.
- Die ADF-Pipeline sendet die Daten an einen Azure Databricks-Cluster, auf dem ein Python-Notebook ausgeführt wird, um die Daten zu transformieren.
- Die Daten werden in einem Blobcontainer gespeichert, wo sie von Azure Machine Learning zum Trainieren eines Modells verwendet werden können.
Continuous Integration und Continuous Delivery (CI/CD) – Übersicht
Wie bei vielen Softwarelösungen ist ein Team (z. B. Data Engineers) daran beteiligt. Die Mitglieder des Teams arbeiten zusammen und nutzen dieselben Azure-Ressourcen, z. B. Azure Data Factory, Azure Databricks und Azure Storage-Konten. Die Sammlung dieser Ressourcen ist eine Entwicklungsumgebung. Die Data Engineers tragen zur gleichen Quellcodebasis bei.
Ein Continuous Integration- und Continuous Delivery-System automatisiert den Prozess der Erstellung, Prüfung und Übermittlung (Bereitstellung) der Lösung. Der CI-Prozess (Continuous Integration) führt die folgenden Aufgaben durch:
- Stellt den Code zusammen
- Prüft den Code mit Codequalitätstests
- Führt Komponententests aus
- Erzeugt Artefakte wie getesteten Code und Azure Resource Manager-Vorlagen
Der Continuous Delivery-Prozess (CD) stellt die Artefakte in den Downstreamumgebungen bereit.
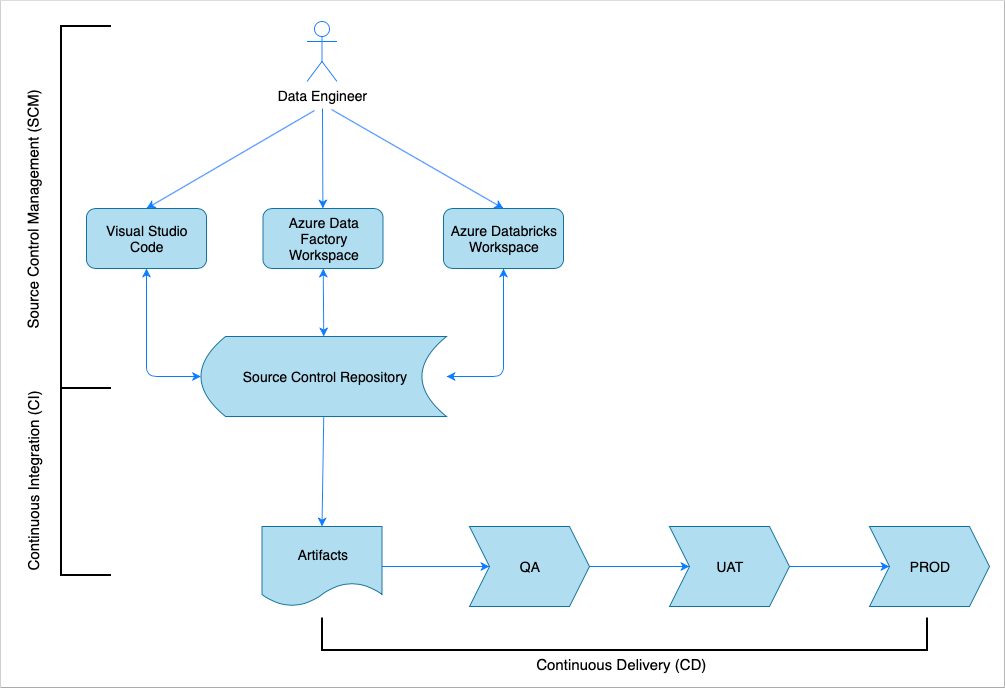
In diesem Artikel wird veranschaulicht, wie die CI- und CD-Prozesse mit Azure Pipelines automatisiert werden.
Quellcodeverwaltung
Die Quellcodeverwaltung ist erforderlich, um Änderungen nachzuverfolgen und die Zusammenarbeit zwischen den Teammitgliedern zu ermöglichen. Beispielsweise würde der Code in einem Azure DevOps-, GitHub- oder GitLab-Repository gespeichert werden. Der Workflow für die Zusammenarbeit basiert auf einem Branchenmodell.
