Interaktives Data Wrangling mit Apache Spark in Azure Machine Learning
Data Wrangling wird zu einem der wichtigsten Bestandteile von Machine Learning-Projekten. Die Azure Machine Learning-Integration mit Azure Synapse Analytics bietet mithilfe von Azure Synapse Zugriff auf einen Apache Spark-Pool, sodass interaktives Data Wrangling mithilfe von Azure Machine Learning-Notebooks durchgeführt werden kann.
In diesem Artikel erfahren Sie, wie Sie Data Wrangling mithilfe der folgenden Elemente durchführen können:
- Serverloses Spark Compute
- Angefügter Synapse Spark-Pool
Voraussetzungen
- Ein Azure-Abonnement: Sollten Sie über kein Azure-Abonnement verfügen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
- Ein Azure Machine Learning-Arbeitsbereich. Siehe Erstellen von Arbeitsbereichsressourcen.
- Ein ADLS Gen2-Speicherkonto (Azure Data Lake Storage). Weitere Informationen finden Sie unter Erstellen eines ADLS Gen2-Speicherkontos (Azure Data Lake Storage).
- (Optional): Eine Azure Key Vault-Instanz. Weitere Informationen finden Sie unter Erstellen einer Azure Key Vault-Instanz.
- (Optional): Ein Dienstprinzipal. Weitere Informationen finden Sie unter Erstellen eines Dienstprinzipals.
- (Optional): Ein angefügter Synapse Spark-Pool im Azure Machine Learning-Arbeitsbereich.
Bevor Sie Ihre Data Wrangling-Aufgaben starten, sollten Sie sich über den Prozess der Speicherung von Geheimnissen informieren.
- Zugriffsschlüssel für das Azure Blob Storage-Konto
- SAS-Token (Shared Access Signature)
- Dienstprinzipalinformationen für ADLS Gen2 (Azure Data Lake Storage)
in der Azure Key Vault-Instanz vertraut machen. Außerdem müssen Sie wissen, wie Rollenzuweisungen in Azure-Speicherkonten funktionieren. Diese Konzepte werden in den folgenden Abschnitten erläutert. Anschließend wird auf die Einzelheiten des interaktiven Data Wrangling mithilfe des Spark-Pools in Azure Machine Learning-Notebooks eingegangen.
Tipp
Weitere Informationen über die Konfiguration der Rollenzuweisung für Azure-Speicherkonten oder über den Zugriff auf Daten in Ihren Speicherkonten mit dem Passthrough der Benutzeridentität finden Sie unter Hinzufügen von Rollenzuweisungen in Azure-Speicherkonten.
Interaktives Data Wrangling mit Apache Spark
Azure Machine Learning bietet serverlose Spark-Berechnungen und einen angebundenen Synapse Spark-Pool für interaktives Data Wrangling mit Apache Spark in Azure Machine Learning Notebooks. Für serverloses Spark Compute müssen keine Ressourcen im Azure Synapse-Arbeitsbereich erstellt werden. Stattdessen wird eine vollständig verwaltete serverlose Spark-Computeressource direkt in den Azure Machine Learning-Notebooks verfügbar. Die Verwendung des serverlosen Spark Compute ist die einfachste Möglichkeit, auf einen Spark-Cluster in Azure Machine Learning zuzugreifen.
Serverloses Spark Compute in Azure Machine Learning Notebooks
Serverloses Spark Compute ist standardmäßig in Azure Machine Learning Notebooks verfügbar. Um in einem Notebook darauf zuzugreifen, wählen Sie unter Azure Machine Learning Serverless Spark die Option Serverloses Spark-Compute aus dem Auswahlmenü Compute aus.
Die Benutzeroberfläche von Notebooks bietet auch Optionen für die Konfiguration von Spark-Sitzungen für serverloses Spark Compute. So konfigurieren Sie eine Spark-Sitzung:
- Wählen Sie am oberen Rand des Bildschirms Sitzung konfigurieren.
- Wählen Sie die Apache Spark-Version aus der Dropdownliste aus.
Wichtig
Azure Synapse-Runtime für Apache Spark: Ankündigungen
- Azure Synapse Runtime for Apache Spark 3.2:
- EOLA-Datum: 8. Juli 2023
- Datum für Supportende: 8. Juli 2024. Nach diesem Datum wird die Runtime deaktiviert.
- Wenn Sie weiterhin Support erhalten und von optimaler Leistung profitieren möchten, empfehlen wir die Migration zu Apache Spark 3.3.
