Diagnostizieren und Lösen von Spinlockkonflikten in SQL Server
Dieser Artikel enthält ausführliche Informationen zum Identifizieren und Lösen von Problemen im Zusammenhang mit Spinlockkonflikten in SQL Server-Anwendungen auf Systemen mit hoher Parallelität.
Hinweis
Die hier dokumentierten Empfehlungen und bewährten Methoden basieren auf praktischen Erfahrungen bei der Entwicklung und Bereitstellung von realen OLTP-Systemen. Ursprünglich wurde dieser Artikel vom SQLCAT (Microsoft SQL Server Customer Advisory Team, Microsoft SQL Server-Kundenberatungsteam) veröffentlicht.
Hintergrund
Früher verwendeten Windows Server-Standardcomputer nur einen oder zwei Mikroprozessorchips/CPU-Chips, und CPUs verfügten über nur einen Prozessor oder „Kern“. Die Steigerung der Computerverarbeitungskapazität wurde durch den Einsatz schnellerer CPUs erreicht, was weitgehend durch Weiterentwicklungen in der Transistordichte ermöglicht wurde. Seit der Entwicklung der ersten universellen Ein-Chip-CPU im Jahr 1971 hat sich die Transistordichte, sprich die Anzahl von Transistoren, die in einem integrierten Schaltkreis enthalten sein können, dem Mooreschen Gesetz entsprechend kontinuierlich alle zwei Jahre verdoppelt. In den letzten Jahren wurde der traditionelle Ansatz des Erhöhens der Verarbeitungskapazität von Computern durch schnellere CPUs um den Bau von Computern mit mehreren CPUs erweitert. Ab diesem Schreiben bietet die Intel Nehalem CPU-Architektur platz für bis zu acht Kerne pro CPU, die bei Verwendung in einem acht Socketsystem dann auf 128 logische Prozessoren durch gleichzeitige Multithreading-Technologie (SMT) verdoppelt werden können. Auf Intel CPUs wird SMT als Hyperthreading bezeichnet. Mit dem Steigen der Anzahl von logischen Prozessoren auf x86-kompatiblen Computern nehmen Probleme im Zusammenhang mit Parallelität zu, da die logischen Prozessoren um die Ressourcen konkurrieren. In diesem Leitfaden wird beschrieben, wie Sie bestimmte Probleme im Zusammenhang mit Ressourcenkonflikten identifizieren und lösen, die auftreten, wenn SQL Server-Anwendungen mit einigen Arbeitsauslastungen auf Systemen mit hoher Parallelität ausgeführt werden.
In diesem Abschnitt analysieren wir die vom SQLCAT-Team gelernten Erkenntnisse aus der Diagnose und Behebung von Spinlock-Inhaltsproblemen. Spinlockkonflikte sind eine Art von Parallelitätsproblem, das bei realen Arbeitsauslastungen von Kunden in umfangreichen Systemen auftritt.
Symptome und Gründe für Spinlockkonflikte
In diesem Abschnitt wird beschrieben, wie Sie Probleme mit Spinlockkonflikten diagnostizieren, die sich negativ auf die Leistung von OLTP-Anwendungen in SQL Server auswirken. Die Diagnose und Problembehandlung im Zusammenhang mit Spinlocks sollte als Thema für Fortgeschrittene angesehen werden, da Wissen über Debugtools und Windows-Komponenten erforderlich ist.
Spinlocks sind einfache primitive Synchronisierungstypen, die zum Schutz des Zugriffs auf Datenstrukturen verwendet werden. Spinlocks sind nicht für SQL Server eindeutig. Das Betriebssystem verwendet sie, wenn der Zugriff auf eine bestimmte Datenstruktur nur für kurze Zeit benötigt wird. Wenn ein Thread, der versucht, einen Spinlock zu erlangen, keinen Zugriff erhält, wird er nicht sofort angehalten, sondern in einer Schleife ausgeführt, wobei regelmäßig überprüft wird, ob die Ressource verfügbar ist. Nach einiger Zeit führt ein Thread, der auf ein Spinlock wartet, zur Folge, bevor er die Ressource abrufen kann. Durch dieses Anhalten können andere Threads auf derselben CPU ausgeführt werden. Dieses Verhalten wird als Backoff bezeichnet und weiter unten in diesem Artikel ausführlicher erläutert.
SQL Server verwendet Spinlocks zum Schutz des Zugriffs auf einige interne Datenstrukturen. Spinlocks werden in der Engine verwendet, um den Zugriff auf bestimmte Datenstrukturen ähnlich wie bei Latches zu serialisieren. Der Standard Unterschied zwischen einem Riegel und einem Spinlock ist die Tatsache, dass Spinlocks dreht (eine Schleife ausführen) für einen Bestimmten Zeitraum, der die Verfügbarkeit einer Datenstruktur überprüft, während ein Thread versucht, zugriff auf eine Struktur zu erhalten, die durch einen Riegel geschützt ist, sofort zur Folge hat, wenn die Ressource nicht verfügbar ist. Das Anhalten erfordert einen Kontextwechsel des Threads nach außerhalb der CPU, damit ein anderer Thread ausgeführt werden kann. Dies ist ein relativ teurer Vorgang und für Ressourcen, die für eine kurze Dauer gehalten werden, ist es insgesamt effizienter, damit ein Thread in einer Schleife regelmäßig nach verfügbarkeit der Ressource ausgeführt werden kann.
Interne Anpassungen an den in SQL Server 2022 (16.x) eingeführten Datenbank-Engine machen Spinlocks effizienter.
Problembeschreibung
Bei jedem beschäftigt hohen Parallelitätssystem ist es normal, aktive Konflikte auf häufig aufgerufenen Strukturen zu sehen, die durch Spinlocks geschützt sind. Diese Nutzung wird erst dann als problematisch angesehen, wenn Konflikte einen erheblichen CPU-Mehraufwand verursachen. Spinlockstatistiken werden von der sys.dm_os_spinlock_stats dynamischen Verwaltungsansicht (Dynamic Management View, DMV) in SQL Server verfügbar gemacht. Diese Abfrage gibt z. B. die folgende Ausgabe zurück:
Hinweis
Weitere Informationen zur Interpretation der von dieser DMV zurückgegebenen Informationen finden Sie weiter unten in diesem Artikel.