Python-Notebookquellcode
Die Data Engineers arbeiten mit dem Python-Notebookquellcode entweder lokal in einer IDE (z. B. Visual Studio Code) oder direkt im Databricks-Arbeitsbereich. Sobald die Codeänderungen abgeschlossen sind, werden sie nach einer Branchingrichtlinie im Repository zusammengeführt.
Tipp
Sie sollten den Code in .py-Dateien anstatt im Jupyter-Notebookformat .ipynb speichern. Dadurch wird die Lesbarkeit des Codes verbessert, und es werden automatische Codequalitätsprüfungen im CI-Prozess ermöglicht.
Azure Data Factory-Quellcode
Der Quellcode von Azure Data Factory-Pipelines ist eine Sammlung von JSON-Dateien, die von einem Azure Data Factory-Arbeitsbereich generiert werden. Normalerweise arbeiten die Data Engineers mit einem visuellen Designer im Azure Data Factory-Arbeitsbereich anstatt direkt mit den Quellcodedateien.
Informationen zum Konfigurieren des Arbeitsbereichs für die Verwendung eines Quellcodeverwaltungs-Repositorys finden Sie unter Erstellen mit der Azure Repos Git-Integration.
Continuous Integration (CI)
Das ultimative Ziel des Continuous Integration-Prozesses besteht darin, die gemeinsame Teamarbeit aus dem Quellcode zu erfassen und diese für die Bereitstellung in den Downstreamumgebungen vorzubereiten. Wie bei der Quellcodeverwaltung unterscheidet sich dieser Prozess für die Python-Notebooks und Azure Data Factory-Pipelines.
Python-Notebook-CI
Der CI-Prozess für die Python-Notebooks ruft den Code aus dem Kollaborationsbranch ab (z. B. master oder develop) und führt die folgenden Aktivitäten aus:
- Codelinting
- Komponententests
- Speichern des Codes als Artefakt
Der folgende Codeausschnitt veranschaulicht die Implementierung dieser Schritte in einer Azure DevOps-yaml-Pipeline:
steps:
- script: |
flake8 --output-file=$(Build.BinariesDirectory)/lint-testresults.xml --format junit-xml
workingDirectory: '$(Build.SourcesDirectory)'
displayName: 'Run flake8 (code style analysis)'
- script: |
python -m pytest --junitxml=$(Build.BinariesDirectory)/unit-testresults.xml $(Build.SourcesDirectory)
displayName: 'Run unit tests'
- task: PublishTestResults@2
condition: succeededOrFailed()
inputs:
testResultsFiles: '$(Build.BinariesDirectory)/*-testresults.xml'
testRunTitle: 'Linting & Unit tests'
failTaskOnFailedTests: true
displayName: 'Publish linting and unit test results'
- publish: $(Build.SourcesDirectory)
artifact: di-notebooks
Die Pipeline verwendet flake8, um das Python-Codelinting auszuführen. Sie führt die im Quellcode definierten Komponententests aus und veröffentlicht die Linting- und Testergebnisse, sodass sie auf dem Ausführungsbildschirm von Azure Pipelines verfügbar sind.
Wenn die Linting- und Komponententests erfolgreich ausgeführt werden, kopiert die Pipeline den Quellcode in das Artefaktrepository, damit er von den nachfolgenden Bereitstellungsschritten verwendet werden kann.
Azure Data Factory-CI
Der CI-Prozess für eine Azure Data Factory-Pipeline ist ein Engpass für eine Datenerfassungspipeline. Es gibt keine Continuous Integration. Ein bereitstellbares Artefakt für Azure Data Factory ist eine Sammlung von Azure Resource Manager-Vorlagen. Diese Vorlagen können Sie nur erstellen, indem Sie im Azure Data Factory-Arbeitsbereich auf die Schaltfläche Veröffentlichen klicken.
- Die Datentechniker führen den Quellcode aus ihren Featurebranches im Kollaborationsbranch zusammen, z. B. in master oder develop.
- Benutzer mit den gewährten Berechtigungen können auf die Schaltfläche Veröffentlichen klicken, um Azure Resource Manager-Vorlagen aus dem Quellcode im Kollaborationsbranch zu generieren.
