Verwenden von Azure Machine Learning Studio in einem virtuellen Netzwerk
Tipp
Microsoft empfiehlt die Verwendung von verwalteten virtuellen Netzwerken für Azure Machine Learning anstelle der Schritte in diesem Artikel. Mit einem verwalteten virtuellen Netzwerk übernimmt Azure Machine Learning die Aufgabe der Netzwerkisolation für Ihren Arbeitsbereich und Ihre verwalteten Computeressourcen. Sie können auch private Endpunkte für Ressourcen hinzufügen, die vom Arbeitsbereich benötigt werden, z. B. Azure Storage-Konto. Weitere Informationen finden Sie unter Verwaltete Netzwerkisolation auf Arbeitsbereichsebene (Vorschau).
In diesem Artikel erfahren Sie, wie Sie Azure Machine Learning Studio in einem virtuellen Netzwerk verwenden. Studio enthält Features wie automatisiertes maschinelles Lernen, den Designer und Datenbeschriftung.
Einige der Funktionen von Studio sind in virtuellen Netzwerken standardmäßig deaktiviert. Wenn Sie diese Features aktivieren möchten, müssen Sie für Speicherkonten, die Sie in Studio verwenden möchten, die verwaltete Identität aktivieren.
Die folgenden Vorgänge sind in einem virtuellen Netzwerk standardmäßig deaktiviert:
- Vorschau der Daten im Studio.
- Visualisieren von Daten im Designer.
- Bereitstellen eines Modells im Designer.
- Senden eines AutoML-Experiments.
- Starten eines Beschriftungsprojekts.
Das Studio unterstützt das Lesen von Daten aus den folgenden Datenspeichertypen in einem virtuellen Netzwerk:
- Azure Storage-Konto (Blob und Datei)
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- Azure SQL-Datenbank
In diesem Artikel werden folgende Vorgehensweisen behandelt:
- Erteilen der Studio-Berechtigung, auf Daten zuzugreifen, die in einem virtuellen Netzwerk gespeichert sind
- Zugreifen auf Studio von einer Ressource innerhalb eines virtuellen Netzwerks aus
- Erfahren Sie, wie sich das Studio auf die Speichersicherheit auswirkt.
Voraussetzungen
In der Übersicht über die Netzwerksicherheit finden Sie Informationen zu gängigen Szenarien im Zusammenhang mit virtuellen Netzwerken sowie zur Architektur.
Ein bereits vorhandenes virtuelles Netzwerk und Subnetz, das verwendet werden kann
Ein vorhandener Azure Machine Learning-Arbeitsbereich mit einem privaten Endpunkt.
Ein vorhandenes Azure Storage-Konto, das Ihrem virtuellen Netzwerk hinzugefügt wurde.
Ein vorhandener Azure Machine Learning-Arbeitsbereich mit einem privaten Endpunkt.
Ein vorhandenes Azure Storage-Konto, das Ihrem virtuellen Netzwerk hinzugefügt wurde.
- Informationen zum Erstellen eines sicheren Arbeitsbereichs finden Sie unter Tutorial: Erstellen eines sicheren Arbeitsbereichs und Tutorial: Erstellen eines sicheren Arbeitsbereichs mithilfe einer Vorlage.
Begrenzungen
Azure Storage-Konto
Wenn sich das Speicherkonto im virtuellen Netzwerk befindet, gibt es zusätzliche Validierungsanforderungen für die Verwendung von Studio:
- Wenn das Speicherkonto einen Dienstendpunkt verwendet, müssen sich der private Endpunkt des Arbeitsbereichs und der Speicherdienstendpunkt im gleichen Subnetz des virtuellen Netzwerks befinden.
- Wenn das Speicherkonto einen privaten Endpunkt verwendet, müssen sich der private Endpunkt des Arbeitsbereichs und der des Speichers im gleichen virtuellen Netzwerk befinden. In diesem Fall können sie sich in unterschiedlichen Subnetzen befinden.