SELECT * FROM sys.dm_os_spinlock_stats
ORDER BY spins DESC;
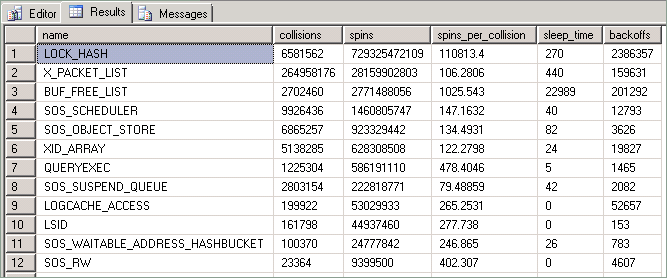
Die von dieser Abfrage zur Verfügung gestellten Statistiken werden wie folgt beschrieben:
| Column | Beschreibung |
|---|---|
| Collisions (Kollisionen) | Dieser Wert erhöht sich immer dann, wenn der Zugriff eines Threads auf eine durch einen Spinlock geschützte Ressource blockiert wird. |
| Spins (Drehungen) | Dieser Wert erhöht sich immer dann, wenn ein Thread eine Schleife ausführt, während er darauf wartet, dass der Spinlock verfügbar wird. Dies ist ein Maß für die Arbeitsmenge, die ein Thread ausführt, während er versucht, eine Ressource zu erwerben. |
| Spins_per_collision (Drehungen_pro_Kollision) | Das Verhältnis von Drehungen zu Kollisionen |
| Sleep time (Ruhezeit) | Der Wert in dieser Spalte hängt mit Backoff-Ereignissen zusammen. Für die in diesem Artikel beschriebenen Methoden ist er jedoch nicht relevant. |
| Backoffs | Ein Backoff tritt auf, wenn ein sich „drehender“ Thread, der versucht, auf eine gesperrte Ressource zuzugreifen, festgestellt hat, dass er das Ausführen anderer Threads auf derselben CPU ermöglichen muss. |
Für die Erläuterungen in diesem Artikel ist die Anzahl von Kollisionen, Drehungen und Backoff-Ereignissen innerhalb eines bestimmten Zeitraums bei starker Auslastung des Systems besonders interessant. Wenn ein Thread versucht, auf eine durch einen Spinlock geschützte Ressource zuzugreifen, tritt eine Kollision auf. Wenn eine Kollision auftritt, erhöht sich die Anzahl von Kollisionen, und der Thread beginnt, sich in einer Schleife zu drehen und regelmäßig zu überprüfen, ob die Ressource verfügbar ist. Bei jeder Drehung des Threads (Schleife) erhöht sich die Anzahl von Drehungen.
Drehungen pro Kollision sind ein Maß für die Menge der Drehungen, die auftreten, während ein Spinlock von einem Thread gehalten wird, und gibt an, wie viele Drehungen auftreten, während Threads das Spinlock halten. So bedeutet z. B. kleine Drehungen pro Kollision und hohe Kollisionsanzahl, dass es eine kleine Anzahl von Drehungen gibt, die unter dem Spinlock auftreten, und es gibt viele Threads, die dafür kämpfen. Eine hohe Anzahl von Drehungen bedeutet, dass der Thread sich im Spinlockcode relativ lang dreht (d. h., im Code wird eine hohe Anzahl von Einträgen in einem Hashbucket durchlaufen). Wenn die Anzahl von Konflikten steigt (und somit die Anzahl von Kollisionen), steigt auch die Anzahl von Drehungen.
Backoffs können Sie sich so ähnlich wie Drehungen vorstellen. Um übermäßige CPU-Abfälle zu vermeiden, drehen Sich Spinlocks nicht unbegrenzt weiter, bis sie auf eine gehaltene Ressource zugreifen können. Um sicherzustellen, dass ein Spinlock nicht übermäßig CPU-Ressourcen verwendet, spinlocks backoffs oder beenden Sie das Drehen und "Schlafen". Backoffs werden unabhängig davon durchgeführt, ob die Zielressource jemals abgerufen wird. Dies geschieht, um die Planung anderer Threads auf der CPU zu ermöglichen, in der Hoffnung, dass so mehr produktives Arbeiten möglich ist. Das Standardverhalten für die Engine ist, dass sich der Thread erst für einen immer gleich langen Zeitraum dreht und dann ein Backoff durchgeführt wird. Der Versuch, einen Spinlock zu erlangen, erfordert, dass der Zustand der Cacheparallelität beibehalten wird. Im Vergleich zum Drehen ist dies ein relativ CPU-intensiver Vorgang. Daher werden Versuche, einen Spinlock zu erlangen, möglichst selten ausgeführt und nicht jedes Mal, wenn ein Thread sich dreht. In SQL Server wurden bestimmte Spinlocktypen (z. B. LOCK_HASH) verbessert, indem ein exponentielles Intervall zwischen versuchen, das Spinlock (bis zu einem bestimmten Grenzwert) zu erwerben, was häufig die Auswirkungen auf die CPU-Leistung reduziert.
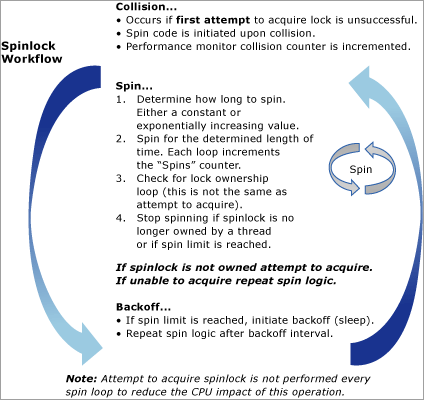
Bei dem folgenden Diagramm handelt es sich um eine konzeptionelle Darstellung des Spinlockalgorithmus:
Typische Szenarien
Spinlockkonflikte können aus vielen verschiedenen Gründen auftreten, die möglicherweise nichts mit Datenbank-Entwurfsentscheidungen zu tun haben. Da spinlocks Gate-Zugriff auf interne Datenstrukturen nicht auf die gleiche Weise manifestiert ist wie Puffersperre, die direkt von Schemaentwurfsoptionen und Datenzugriffsmustern beeinflusst wird.
Das Symptom, das hauptsächlich mit Spinlockkonflikten assoziiert wird, ist eine hohe CPU-Auslastung aufgrund der hohen Anzahl von Drehungen und der vielen Threads, die versuchen, denselben Spinlock zu erlangen. Allgemein wurde dies auf Systemen mit >= 24 CPU-Kernen und am häufigsten auf solchen mit >= 32 CPU-Kernen beobachtet. Wie bereits erwähnt, ist ein gewisses Maß an Konsenz auf Spinlocks für hohe Parallelitäts-OLTP-Systeme mit erheblicher Belastung normal, und es gibt oft eine große Anzahl von Spins (Milliarden/Billionen), die von der sys.dm_os_spinlock_stats DMV auf Systemen gemeldet wurden, die seit langer Zeit laufen. Die Beobachtung einer hohen Anzahl von Drehungen für einen bestimmten Spinlocktyp reicht nicht aus, um festzustellen, dass negative Auswirkungen auf die Arbeitsauslastungsleistung auftreten.
Eine Kombination aus mehreren der folgenden Symptome kann auf Spinlockkonflikte hindeuten:
Für einen bestimmten Spinlocktyp ist eine hohe Anzahl von Drehungen und Backoffs zu beobachten.
Das System verfügt über eine hohe CPU-Auslastung oder CPU-Auslastungsspitzen. In schweren CPU-Szenarien sehen Sie, dass das hohe Signal auf SOS_SCHEDULER_YIELD wartet (vom DMV
sys.dm_os_wait_statsgemeldet).Das System verfügt über eine hohe Parallelität.
Die CPU-Auslastung und die Anzahl von Drehungen steigen nicht proportional zum Durchsatz.
Wichtig
Auch wenn jede der vorherigen Bedingungen erfüllt ist, ist es immer noch möglich, dass die Ursache für hohen CPU-Verbrauch an anderer Stelle liegt. Tatsächlich ist es so, dass eine erhöhte CPU-Auslastung in den allermeisten Fällen auf andere Gründe als Spinlockkonflikte zurückzuführen ist. Häufigere Gründe für eine erhöhte CPU-Auslastung sind z. B. die folgenden:
Abfragen, die im Laufe der Zeit aufgrund der steigenden Menge von zugrunde liegenden Daten ressourcenintensiver werden, was dazu führt, dass zusätzliche logische Lesevorgänge für speicherresidente Daten durchgeführt werden müssen
Änderungen in Abfrageplänen, die eine suboptimale Ausführung zur Folge haben
Wenn alle diese Bedingungen zutreffen, führen Sie weitere Untersuchungen zu möglichen Problemen im Zusammenhang mit Spinlockkonflikten durch.
Ein häufiges und leicht zu diagnostizierendes Phänomen ist eine erhebliche Abweichung zwischen Durchsatz und CPU-Auslastung. Bei vielen OLTP-Arbeitsauslastungen besteht eine Beziehung zwischen (Durchsatz/Anzahl von Benutzern im System) und der CPU-Auslastung. Eine zu beobachtende hohe Anzahl von Drehungen in Verbindung mit einer erheblichen Abweichung zwischen CPU-Auslastung und Durchsatz kann ein Hinweis auf Spinlockkonflikte sein, die zu CPU-Mehraufwand führen. Ein wichtiger Punkt hier ist, dass es auch üblich ist, diese Art von Divergenz auf Systemen zu sehen, wenn bestimmte Abfragen im Laufe der Zeit teurer werden. Beispielsweise führen Abfragen, die für Datasets ausgeführt werden, die im Laufe der Zeit immer mehr logische Lesevorgänge ausführen, möglicherweise zu ähnlichen Symptomen.
Es ist wichtig, andere häufigere Ursachen einer hohen CPU auszuschließen, wenn diese Arten von Problemen behoben werden.
Beispiele
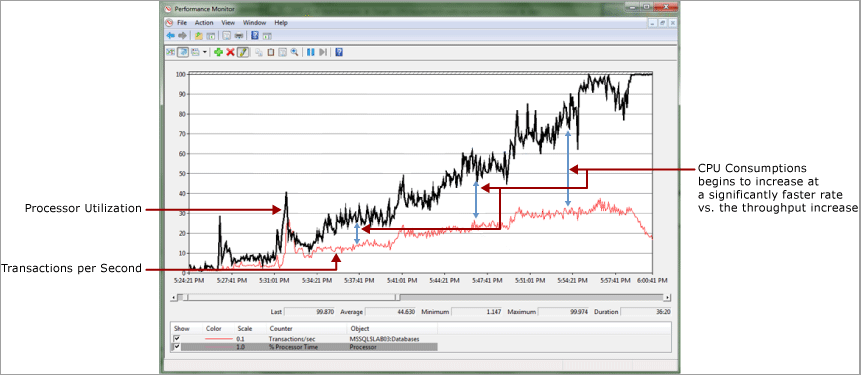
Im folgenden Beispiel gibt es eine nahezu lineare Beziehung zwischen CPU-Verbrauch und Durchsatz, wie durch Transaktionen pro Sekunde gemessen. Es ist normal, hier einige Divergenzen zu sehen, da der Aufwand entsteht, da jeder Arbeitsaufwand zunimmt. Wie hier gezeigt, wird diese Abweichung erheblich. Es gibt auch einen vorwegigen Rückgang des Durchsatzes, sobald der CPU-Verbrauch 100 % erreicht.
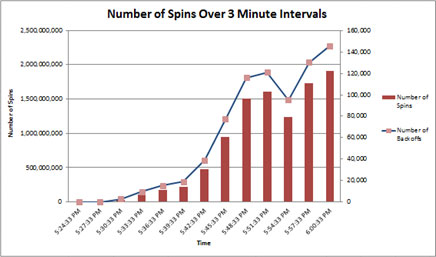
Beim Messen der Anzahl von Drehungen innerhalb von 3-Minuten-Intervallen ist eher ein exponentieller als ein linearer Anstieg zu beobachten, was zeigt, dass Spinlockkonflikte problematisch sein können.