- Azure Synapse Runtime for Apache Spark 3.2:
- Wählen Sie im Dropdownmenü Instanztyp aus. Folgende Instanztypen werden derzeit unterstützt:
Standard_E4s_v3Standard_E8s_v3Standard_E16s_v3Standard_E32s_v3Standard_E64s_v3
- Geben Sie einen Wert für das Spark-Sitzungstimeout in Minuten ein.
- Wählen Sie aus, ob Sie Executors dynamisch zuordnen möchten.
- Wählen Sie die Anzahl der Executors für die Spark-Sitzung aus.
- Wählen Sie aus dem Dropdownmenü die Executor size (Executorgröße) aus.
- Wählen Sie aus dem Dropdownmenü die Driver size (Treibergröße) aus.
- Aktivieren Sie das Kontrollkästchen Conda-Datei hochladen, um eine Conda-Datei zum Konfigurieren einer Spark-Sitzung zu verwenden. Wählen Sie anschließend Durchsuchen aus, und wählen Sie die Conda-Datei mit der gewünschten Spark-Sitzungskonfiguration aus.
- Fügen Sie Eigenschaften zu den Konfigurationseinstellungen hinzu, geben Sie Werte in die Textfelder Eigenschaft und Wert ein, und wählen Sie Hinzufügen aus.
- Wählen Sie Übernehmen.
- Wählen Sie Sitzung beenden im Popupfenster Neue Sitzung konfigurieren? aus.
Die Änderungen an der Sitzungskonfiguration bleiben bestehen und werden für eine andere Notebook-Sitzung verfügbar, die mit dem serverlosen Spark Compute gestartet wird.
Tipp
Wenn Sie Conda-Pakete auf Sitzungsebene verwenden, können Sie die Kaltstartzeit der Spark-Sitzung verbessern, wenn Sie die Konfigurationsvariable spark.hadoop.aml.enable_cache auf „true“ festlegen. Ein Kaltstart der Sitzung mit Conda-Paketen auf Sitzungsebene dauert in der Regel 10 bis 15 Minuten, wenn die Sitzung zum ersten Mal gestartet wird. Nachfolgende Kaltstarts von Sitzungen, bei denen die Konfigurationsvariable auf „true“ gesetzt ist, dauern jedoch normalerweise drei bis fünf Minuten.
Importieren und Aufbereiten von Daten aus ADLS Gen2 (Azure Data Lake Storage)
Sie können auf mit abfss://-Daten-URIs in ADLS Gen2-Speicherkonten (Azure Data Lake Storage) gespeicherte Daten zugreifen und diese aufbereiten, indem Sie einen der folgenden Zugriffsmechanismen verwenden:
- Passthrough der Benutzeridentität
- Dienstprinzipalbasierter Datenzugriff
Tipp
Data Wrangling mit serverlosem Spark-Computing und Passthrough der Benutzeridentität für den Zugriff auf Daten in einem ADLS Gen 2-Speicherkonto (Azure Data Lake Storage) erfordert die geringste Anzahl von Konfigurationsschritten.
So starten Sie das interaktive Data Wrangling mit dem Passthrough der Benutzeridentität:
Überprüfen Sie, ob die Benutzeridentität über die RollenzuweisungenMitwirkender und Mitwirkender an Storage-Blobdaten im ADLS Gen2-Speicherkonto (Azure Data Lake Storage) verfügt.
Um das serverlose Spark Compute zu verwenden, wählen Sie unter Azure Machine Learning Serverless Spark die Option Serverloses Spark Compute im Compute-Auswahlmenü aus.
Wählen Sie im Auswahlmenü Compute unter Synapse Spark-Pool einen angefügten Synapse Spark-Pool aus, um einen angefügten Synapse Spark-Pool zu verwenden.
Bei diesem Codebeispiel für Titanic-Data Wrangling wird die Verwendung eines Daten-URI im Format
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>mitpyspark.pandasundpyspark.ml.feature.Imputerveranschaulicht.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/wrangled", index_col="PassengerId", )Hinweis
Dieses Python-Codebeispiel verwendet
pyspark.pandas. Dies wird nur von der Spark-Laufzeitversion 3.2 oder höher unterstützt.
So bereiten Sie Daten durch den Zugriff über einen Dienstprinzipal auf:
Überprüfen Sie, ob der Dienstprinzipal über die RollenzuweisungenMitwirkender und Mitwirkender an Storage-Blobdaten im ADLS Gen2-Speicherkonto (Azure Data Lake Storage) verfügt.