Beispielpipeline für den Designer
Es gibt ein bekanntes Problem, bei dem Benutzer*innen keine Stichprobenpipeline auf der Designer-Homepage ausführen können. Dieses Problem tritt auf, weil das in der Beispielpipeline verwendete Beispieldataset ein globales Azure-Dataset ist. Aus einer virtuellen Netzwerkumgebung kann nicht darauf zugegriffen werden.
Um dieses Problem zu beheben, verwenden Sie einen öffentlichen Arbeitsbereich, um die Beispielpipeline auszuführen. Alternativ können Sie das Beispieldataset durch Ihr eigenes Dataset im Arbeitsbereich in einem virtuellen Netzwerk ersetzen.
Datenspeicher: Azure Storage-Konto
Führen Sie die folgenden Schritte aus, um den Zugriff auf die gespeicherten Daten in Azure-Blob- und -Dateispeicher zu ermöglichen:
Tipp
Der erste Schritt ist für das Standardspeicherkonto des Arbeitsbereichs nicht erforderlich. Alle anderen Schritte sind für alle Speicherkonten erforderlich, die sich hinter dem VNET befinden und vom Arbeitsbereich verwendet werden, einschließlich des Standardspeicherkontos.
Überspringen Sie diesen Schritt, wenn das Speicherkonto der Standardspeicher für Ihren Arbeitsbereich ist. Wenn dies nicht der Standardspeicher ist, müssen Sie der verwalteten Identität des Arbeitsbereichs die Rolle „Storage-Blobdatenleser“ für das Azure Storage-Konto gewähren, damit die Daten aus dem Blobspeicher gelesen werden können.
Weitere Informationen finden Sie unter der integrierten Rolle Storage-Blobdatenleser.
Weisen Sie Ihrer Azure-Benutzeridentität die Rolle Storage-Blobdatenleser für das Azure-Speicherkonto zu. Studio nutzt Ihre Identität, um auf Daten im Blobspeicher zuzugreifen, auch wenn die verwaltete Identität des Arbeitsbereichs über die Rolle „Leser“ verfügt.
Weitere Informationen finden Sie unter der integrierten Rolle Storage-Blobdatenleser.
Gewähren Sie der verwalteten Identität des Arbeitsbereichs die Rolle „Leser“ für private Speicherendpunkte. Wenn für Ihren Speicherdienst ein privater Endpunkt verwendet wird, müssen Sie der vom Arbeitsbereich verwalteten Identität Lesezugriff auf den privaten Endpunkt gewähren. Die vom Arbeitsbereich verwaltete Identität in Microsoft Entra ID hat den gleichen Namen wie Ihr Azure Machine Learning-Arbeitsbereich. Ein privater Endpunkt ist für die Speichertypen Blob- und Datei erforderlich.
Tipp
Ihr Speicherkonto kann über mehrere private Endpunkte verfügen. Beispielsweise kann ein Speicherkonto über einen separaten privaten Endpunkt für Blob, Datei und DFS verfügen (Azure Data Lake Storage Gen2). Fügen Sie allen diesen Endpunkten die verwaltete Identität hinzu.
Weitere Informationen finden Sie unter der integrierten Rolle Leser.
Aktivieren Sie die Authentifizierung mit verwalteten Identitäten für Standardspeicherkonten. Jeder Azure Machine Learning-Arbeitsbereich verfügt über zwei Standardspeicherkonten: ein Blob Storage-Standardkonto und ein Standardkonto für den Dateispeicher. Beide werden definiert, wenn Sie Ihren Arbeitsbereich erstellen. Sie können auch auf der Verwaltungsseite neue Standardeinstellungen für den Datenspeicher festlegen.
In der folgenden Tabelle ist beschrieben, warum die Authentifizierung mit verwalteten Identitäten für die Standardspeicherkonten Ihres Arbeitsbereichs genutzt wird.
