Reverse proxy in Azure Service Fabric
Reverse proxy built into Azure Service Fabric helps microservices running in a Service Fabric cluster discover and communicate with other services that have http endpoints.
Microservices communication model
Microservices in Service Fabric run on a subset of nodes in the cluster and can migrate between the nodes for various reasons. As a result, the endpoints for microservices can change dynamically. To discover and communicate with other services in the cluster, microservice must go through the following steps:
- Resolve the service location through the naming service.
- Connect to the service.
- Wrap the preceding steps in a loop that implements service resolution and retry policies to apply on connection failures
For more information, see Connect and communicate with services.
Communicating by using the reverse proxy
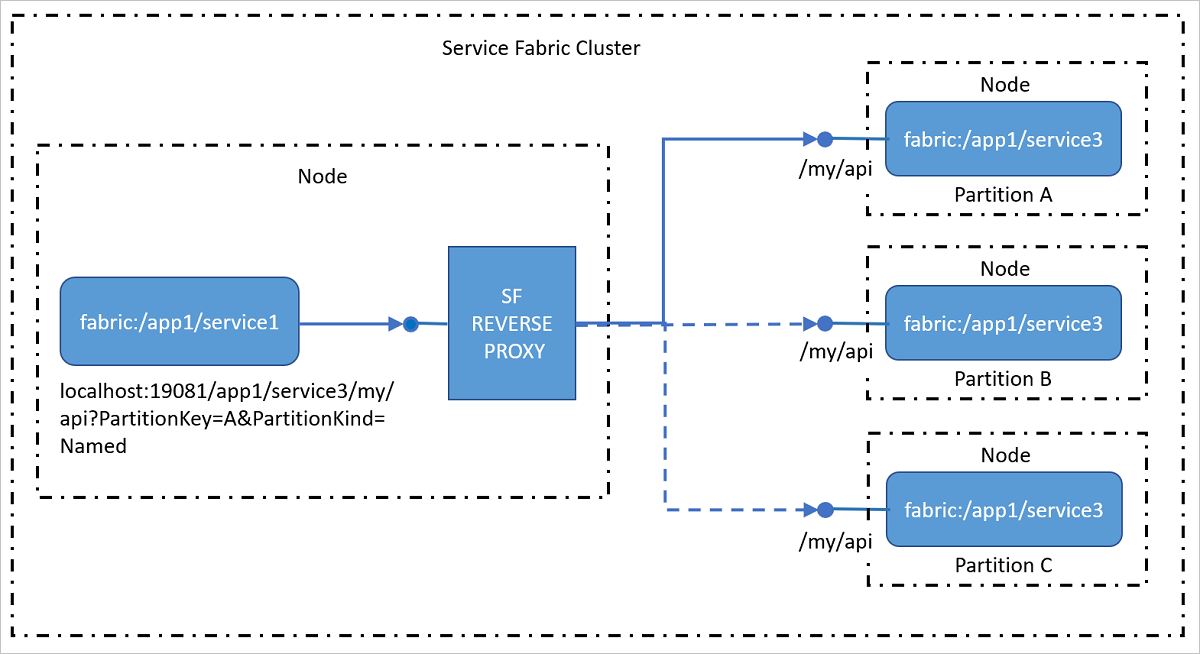
Reverse proxy is a service that runs on every node and handles endpoint resolution, automatic retry, and other connection failures on behalf of client services. Reverse proxy can be configured to apply various policies as it handles requests from client services. Using a reverse proxy allows the client service to use any client-side HTTP communication libraries and does not require special resolution and retry logic in the service.
Reverse proxy exposes one or more endpoints on local node for client services to use for sending requests to other services.
Note
Supported Platforms
Reverse proxy in Service Fabric currently supports the following platforms
- Windows Cluster: Windows 8 and later or Windows Server 2012 and later
- Linux Cluster: Reverse Proxy is not currently available for Linux clusters
Reaching microservices from outside the cluster
The default external communication model for microservices is an opt-in model where each service cannot be accessed directly from external clients. Azure Load Balancer, which is a network boundary between microservices and external clients, performs network address translation and forwards external requests to internal IP:port endpoints. To make a microservice's endpoint directly accessible to external clients, you must first configure Load Balancer to forward traffic to each port that the service uses in the cluster. However, most microservices, especially stateful microservices, don't live on all nodes of the cluster. The microservices can move between nodes on failover. In such cases, Load Balancer cannot effectively determine the location of the target node of the replicas to which it should forward traffic.
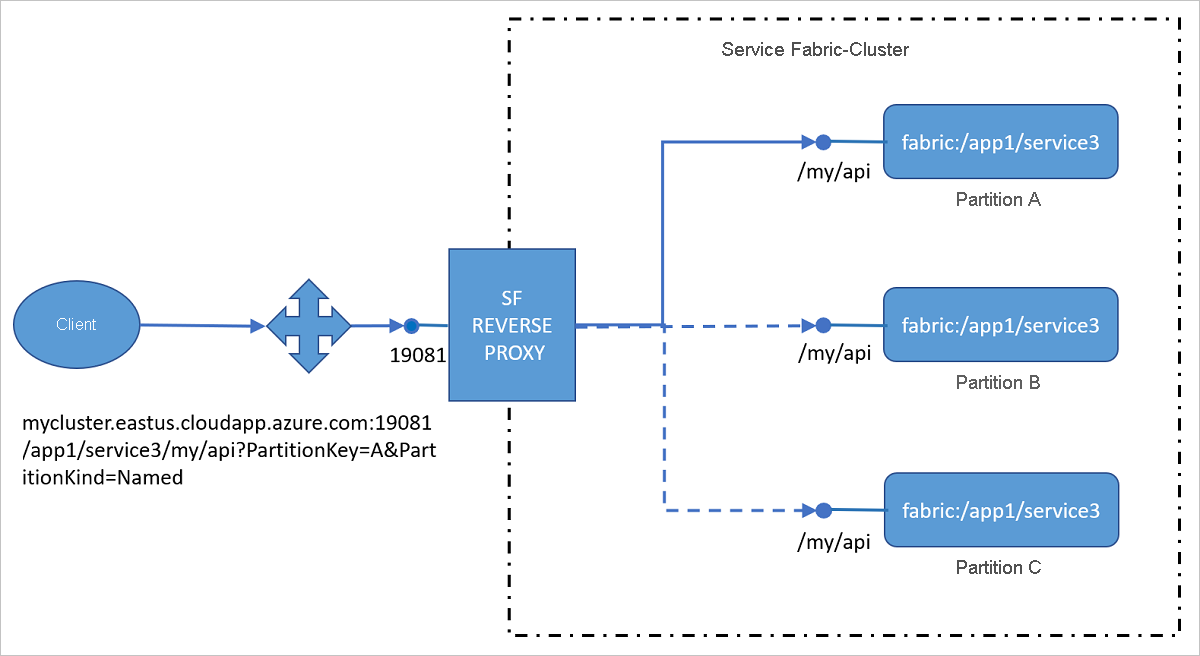
Reaching microservices via the reverse proxy from outside the cluster
Instead of configuring the port of an individual service in Load Balancer, you can configure just the port of the reverse proxy in Load Balancer. This configuration lets clients outside the cluster reach services inside the cluster by using the reverse proxy without additional configuration.
Warning
When you configure the reverse proxy's port in Load Balancer, all microservices in the cluster that expose an HTTP endpoint are addressable from outside the cluster. This means that microservices meant to be internal may be discoverable by a determined malicious user. This potentially presents serious vulnerabilities that can be exploited; for example:
- A malicious user may launch a denial of service attack by repeatedly calling an internal service that does not have a sufficiently hardened attack surface.
- A malicious user may deliver malformed packets to an internal service resulting in unintended behavior.
- A service meant to be internal may return private or sensitive information not intended to be exposed to services outside the cluster, thus exposing this sensitive information to a malicious user.
Make sure you fully understand and mitigate the potential security ramifications for your cluster and the apps running on it, before you make the reverse proxy port public.
URI format for addressing services by using the reverse proxy
The reverse proxy uses a specific uniform resource identifier (URI) format to identify the service partition to which the incoming request should be forwarded:
http(s)://<Cluster FQDN | internal IP>:Port/<ServiceInstanceName>/<Suffix path>?PartitionKey=<key>&PartitionKind=<partitionkind>&ListenerName=<listenerName>&TargetReplicaSelector=<targetReplicaSelector>&Timeout=<timeout_in_seconds>
http(s): The reverse proxy can be configured to accept HTTP or HTTPS traffic. For HTTPS forwarding, refer to Connect to a secure service with the reverse proxy once you have reverse proxy setup to listen on HTTPS.
Cluster fully qualified domain name (FQDN) | internal IP: For external clients, you can configure the reverse proxy so that it is reachable through the cluster domain, such as mycluster.eastus.cloudapp.azure.com. By default, the reverse proxy runs on every node. For internal traffic, the reverse proxy can be reached on localhost or on any internal node IP, such as 10.0.0.1.
Port: This is the port, such as 19081, that has been specified for the reverse proxy.
ServiceInstanceName: This is the fully-qualified name of the deployed service instance that you are trying to reach without the "fabric:/" scheme. For example, to reach the fabric:/myapp/myservice/ service, you would use myapp/myservice.
The service instance name is case-sensitive. Using a different casing for the service instance name in the URL causes the requests to fail with 404 (Not Found).
Suffix path: This is the actual URL path, such as myapi/values/add/3, for the service that you want to connect to.
PartitionKey: For a partitioned service, this is the computed partition key of the partition that you want to reach. Note that this is not the partition ID GUID. This parameter is not required for services that use the singleton partition scheme.
PartitionKind: This is the service partition scheme. This can be 'Int64Range' or 'Named'. This parameter is not required for services that use the singleton partition scheme.
ListenerName The endpoints from the service are of the form {"Endpoints":{"Listener1":"Endpoint1","Listener2":"Endpoint2" ...}}. When the service exposes multiple endpoints, this identifies the endpoint that the client request should be forwarded to. This can be omitted if the service has only one listener.
TargetReplicaSelector This specifies how the target replica or instance should be selected.
- When the target service is stateful, the TargetReplicaSelector can be one of the following: 'PrimaryReplica', 'RandomSecondaryReplica', or 'RandomReplica'. When this parameter is not specified, the default is 'PrimaryReplica'.
- When the target service is stateless, reverse proxy picks a random instance of the service partition to forward the request to.
Timeout: This specifies the timeout for the HTTP request created by the reverse proxy to the service on behalf of the client request. The default value is 120 seconds. This is an optional parameter.
Example usage
As an example, let's take the fabric:/MyApp/MyService service that opens an HTTP listener on the following URL:
http://10.0.0.5:10592/3f0d39ad-924b-4233-b4a7-02617c6308a6-130834621071472715/
Following are the resources for the service:
/index.html/api/users/<userId>
If the service uses the singleton partitioning scheme, the PartitionKey and PartitionKind query string parameters are not required, and the service can be reached by using the gateway as:
- Externally:
http://mycluster.eastus.cloudapp.azure.com:19081/MyApp/MyService - Internally:
http://localhost:19081/MyApp/MyService
If the service uses the Uniform Int64 partitioning scheme, the PartitionKey and PartitionKind query string parameters must be used to reach a partition of the service:
- Externally:
http://mycluster.eastus.cloudapp.azure.com:19081/MyApp/MyService?PartitionKey=3&PartitionKind=Int64Range - Internally:
http://localhost:19081/MyApp/MyService?PartitionKey=3&PartitionKind=Int64Range
To reach the resources that the service exposes, simply place the resource path after the service name in the URL:
- Externally:
http://mycluster.eastus.cloudapp.azure.com:19081/MyApp/MyService/index.html?PartitionKey=3&PartitionKind=Int64Range - Internally:
http://localhost:19081/MyApp/MyService/api/users/6?PartitionKey=3&PartitionKind=Int64Range
The gateway will then forward these requests to the service's URL:
http://10.0.0.5:10592/3f0d39ad-924b-4233-b4a7-02617c6308a6-130834621071472715/index.htmlhttp://10.0.0.5:10592/3f0d39ad-924b-4233-b4a7-02617c6308a6-130834621071472715/api/users/6
Special handling for port-sharing services
The Service Fabric reverse proxy attempts to resolve a service address again and retry the request when a service cannot be reached. Generally, when a service cannot be reached, the service instance or replica has moved to a different node as part of its normal lifecycle. When this happens, the reverse proxy might receive a network connection error indicating that an endpoint is no longer open on the originally resolved address.
However, replicas or service instances can share a host process and might also share a port when hosted by an http.sys-based web server, including:
In this situation, it is likely that the web server is available in the host process and responding to requests, but the resolved service instance or replica is no longer available on the host. In this case, the gateway will receive an HTTP 404 response from the web server. Thus, an HTTP 404 response can have two distinct meanings:
- Case #1: The service address is correct, but the resource that the user requested does not exist.
- Case #2: The service address is incorrect, and the resource that the user requested might exist on a different node.
The first case is a normal HTTP 404, which is considered a user error. However, in the second case, the user has requested a resource that does exist. The reverse proxy was unable to locate it because the service itself has moved. The reverse proxy needs to resolve the address again and retry the request.
The reverse proxy thus needs a way to distinguish between these two cases. To make that distinction, a hint from the server is required.
By default, the reverse proxy assumes case #2 and attempts to resolve and issue the request again.
To indicate case #1 to the reverse proxy, the service should return the following HTTP response header:
X-ServiceFabric : ResourceNotFound
This HTTP response header indicates a normal HTTP 404 situation in which the requested resource does not exist, and the reverse proxy will not attempt to resolve the service address again.
Special handling for services running in containers
For services running inside containers, you can use the environment variable, Fabric_NodeIPOrFQDN to construct the reverse proxy URL as in the following code:
var fqdn = Environment.GetEnvironmentVariable("Fabric_NodeIPOrFQDN");
var serviceUrl = $"http://{fqdn}:19081/DockerSFApp/UserApiContainer";
For the local cluster, Fabric_NodeIPOrFQDN is set to "localhost" by default. Start the local cluster with the -UseMachineName parameter to make sure containers can reach reverse proxy running on the node. For more information, see Configure your developer environment to debug containers.
Service Fabric services that run within Docker Compose containers require a special docker-compose.yml Ports section http: or https: configuration. For more information, see Docker Compose deployment support in Azure Service Fabric.
Next steps
- Set up and configure reverse proxy on a cluster.
- Set up forwarding to secure HTTP service with the reverse proxy
- Diagnose reverse proxy events
- See an example of HTTP communication between services in a sample project on GitHub.
- Remote procedure calls with Reliable Services remoting
- Web API that uses OWIN in Reliable Services
- WCF communication by using Reliable Services