Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In Service Manager können Daten, die im Data Warehouse vorhanden sind, aus verschiedenen Quellen zusammengeführt werden. Es wird in Service Manager mithilfe vordefinierter und benutzerdefinierter Microsoft Online Analytical Processing (OLAP)-Datencubes dargestellt. Kurz gesagt besteht die erweiterte Analyse im Service Manager aus der Veröffentlichung, Anzeige und Bearbeitung von Cubedaten, in der Regel in Microsoft Excel oder Microsoft SharePoint. Excel wird in erster Linie allein zum Anzeigen und Bearbeiten von Daten verwendet. SharePoint wird in erster Linie als Mittel zum Veröffentlichen und Freigeben von Cubedaten verwendet.
Service Manager umfasst ein System Center-weites Data Warehouse. Daher können Daten aus Operations Manager, Configuration Manager und Service Manager in das Data Warehouse konsolidiert werden, wo Sie problemlos mehrere Datenansichten verwenden können, um alle gewünschten Informationen abzurufen. Dies ist auch eine Schnittstelle, über die Sie Daten aus Ihren eigenen benutzerdefinierten Quellen, z. B. SAP-Anwendungen oder einer Personalanwendung von Drittanbietern, in dasselbe Data Warehouse einfügen können. Diese Konsolidierung erstellt ein Common Data Model und ermöglicht erweiterte Analysen, mit denen Sie ein Data Warehouse in Ihrer IT-Organisation erstellen können, das alle Ihre Business Intelligence- und Berichterstellungsanforderungen erfüllen kann.
Wenn sich Ihre Daten in einem gemeinsamen Modell befinden, können Sie Informationen bearbeiten und verfügen über gemeinsame Definitionen und eine gemeinsame Taxonomie für Ihr gesamtes Unternehmen. Dies ist möglich, indem Sie OLAP-Datencubes bereitstellen und über Standardtools wie Excel und SharePoint auf die Informationen aus den Cubes zugreifen. Dies ermöglicht es Ihren Benutzenden, Fähigkeiten einzusetzen, die sie bereits kennen. Sie steuern die Definition Ihrer Geschäftslogik zentral. Sie können beispielsweise wichtige Leistungsindikatoren definieren, z. B. die Schwellenwerte für die Auflösung von Vorfällen und welche Werte für die Schwellenwerte grün, gelb oder rot sind. Sie können diese Auswahl zentral steuern und Ihren Benutzenden die einfache Verwendung der Daten ermöglichen, während die gemeinsame Definition in ihren Excel-Berichten oder ihren SharePoint-Dashboards angezeigt wird.
Informationen zu OLAP-Cubes im Service-Manager
OLAP-Cubes (Online Analytical Processing) sind eine Funktion in Service Manager, die die vorhandene Data Warehouse-Infrastruktur nutzen, um Endbenutzenden Self-Service-Business-Intelligence-Funktionen bereitzustellen.
Ein OLAP-Cube ist eine Datenstruktur, die die Einschränkungen relationaler Datenbanken durch eine schnelle Analyse von Daten überwindet. Cubes können große Datenmengen anzeigen und addieren und Benutzenden gleichzeitig einen durchsuchbaren Zugriff auf Datenpunkte bieten. Auf diese Weise können die Daten nach Bedarf zusammengefasst, aufgeschlüsselt und untergliedert werden, um die unterschiedlichsten Fragen zu beantworten, die für den Interessenbereich eines Benutzenden relevant sind.
Softwareanbieter oder IT-Entwickelnde mit Kenntnissen über OLAP-Cubes können Management Packs erstellen, um ihre eigenen erweiterbaren und anpassbaren OLAP-Cubes zu definieren, die auf der Data Warehouse-Infrastruktur basieren. Diese Cubes werden in SQL Server Analysis Services (SSAS) gespeichert. Self-Service Business Intelligence-Tools wie Excel und SQL Server Reporting Services (SSRS) können diese Cubes in SSAS als Ziel verwenden, und Sie können sie verwenden, um die Daten aus mehreren Perspektiven zu analysieren.