Erstellen Sie Azure Key Vault-Geheimnisse für die Mandanten-ID, die Client-ID und die Werte des geheimen Clientschlüssels des Dienstprinzipals.
Wählen Sie Serverloses Spark Compute unter Azure Machine Learning Serverless Spark aus dem Compute-Auswahlmenü aus, oder wählen Sie einen angefügten Synapse Spark-Pool unter Synapse Spark-Pools aus dem Compute-Auswahlmenü aus.
Führen Sie das folgende Codebeispiel aus, um die Mandanten-ID, die Client-ID und den geheimen Clientschlüssel des Dienstprinzipals in der Konfiguration festzulegen.
Der
get_secret()-Aufruf im Code hängt vom Namen der Azure Key Vault-Instanz und den Namen der Azure Key Vault-Geheimnisse ab, die für die Mandanten-ID, die Client-ID und den geheimen Clientschlüssel des Dienstprinzipals erstellt wurden. Legen Sie diese entsprechenden Eigenschaftsnamen/Werte in der Konfiguration fest:- Eigenschaft der Client-ID:
fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Eigenschaft des geheimen Clientschlüssels:
fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Eigenschaft der Mandanten-ID:
fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Wert der Mandanten-ID:
https://login.microsoftonline.com/<TENANT_ID>/oauth2/token
from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary # Set up service principal tenant ID, client ID and secret from Azure Key Vault client_id = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_ID_SECRET_NAME>") tenant_id = token_library.getSecret("<KEY_VAULT_NAME>", "<TENANT_ID_SECRET_NAME>") client_secret = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_SECRET_NAME>") # Set up service principal which has access of the data sc._jsc.hadoopConfiguration().set( "fs.azure.account.auth.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "OAuth" ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth.provider.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider", ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_id, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_secret, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "https://login.microsoftonline.com/" + tenant_id + "/oauth2/token", )- Eigenschaft der Client-ID:
Importieren Sie die Daten wie im Codebeispiel gezeigt mithilfe des Daten-URI im Format
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>, und bereiten Sie sie auf. Verwenden Sie dabei die Titanic-Daten.
Importieren und Aufbereiten von Daten aus Azure Blob Storage
Sie können auf Azure Blob Storage-Daten entweder mit dem Zugriffsschlüssel für das Speicherkonto oder einem SAS-Token (Shared Access Signature) zugreifen. Sie sollten diese Anmeldeinformationen in der Azure Key Vault-Instanz als Geheimnis speichern und als Eigenschaften in der Sitzungskonfiguration festlegen.
So beginnen Sie das interaktive Data Wrangling:
Wählen Sie im linken Bereich von Azure Machine Learning Studio Notebooks aus.
Wählen Sie Serverloses Spark Compute unter Azure Machine Learning Serverless Spark aus dem Compute-Auswahlmenü aus, oder wählen Sie einen angefügten Synapse Spark-Pool unter Synapse Spark-Pools aus dem Compute-Auswahlmenü aus.
So konfigurieren Sie den Zugriffsschlüssel für das Speicherkonto oder ein SAS-Token (Shared Access Signature) für den Datenzugriff in Azure Machine Learning-Notebooks:
Legen Sie die Eigenschaft
fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.netfür den Zugriffsschlüssel wie in diesem Codeschnipsel gezeigt fest:from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary access_key = token_library.getSecret("<KEY_VAULT_NAME>", "<ACCESS_KEY_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", access_key )Legen Sie die Eigenschaft
fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.netfür das SAS-Token wie in diesem Codeschnipsel gezeigt fest:from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary sas_token = token_library.getSecret("<KEY_VAULT_NAME>", "<SAS_TOKEN_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", sas_token, )Hinweis
Bei den
get_secret()-Aufrufen in den obigen Codeschnipseln sind der Name der Azure Key Vault-Instanz und die Namen der Geheimnisse erforderlich, die für den Zugriffsschlüssel oder das SAS-Token des Azure Blob Storage-Kontos erstellt wurden.
Führen Sie den Data Wrangling-Code im selben Notebook aus. Formatieren Sie den Daten-URI ähnlich wie in diesem Codeschnipsel als
wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/<PATH_TO_DATA>:import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/wrangled", index_col="PassengerId", )Hinweis
Dieses Python-Codebeispiel verwendet
pyspark.pandas. Dies wird nur von der Spark-Laufzeitversion 3.2 oder höher unterstützt.
Importieren und Aufbereiten von Daten aus dem Azure Machine Learning-Datenspeicher
Definieren Sie einen Pfad zu Daten im Datenspeicher mit dem URI-Formatazureml://datastores/<DATASTORE_NAME>/paths/<PATH_TO_DATA>, um auf Daten aus dem Azure Machine Learning-Datenspeicher zuzugreifen. So bereiten Sie Daten aus einem Azure Machine Learning-Datenspeicher interaktiv in einer Notebooks-Sitzung auf:
Wählen Sie Serverloses Spark Compute unter Azure Machine Learning Serverless Spark aus dem Compute-Auswahlmenü aus, oder wählen Sie einen angefügten Synapse Spark-Pool unter Synapse Spark-Pools aus dem Compute-Auswahlmenü aus.
In diesem Codebeispiel wird gezeigt, wie Titanic-Daten mithilfe des
azureml://-Datenspeicher-URI,pyspark.pandasundpyspark.ml.feature.Imputeraus einem Azure Machine Learning-Datenspeicher gelesen und aufbereitet werden können.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "azureml://datastores/workspaceblobstore/paths/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "azureml://datastores/workspaceblobstore/paths/data/wrangled", index_col="PassengerId", )Hinweis
Dieses Python-Codebeispiel verwendet
pyspark.pandas. Dies wird nur von der Spark-Laufzeitversion 3.2 oder höher unterstützt.
Azure Machine Learning-Datenspeicher können mithilfe der Anmeldeinformationen für das Azure-Speicherkonto auf Daten zugreifen
- Zugriffsschlüssel
- SAS-Token
- Dienstprinzipal
oder den Datenzugriff ohne Anmeldeinformationen gewähren. Je nach Datenspeichertyp und zugrunde liegendem Azure-Speicherkontotyp können Sie einen geeigneten Authentifizierungsmechanismus auswählen, um den Datenzugriff sicherzustellen. In dieser Tabelle sind die Authentifizierungsmechanismen für den Zugriff auf Daten in den Azure Machine Learning-Datenspeichern zusammengefasst:
| Speicherkontotyp | Datenzugriff ohne Anmeldeinformationen | Datenzugriffsmechanismus | Rollenzuweisungen |
|---|---|---|---|
| Azure Blob | Nein | Zugriffsschlüssel oder SAS-Token | Keine Rollenzuweisungen erforderlich |
| Azure Blob | Ja | Passthrough der Benutzeridentität* | Die Benutzeridentität sollte über geeignete Rollenzuweisungen im Azure Blob Storage-Konto verfügen. |
| ADLS Gen2 (Azure Data Lake Storage) | Nein | Dienstprinzipal | Der Dienstprinzipal sollte über geeignete Rollenzuweisungen im ADLS Gen2-Speicherkonto (Azure Data Lake Storage) verfügen. |
| ADLS Gen2 (Azure Data Lake Storage) | Ja | Passthrough der Benutzeridentität | Die Benutzeridentität sollte über geeignete Rollenzuweisungen im ADLS Gen2-Speicherkonto (Azure Data Lake Storage) verfügen. |
* Der Passthrough der Benutzeridentitäten funktioniert nur für Datenspeicher ohne Anmeldeinformationen, die auf Azure Blob Storage-Konten verweisen, wenn vorläufiges Löschen nicht aktiviert ist.
Zugreifen auf Daten in der Standarddateifreigabe
Die Standard-Dateifreigabe wird sowohl in serverlose Spark Compute- als auch in angeschlossene Synapse Spark-Pools eingebunden.