Speicherkonto Notizen Standardblobspeicher für den Arbeitsbereich Speichert Modellressourcen vom Designer. Aktivieren Sie die Authentifizierung mit verwalteten Identitäten für dieses Speicherkonto, um Modelle im Designer bereitzustellen. Wenn die Authentifizierung der verwalteten Identität deaktiviert ist, wird die Identität des Benutzers verwendet, um auf die im Blob gespeicherten Daten zuzugreifen.
Sie können eine Designer-Pipeline visualisieren und ausführen, wenn sie nicht den Standarddatenspeicher verwendet, sondern einen, der für die Verwendung der verwalteten Identität konfiguriert wurde. Wenn Sie jedoch versuchen, ein trainiertes Modell ohne aktivierte verwaltete Identität im Standarddatenspeicher bereitzustellen, tritt dabei ein Fehler auf, unabhängig davon, welche anderen Datenspeicher verwendet werden.Standarddateispeicher für den Arbeitsbereich Speichert Experimentressourcen für automatisiertes maschinelles Lernen. Aktivieren Sie die Authentifizierung mit verwalteten Identitäten für dieses Speicherkonto, um Experimente für automatisiertes maschinelles Lernen zu übermitteln. Konfigurieren Sie Datenspeicher für die Verwendung der Authentifizierung mit verwalteten Identitäten. Nachdem Sie Ihrem virtuellen Netzwerk mit einem Dienstendpunkt oder privaten Endpunkt ein Azure Storage-Konto hinzugefügt haben, müssen Sie Ihren Datenspeicher für die Verwendung der Authentifizierung anhand der verwalteten Identität konfigurieren. Auf diese Weise kann Studio auf Daten in Ihrem Speicherkonto zugreifen.
Azure Machine Learning verwendet Datenspeicher, um eine Verbindung mit Speicherkonten herzustellen. Verwenden Sie beim Erstellen eines neuen Datenspeichers die folgenden Schritte, um einen Datenspeicher für die Verwendung der Authentifizierung mit verwalteten Identitäten zu konfigurieren:
Wählen Sie Datastores (Datenspeicher) im Studio aus.
Wählen Sie + Erstellen aus, um einen neuen Datenspeicher zu erstellen.
Aktivieren Sie in den Datenspeichereinstellungen die Option Für Datenvorschau und Profilerstellung in Azure Machine Learning Studio eine im Arbeitsbereich verwaltete Identität verwenden.
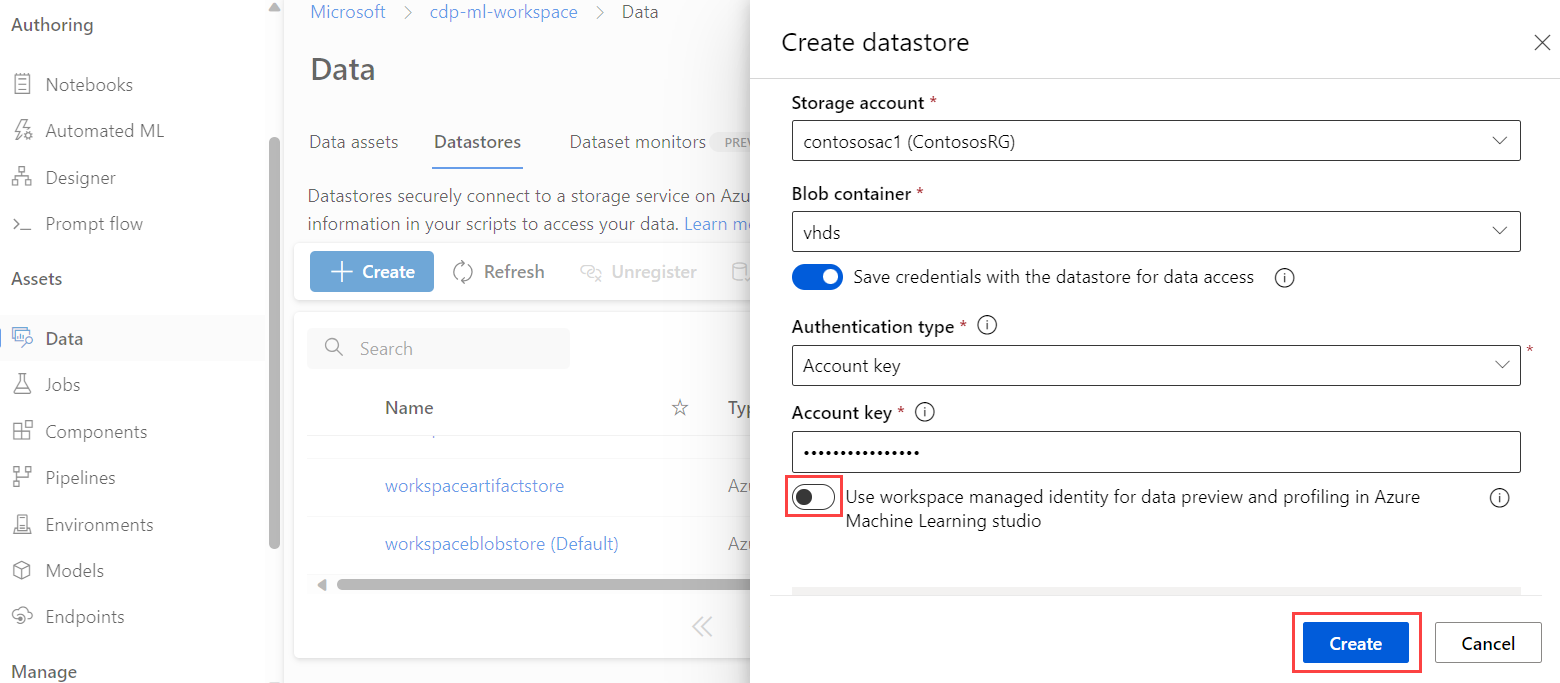
Fügen Sie in den Netzwerkeinstellungen für das Azure Storage-Konto den
Microsoft.MachineLearningService/workspacesRessourcentyp hinzu, und legen Sie den Instanznamen auf den Arbeitsbereich fest.
Mit diesen Schritten wird die verwaltete Identität des Arbeitsbereichs mithilfe der rollenbasierten Zugriffssteuerung (Role-Based Access Control, RBAC) von Azure dem neuen Speicherdienst als Leser hinzugefügt. Lesezugriff erlaubt dem Arbeitsbereich das Anzeigen der Ressource, aber keine Änderungen.


Datenspeicher: Azure Data Lake Storage Gen1
Wenn Sie Azure Data Lake Storage Gen1 als Datenspeicher verwenden, können Sie nur Zugriffssteuerungslisten im POSIX-Stil nutzen. Sie können der vom Arbeitsbereich verwalteten Identität wie jedem anderen Sicherheitsprinzipal Zugriff auf Ressourcen zuweisen. Weitere Informationen finden Sie unter Zugriffssteuerung in Azure Data Lake Storage Gen1.
Datenspeicher: Azure Data Lake Storage Gen2
Beim Verwenden von Azure Data Lake Storage Gen2 als Datenspeicher können Sie den Datenzugriff in einem virtuellen Netzwerk sowohl per Azure RBAC als auch mit POSIX-Zugriffssteuerungslisten (Access Control Lists, ACLs) steuern.
Um Azure RBAC zu verwenden, führen Sie die Schritte im Abschnitt Datenspeicher: Azure Storage-Konto dieses Artikels aus. Data Lake Storage Gen2 basiert auf Azure Storage, sodass die gleichen Schritte gelten, wenn Sie Azure RBAC verwenden.