Die Datenbanken, die von einem Unternehmen zum Speichern aller Transaktionen und Datensätze verwendet werden, werden als Datenbanken mit Onlinetransaktionsverarbeitung (Online Transaction Processing, OLTP) bezeichnet. Diese Datenbanken verfügen in der Regel über Datensätze, die einzeln eingegeben werden und eine Fülle von Informationen enthalten, die von Strategen verwendet werden können, um fundierte Entscheidungen über ihr Unternehmen zu treffen. Die Datenbanken, in denen die Daten gespeichert werden, wurden dagegen nicht für Analysezwecke entworfen. Daher ist das Abrufen von Antworten aus diesen Datenbanken sehr zeitintensiv und aufwändig. OLAP-Datenbanken sind spezielle Datenbanken, die dazu entworfen wurden, diese Business Intelligence-Informationen aus den Daten zu extrahieren.
OLAP-Cubes können als das letzte Puzzleteil für eine Data Warehouse-Lösung betrachtet werden. Ein OLAP-Cube, auch als multidimensionaler Cube oder Hypercube bezeichnet, ist eine Datenstruktur in SQL Server Analysis Services (SSAS), die mithilfe von OLAP-Datenbanken erstellt wird, um eine nahezu sofortige Analyse von Daten zu ermöglichen. Die Topologie dieses Systems wird in der folgenden Abbildung gezeigt.
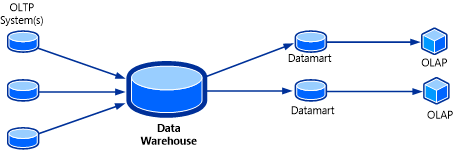
Das nützliche Feature eines OLAP-Cubes besteht darin, dass die Daten im Cube in einer aggregierten Form enthalten sein können. Für den Benutzenden scheint der Cube die Antworten im Voraus zu haben, da die Werteauswahl bereits vorkompiliert ist. Ohne die OLAP-Quelldatenbank abfragen zu müssen, kann der Cube fast augenblicklich Antworten auf eine Vielzahl von Fragen liefern.
Das Hauptziel von Service Manager-OLAP-Cubes ist es, Softwareanbietern oder IT-Entwicklenden die Möglichkeit zu geben, nahezu sofortige Analysen von Daten sowohl für historische Analysen als auch Trendzwecke durchzuführen. Service Manager ermöglicht dies wie folgt:
- Sie können OLAP-Cubes in Management Packs definieren, die automatisch in SSAS erstellt werden, wenn das Management Pack bereitgestellt wird.
- Automatische Verwaltung des Cubes ohne Benutzereingriff, Ausführen von Aufgaben wie Verarbeitung, Partitionierung, Übersetzungen und Lokalisierung sowie Schemaänderungen.
- Benutzende können Self-Service Business Intelligence-Tools wie Excel verwenden, um die Daten aus mehreren Perspektiven zu analysieren.
- Speichern generierter Excel-Berichte für zukünftige Referenzzwecke.
Um zu sehen, wie Data Warehouse-Cubes in der Service Manager-Konsole dargestellt werden, navigieren Sie zum Arbeitsbereich Data Warehouse und wählen Sie Cubes aus.
OLAP-Cubes des Service Managers
Die folgende Abbildung zeigt ein Bild aus SQL Server Business Intelligence Development Studio (BIDS), das die Hauptbestandteile darstellt, die für Online Analytical Processing (OLAP)-Cubes erforderlich sind. Diese Teile sind die Datenquelle, die Datenquellenansicht, die Cubes und die Dimensionen. In den folgenden Abschnitten werden die OLAP-Cubeteile und die Aktionen beschrieben, die Benutzende mit ihnen ausführen können.
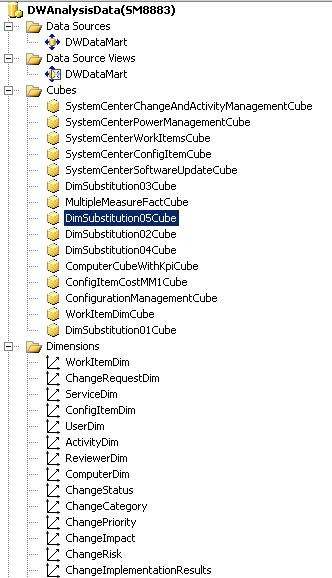
Datenquelle
Eine Datenquelle ist der Ursprung aller Daten, die in einem OLAP-Cube enthalten sind. Ein OLAP-Cube verbindet sich mit einer Datenquelle, um Rohdaten zu lesen und zu verarbeiten und dann Aggregationen und Berechnungen für die zugehörigen Measures auszuführen. Die Datenquelle für alle OLAP-Cubes von Service Manager sind die Data Marts, die sowohl die Data Marts für Operations Manager als auch für Configuration Manager enthalten. Authentifizierungsinformationen zur Datenquelle müssen in SQL Server Analysis Services (SSAS) gespeichert werden, um die richtige Berechtigungsstufe festzulegen.
Datenquellensicht
Die Datenquellenansicht (DSV, Data Source View) ist eine Sammlung von Ansichten, die die Dimensions-, Fakten- und Outriggertabellen aus der Datenquelle darstellen, z. B. die Data Marts von Service Manager. Die DSV (Datenquellenansicht) enthält alle Beziehungen zwischen Tabellen, wie Primär- und Fremdschlüssel. Mit anderen Worten: die Datenquellenansicht gibt an, wie die SSAS-Datenbank dem relationalen Schema zugeordnet wird und stellt eine Abstraktionsebene über der relationalen Datenbank bereit. Mithilfe dieser Abstraktionsebene können Beziehungen zwischen Fakten- und Dimensionstabellen definiert werden, auch wenn keine Beziehungen in der relationalen Datenbank der Quelle vorhanden sind. Auch benannte Berechnungen, benutzerdefinierte Measures und neue Attribute können in der Datenquellenansicht definiert werden, auch wenn sie möglicherweise nicht nativ im dimensionalen Schema des Data Warehouses existieren. Beispielsweise berechnet eine benannte Berechnung, die einen booleschen Wert für Gelöste Vorfälle definiert, den Wert als „True“, wenn der Status eines Vorfalls gelöst oder geschlossen ist. Mithilfe der benannten Berechnung kann Service Manager dann ein Measure definieren, um nützliche Informationen anzuzeigen, z. B. den Prozentsatz der gelösten Vorfälle, die Gesamtzahl der gelösten Vorfälle und die Gesamtzahl der nicht gelösten Vorfälle.
Ein weiteres schnelles Beispiel für eine benannte Berechnung ist ReleasesImplementedOnSchedule. Diese benannte Berechnung stellt eine schnelle Integritätsstatusüberprüfung für die Anzahl der Veröffentlichungsdatensätze bereit, bei denen das tatsächliche Enddatum kleiner oder gleich dem geplanten Enddatum ist.
OLAP-Cubes
Ein OLAP-Cube ist eine Datenstruktur, die Einschränkungen relationaler Datenbanken durch eine schnelle Analyse von Daten überwindet. OLAP-Cubes können große Datenmengen anzeigen und summieren und gleichzeitig Benutzenden durchsuchbaren Zugriff auf alle Datenpunkte bieten, sodass die Daten nach Bedarf zusammengefasst, aufgeschlüsselt und untergliedert werden können, sodass die größtmögliche Vielfalt an Fragen behandelt werden kann, die für den Interessenbereich von Benutzenden relevant sind.
Maße
Eine Dimension in SSAS verweist auf eine Dimension aus dem Service Manager-Data Warehouse. In Service Manager entspricht eine Dimension ungefähr einer Management Pack-Klasse. Jede Management Pack-Klasse verfügt über eine Liste von Eigenschaften, während jede Dimension eine Liste von Attributen enthält, wobei jedes Attribut einer Eigenschaft in einer Klasse zugeordnet ist. Dimensionen ermöglichen das Filtern, Gruppieren und Bezeichnen von Daten. So können Sie z. B. Computer nach dem installierten Betriebssystem filtern und Personen nach Geschlecht oder Alter in Kategorien gruppieren. Die Daten können dann in einem Format dargestellt werden, in dem sie zur ausführlicheren Analyse natürlich in diese Hierarchien und Kategorien unterteilt werden. Auch Dimensionen können natürliche Hierarchien aufweisen, sodass Benutzende Informationen zu detaillierteren Ebenen vertiefen können. Beispielsweise weist die Datumsdimension eine Hierarchie auf, für die nach Jahr, Quartal, Monat, Woche und dann Tag Detailinformationen angezeigt werden können.
Die folgende Abbildung zeigt einen OLAP-Cube, der die Dimensionen Datum, Region und Produkt enthält.
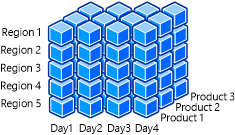
Beispielsweise möchten Microsoft-Teammitglieder eine schnelle und einfache Zusammenfassung der Verkäufe einer bestimmten Version der Xbox One-Spielekonsole anzeigen. Sie können tiefer in die Details einsteigen, um Umsatzzahlen für einen eingegrenzteren Zeitrahmen abzurufen. Geschäftsanalysten könnten untersuchen, wie sich der Vertrieb von Xbox One-Konsolen seit Einführung des neuen Konsolendesigns und des Kinect für Xbox One entwickelt hat. Auf diese Weise können sie ermitteln, welche Umsatztrends auftreten und welche Überarbeitungen der Geschäftsstrategie erforderlich sind. Durch Filtern nach der Datumsdimension können diese Informationen schnell übermittelt und genutzt werden. Das Aufschlüssen und Untergliedern von Daten ist nur möglich, da die Dimensionen mit Attributen und Daten entworfen wurden, die von der Kundschaft ganz einfach gefiltert und gruppiert werden können.
In Service Manager teilen alle OLAP-Cubes eine gemeinsame Gruppe von Dimensionen. Alle Dimensionen verwenden den primären Data Warehouse-Data Mart als Quelle, auch in Szenarien mit mehreren Data Marts. In Szenarien mit mehreren Data Marts kann dies möglicherweise zu Dimensionsschlüsselfehlern während der Verarbeitung des Cubes führen.
Maßgruppe
Eine Maßgruppe ist dasselbe Konzept wie ein Fakt in der Data-Warehouse-Terminologie. Ebenso wie Fakten numerische Kennzahlen in einem Data Warehouse enthalten, enthält eine Kennzahlgruppe Kennzahlen für einen OLAP-Cube. Alle Kennzahlen in einem OLAP-Cube, die sich von einer einzelnen Faktentabelle in einer Datenquellensicht ableiten, können auch als Kennzahlengruppe angesehen werden. Es kann jedoch vorkommen, dass mehrere Faktentabellen existieren, von denen sich die Measures in einem OLAP-Cube ableiten. Maße des gleichen Detaillierungsgrads werden in einer Maßgruppe zusammengefasst. Maßgruppierungen definieren, welche Daten in das System geladen werden, wie die Daten geladen werden und wie die Daten an den mehrdimensionalen Würfel gebunden werden.
Jede Maßgruppe enthält auch eine Liste von Partitionen, die die tatsächlichen Daten in separaten, sich nicht überschneidenden Abschnitten halten. Messgruppen enthalten auch ein Aggregationsdesign, das die voraggregierten Datensätze definiert, die für jede Messgruppe berechnet werden, um die Leistung von Benutzerabfragen zu verbessern.
Maßnahmen
Measures sind die numerischen Werte, die Benutzende aufschlüsseln, untergliedern, aggregieren und analysieren können. Sie sind einer der Hauptgründe, warum Sie OLAP-Cubes mithilfe der Data Warehouse-Infrastruktur erstellen sollten. Mithilfe von SSAS können Sie OLAP-Cubes erstellen, die Geschäftsregeln und -berechnungen anwenden, um Measures in einem anpassbaren Format zu formatieren und anzuzeigen. Ein Großteil Ihrer Entwicklungszeit für OLAP-Würfel wird darauf verwendet, festzulegen und zu definieren, welche Measures angezeigt werden und wie sie berechnet werden.
Measures sind Werte, die in der Regel numerischen Spalten in einer Data Warehouse-Faktentabelle zugeordnet sind, aber auch auf Dimensions- und degenerierten Dimensionsattributen erstellt werden können. Diese Kennzahlen sind die wichtigsten Werte eines OLAP-Cubes, der analysiert wird, und sind von besonderem Interesse für Endbenutzer, die den OLAP-Cube abfragen. Ein Beispiel für ein Measure, das im Data Warehouse vorhanden ist, ist „ActivityTotalTimeMeasure“. „ActivityTotalTimeMeasure“ ist ein Measure aus „ActivityStatusDurationFact“, das die Zeit darstellt, zu der sich jede Aktivität in einem bestimmten Status befindet. Der Detailgrad einer Maßnahme wird durch alle Dimensionen bestimmt, auf die verwiesen wird. Die Detailebene des Beziehungsfakts ComputerHostsOperatingSystem besteht beispielsweise aus den Dimensionen „Computer“ und „Betriebssystem“.
Aggregationsfunktionen werden auf Messwerten berechnet, um weitere Datenanalysen zu ermöglichen. Die am häufigsten verwendete Aggregationsfunktion ist „Summe“. Eine allgemeine OLAP-Cubeabfrage summiert beispielsweise die Gesamtzeit für alle Aktivitäten, die in Bearbeitung sind. Andere allgemeine Aggregationsfunktionen sind Min, Max und Count.
Nachdem die Rohdaten in einem OLAP-Cube verarbeitet wurden, können Benutzende komplexere Berechnungen und Abfragen mithilfe von mehrdimensionalen Ausdrücken (Multidimensional Expressions, MDX) ausführen, um ihre eigenen Measureausdrücke oder berechneten Member zu definieren. MDX ist der Branchenstandard zum Abfragen und Zugreifen auf Daten, die in OLAP-Systemen gespeichert sind. SQL Server wurde nicht für die Arbeit mit dem Datenmodell entwickelt, das mehrdimensionale Datenbanken unterstützt.
Drilldown durchführen
Wenn ein Benutzender einen Drilldown in den Daten in einem OLAP-Cube ausführt, analysiert der Benutzende die Daten auf einer anderen Zusammenfassungsebene. Die Detailebene der Daten ändert sich, während der Benutzer einen Drilldown ausführt und die Daten auf verschiedenen Ebenen in der Hierarchie untersucht. Während die Benutzenden einen Drilldown ausführen, wechseln sie von Zusammenfassungsinformationen zu Daten mit einem engeren Fokus. Im Folgenden sind Beispiele für eine Detaillierung aufgeführt:
- Vertiefende Analyse der Daten, um demografische Informationen über die Bevölkerung der USA zu erhalten, dann über den Bundesstaat Washington, dann über die Metropolregion Seattle, dann über die Stadt Redmond und schließlich über die Bevölkerung bei Microsoft.
- Detaillierte Analyse der Verkaufszahlen für Xbox One-Konsolen für das Kalenderjahr 2015, dann für das vierte Quartal des Jahres, dann für den Monat Dezember, dann für die Woche vor Weihnachten und schließlich für den Heiligabend.
Durchbohrung
Wenn Benutzende Daten durchbohren, möchten sie alle einzelnen Transaktionen sehen, die zu den aggregierten Daten des OLAP-Cubes beigetragen haben. Mit anderen Worten, der Benutzende kann die Daten für einen bestimmten Messwert auf der niedrigsten Detailebene abrufen. Wenn Sie z. B. die Umsatzdaten für einen bestimmten Monat und eine spezifische Produktkategorie erhalten, können Sie diese Daten detailliert durchgehen, um eine Liste der einzelnen Tabellenzeilen anzuzeigen, die in diesem Datenbereich enthalten sind.
Die Begriffe Drilldown und Drillthrough werden häufig miteinander verwechselt. Der Hauptunterschied zwischen ihnen besteht darin, dass ein Drilldown auf einer vordefinierten Hierarchie von Daten innerhalb des OLAP-Cubes arbeitet, z. B. USA, dann Washington und dann Seattle. Ein Drillthrough erfolgt direkt auf der niedrigsten Detailebene der Daten und ruft eine Reihe von Zeilen aus der Datenquelle ab, die in eine einzelne Zelle aggregiert wurden.
Leistungskennzahl
Organisationen können Key Performance Indicators (KPIs) verwenden, um den Status ihres Unternehmens und ihrer Leistung zu messen, indem sie ihren Fortschritt bei der Erreichung ihrer Ziele messen. KPIs sind Geschäftsmetriken, die definiert werden können, um den Fortschritt im Hinblick auf bestimmte vordefinierte Ziele zu überwachen. Ein KPI hat einen Zielwert und einen tatsächlichen Wert, der ein quantitatives Ziel darstellt, das für den Erfolg der Organisation von entscheidender Bedeutung ist. KPIs werden in Gruppen auf einer Scorecard angezeigt, um den Gesamtzustand des Unternehmens in einer schnellen Momentaufnahme darzustellen.
Ein Beispiel für einen KPI ist die Bearbeitung aller Änderungsanforderungen innerhalb von 48 Stunden. Ein KPI kann verwendet werden, um den Prozentsatz der Änderungsanforderungen zu messen, die innerhalb dieses Zeitrahmens gelöst werden. Sie können Dashboards erstellen, um KPIs visuell darzustellen. Sie können z. B. einen KPI-Zielwert für die Bearbeitung aller Änderungsanforderungen innerhalb von 48 Stunden auf 75 Prozent festlegen.
Partitionen
Eine Partition ist eine Datenstruktur, die einige oder alle Daten in einer Maßgruppe hält. Jede Maßgruppierung ist in Partitionen unterteilt. Eine Aufteilung definiert eine Teilmenge der Faktendaten, die in die Maßgruppe geladen wird. Die SSAS Standard Edition erlaubt nur eine Partition pro Measuregruppe, während in der SSAS Enterprise Edition eine Measuregruppe mehrere Partitionen enthalten kann. Partitionen sind ein Feature, das für den Endbenutzenden transparent ist, aber sie haben einen großen Einfluss auf die Leistung und Skalierbarkeit von OLAP-Würfeln. Alle Partitionen für eine Measure-Gruppe befinden sich immer in derselben physischen Datenbank.
Partitionen ermöglichen es einem Administrierenden, einen OLAP-Cube besser zu verwalten und die Leistung eines OLAP-Cubes zu verbessern. Sie können beispielsweise die Daten in einer Partition einer Measuregruppe entfernen oder erneut verarbeiten, ohne dass sich dies auf die restliche Measuregruppe auswirkt. Wenn Sie neue Daten in eine Faktentabelle laden, sind nur die Partitionen betroffen, die die neuen Daten enthalten sollen.
Die Partitionierung verbessert auch die Verarbeitung und Abfrageleistung für OLAP-Cubes. SSAS kann mehrere Partitionen parallel verarbeiten, was zu einer wesentlich effizienteren Verwendung der CPU- und Arbeitsspeicherressourcen auf dem Server führt. Während eine Abfrage ausgeführt wird, ruft SSAS auch Daten aus mehreren Partitionen ab, verarbeitet und aggregiert sie. Es werden nur Partitionen gescannt, die die für eine Abfrage relevanten Daten enthalten , wodurch die Gesamtmenge der Ein- und Ausgaben reduziert wird.
Ein Beispiel für eine Partitionierungsstrategie besteht darin, die Faktendaten für jeden Monat in eine monatliche Partition zu setzen. Am Ende jedes Monats werden alle neuen Daten in eine neue Partition verschoben, was zu einer natürlichen Verteilung von Daten mit nicht überlappten Werten führt.
Aggregationen
Aggregationen in einem OLAP-Cube sind vorab zusammengefasste Datasets. Sie sind analog zu einer SQL SELECT-Anweisung mit einer GROUP BY-Klausel. SSAS kann diese Aggregationen verwenden, wenn sie Abfragen beantwortet, um die Menge der erforderlichen Berechnungen zu reduzieren und die Antworten schnell an den Benutzenden zurückzugeben. In den OLAP-Cube integrierte Aggregationen reduzieren die Menge an Aggregationen, die SSAS zum Abfragezeitpunkt durchführen muss. Das Erstellen der richtigen Aggregationen kann die Abfrageleistung erheblich verbessern. Dies ist häufig ein sich entwickelnder Prozess während der gesamten Lebensdauer des OLAP-Cubes, da sich die Abfragen und die Verwendung ändern.
In der Regel wird ein Basissatz von Aggregationen erstellt, der für die meisten Abfragen für den OLAP-Cube nützlich ist. Aggregationen werden für jede Partition eines OLAP-Würfels innerhalb einer Maßgruppe erstellt. Wenn eine Aggregation erstellt wird, werden bestimmte Attribute von Dimensionen in das vorab zusammengefasste Dataset einbezogen. Benutzende können die Daten schnell anhand dieser Aggregationen abfragen, wenn sie den OLAP-Cube durchsuchen. Aggregationen müssen sorgfältig entworfen werden, da die Anzahl potenzieller Aggregationen so groß ist, dass das Erstellen aller Aggregationen unangemessen viel Zeit und Speicherplatz in Anspruch nehmen würde.
Der Service Manager verwendet die folgenden beiden Optionen, wenn er Aggregationen in Service Manager-OLAP-Cubes erstellt und entwickelt:
- Leistungsgewinn erreicht
- Nutzungsbasierte Optimierung
Die Option „Erreichen des Leistungsgewinns“ definiert, welcher Prozentsatz der Aggregationen erstellt wird. Wenn Sie diese Option beispielsweise auf den Standard- und empfohlenen Wert von 30 Prozent festlegen, bedeutet dies, dass Aggregationen erstellt werden, um dem OLAP-Cube einen geschätzten Leistungsgewinn von 30 Prozent zu verleihen. Dies bedeutet jedoch nicht, dass 30 Prozent der möglichen Aggregationen erstellt werden.
Die nutzungsbasierte Optimierung ermöglicht es SSAS, die Datenanforderungen zu protokollieren, sodass die Informationen beim Ausführen einer Abfrage in den Aggregationsentwurfsprozess eingespeist werden. SSAS überprüft dann die Daten und empfiehlt, welche Aggregationen erstellt werden sollten, um den besten geschätzten Leistungsgewinn zu erzielen.
Service Manager-Cubepartitionierung
Jede Maßgruppe in einem Cube wird in Partitionen unterteilt, wobei eine Partition einen Teil der Faktendaten definiert, die in eine Maßgruppe geladen werden. SQL Server Analysis Services (SSAS) in SQL Server Standard Edition erlaubt nur eine Partition pro Measuregruppe, während in der Enterprise Edition mehrere Partitionen zulässig sind. Partitionen sind für den Endbenutzende vollständig transparent, haben aber einen wichtigen Einfluss auf die Leistung und Skalierbarkeit. Partitionen können beispielsweise separat und parallel verarbeitet werden. Sie können unterschiedliche Aggregationsdesigns haben. Sie können eine Partition neu verarbeiten, ohne dass dies die anderen Partitionen in einer Measuregruppe beeinflusst. Außerdem überprüft SSAS automatisch nur die Partitionen, die die für eine Abfrage erforderlichen Daten enthalten, wodurch die Abfrageleistung erheblich verbessert werden kann.
Die Cubepartitionierung wird bei jeder Ausführung eines Data-Warehouse-Wartungsauftrags durchgeführt, standardmäßig stündlich. Das spezifische Prozessmodul, das ausgeführt wird, lautet „ManageCubePartitions“. Sie wird immer nach dem Schritt „CreateMartPartitions“ ausgeführt. Diese Abhängigkeitsdaten werden in der Tabelle „infra.moduletriggercondition“ gespeichert.
Die wichtigste Dynamic Link Library (DLL), die Partitionierung verarbeitet, befindet sich in der Warehouse-Hilfsprogramm-DLL, Microsoft.EnterpriseManagement.Warehouse.Utility, in der PartitionUtil-Klasse. Insbesondere gibt es eine ManagePartitions()-Methode in der Klasse, die die gesamte Partitionswartung übernimmt. Die Data Warehouse-Wartungs-DLL, Microsoft.EnterpriseManagement.Warehouse.Maintenance und die OLAP-DLL (Data Warehouse Online Analytical Processing), Microsoft.EnterpriseManagement.Warehouse.Olap, rufen beide Microsoft.EnterpriseManagement.Warehouse.Utility auf, um Partitionen während der Wartung und Cubebereitstellung zu verarbeiten. Aus diesem Grund befindet sich die eigentliche Partitionsverarbeitung in der allgemeinen Warehouse-Hilfsprogramm-DLL, um die Duplizierung von Logik oder Code zu vermeiden.
