Auswählen von Algorithmen für Azure Machine Learning
Eine häufig gestellte Frage lautet: „Welchen Algorithmus für maschinelles Lernen sollte ich verwenden?“ Der von Ihnen gewählte Algorithmus hängt in erster Linie von zwei verschiedenen Aspekten Ihres Data Science-Szenarios ab:
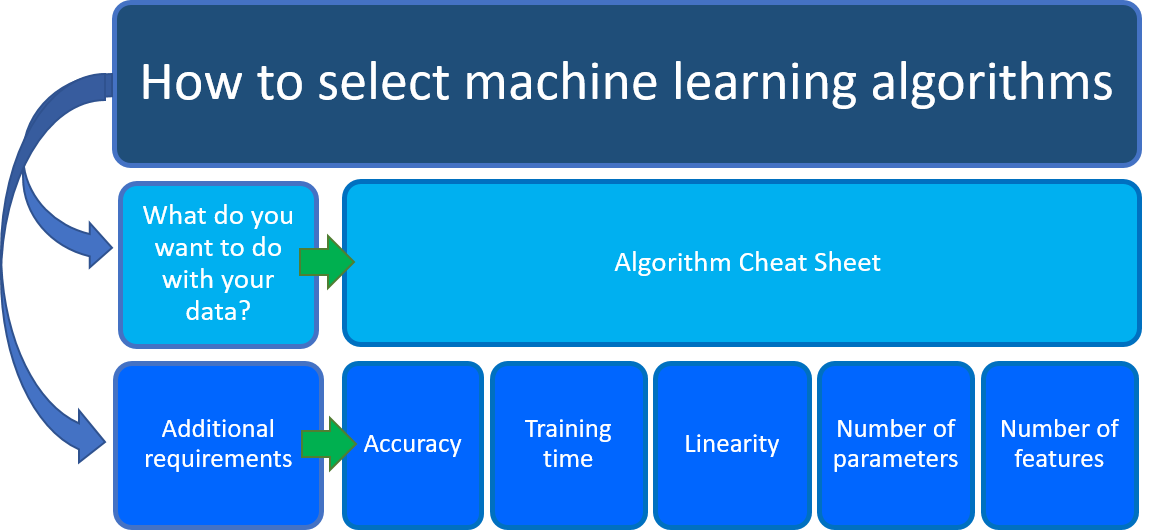
Was möchten Sie mit Ihren Daten machen? Wie genau lautet die geschäftliche Frage, die Sie beantworten möchten, indem Sie aus Ihren bisherigen Daten lernen?
Welche Anforderungen gelten für Ihr Data Science-Szenario? Welche Genauigkeit, Trainingszeit, Linearität, Anzahl der Parameter und Anzahl der Features unterstützt Ihre Lösung im Besonderen?
Hinweis
Der Designer unterstützt zwei Komponententypen: klassische vorkonfigurierte Komponenten (v1) und benutzerdefinierte Komponenten (v2). Diese beiden Komponententypen sind NICHT kompatibel.
Klassische vorkonfigurierte Komponenten bieten vordefinierte Komponenten, die vor allem für die Datenverarbeitung und für herkömmliche Machine Learning-Aufgaben wie Regression und Klassifizierung genutzt werden. Dieser Komponententyp wird weiterhin unterstützt, aber es werden keine neuen Komponenten hinzugefügt.
Benutzerdefinierte Komponenten ermöglichen es Ihnen, Ihren eigenen Code als Komponente bereitzustellen. Sie unterstützen die arbeitsbereichübergreifende Freigabe und die reibungslose Erstellung über Studio-, CLI (v2)- und SDK (v2)-Schnittstellen.
Für neue Projekte wird dringend empfohlen, eine benutzerdefinierte Komponente zu verwenden, die mit AzureML V2 kompatibel ist und weiterhin neue Updates erhält.
Dieser Artikel gilt für klassische vordefinierte Komponenten und ist nicht mit CLI v2 und SDK v2 kompatibel.