Für die Verwendung von ACLs kann der verwalteten Identität des Arbeitsbereichs wie jedem anderen Sicherheitsprinzipal Zugriff gewährt werden. Weitere Informationen finden Sie unter Zugriffssteuerungslisten für Dateien und Verzeichnisse.
Datenspeicher: Azure SQL-Datenbank
Wenn Sie mit einer verwalteten Identität auf Daten zugreifen möchten, die in einer Azure SQL-Datenbank-Instanz gespeichert sind, müssen Sie einen eigenständigen SQL-Benutzer erstellen, der der verwalteten Identität zugeordnet ist. Weitere Informationen zum Erstellen von Benutzern von einem externen Anbieter finden Sie unter Erstellen eigenständiger Benutzer mit Zuordnung zu Microsoft Entra-Identitäten.
Nachdem Sie einen eigenständigen SQL-Benutzer erstellt haben, erteilen Sie mithilfe des GRANT T-SQL-Befehls Berechtigungen.
Ausgabe der Zwischenkomponente
Wenn Sie die Ausgabe der Zwischenkomponente des Azure Machine Learning-Designers nutzen, können Sie den Ausgabespeicherort für jede Komponente im Designer angeben. Mit dieser Ausgabe können Sie zwischengeschaltete Datasets zu Sicherheits-, Protokollierungs- oder Überwachungszwecken an einem separaten Ort speichern. Führen Sie die folgenden Schritte aus, um die Ausgabe anzugeben:
- Wählen Sie die Komponente aus, für die Sie die Ausgabe angeben möchten.
- Wählen Sie im Bereich mit den Komponenteneinstellungen die Option Ausgabeeinstellungen aus.
- Geben Sie den Datenspeicher an, den Sie für die einzelnen Komponentenausgaben verwenden möchten.
Stellen Sie sicher, dass Sie auf die zwischengeschalteten Speicherkonten in Ihrem virtuellen Netzwerk Zugriff haben. Andernfalls tritt bei der Pipeline ein Fehler auf.
Aktivieren Sie die Authentifizierung mit verwalteten Identitäten für die zwischengeschalteten Speicherkonten, damit Ausgabedaten visualisiert werden können.
Zugriff auf Studio von einer Ressource innerhalb des virtuellen Netzwerks aus
Wenn Sie über eine Ressource innerhalb eines virtuellen Netzwerks (z. B. eine Compute-Instanz oder eine VM) auf Studio zugreifen, müssen Sie den Datenverkehr zulassen, der aus dem virtuellen Netzwerk an Studio gesendet wird.
Wenn Sie beispielsweise ausgehenden Datenverkehr mit Netzwerksicherheitsgruppen (NSG) einschränken, fügen Sie dem DiensttagzielAzureFrontDoor.Frontend eine Regel hinzu.
Firewalleinstellungen
Einige Speicherdienste, z. B. ein Azure Storage-Konto, verfügen über Firewalleinstellungen, die für den öffentlichen Endpunkt dieser speziellen Dienstinstanz gelten. In der Regel können Sie mit dieser Einstellung den Zugriff von bestimmten IP-Adressen aus dem öffentlichen Internet zulassen bzw. blockieren. Dies wird bei Verwendung von Azure Machine Learning Studio nicht unterstützt. Sie wird bei Verwendung des Azure Machine Learning-SDK oder der Befehlszeilenschnittstelle unterstützt.
Tipp
Azure Machine Learning Studio wird bei Verwendung des Azure Firewall-Diensts unterstützt. Weitere Informationen finden Sie unter Konfiguration des ein- und ausgehenden Netzwerkdatenverkehrs.
Zugehöriger Inhalt
Dieser Artikel ist Teil einer Reihe zum Schützen eines Azure Machine Learning-Workflows. Sehen Sie sich auch die anderen Artikel in dieser Reihe an: