Dimensionen für Azure Stream Analytics-Metriken
Azure Stream Analytics bietet einen serverlosen, verteilten Streamingverarbeitungsdienst. Aufträge können auf einem oder mehreren verteilten Streamingknoten ausgeführt werden, die der Dienst automatisch verwaltet. Die Eingabedaten werden partitioniert und verschiedenen Streamingknoten zur Verarbeitung zugewiesen.
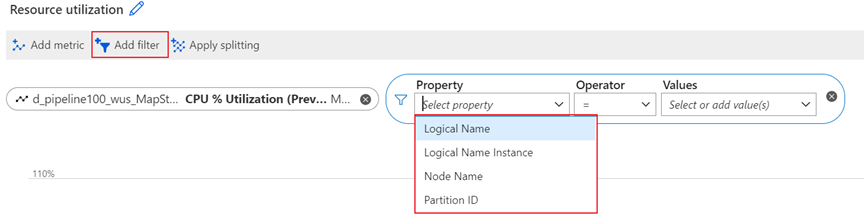
Stream Analytics verfügt über viele Metriken, um die Integrität eines Auftrags zu überwachen. Zur Problembehandlung von Leistungsproblemen mit Ihrem Auftrag können Sie Metriken mithilfe der folgenden Dimensionen aufteilen und filtern.
| Dimension | Definition |
|---|---|
| Logischer Name | Der Eingabe- oder Ausgabename für einen Stream Analytics-Auftrag. |
| Partitions-ID | Die ID der Eingabedatenpartition aus einer Eingabequelle. Wenn z. B. die Eingabequelle ein Event Hub ist, ist die Partitions-ID die Partitions-ID des Event Hubs. Bei hochgradig parallelen Aufträgen ist die Partitions-ID in der Ausgabe dieselbe wie in der Eingabe. |
| Node Name (Knotenname) | Der Bezeichner eines Streamingknotens, der bereitgestellt wird, wenn Ihr Auftrag ausgeführt wird. Ein Streamingknoten stellt die Menge an Compute- und Arbeitsspeicherressourcen dar, die Ihrem Auftrag zugewiesen sind. |

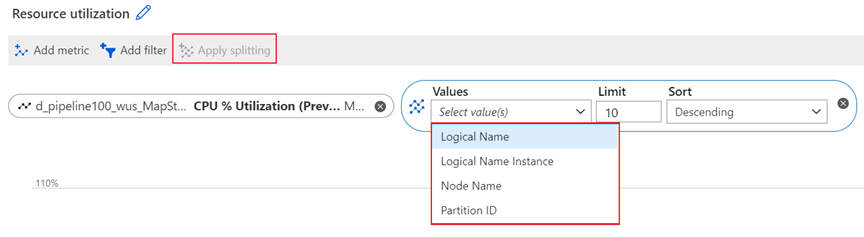
Dimension „Logischer Name“
Logischer Name ist der Eingabe- oder Ausgabename für einen Stream Analytics-Auftrag. Nehmen wir z. B. an, dass ein Stream Analytics-Auftrag vier Eingaben und fünf Ausgaben hat. Sie sehen die vier einzelnen logischen Eingaben und fünf einzelnen logischen Ausgaben, wenn Sie eingabe- und ausgabebezogene Metriken nach dieser Dimension aufteilen.


Die Dimension Logischer Name ist für die Filterung und Aufteilung der folgenden Metriken verfügbar:
- Eingabeereignisse im Rückstand
- Konvertierungsfehler
- Frühe Eingabeereignisse
- Eingabefehler bei Deserialisierung
- Eingabeereignisbytes
- Eingabeereignisse
- Empfangene Eingabequelle
- Ereignisse bei verspäteter Eingabe
- Ereignisse mit falscher Reihenfolge
- Ausgabeereignisse
- Wasserzeichenverzögerung
Dimension „Knotenname“
Ein Streamingknoten stellt eine Reihe von Computeressourcen dar, die verwendet werden, um Ihre Eingabedaten zu verarbeiten. Je sechs Streamingeinheiten (Streaming Unit, SU) entsprechen einem Knoten, den der Dienst automatisch in Ihrem Namen verwaltet. Weitere Informationen über die Beziehung zwischen Streamingeinheiten und Streamingknoten finden Sie unter Verstehen und Anpassen von Streamingeinheiten.
Knotenname ist eine Dimension auf der Streamingknotenebene. Er kann Ihnen helfen, bestimmte Metriken bis auf die Streamingknotenebene aufzuschlüsseln. Sie können z. B. die Metrik CPU-Auslastung in Prozent nach Streamingknotenebene aufteilen, um die CPU-Auslastung eines einzelnen Streamingknotens zu überprüfen.

Die Dimension Knotenname ist für die Filterung und Aufteilung der folgenden Metriken verfügbar:
- Eingabeereignisse im Rückstand
- CPU-Auslastung in Prozent (Vorschau)
- Eingabeereignisse
- Ausgabeereignisse
- SU (Speicher) % Auslastung
- Wasserzeichenverzögerung
Dimension „Partitions-ID“
Wenn Streamingdaten zur Verarbeitung im Azure Stream Analytics-Dienst erfasst werden, erfolgt die Verteilung der Eingabedaten auf die Streamingknoten entsprechend den Partitionen in der Eingabequelle. Die Dimension Partitions-ID ist die ID der Partition der Eingabedaten aus der Eingabequelle.
Wenn z. B. die Eingabequelle ein Event Hub ist, ist die Partitions-ID die Partitions-ID des Event Hubs. Die Partitions-ID in der Eingabe ist die gleiche wie in der Ausgabe.

Die Dimension Partitions-ID ist für die Filterung und Aufteilung der folgenden Metriken verfügbar:
- Eingabeereignisse im Rückstand
- Konvertierungsfehler
- Frühe Eingabeereignisse
- Eingabefehler bei Deserialisierung
- Eingabeereignisbytes
- Eingabeereignisse
- Empfangene Eingabequelle
- Ereignisse bei verspäteter Eingabe
- Ausgabeereignisse
- Wasserzeichenverzögerung
Nächste Schritte
- Azure Stream Analytics-Auftragsmetriken
- Analysieren der Azure Stream Analytics-Auftragsleistung mithilfe von Metriken und Dimensionen
- Debuggen mit dem physischen Auftragsdiagramm (Vorschau) im Azure-Portal
- Debuggen mit dem logischen Auftragsdiagramm (Vorschau) im Azure-Portal
- Überwachen eines Stream Analytics-Auftrags mit dem Azure-Portal
- Verstehen und Anpassen von Streamingeinheiten