Geschäftsszenarios und der Spickzettel für Machine Learning-Algorithmen
Der Spickzettel für Azure Machine Learning-Algorithmen hilft Ihnen bei der ersten Überlegung: Was möchten Sie mit Ihren Daten machen? Suchen Sie auf dem Spickzettel für den Machine Learning-Algorithmus nach der Aufgabe, die Sie erledigen möchten, und suchen Sie dann einen Azure Machine Learning-Designeralgorithmus für die Predictive Analytics-Lösung.
Der Machine Learning-Designer bietet ein umfassendes Portfolio an Algorithmen, z. B. Entscheidungswald mit mehreren Klassen, Empfehlungssysteme, Regression mit neuronalen Netzwerken, Mehrklassiges neuronales Netzwerk und k-Means-Algorithmus. Jeder Algorithmus ist speziell auf eine andere Art von Machine Learning-Problem ausgelegt. Eine vollständige Liste finden Sie in der Algorithmus- und Komponentenreferenz des Designers für maschinelles Lernen, zusammen mit einer Dokumentation über die Funktionsweise der einzelnen Algorithmen und die Einstellung der Parameter zur Optimierung des Algorithmus.
Hinweis
Laden Sie das Cheatsheet hier herunter: Cheatsheet für Machine Learning-Algorithmen (11x17 Zoll)
Berücksichtigen Sie neben der Anleitung auf dem Spickzettel für den Azure Machine Learning-Algorithmus auch andere Anforderungen, wenn Sie einen Algorithmus für maschinelles Lernen für Ihre Lösung auswählen. Im Folgenden sind zusätzliche Faktoren zu berücksichtigen, z. B. die Genauigkeit, die Trainingszeit, die Linearität, die Anzahl der Parameter und die Anzahl der Features.
Vergleich von Algorithmen für maschinelles Lernen
Einige Lernalgorithmen treffen bestimmte Annahmen über die Struktur der Daten oder der gewünschten Ergebnisse. Wenn Sie einen finden, der Ihren Bedürfnissen entspricht, kann Ihnen dieser genauere Vorhersagen oder kürzere Trainingsdauern liefern.
In der folgenden Tabelle werden einige der wichtigsten Merkmale von Algorithmen aus den Familien Klassifizierung, Regression und Clustering zusammengefasst:
| Algorithmus | Genauigkeit | Trainingsdauer | Linearität | Parameter | Hinweise |
|---|---|---|---|---|---|
| Familie Klassifizierung | |||||
| Logistische Regression mit zwei Klassen | Gut | Schnell | Ja | 4 | |
| Entscheidungswald mit zwei Klassen | Hervorragend | Moderat | Nein | 5 | Bei diesem Algorithmus kommt es zu längeren Bewertungszeiten. Es wird empfohlen, nicht mit One-vs-All-Klassifizierung mit mehreren Klassen zu arbeiten, da das Sperren von Threads beim Akkumulieren von Entscheidungsstrukturvorhersagen zu längeren Bewertungszeiten führt. |
| Verstärkte Entscheidungsstruktur mit zwei Klassen | Hervorragend | Moderat | Nein | 6 | Hoher Speicherbedarf |
| Neuronales Netz mit zwei Klassen | Gut | Moderat | Nein | 8 | |
| Gemitteltes Perzeptron mit zwei Klassen | Gut | Moderat | Ja | 4 | |
| Support Vector Machine mit zwei Klassen | Gut | Schnell | Ja | 5 | Für große Merkmalssätze geeignet |
| Logistische Regression mit mehreren Klassen | Gut | Schnell | Ja | 4 | |
| Entscheidungswald mit mehreren Klassen | Hervorragend | Moderat | Nein | 5 | Bei diesem Algorithmus kommt es zu längeren Bewertungszeiten. |
| Verstärkte Entscheidungsstruktur mit mehreren Klassen | Hervorragend | Moderat | Nein | 6 | Verbessert tendenziell die Genauigkeit, allerdings mit einem geringen Risiko einer geringeren Abdeckung |
| Neuronales Netz mit mehreren Klassen | Gut | Moderat | Nein | 8 | |
| One-vs-All-Klassifizierung mit mehreren Klassen | - | - | - | - | Siehe die Eigenschaften der ausgewählten zweiklassigen Methode |
| Familie Regression | |||||
| Lineare Regression | Gut | Schnell | Ja | 4 | |
| Regression mit Entscheidungswald | Hervorragend | Moderat | Nein | 5 | |
| Regression mit verstärkter Entscheidungsstruktur | Hervorragend | Moderat | Nein | 6 | Hoher Speicherbedarf |
| Regression mit neuronalem Netz | Gut | Moderat | Nein | 8 | |
| Familie Clustering | |||||
| k-Means-Clustering | Hervorragend | Moderat | Ja | 8 | Clusteringalgorithmus |
Anforderungen für ein Data Science-Szenario
Sobald Sie wissen, wie Sie mit Ihren Daten verfahren möchten, müssen Sie zusätzliche Anforderungen für Ihre Lösung festlegen.
