Azure Machine Learning – Rückschlussrouter und Konnektivitätsanforderungen
Der Azure Machine Learning-Rückschlussrouter ist eine wichtige Komponente für Echtzeitrückschlüsse mit einem Kubernetes-Cluster. In diesem Artikel erfahren Sie Folgendes:
- Was ist der Azure Machine Learning-Rückschlussrouter?
- Funktionsweise der automatischen Skalierung
- Konfigurieren und Erfüllen der Rückschlussanforderungsleistung (Anzahl der Anforderungen pro Sekunde und Wartezeit)
- Konnektivitätsanforderungen für AKS-Rückschlusscluster
Was ist der Azure Machine Learning-Rückschlussrouter?
Der Azure Machine Learning-Rückschlussrouter ist die Front-End-Komponente (azureml-fe), die in einem AKS- oder Arc Kubernetes-Cluster zum Zeitpunkt der Bereitstellung der Azure Machine Learning-Erweiterung bereitgestellt wird. Er verfügt über folgende Funktionen:
- Leitet eingehende Rückschlussanforderungen vom Lastenausgleich des Clusters oder vom Eingangsdatencontroller an die entsprechenden Modellpods weiter.
- Sorgt für einen Lastausgleich aller eingehenden Rückschlussanforderungen mit intelligentem koordiniertem Routing.
- Verwaltet die automatische Skalierung von Modellpods.
- Fehlertoleranz und Failoverfunktion, um sicherzustellen, dass Rückschlussanforderungen für unternehmenskritische Anwendungen immer bedient werden.
Die folgenden Schritte zeigen, wie Anforderungen vom Front-End verarbeitet werden:
- Der Client sendet eine Anforderung an den Lastenausgleich.
- Der Lastenausgleich sendet an eine der Front-End-Instanzen.
- Das Front-End findet den Dienstrouter (die Front-End-Instanz, die als Koordinator fungiert) für den Dienst.
- Der Dienstrouter wählt ein Back-End aus und gibt es an das Front-End zurück.
- Das Front-End leitet die Anforderung an das Back-End weiter.
- Nachdem die Anforderung verarbeitet wurde, sendet das Back-End eine Antwort an die Front-End-Komponente.
- Das Front-End sendet die Antwort an den Client zurück.
- Das Front-End teilt dem Dienstrouter mit, dass das Back-End die Verarbeitung abgeschlossen hat und für weitere Anforderungen zur Verfügung steht.
Dieser Flow wird im folgenden Diagramm veranschaulicht:
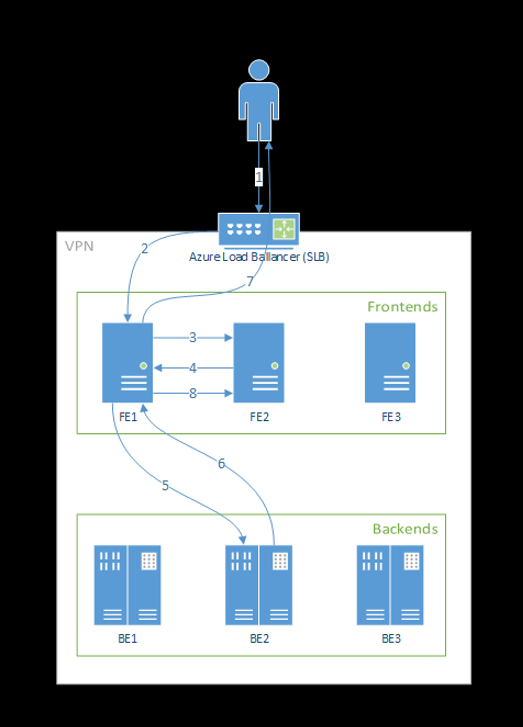
Wie Sie dem Diagramm oben entnehmen können, werden bei der Bereitstellung der Azure Machine Learning-Erweiterung standardmäßig drei azureml-fe-Instanzen erstellt: Eine dieser Instanzen fungiert als koordinierende Rolle, die anderen beiden verarbeiten eingehende Rückschlussanforderungen. Die koordinierende Instanz verfügt über alle Informationen zu den Modellpods und entscheidet, welcher Modellpod die eingehende Anforderung bedienen soll, während die bedienenden azureml-fe-Instanzen für die Weiterleitung der Anforderung an den ausgewählten Modellpod verantwortlich sind und die Antwort an den ursprünglichen Benutzer zurückleiten.
Automatische Skalierung
Der Azure Machine Learning-Rückschlussrouter verwaltet die automatische Skalierung für alle Modellimplementierungen im Kubernetes-Cluster. Da er von allen Rückschlussanforderungen durchlaufen wird, verfügt er über die zum automatischen Skalieren der bereitgestellten Modelle erforderlichen Daten.
Wichtig
Aktivieren Sie die horizontale automatische Kubernetes-Podskalierung (HPA) nicht für Modellbereitstellungen. Dies würde dazu führen, dass die beiden Komponenten für die automatische Skalierung miteinander konkurrieren würden. Azureml-fe ist für die automatische Skalierung von Modellen konzipiert, die von Azure Machine Learning bereitgestellt wurden. Dabei müsste HPA die Modellauslastung anhand einer generischen Metrik wie der CPU-Auslastung oder einer benutzerdefinierten Metrikkonfiguration erraten oder näherungsweise ermitteln.