Wie bereits erwähnt, werden Spinlocks meist auf stark ausgelasteten Systemen mit hoher Parallelität verwendet.
Szenarios, in denen dieses Problem häufig auftritt, sind z. B. die folgenden:
Es treten Probleme bei der Namensauflösung auf, die durch einen Fehler beim vollständigen Qualifizieren von Namen von Objekten verursacht wurden. Weitere Informationen finden Sie unter Problembehandlung bei Blockierung aufgrund von Kompilierungssperren. Dieses spezifische Problem wird in diesem Artikel ausführlicher beschrieben.
Im Sperren-Manager treten Konflikte für Sperrhashbuckets für Arbeitsauslastungen auf, die häufig auf dieselbe Sperre zugreifen (z. B. eine gemeinsame Sperre für eine häufig gelesene Zeile). Diese Art von Konflikt äußert sich in einem LOCK_HASH-Spinlock. In einem bestimmten Fall haben wir festgestellt, dass dieses Problem auf falsch modellierte Zugriffsmuster in einer Testumgebung zurückzuführen war. In dieser Umgebung griffen aufgrund von falsch konfigurierten Testparametern kontinuierlich mehr Threads als erwartet auf ein und dieselbe Zeile zu.
Hohe Rate von DTC-Transaktionen, wenn zwischen den MSDTC-Transaktionskoordinatoren eine hohe Latenz besteht. Dieses spezifische Problem ist im SQLCAT-Blogeintrag Auflösen von DTC-bezogenen Wartevorgängen und Optimieren der Skalierbarkeit von DTC ausführlich dokumentiert.
Diagnose von Spinlock-Inhalten
Dieser Abschnitt enthält Informationen zur Diagnose von Spinlockkonflikten in SQL Server. Die primären Tools für die Diagnose von Spinlockkonflikten sind:
| Tool | Verwendung |
|---|---|
| Systemmonitor | Suchen Sie nach Bedingungen mit hoher CPU-Auslastung oder Abweichungen zwischen Durchsatz und CPU-Auslastung. |
sys.dm_os_spinlock stats DMV** |
Suchen Sie nach einer hohen Anzahl von Drehungen und Backoff-Ereignissen im Zeitverlauf. |
| Erweiterte Ereignisse von SQL Server | Dieses Tool wird verwendet, um Aufruflisten für Spinlocks mit einer hohen Anzahl von Drehungen nachzuverfolgen. |
| Arbeitsspeicherabbilder | In einigen Fällen werden Arbeitsspeicherabbilder des SQL Server-Prozesses und die Windows-Debugtools verwendet. Im Allgemeinen wird eine solche Analyse durchgeführt, wenn die Microsoft SQL Server-Supportteams eingebunden werden. |
Der allgemeine technische Prozess für die Diagnose von Spinlockkonflikten in SQL Server sieht wie folgt aus:
Schritt 1: Ermitteln Sie, ob es einen Streit gibt, der sich möglicherweise auf Spinlock bezieht.
Schritt 2: Erfassen von Statistiken aus
sys.dm_ os_spinlock_stats , um den Spinlocktyp zu finden, der den größten Inhalt aufweist.Schritt 3: Abrufen von Debugsymbolen für sqlservr.exe (sqlservr.pdb) und Platzieren Sie die Symbole im selben Verzeichnis wie die SQL Server-Dienst-EXE-Datei (sqlservr.exe) für die Instanz von SQL Server.\ Um die Aufrufstapel für die Back off-Ereignisse anzuzeigen, müssen Sie Symbole für die bestimmte Version von SQL Server haben, die Sie ausführen. Symbole für SQL Server werden auf dem Microsoft-Symbolserver bereitgestellt. Weitere Informationen zum Herunterladen von Symbolen über den Microsoft-Symbolserver finden Sie unter Debuggen mit Symbolen.
Schritt 4: Verwenden Sie erweiterte SQL Server-Ereignisse, um die Back off-Ereignisse für die interessanten Spinlocktypen zu verfolgen.
Erweiterte Ereignisse bieten die Möglichkeit, das "Backoff"-Ereignis nachzuverfolgen und den Aufrufstapel für diese Vorgänge zu erfassen, die am häufigsten versuchen, das Spinlock abzurufen. Durch die Analyse des Aufrufstapels ist es möglich, zu bestimmen, welche Art des Vorgangs zu einem Streit für ein bestimmtes Spinlock beiträgt.
Exemplarische Vorgehensweise für die Diagnose
Im Rahmen der folgenden exemplarischen Vorgehensweise wird gezeigt, wie Sie die Tools und Methoden verwenden, um ein Problem mit Spinlockkonflikten in einem realen Szenario zu diagnostizieren. Sie basiert auf einem Kundenauftrag, bei dem ein Benchmarktest durchgeführt wurde, um ungefähr 6.500 gleichzeitige Benutzer auf einem Server mit 8 Sockeln, 64 physischen Kernen und 1 TB Arbeitsspeicher zu simulieren.
Problembeschreibung
Es wurden regelmäßige CPU-Auslastungsspitzen beobachtet, die zu einer CPU-Auslastung von fast 100 % führten. Darüber hinaus wurde eine Abweichung zwischen Durchsatz und CPU-Auslastung festgestellt, die zu diesem Problem führte. Zu dem Zeitpunkt, zu dem die große CPU-Spitze auftrat, trat bereits bei hoher CPU-Auslastung in bestimmten Abständen eine hohe Anzahl von Drehungen auf.
Dies war ein Extremfall, bei dem durch den Konflikt ein Spinlockkonvoi entstand. Ein Konvoi tritt auf, wenn Threads die Arbeitsauslastung nicht mehr weiter ausführen können, sondern stattdessen alle Verarbeitungsressourcen dafür verwenden, zu versuchen, auf die Sperre zuzugreifen. Das Systemmonitorprotokoll zeigt diese Abweichung zwischen dem Durchsatz im Transaktionsprotokoll und der CPU-Auslastung sowie schließlich die große CPU-Auslastungsspitze.
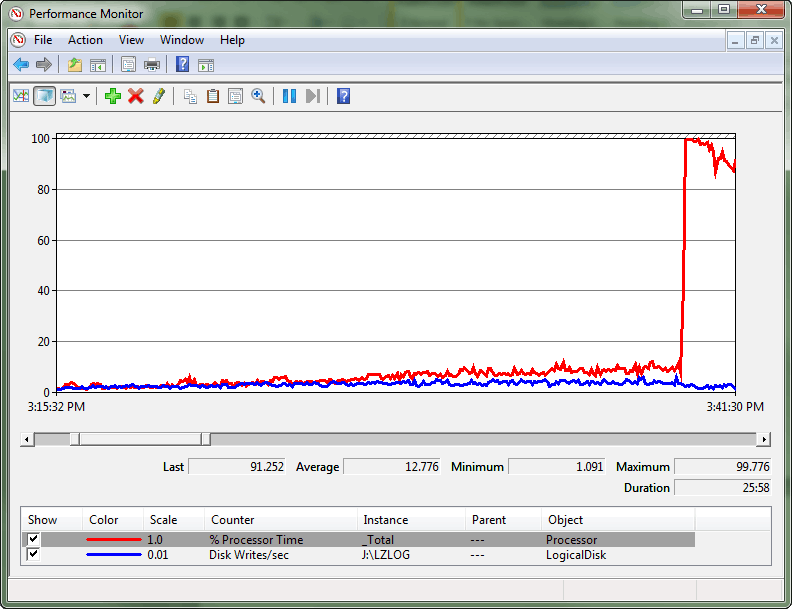
Nach der Abfrage sys.dm_os_spinlock_stats , um das Vorhandensein eines signifikanten Konflikts für SOS_CACHESTORE zu ermitteln, wurde ein Skript für erweiterte Ereignisse verwendet, um die Anzahl der Backoffereignisse für die interessanten Spinlocktypen zu messen.
| Name | Kollisionen | Drehungen | Drehungen pro Kollision | Backoffs |
|---|---|---|---|---|
SOS_CACHESTORE |
14.752.117 | 942.869.471.526 | 63.914 | 67.900.620 |
SOS_SUSPEND_QUEUE |
69.267.367 | 473.760.338.765 | 6\.840 | 2.167.281 |
LOCK_HASH |
5.765.761 | 260.885.816.584 | 45.247 | 3.739.208 |
MUTEX |
2.802.773 | 9.767.503.682 | 3.485 | 350.997 |
SOS_SCHEDULER |
1.207.007 | 3.692.845.572 | 3.060 | 109.746 |
Die einfachste Methode zur Quantifizierung der Auswirkungen der Drehungen besteht darin, die Anzahl der Backoffereignisse zu untersuchen, die über sys.dm_os_spinlock_stats das gleiche Intervall von 1 Minuten für die Spinlocktypen mit der höchsten Anzahl von Drehungen verfügbar gemacht werden. Diese Methode ist am besten geeignet, um erhebliche Konflikte zu erkennen, da sie anzeigt, wenn Threads die Drehungsobergrenze erreichen, während sie auf das Erlangen des Spinlocks warten. Das folgende Skript veranschaulicht eine komplexe Methode, bei der erweiterte Ereignisse verwendet werden, um verwandte Backoff-Ereignisse zu messen und die spezifischen Codepfade zu identifizieren, bei denen die Konflikte auftreten.
Weitere Informationen zu erweiterten Ereignissen von SQL Server finden Sie unter Übersicht über erweiterte Ereignisse.
Skript
/*
This script is provided "AS IS" with no warranties, and confers no rights.
This script will monitor for backoff events over a given period of time and
capture the code paths (callstacks) for those.
--Find the spinlock types
select map_value, map_key, name from sys.dm_xe_map_values
where name = 'spinlock_types'
order by map_value asc
--Example: Get the type value for any given spinlock type
select map_value, map_key, name from sys.dm_xe_map_values
where map_value IN ('SOS_CACHESTORE', 'LOCK_HASH', 'MUTEX')
Examples:
61LOCK_HASH
144 SOS_CACHESTORE
08MUTEX
*/
--create the even session that will capture the callstacks to a bucketizer
--more information is available in this reference: http://msdn.microsoft.com/en-us/library/bb630354.aspx
CREATE EVENT SESSION spin_lock_backoff ON SERVER
ADD EVENT sqlos.spinlock_backoff (
ACTION(package0.callstack) WHERE type = 61 --LOCK_HASH
OR TYPE = 144 --SOS_CACHESTORE
OR TYPE = 8 --MUTEX
) ADD TARGET package0.asynchronous_bucketizer (
SET filtering_event_name = 'sqlos.spinlock_backoff',
source_type = 1,
source = 'package0.callstack'
)
WITH (
MAX_MEMORY = 50 MB,
MEMORY_PARTITION_MODE = PER_NODE
);
--Ensure the session was created
SELECT * FROM sys.dm_xe_sessions
WHERE name = 'spin_lock_backoff';
--Run this section to measure the contention
ALTER EVENT SESSION spin_lock_backoff ON SERVER STATE = START;
--wait to measure the number of backoffs over a 1 minute period
WAITFOR DELAY '00:01:00';
--To view the data
--1. Ensure the sqlservr.pdb is in the same directory as the sqlservr.exe
--2. Enable this trace flag to turn on symbol resolution
DBCC TRACEON (3656, -1);
--Get the callstacks from the bucketize target
SELECT event_session_address,
target_name,
execution_count,
cast(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spin_lock_backoff';
--clean up the session
ALTER EVENT SESSION spin_lock_backoff ON SERVER STATE = STOP;
DROP EVENT SESSION spin_lock_backoff ON SERVER;
Wenn Sie die Ausgabe analysieren, sehen Sie die Aufruflisten für die häufigsten Codepfade für die SOS_CACHESTORE-Drehungen. Während die CPU-Auslastung hoch war, wurde das Skript mehrmals ausgeführt, um die Konsistenz der zurückgegeben Aufruflisten zu überprüfen. Die Aufrufstapel mit der höchsten Anzahl von Steckplätzen werden zwischen den beiden Ausgaben (35.668 und 8.506) gemeinsam verwendet. Diese Aufruflisten verfügen über eine „Slotanzahl“, die zwei Größenordnungen größer als der Eintrag mit der nächstniedrigeren Anzahl ist. Dies ist ein Hinweis auf einen relevanten Codepfad.