Treffen Sie Entscheidungen und möglicherweise Kompromisse für die folgenden Anforderungen:
- Genauigkeit
- Trainingsdauer
- Linearität
- Anzahl von Parametern
- Anzahl von Merkmalen
Genauigkeit
Die Genauigkeit beim maschinellen Lernen misst die Wirksamkeit eines Modells als Anteil der tatsächlichen Ergebnisse an der Gesamtzahl der Fälle. Im Machine Learning Designer berechnet die Komponente Evaluate Model eine Reihe von standardisierten Bewertungsmetriken. Sie können diese Komponente verwenden, um die Genauigkeit eines trainierten Modells zu messen.
Eine so genaue Antwort wie möglich zu erhalten, ist nicht immer erforderlich. Manchmal ist ein Näherungswert ausreichend, je nachdem, wofür Sie ihn verwenden möchten. Wenn dies der Fall ist, können Sie die Verarbeitungszeit möglicherweise erheblich verringern, indem Sie stärker Näherungsmethoden verwenden. Näherungsmethoden neigen natürlich auch dazu, eine Überanpassung zu vermeiden.
Es gibt drei Möglichkeiten, die Komponente Modell auswerten zu verwenden:
- Generieren Sie Ergebnisse zu Ihren Trainingsdaten, um das Modell auszuwerten.
- Generieren Sie Ergebnisse für das Modell, vergleichen Sie diese aber mit Ergebnissen für ein reserviertes Testdataset.
- Vergleichen Sie die Ergebnisse für zwei verschiedene, aber zusammengehörige Modelle unter Verwendung desselben Datasets.
Eine vollständige Liste der Metriken und Ansätze, die Sie zur Bewertung der Genauigkeit von Modellen des maschinellen Lernens verwenden können, finden Sie unter Modellkomponente auswerten.
Trainingsdauer
Beim beaufsichtigten Lernen bedeutet Training die Verwendung historischer Daten zur Erstellung eines Machine Learning-Modells, das Fehler minimiert. Die Anzahl der Minuten oder Stunden, die zum Trainieren eines Modells notwendig sind, variieren sehr stark von Algorithmus zu Algorithmus. Die Trainingsdauer ist oft eng an die Genauigkeit gebunden. Das eine geht in der Regel mit dem anderen einher.
Darüber hinaus reagieren einige Algorithmen empfindlicher auf die Anzahl der Datenpunkte als andere. Aufgrund der vorliegenden zeitlichen Begrenzung könnten Sie einen bestimmten Algorithmus auswählen, insbesondere wenn das Dataset groß ist.
Im Machine Learning-Designer werden Machine Learning-Modelle in der Regel in einem dreistufigen Prozess erstellt und verwendet:
Konfigurieren eines Modells, indem Sie einen bestimmten Algorithmustyp auswählen und dann seine Parameter oder Hyperparameter definieren.