Azureml-fe skaliert die Anzahl der Knoten in einem AKS-Cluster nicht, da dies zu unerwarteten Kostensteigerungen führen könnte. Stattdessen erfolgt eine Skalierung der Anzahl der Replikate für das Modell innerhalb der physischen Clustergrenzen. Wenn Sie die Anzahl der Knoten im Cluster skalieren müssen, können Sie den Cluster manuell skalieren oder die Autoskalierung von AKS-Clustern konfigurieren.
Die automatische Skalierung kann über die scale_settings-Eigenschaft in der YAML-Datei für die Bereitstellung gesteuert werden. Die Aktivierung der automatischen Skalierung wird im folgenden Beispiel veranschaulicht:
# deployment yaml
# other properties skipped
scale_setting:
type: target_utilization
min_instances: 3
max_instances: 15
target_utilization_percentage: 70
polling_interval: 10
# other deployment properties continue
Die Entscheidung, hoch- oder herunterzuskalieren, basiert auf der utilization of the current container replicas.
utilization_percentage = (The number of replicas that are busy processing a request + The number of requests queued in azureml-fe) / The total number of current replicas
Übersteigt dieser Wert target_utilization_percentage, werden weitere Replikate erstellt. Wenn es niedriger ist, werden Replikate reduziert. Die Zielauslastung ist standardmäßig auf 70 Prozent festgelegt.
Entscheidungen zum Hinzufügen von Replikaten sind eifrig und schnell (ungefähr 1 Sekunde). Die Entscheidung, Replikate zu entfernen, erfolgt zurückhaltend (etwa 1 Minute).
Wenn Sie z. B. einen Modelldienst bereitstellen und wissen möchten, wie viele Instanzen (Pods/Replikate) für die Zielanforderungen pro Sekunde (Requests Per Second, RPS) und die Zielantwortzeit konfiguriert werden sollten. Die erforderlichen Replikate können mithilfe des folgenden Codes berechnet werden:
from math import ceil
# target requests per second
targetRps = 20
# time to process the request (in seconds)
reqTime = 10
# Maximum requests per container
maxReqPerContainer = 1
# target_utilization. 70% in this example
targetUtilization = .7
concurrentRequests = targetRps * reqTime / targetUtilization
# Number of container replicas
replicas = ceil(concurrentRequests / maxReqPerContainer)
Leistung von azureml-fe
azureml-fe kann bis zu 5.000 Anforderungen pro Sekunde (Requests per Second, RPS) mit guter Wartezeit erreichen, wobei der Overhead im Durchschnitt nicht mehr als 3 ms und im 99. Perzentil nicht mehr als 15 ms beträgt.
Hinweis
Wenn Sie mehr als 10.000 RPS benötigen, sollten Sie die folgenden Optionen in Betracht ziehen:
- Erhöhen Sie die Ressourcenanforderungen/Grenzwerte für
azureml-fe-Pods. Standardmäßig gilt ein Ressourcenlimit von 2 vCPU und 1,2 GB Arbeitsspeicher. - Verringern Sie die Anzahl der Instanzen für
azureml-fe. Standardmäßig erstellt Azure Machine Learning eine oder dreiazureml-fe-Instanzen pro Cluster.- Diese Instanzanzahl hängt von Ihrer
inferenceRouterHA-Konfiguration der Azure Machine Learning-Erweiterung ab. - Die erhöhte Instanzanzahl kann nicht beibehalten werden, da sie nach dem Upgrade der Erweiterung mit Ihrem konfigurierten Wert überschrieben wird.
- Diese Instanzanzahl hängt von Ihrer
- Wenden Sie sich an die Microsoft-Experten, um Hilfe zu erhalten.
Grundlegendes zu Konnektivitätsanforderungen für AKS-Rückschlusscluster
Der AKS-Cluster wird mit einem der beiden folgenden Netzwerkmodelle bereitgestellt:
- Kubenet-Netzwerke: Die Netzwerkressourcen werden normalerweise bei der Bereitstellung des AKS-Clusters erstellt und konfiguriert.
- Azure Container Networking Interface (CNI)-Netzwerke: Der AKS-Cluster wird mit einer vorhandenen virtuellen Netzwerkressource und -konfigurationen verbunden.
Für das Kubenet-Netzwerk wird das Netzwerk für den Azure Machine Learning Service erstellt und ordnungsgemäß konfiguriert. Für das CNI-Netzwerk müssen Sie die Konnektivitätsanforderungen verstehen und die DNS-Auflösung und die ausgehende Konnektivität für AKS-Rückschlüsse sicherstellen. Es können beispielsweise weitere Schritte erforderlich sein, wenn Sie eine Firewall verwenden, um Netzwerkdatenverkehr zu blockieren.
Das folgende Diagramm zeigt die Konnektivitätsanforderungen für AKS-Rückschlüsse. Die schwarzen Pfeile stehen für die tatsächliche Kommunikation und die blauen Pfeile für die Domänennamen. Möglicherweise müssen Sie Einträge für diese Hosts zu Ihrer Firewall oder zu Ihrem benutzerdefinierten DNS-Server hinzufügen.
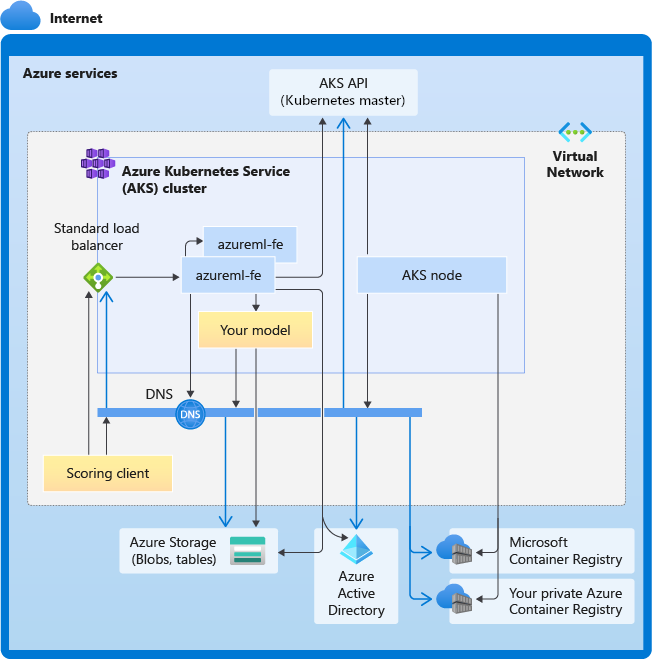
Allgemeine Anforderungen an die AKS-Konnektivität finden Sie unter Steuern des ausgehenden Datenverkehrs für Clusterknoten in Azure Kubernetes Service (AKS).
Informationen zum Zugreifen auf Azure Machine Learning-Dienste hinter einer Firewall finden Sie unter Konfigurieren von ein- und ausgehendem Netzwerkdatenverkehr.
Allgemeine Anforderungen an die DNS-Auflösung
Die DNS-Auflösung innerhalb eines bestehenden virtuellen Netzwerks unterliegt Ihrer Kontrolle. Beispiel: Firewall oder benutzerdefinierter DNS-Server. Die folgenden Hosts müssen erreichbar sein:
| Hostname | Verwendet von |
|---|---|
<cluster>.hcp.<region>.azmk8s.io |
AKS-API-Server |
mcr.microsoft.com |
Microsoft Container Registry (MCR) |
<ACR name>.azurecr.io |
Azure Container Registry (ACR) |
<account>.blob.core.windows.net |
Azure Storage-Konto (Blobspeicher) |
api.azureml.ms |
Microsoft Entra-Authentifizierung |
ingest-vienna<region>.kusto.windows.net |
Kusto-Endpunkt zum Hochladen von Telemetriedaten |
Konnektivitätsanforderungen in chronologischer Reihenfolge: von der Clustererstellung zur Modellimplementierung
Direkt nach der Bereitstellung von azureml-fe wird der Start versucht und dies erfordert Folgendes:
- Auflösen von DNS für den AKS-API-Server
- Fragen Sie den AKS-API-Server ab, um andere Instanzen von sich selbst zu ermitteln (es handelt sich um einen Multi-Pod-Dienst).
- Herstellen einer Verbindung mit anderen Instanzen von sich selbst
Nachdem azureml-fe gestartet wurde, benötigt es die folgende Konnektivität, um ordnungsgemäß zu funktionieren:
- Herstellen einer Verbindung mit Azure Storage zum Herunterladen einer dynamischen Konfiguration
- Lösen Sie das DNS für den Microsoft Entra-Authentifizierungsserver „api.azureml.ms“ auf und kommunizieren Sie mit ihm, wenn der bereitgestellte Dienst die Microsoft Entra-Authentifizierung verwendet.
- Abfragen des AKS-API-Servers, um bereitgestellte Modelle zu entdecken
- Kommunizieren mit bereitgestellten Modell-PODs
Zum Zeitpunkt der Modellimplementierung sollte der AKS-Knoten zu Folgendem in der Lage sein:
- Auflösen von DNS für die ACR des Kunden
- Herunterladen von Images aus der ACR des Kunden
- Auflösen von DNS für Azure-BLOBs, in denen das Modell gespeichert wird
- Herunterladen von Modellen aus Azure-BLOBs
Nachdem das Modell bereitgestellt und der Dienst gestartet wurde, erkennt azureml-fe es automatisch mithilfe der AKS-API und ist bereit, Anforderungen an es weiterzuleiten. Es muss in der Lage sein, mit den Modell-PODs zu kommunizieren.
Hinweis
Wenn das bereitgestellte Modell eine Konnektivität erfordert (z. B. Abfragen einer externen Datenbank oder eines anderen REST-Diensts, Herunterladen eines BLOBs usw.), dann sollten sowohl die DNS-Auflösung als auch die ausgehende Kommunikation für diese Dienste aktiviert sein.