Hinweis
Es ist nicht ungewöhnlich, dass Aufrufstapel vom vorherigen Skript zurückgegeben werden. Als das Skript 1 Minute lang ausgeführt wurde, haben wir festgestellt, dass Aufrufstapel mit einer Slotanzahl von > 1000 problematisch waren, aber die Slotanzahl von > 10.000 war wahrscheinlicher problematisch, da es sich um eine höhere Slotanzahl handelt.
Hinweis
Die Formatierung der folgenden Ausgabe wurde zur besseren Lesbarkeit bereinigt.
Ausgabe 1
<BucketizerTarget truncated="0" buckets="256">
<Slot count="35668" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid
CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey
CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
NTGroupInfo::`vector deleting destructor'
</value>
</Slot>
<Slot count="752" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
</value>
</Slot>
Ausgabe 2
<BucketizerTarget truncated="0" buckets="256">
<Slot count="8506" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep+c7 [ @ 0+0x0 SpinlockBase::Backoff Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
NTGroupInfo::`vector deleting destructor'
</value>
</Slot>
<Slot count="190" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
</value>
</Slot>
Im vorherigen Beispiel verfügten die interessantesten Listen über die höchste Anzahl von Slots (35.668 und 8.506), bei der es sich auch um eine Slotanzahl > 1.000 handelt.
Nun fragen Sie sich möglicherweise, inwiefern diese Information Ihnen weiterhilft. Im Allgemeinen sind umfassende Kenntnisse in Bezug auf die SQL Server-Engine erforderlich, um die Informationen aus den Aufruflisten nutzen zu können. Daher betritt der Problembehandlungsprozess nun eine Grauzone. In diesem speziellen Fall können wir anhand der Aufrufstapel sehen, dass der Codepfad, in dem das Problem auftritt, mit Sicherheits- und Metadaten-Nachschlagevorgängen verknüpft ist (Wie durch die folgenden Stapelframes CMEDCatalogOwner::GetProxyOwnerBySID & CMEDProxyDatabase::GetOwnerBySID)ersichtlich.
Isoliert ist es schwierig, diese Informationen zu verwenden, um das Problem zu beheben, aber es gibt uns einige Ideen, wo wir zusätzliche Problembehandlung konzentrieren können, um das Problem weiter zu isolieren.
Da dieses Problem mit Codepfaden in Zusammenhang zu stehen schien, die sicherheitsbezogene Überprüfungen durchführten, wurde entschieden, einen Test durchzuführen, bei dem Anwendungsbenutzern, die eine Verbindung mit der Datenbank herstellten, SysAdmin-Berechtigungen erteilt wurden. In einer Produktionsumgebung ist dieses Vorgehen zwar nie zu empfehlen, in unserer Testumgebung erwies es sich jedoch als nützlicher Schritt bei der Problembehandlung. Wenn die Sitzungen mit erhöhten Rechten (SysAdmin) ausgeführt wurden, verschwanden die CPU-Spitzen im Zusammenhang mit Konflikten.
Optionen und Problemumgehungen
Die Problembehandlung bei Spinlockkonflikten kann auf jeden Fall eine nicht triviale Aufgabe sein. Es gibt keinen "gemeinsamen besten Ansatz". Der erste Schritt bei der Problembehandlung und der Behebung von Leistungsproblemen besteht darin, die Grundursache zu ermitteln. Die Verwendung der in diesem Artikel beschriebenen Methoden und Tools ist der erste Schritt der Durchführung der zum Verstehen der Konfliktpunkte im Zusammenhang mit Spinlocks erforderlichen Analyse.
Mit der Entwicklung neuer Versionen von SQL Server wird die Skalierbarkeit in der Engine durch das Implementieren von Code, der für Systeme mit hoher Parallelität besser optimiert ist, immer weiter verbessert. SQL Server hat viele Optimierungen für Systeme mit hoher Parallelität eingeführt. Eine davon ist das exponentielle Backoff für die häufigsten Konfliktpunkte. Durch bestimmte Optimierungen ab SQL Server 2012 wurde speziell dieser Bereich durch die Verwendung exponentieller Backoffalgorithmen für alle Spinlocks innerhalb der Engine verbessert.
Wenn Sie High-End-Anwendungen entwickeln, für die eine äußerst hohe Leistung und ein sehr großer Umfang erforderlich sind, sollten Sie überlegen, wie Sie den benötigten Codepfad in SQL Server so kurz wie möglich halten. Ein kürzerer Codepfad bedeutet weniger Arbeit für die Datenbank-Engine und vermeidet natürlich Konfliktpunkte. Eine Nebenwirkung bei vielen bewährten Methoden ist, dass die erforderliche Arbeit der Engine reduziert und somit die Arbeitsauslastungsleistung optimiert wird.
Einige der in diesem Artikel bereits erwähnten bewährten Methoden sind Beispiele hierfür:
Vollqualifizierte Namen: Vollständig qualifizierende Namen aller Objekte führen dazu, dass SQL Server Codepfade ausführt, die zum Auflösen von Namen erforderlich sind. Beim Spinlocktyp SOS_CACHESTORE waren Konfliktpunkte auch zu beobachten, wenn beim Aufrufen gespeicherter Prozeduren keine vollqualifizierten Namen verwendet wurden. Wenn diese Namen nicht vollqualifiziert sind, muss SQL Server das Standardschema für den Benutzer suchen, was dazu führt, dass ein längerer Codepfad zum Ausführen des SQL-Codes erforderlich ist.
Parametrisierte Abfragen: Ein weiteres Beispiel verwendet parametrisierte Abfragen und gespeicherte Prozeduraufrufe, um die Arbeit zu reduzieren, die zum Generieren von Ausführungsplänen erforderlich ist. Dies führt ebenfalls zu einem kürzeren Codepfad für die Ausführung.
LOCK_HASH Contention: In manchen Fällen ist die Auseinandersetzung mit bestimmten Sperrstrukturen oder Hash-Bucket-Kollisionen unvermeidbar. Auch wenn die SQL Server-Engine den Großteil der Sperrstrukturen partitioniert, gibt es dennoch Fälle, in denen das Erlangen einer Sperre zum Zugriff auf denselben Hashbucket führt. Dies ist z. B. bei einer Anwendung der Fall, bei der mehrere Threads gleichzeitig auf dieselbe Zeile zugreifen (also bei Verweisdaten). Diese Arten von Problemen können mithilfe von Techniken näher behandelt werden, die diese Referenzdaten entweder innerhalb des Datenbankschemas skalieren oder wenn möglich NOLOCK-Hinweise verwenden.
Der erste Ansatz bei der Optimierung von SQL Server-Arbeitsauslastungen sind immer die Standardoptimierungsmethoden (z. B. Indizierung, Abfrageoptimierung und E/A-Optimierung). Neben den standardmäßig durchgeführten Optimierungsmaßnahmen stellt jedoch auch die Verwendung von Methoden zur Reduzierung der für das Ausführen von Vorgängen erforderlichen Codemenge einen wichtigen Ansatz dar. Selbst wenn bewährte Methoden befolgt werden, besteht immer noch die Möglichkeit, dass spinlock-Konkurrierung auf stark besetzten Parallelitätssystemen auftreten kann. Die Verwendung der Tools und Techniken in diesem Artikel kann dazu beitragen, diese Arten von Problemen zu isolieren oder auszuschließen und zu bestimmen, wann es erforderlich ist, die richtigen Microsoft-Ressourcen zu unterstützen.
Diese Vorgehensweisen bieten hoffentlich sowohl eine nützliche Methodik für diese Art der Problembehandlung als auch Einblicke in einige der mit SQL Server möglichen fortgeschritteneren Methoden zur Leistungsprofilerstellung.
Anhang: Automatisieren der Speicherabbilderfassung
Das folgende Skript für erweiterte Ereignisse hat sich für die Automatisierung der Erfassung von Arbeitsspeicherabbildern, wenn Spinlockkonflikte erheblich werden, als nützlich erwiesen. In einigen Fällen sind Arbeitsspeicherabbilder für eine vollständige Diagnose des Problems erforderlich, oder sie werden von Microsoft-Supportteams für die Durchführung einer ausführlichen Analyse verlangt. In SQL Server 2008 gibt es ein Limit von 16 Frames in Callstacks, die vom Bucketizer erfasst werden, was möglicherweise nicht tief genug ist, um genau zu bestimmen, wo im Modul der Aufrufstack eingegeben wird. In SQL Server 2012 wurden Verbesserungen eingeführt, indem die Anzahl der Frames in vom Bucketizer erfassten Aufruflisten auf 32 erhöht wurde.
Das folgende SQL-Skript kann verwendet werden, um den Erfassungsprozess für Arbeitsspeicherabbilder als Hilfe bei der Analyse von Spinlockkonflikten zu automatisieren:
/*
This script is provided "AS IS" with no warranties, and confers no rights.
Use: This procedure will monitor for spinlocks with a high number of backoff events
over a defined time period which would indicate that there is likely significant
spin lock contention.
Modify the variables noted below before running.
Requires:
xp_cmdshell to be enabled
sp_configure 'xp_cmd', 1
go
reconfigure
go
*********************************************************************************************************/
USE tempdb;
GO
IF object_id('sp_xevent_dump_on_backoffs') IS NOT NULL
DROP PROCEDURE sp_xevent_dump_on_backoffs
GO
CREATE PROCEDURE sp_xevent_dump_on_backoffs (
@sqldumper_path NVARCHAR(max) = '"c:\Program Files\Microsoft SQL Server\100\Shared\SqlDumper.exe"',
@dump_threshold INT = 500, --capture mini dump when the slot count for the top bucket exceeds this
@total_delay_time_seconds INT = 60, --poll for 60 seconds
@PID INT = 0,
@output_path NVARCHAR(MAX) = 'c:\',
@dump_captured_flag INT = 0 OUTPUT
)
AS
/*
--Find the spinlock types
select map_value, map_key, name from sys.dm_xe_map_values
where name = 'spinlock_types'
order by map_value asc
--Example: Get the type value for any given spinlock type
select map_value, map_key, name from sys.dm_xe_map_values
where map_value IN ('SOS_CACHESTORE', 'LOCK_HASH', 'MUTEX')
*/
IF EXISTS (
SELECT *
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump'
)
DROP EVENT SESSION spinlock_backoff_with_dump
ON SERVER
CREATE EVENT SESSION spinlock_backoff_with_dump ON SERVER
ADD EVENT sqlos.spinlock_backoff (
ACTION(package0.callstack) WHERE type = 61 --LOCK_HASH
--or type = 144 --SOS_CACHESTORE
--or type = 8 --MUTEX
--or type = 53 --LOGCACHE_ACCESS
--or type = 41 --LOGFLUSHQ
--or type = 25 --SQL_MGR
--or type = 39 --XDESMGR
) ADD target package0.asynchronous_bucketizer (
SET filtering_event_name = 'sqlos.spinlock_backoff',
source_type = 1,
source = 'package0.callstack'
)
WITH (
MAX_MEMORY = 50 MB,
MEMORY_PARTITION_MODE = PER_NODE
)
ALTER EVENT SESSION spinlock_backoff_with_dump ON SERVER STATE = START;
DECLARE @instance_name NVARCHAR(MAX) = @@SERVICENAME;
DECLARE @loop_count INT = 1;
DECLARE @xml_result XML;
DECLARE @slot_count BIGINT;
DECLARE @xp_cmdshell NVARCHAR(MAX) = NULL;
--start polling for the backoffs
PRINT 'Polling for: ' + convert(VARCHAR(32), @total_delay_time_seconds) + ' seconds';
WHILE (@loop_count < CAST(@total_delay_time_seconds / 1 AS INT))
BEGIN
WAITFOR DELAY '00:00:01'
--get the xml from the bucketizer for the session
SELECT @xml_result = CAST(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump';
--get the highest slot count from the bucketizer
SELECT @slot_count = @xml_result.value(N'(//Slot/@count)[1]', 'int');
--if the slot count is higher than the threshold in the one minute period
--dump the process and clean up session
IF (@slot_count > @dump_threshold)
BEGIN
PRINT 'exec xp_cmdshell ''' + @sqldumper_path + ' ' + convert(NVARCHAR(max), @PID) + ' 0 0x800 0 c:\ '''
SELECT @xp_cmdshell = 'exec xp_cmdshell ''' + @sqldumper_path + ' ' + convert(NVARCHAR(max), @PID) + ' 0 0x800 0 ' + @output_path + ' '''
EXEC sp_executesql @xp_cmdshell
PRINT 'loop count: ' + convert(VARCHAR(128), @loop_count)
PRINT 'slot count: ' + convert(VARCHAR(128), @slot_count)
SET @dump_captured_flag = 1
BREAK
END
--otherwise loop
SET @loop_count = @loop_count + 1
END;
--see what was collected then clean up
DBCC TRACEON (3656, -1);
SELECT event_session_address,
target_name,
execution_count,
cast(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump';
ALTER EVENT SESSION spinlock_backoff_with_dump ON SERVER STATE = STOP;
DROP EVENT SESSION spinlock_backoff_with_dump ON SERVER;
GO
/* CAPTURE THE DUMPS
******************************************************************/
--Example: This will run continuously until a dump is created.
DECLARE @sqldumper_path NVARCHAR(MAX) = '"c:\Program Files\Microsoft SQL Server\100\Shared\SqlDumper.exe"';
DECLARE @dump_threshold INT = 300; --capture mini dump when the slot count for the top bucket exceeds this
DECLARE @total_delay_time_seconds INT = 60; --poll for 60 seconds
DECLARE @PID INT = 0;
DECLARE @flag TINYINT = 0;
DECLARE @dump_count TINYINT = 0;
DECLARE @max_dumps TINYINT = 3; --stop after collecting this many dumps
DECLARE @output_path NVARCHAR(max) = 'c:\'; --no spaces in the path please :)
--Get the process id for sql server
DECLARE @error_log TABLE (
LogDate DATETIME,
ProcessInfo VARCHAR(255),
TEXT VARCHAR(max)
);
INSERT INTO @error_log
EXEC ('xp_readerrorlog 0, 1, ''Server Process ID''');
SELECT @PID = convert(INT, (REPLACE(REPLACE(TEXT, 'Server Process ID is ', ''), '.', '')))
FROM @error_log
WHERE TEXT LIKE ('Server Process ID is%');
PRINT 'SQL Server PID: ' + convert(VARCHAR(6), @PID);
--Loop to monitor the spinlocks and capture dumps. while (@dump_count < @max_dumps)
BEGIN
EXEC sp_xevent_dump_on_backoffs @sqldumper_path = @sqldumper_path,
@dump_threshold = @dump_threshold,
@total_delay_time_seconds = @total_delay_time_seconds,
@PID = @PID,
@output_path = @output_path,
@dump_captured_flag = @flag OUTPUT
IF (@flag > 0)
SET @dump_count = @dump_count + 1
PRINT 'Dump Count: ' + convert(VARCHAR(2), @dump_count)
WAITFOR DELAY '00:00:02'
END;
Anhang: Erfassen von Spinlockstatistiken im Laufe der Zeit
Das folgende Skript kann verwendet werden, um die Spinlockstatistiken für einen bestimmten Zeitraum anzuzeigen. Immer wenn es ausgeführt wird, wird die Differenz zwischen den aktuellen Werten und den zuvor erfassten Werten zurückgegeben.
/* Snapshot the current spinlock stats and store so that this can be compared over a time period
Return the statistics between this point in time and the last collection point in time.
**This data is maintained in tempdb so the connection must persist between each execution**
**alternatively this could be modified to use a persisted table in tempdb. if that
is changed code should be included to clean up the table at some point.**
*/
USE tempdb;
GO
DECLARE @current_snap_time DATETIME;
DECLARE @previous_snap_time DATETIME;
SET @current_snap_time = GETDATE();
IF NOT EXISTS (
SELECT name
FROM tempdb.sys.sysobjects
WHERE name LIKE '#_spin_waits%'
)
CREATE TABLE #_spin_waits (
lock_name VARCHAR(128),
collisions BIGINT,
spins BIGINT,
sleep_time BIGINT,
backoffs BIGINT,
snap_time DATETIME
);
--capture the current stats
INSERT INTO #_spin_waits (
lock_name,
collisions,
spins,
sleep_time,
backoffs,
snap_time
)
SELECT name,
collisions,
spins,
sleep_time,
backoffs,
@current_snap_time
FROM sys.dm_os_spinlock_stats;
SELECT TOP 1 @previous_snap_time = snap_time
FROM #_spin_waits
WHERE snap_time < (
SELECT max(snap_time)
FROM #_spin_waits
)
ORDER BY snap_time DESC;
--get delta in the spin locks stats
SELECT TOP 10 spins_current.lock_name,
(spins_current.collisions - spins_previous.collisions) AS collisions,
(spins_current.spins - spins_previous.spins) AS spins,
(spins_current.sleep_time - spins_previous.sleep_time) AS sleep_time,
(spins_current.backoffs - spins_previous.backoffs) AS backoffs,
spins_previous.snap_time AS [start_time],
spins_current.snap_time AS [end_time],
DATEDIFF(ss, @previous_snap_time, @current_snap_time) AS [seconds_in_sample]
FROM #_spin_waits spins_current
INNER JOIN (
SELECT *
FROM #_spin_waits
WHERE snap_time = @previous_snap_time
) spins_previous
ON (spins_previous.lock_name = spins_current.lock_name)
WHERE spins_current.snap_time = @current_snap_time
AND spins_previous.snap_time = @previous_snap_time
AND spins_current.spins > 0
ORDER BY (spins_current.spins - spins_previous.spins) DESC;
--clean up table
DELETE
FROM #_spin_waits
WHERE snap_time = @previous_snap_time;
Nächster Schritt
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für