Bereitstellen eines bezeichneten Datasets mit Daten, die mit dem Algorithmus kompatibel sind. Verbinden Sie sowohl die Daten als auch das Modell mit der Komponente Train Model.
Nach Abschluss des Trainings verwenden Sie das trainierte Modell mit einer der Score-Komponenten, um Vorhersagen für neue Daten zu treffen.
Linearität
Linearität in der Statistik und beim maschinellen Lernen bedeutet, dass es eine lineare Beziehung zwischen einer Variablen und einer Konstanten in Ihrem Dataset gibt. Lineare Klassifizierungsalgorithmen gehen z. B. davon aus, dass sich Klassen durch einer gerade Linie (oder deren höher dimensionale Entsprechung) trennen lassen.
Viele Algorithmen für maschinelles Lernen nutzen Linearität. Im Azure Machine Learning-Designer umfassen sie Folgendes:
- Logistische Regression mit mehreren Klassen
- Logistische Regression mit zwei Klassen
- Support Vector Machines
Linear Regressionsalgorithmen gehen davon aus, dass Datentrends einer geraden Linie folgen. Diese Annahme ist für einige Probleme durchaus angemessen, aber für andere verringert sie die Genauigkeit. Trotz ihrer Nachteile sind lineare Algorithmen als erste Strategie beliebt. Sie sind tendenziell algorithmisch einfach und lassen sich schnell trainieren.
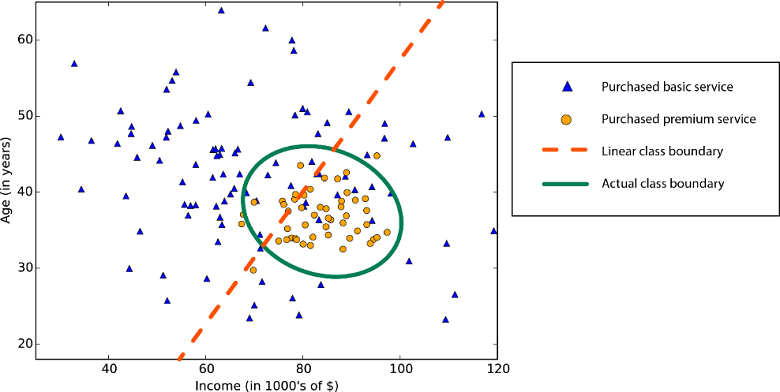
Nicht lineare Klassengrenze: Die Verwendung eines linearen Klassifizierungsalgorithmus würde zu einer verringerten Genauigkeit führen.
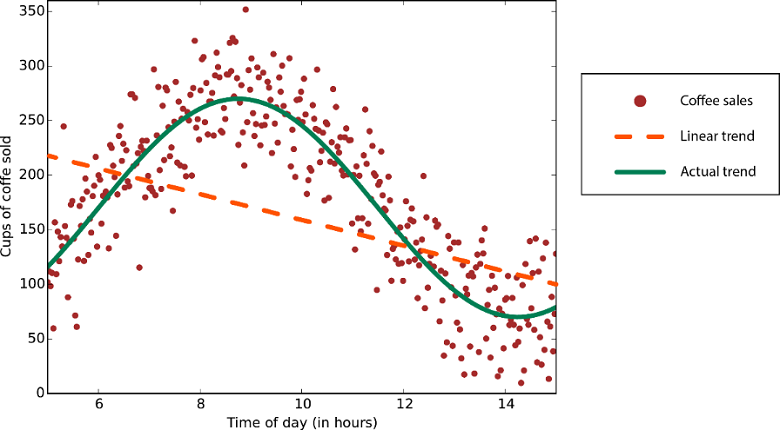
Daten mit einem nicht linearen Trend: Die Verwendung einer linearen Regressionsmethode würde wesentlich höhere Fehler erzeugen als nötig.