- Der Arbeitsbereich überprüft die Pipelines (etwa Linting und Komponententests), generiert Azure Resource Manager-Vorlagen (ähnlich einem Buildvorgang) und speichert die generierten Vorlagen im technischen Branch adf_publish im gleichen Coderepository (ähnlich der Veröffentlichung von Artefakten). Dieser Branch wird automatisch vom Azure Data Factory-Arbeitsbereich erstellt.
Weitere Informationen zu diesem Prozess finden Sie unter Continuous Integration und Continuous Delivery in Azure Data Factory.
Es ist wichtig sicherzustellen, dass die generierten Azure Resource Manager-Vorlagen umgebungsagnostisch sind. Dies bedeutet, dass alle Werte, die sich zwischen Umgebungen unterscheiden können, parametrisiert werden. Azure Data Factory ist intelligent genug, um die Mehrzahl dieser Werte als Parameter bereitzustellen. In der folgenden Vorlage werden z. B. die Verbindungseigenschaften für einen Azure Machine Learning-Arbeitsbereich als Parameter zur Verfügung gestellt:
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"factoryName": {
"value": "devops-ds-adf"
},
"AzureMLService_servicePrincipalKey": {
"value": ""
},
"AzureMLService_properties_typeProperties_subscriptionId": {
"value": "0fe1c235-5cfa-4152-17d7-5dff45a8d4ba"
},
"AzureMLService_properties_typeProperties_resourceGroupName": {
"value": "devops-ds-rg"
},
"AzureMLService_properties_typeProperties_servicePrincipalId": {
"value": "6e35e589-3b22-4edb-89d0-2ab7fc08d488"
},
"AzureMLService_properties_typeProperties_tenant": {
"value": "72f988bf-86f1-41af-912b-2d7cd611db47"
}
}
}
Möglicherweise möchten Sie jedoch Ihre benutzerdefinierten Eigenschaften verfügbar machen, die nicht standardmäßig vom Azure Data Factory-Arbeitsbereich verarbeitet werden. Im Szenario dieses Artikels ruft eine Azure Data Factory-Pipeline ein Python-Notebook auf, das die Daten verarbeitet. Das Notebook akzeptiert einen Parameter mit dem Namen einer Eingabedatendatei.
import pandas as pd
import numpy as np
data_file_name = getArgument("data_file_name")
data = pd.read_csv(data_file_name)
labels = np.array(data['target'])
...
Dieser Name unterscheidet sich für Dev- (Entwicklung), QA- (Qualitätssicherung), UAT- (Akzeptanztests) und PROD-Umgebungen (Produktion). In einer komplexen Pipeline mit mehreren Aktivitäten können mehrere benutzerdefinierte Eigenschaften vorhanden sein. Es empfiehlt sich, alle diese Werte an einem Ort zu sammeln und als Variablen der Pipeline zu definieren:
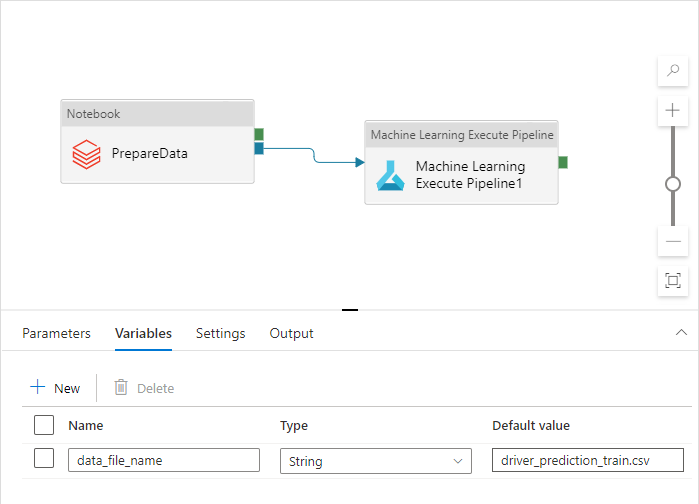
Die Pipelineaktivitäten können auf die Pipelinevariablen verweisen, während sie tatsächlich verwendet werden:
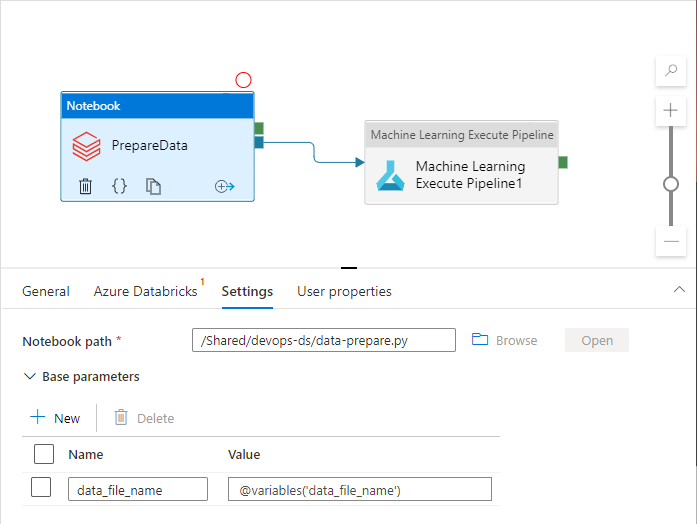
Der Azure Data Factory-Arbeitsbereich stellt Pipelinevariablen standardmäßig nicht als Azure Resource Manager-Vorlagenparameter bereit. Der Arbeitsbereich verwendet die Standardparameterisierungsvorlage, die vorgibt, welche Pipelineeigenschaften als Azure Resource Manager-Vorlagenparameter verfügbar gemacht werden sollen. Um der Liste Pipelinevariablen hinzuzufügen, aktualisieren Sie den Abschnitt "Microsoft.DataFactory/factories/pipelines" der Standardparameterisierungsvorlage mit dem folgenden Codeausschnitt, und platzieren Sie die JSON-Ergebnisdatei im Stammverzeichnis des Quellordners:
"Microsoft.DataFactory/factories/pipelines": {
"properties": {
"variables": {
"*": {
"defaultValue": "="
}
}
}
}
Dadurch wird der Azure Data Factory-Arbeitsbereich gezwungen, die Variablen der Parameterliste hinzuzufügen, wenn auf die Schaltfläche Veröffentlichen geklickt wird:
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"factoryName": {
"value": "devops-ds-adf"
},
...
"data-ingestion-pipeline_properties_variables_data_file_name_defaultValue": {
"value": "driver_prediction_train.csv"
}
}
}
Bei den Werten in der JSON-Datei handelt es sich um in der Pipelinedefinition konfigurierte Standardwerte. Beim Bereitstellen der Azure Resource Manager-Vorlage wird erwartet, dass sie mit den Werten der Zielumgebung überschrieben werden.
Continuous Delivery (CD)
Der Continuous Delivery-Prozess verwendet die Artefakte und stellt sie in der ersten Zielumgebung bereit. Er stellt sicher, dass die Lösung funktioniert, indem Tests ausgeführt werden. Bei Erfolg wird der Vorgang in der nächsten Umgebung fortgesetzt.
Die CD-Instanz von Azure Pipelines besteht aus mehreren Stufen, die die Umgebungen darstellen. Jede Stufe enthält Bereitstellungen und Aufträge, mit denen die folgenden Schritte ausgeführt werden:
- Bereitstellen eines Python-Notebooks im Azure Databricks-Arbeitsbereich
- Bereitstellen einer Azure Data Factory-Pipeline
- Führen Sie die Pipeline aus.
- Überprüfen des Ergebnisses der Datenerfassung
Die Pipelinestufen können mit Genehmigungen und Gates konfiguriert werden, die zusätzliche Kontrolle über die Weiterentwicklung des Bereitstellungsprozesses in der Kette der Umgebungen bieten.
Bereitstellen eines Python-Notebooks
Mit dem folgenden Codeausschnitt wird die Bereitstellungs einer Azure-Pipeline definiert, die ein Python-Notebook in einen Databricks-Cluster kopiert:
- stage: 'Deploy_to_QA'
displayName: 'Deploy to QA'
variables:
- group: devops-ds-qa-vg
jobs:
- deployment: "Deploy_to_Databricks"
displayName: 'Deploy to Databricks'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: deploynotebooks@0
inputs:
notebooksFolderPath: '$(Pipeline.Workspace)/di-notebooks'
workspaceFolder: '/Shared/devops-ds'
displayName: 'Deploy (copy) data processing notebook to the Databricks cluster'
Die von CI erstellten Artefakte werden automatisch in den Bereitstellungs-Agent kopiert und sind im Ordner $(Pipeline.Workspace) verfügbar. In diesem Fall verweist die Bereitstellungsaufgabe auf das di-notebooks-Artefakt, das das Python-Notebook enthält. Diese Bereitstellungs verwendet die Databricks Azure DevOps-Erweiterung, um die Notebookdateien in den Databricks-Arbeitsbereich zu kopieren.
Die Stufe Deploy_to_QA enthält einen Verweis auf die im Azure DevOps-Projekt definierte Variablengruppe devops-ds-qa-vg. Die Schritte in dieser Stufe verweisen auf die Variablen aus dieser Variablengruppe (z. B. $(DATABRICKS_URL) und $(DATABRICKS_TOKEN)). Der Gedanke dabei ist, dass die nächste Stufe (z. B. Deploy_to_UAT) mit denselben Variablennamen ausgeführt wird, die in der eigenen Variablengruppe mit dem Bereich „UAT“ definiert sind.
Bereitstellen einer Azure Data Factory-Pipeline
Ein bereitstellbares Artefakt für Azure Data Factory ist eine Azure Resource Manager-Vorlage. Sie wird mit der Aufgabe Azure-Ressourcengruppenbereitstellung bereitgestellt, wie im folgenden Codeausschnitt veranschaulicht:
- deployment: "Deploy_to_ADF"
displayName: 'Deploy to ADF'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: AzureResourceGroupDeployment@2
displayName: 'Deploy ADF resources'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
resourceGroupName: $(RESOURCE_GROUP)
location: $(LOCATION)
csmFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateForFactory.json'
csmParametersFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateParametersForFactory.json'
overrideParameters: -data-ingestion-pipeline_properties_variables_data_file_name_defaultValue "$(DATA_FILE_NAME)"
Der Wert des Parameters „data filename“ stammt von der Variablen $(DATA_FILE_NAME), die in einer Variablengruppe der QA-Stufe definiert ist. Auf ähnliche Weise können alle Parameter, die in ARMTemplateForFactory.json definiert sind, überschrieben werden. Wenn dies nicht der Fall ist, werden die Standardwerte verwendet.
Ausführen der Pipeline und Überprüfen des Ergebnisses der Datenerfassung
Im nächsten Schritt müssen Sie sicherstellen, dass die bereitgestellte Lösung funktioniert. Die folgende Auftragsdefinition führt eine Azure Data Factory-Pipeline mit einem PowerShell-Skript aus und führt ein Python-Notebook in einem Azure Databricks-Cluster aus. Das Notebook überprüft, ob die Daten ordnungsgemäß erfasst wurden, und validiert die Ergebnisdatendatei mit dem Namen $(bin_FILE_NAME).
- job: "Integration_test_job"
displayName: "Integration test job"
dependsOn: [Deploy_to_Databricks, Deploy_to_ADF]
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: AzurePowerShell@4
displayName: 'Execute ADF Pipeline'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
ScriptPath: '$(Build.SourcesDirectory)/adf/utils/Invoke-ADFPipeline.ps1'
ScriptArguments: '-ResourceGroupName $(RESOURCE_GROUP) -DataFactoryName $(DATA_FACTORY_NAME) -PipelineName $(PIPELINE_NAME)'
azurePowerShellVersion: LatestVersion
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: executenotebook@0
inputs:
notebookPath: '/Shared/devops-ds/test-data-ingestion'
existingClusterId: '$(DATABRICKS_CLUSTER_ID)'
executionParams: '{"bin_file_name":"$(bin_FILE_NAME)"}'
displayName: 'Test data ingestion'
- task: waitexecution@0
displayName: 'Wait until the testing is done'
Die letzte Aufgabe im Auftrag überprüft das Ergebnis der Notebookausführung. Wenn ein Fehler zurückgegeben wird, wird der Status der Pipelineausführung auf „fehlerhaft“ festgelegt.
Zusammenführen der einzelnen Elemente
Die vollständige CI/CD-Azure-Pipeline besteht aus den folgenden Stufen:
- CI
- Bereitstellung für QA
- Bereitstellung für Databricks und Bereitstellung in ADF
- Integrationstest
Sie enthält eine Reihe von Bereitstellungsstufen, die der Anzahl der Zielumgebungen entsprechen. Jede Bereitstellungsstufe enthält zwei Bereitstellungen, die parallel ausgeführt werden, sowie einen Auftrag, der nach den Bereitstellungen ausgeführt wird, um die Lösung in der Umgebung zu testen.
Eine Beispielimplementierung der Pipeline wird im folgenden yaml-Codeausschnitt zusammengestellt:
variables:
- group: devops-ds-vg
stages:
- stage: 'CI'
displayName: 'CI'
jobs:
- job: "CI_Job"
displayName: "CI Job"
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- script: pip install --upgrade flake8 flake8_formatter_junit_xml
displayName: 'Install flake8'
- checkout: self
- script: |
flake8 --output-file=$(Build.BinariesDirectory)/lint-testresults.xml --format junit-xml
workingDirectory: '$(Build.SourcesDirectory)'
displayName: 'Run flake8 (code style analysis)'
- script: |
python -m pytest --junitxml=$(Build.BinariesDirectory)/unit-testresults.xml $(Build.SourcesDirectory)
displayName: 'Run unit tests'
- task: PublishTestResults@2
condition: succeededOrFailed()
inputs:
testResultsFiles: '$(Build.BinariesDirectory)/*-testresults.xml'
testRunTitle: 'Linting & Unit tests'
failTaskOnFailedTests: true
displayName: 'Publish linting and unit test results'
# The CI stage produces two artifacts (notebooks and ADF pipelines).
# The pipelines Azure Resource Manager templates are stored in a technical branch "adf_publish"
- publish: $(Build.SourcesDirectory)/$(Build.Repository.Name)/code/dataingestion
artifact: di-notebooks
- checkout: git://${{variables['System.TeamProject']}}@adf_publish
- publish: $(Build.SourcesDirectory)/$(Build.Repository.Name)/devops-ds-adf
artifact: adf-pipelines
- stage: 'Deploy_to_QA'
displayName: 'Deploy to QA'
variables:
- group: devops-ds-qa-vg
jobs:
- deployment: "Deploy_to_Databricks"
displayName: 'Deploy to Databricks'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: deploynotebooks@0
inputs:
notebooksFolderPath: '$(Pipeline.Workspace)/di-notebooks'
workspaceFolder: '/Shared/devops-ds'
displayName: 'Deploy (copy) data processing notebook to the Databricks cluster'
- deployment: "Deploy_to_ADF"
displayName: 'Deploy to ADF'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: AzureResourceGroupDeployment@2
displayName: 'Deploy ADF resources'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
resourceGroupName: $(RESOURCE_GROUP)
location: $(LOCATION)
csmFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateForFactory.json'
csmParametersFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateParametersForFactory.json'
overrideParameters: -data-ingestion-pipeline_properties_variables_data_file_name_defaultValue "$(DATA_FILE_NAME)"
- job: "Integration_test_job"
displayName: "Integration test job"
dependsOn: [Deploy_to_Databricks, Deploy_to_ADF]
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: AzurePowerShell@4
displayName: 'Execute ADF Pipeline'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
ScriptPath: '$(Build.SourcesDirectory)/adf/utils/Invoke-ADFPipeline.ps1'
ScriptArguments: '-ResourceGroupName $(RESOURCE_GROUP) -DataFactoryName $(DATA_FACTORY_NAME) -PipelineName $(PIPELINE_NAME)'
azurePowerShellVersion: LatestVersion
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: executenotebook@0
inputs:
notebookPath: '/Shared/devops-ds/test-data-ingestion'
existingClusterId: '$(DATABRICKS_CLUSTER_ID)'
executionParams: '{"bin_file_name":"$(bin_FILE_NAME)"}'
displayName: 'Test data ingestion'
- task: waitexecution@0
displayName: 'Wait until the testing is done'