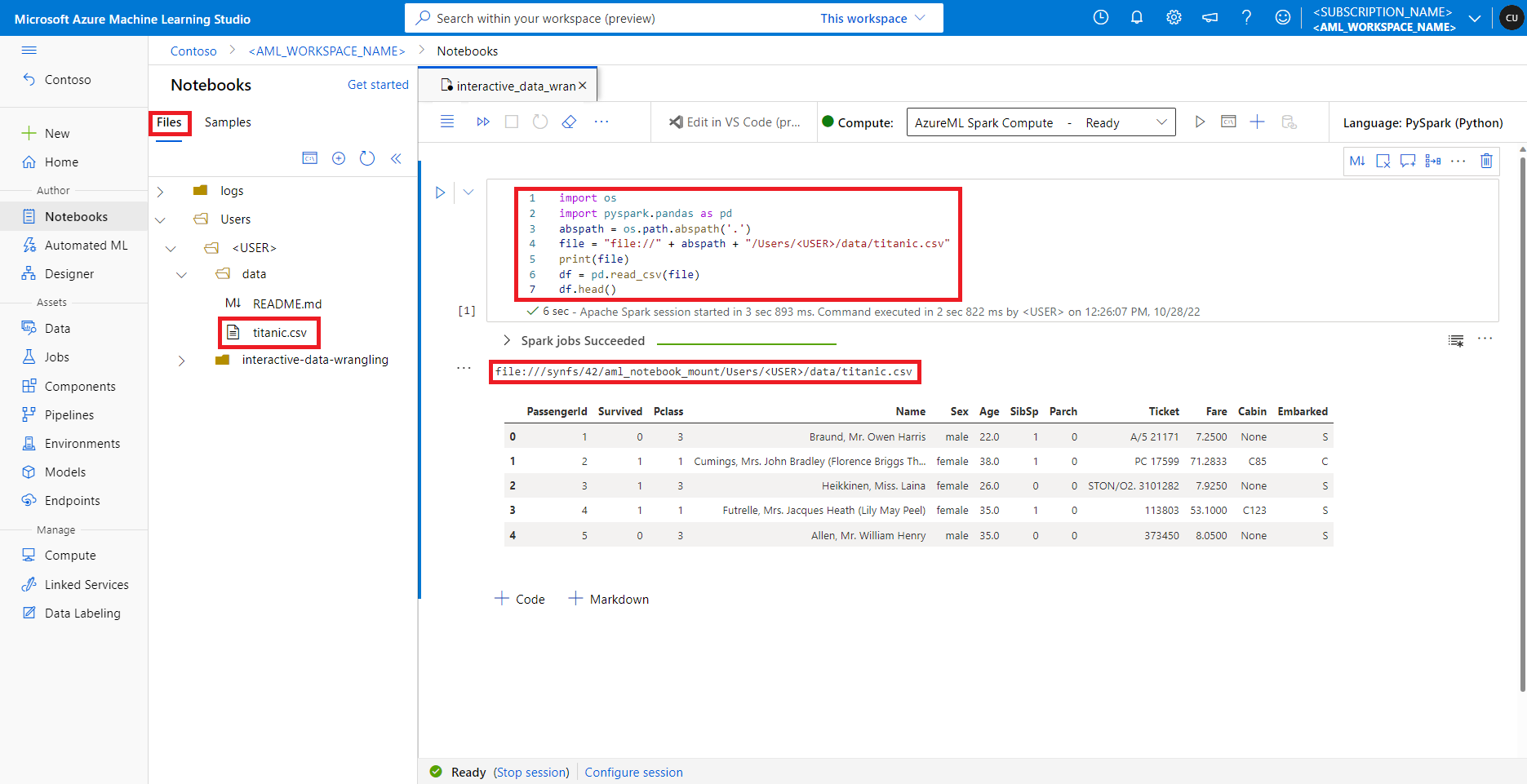
In Azure Machine Learning Studio werden Dateien in der Standarddateifreigabe in der Verzeichnisstruktur auf der Registerkarte Dateien angezeigt. Notebookcode kann direkt auf Dateien zugreifen, die in dieser Dateifreigabe mit dem file://-Protokoll zusammen mit dem absoluten Pfad der Datei und ohne weitere Konfigurationen gespeichert sind. Dieser Codeausschnitt zeigt, wie Sie auf eine Datei zugreifen, die in der Standarddateifreigabe gespeichert ist:
import os
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
abspath = os.path.abspath(".")
file = "file://" + abspath + "/Users/<USER>/data/titanic.csv"
print(file)
df = pd.read_csv(file, index_col="PassengerId")
imputer = Imputer(
inputCols=["Age"],
outputCol="Age").setStrategy("mean") # Replace missing values in Age column with the mean value
df.fillna(value={"Cabin" : "None"}, inplace=True) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
output_path = "file://" + abspath + "/Users/<USER>/data/wrangled"
df.to_csv(output_path, index_col="PassengerId")
Hinweis
Dieses Python-Codebeispiel verwendet pyspark.pandas. Dies wird nur von der Spark-Laufzeitversion 3.2 oder höher unterstützt.