Anzahl von Parametern
Parameter sind die Knöpfe, an denen ein Datenanalyst drehen kann, wenn er einen Algorithmus einrichtet. Es handelt sich dabei um Zahlen, die das Verhalten des Algorithmus beeinflussen, z. B. Fehlertoleranz oder Anzahl von Iterationen oder Optionen zwischen Varianten der Verhaltensweisen des Algorithmus. Die Trainingsdauer und die Genauigkeit des Algorithmus können beim Finden der richtigen Einstellungen manchmal empfindlich reagieren. Normalerweise erfordern Algorithmen mit vielen Parametern die meisten Testversuche, um eine gute Kombination zu finden.
Alternativ dazu gibt es die Komponente Tune Model Hyperparameters im Machine Learning Designer: Ziel dieser Komponente ist es, die optimalen Hyperparameter für ein maschinelles Lernmodell zu bestimmen. Die Komponente erstellt und testet mehrere Modelle unter Verwendung verschiedener Kombinationen von Einstellungen. Die Metriken werden über alle Modelle hinweg verglichen, um die Kombinationen der Einstellungen zu erhalten.
Zwar stellt dies eine hervorragende Möglichkeit dar, um sicherzustellen, dass Sie den gesamten Parameterbereich abgedeckt haben, doch die Zeit, die zum Trainieren eines Modells erforderlich ist, steigt exponentiell mit der Anzahl der Parameter. Der Vorteil ist, dass das Vorhandensein vieler Parameter normalerweise darauf hindeutet, dass ein Algorithmus über größere Flexibilität verfügt. Er erreicht oft eine hervorragende Genauigkeit, vorausgesetzt, dass Sie die richtige Kombination von Parametereinstellungen finden.
Anzahl von Merkmalen
Beim maschinellen Lernen ist ein Merkmal eine quantifizierbare Variable des Phänomens, das Sie zu analysieren versuchen. Bei bestimmten Datentypen kann die Anzahl der Merkmale im Vergleich zur Anzahl der Datenpunkte sehr groß sein. Dies ist häufig der Fall bei Genetik- oder Textdaten.
Eine große Anzahl von Merkmalen kann bei einigen Lernalgorithmen dazu führen, dass sie sich verzetteln, was impraktikabel lange Trainingsdauern nach sich zieht. Support Vector Machines eignen sich besonders gut für Szenarien mit einer hohen Anzahl von Merkmalen. Aus diesem Grund wurden sie in vielen Anwendungen (von der Informationsbeschaffung bis zur Text- und Bildklassifizierung) eingesetzt. Support Vector Machines können für sowohl Klassifizierungs-als auch Regressionsaufgaben verwendet werden.
„Feature Selection“ (Auswahl von Merkmalen) bezieht sich auf die Anwendung statistischer Tests auf Eingaben, wenn eine Ausgabe angegeben ist. Das Ziel besteht in der Bestimmung der Spalten, die für die Ausgabe aussagekräftiger sind. Die Komponente Filterbasierte Merkmalsauswahl im Designer für maschinelles Lernen bietet mehrere Algorithmen zur Merkmalsauswahl zur Auswahl an. Die Komponente umfasst Korrelationsmethoden wie die Pearson-Korrelation und Chi-Quadrat-Werte.
Sie können auch die Komponente Permutation Feature Importance verwenden, um einen Satz von Feature Importance Scores für Ihren Datensatz zu berechnen. Sie können dann diese Bewertungen nutzen, um die besten Merkmale zur Verwendung in einem Modell zu bestimmen.
Nächste Schritte
- Weitere Informationen zum Azure Machine Learning-Designer
- Beschreibungen aller in Azure Machine Learning Designer verfügbaren Algorithmen für maschinelles Lernen finden Sie unter Machine Learning Designer Algorithmus- und Komponentenreferenz
- Informationen zur Beziehung zwischen Deep Learning, maschinellem Lernen und KI finden Sie unter Deep Learning im Vergleich zu maschinellem Lernen