Die Wartung der Kubenpartitionierung führt die folgenden Aufgaben aus:
- Erstellen von Partitionen
- Löschen von Partitionen
- Aktualisieren von Partitionsgrenzen
Dazu wird die SQL-Tabelle etl.TablePartition (Structured Query Language) gelesen, um alle Faktenpartitionen zu bestimmen, die für eine Maßgruppe erstellt wurden. Die folgenden Aktionen treten auf:
- Starten Sie die Verarbeitung des Würfels für jede Maßgruppe im Würfel.
- Rufen Sie alle Partitionen aus der etl.TablePartition-Tabelle für die Messgruppe ab.
- Löschen Sie alle Partitionen, die in der Maßgruppe vorhanden sind, die jedoch in der Tabelle etl.TablePartition fehlen.
- Fügen Sie alle neuen Partitionen hinzu, die erstellt wurden und die nur in der etl.TablePartition-Tabelle vorhanden sind
- Aktualisieren Sie alle Partitionen, die sich möglicherweise geändert haben, indem Sie jede Partition dem RangeStartDate und RangeEndDate in der etl.TablePartition-Tabelle zuordnen
Beachten Sie Folgendes bei der Würfelverarbeitung:
- Nur Maßgruppen, die auf Fakten ausgerichtet sind, enthalten mehrere Partitionen in SQL Server Standard Edition. Standardmäßig enthalten alle Maßgruppen und Dimensionen nur eine Partition. Daher weist die Partition keine Grenzbedingungen auf.
- Die Partitionsgrenzen werden durch eine Abfragebindung definiert, die auf Datumschlüsseln basiert, die mit den Datumschlüsseln für die entsprechende Faktenpartition in der Tabelle „etl.TablePartition“ übereinstimmen.
Service Manager-OLAP-Cube-Bereitstellung
Die OLAP-Cubebereitstellung (analytische Onlineverarbeitung) verwendet die Service Manager-Bereitstellungsinfrastruktur, um OLAP-Cubes in der SSAS-Datenbank (SQL Server Analysis Services) zu erstellen.
Zusammenfassend lässt sich sagen, dass ein einsetzbares Element einen Bereitsteller mit einer Sammlung von Ressourcen zurückgibt, die serialisiert sind und zur Erstellung des OLAP-Cubes in der SSAS-Datenbank verwendet werden. Bei OLAP-Cubes lautet der Name des bereitstellbaren Objekts „CubeDeployable“ für das SystemCenterCube-Element und „CubeExtensionDeployable“ für das CubeExtension-Element. Der Bereitsteller für beide Elemente ist CubeDeployer.
Die Tabelle„dbo.Selector“ in der Datenbank „DWStagingAndConfig“ enthält einen Eintrag für die beiden Elemente „SystemCenterCube“ und „CubeExtension Management Pack“. Das Bereitstellungsmodul verwendet diese Metadaten, wenn eine zusätzliche Bereitstellungsverarbeitung für ein Management Pack-Element erforderlich ist, wenn das Management Pack mithilfe des MPSync-Auftrags in das Data Warehouse importiert wird.
Bereitstellungen verwenden die AMO-Anwendungsprogrammierschnittstelle (Analysis Management Objects, API), um alle Cubekomponenten in der SSAS-Datenbank zu erstellen und zu ändern. Insbesondere wird AMO im getrennten Modus verwendet, da das CubeDeployable-Element keine Verbindung mit der SSAS-Datenbank hat. Durch das Arbeiten mit AMO im getrennten Modus können Sie die gesamte Struktur von AMO-Objekten erstellen, ohne eine Verbindung mit dem Server herzustellen. Service Manager serialisiert dann die Hierarchie von Objekten als Datenstromressourcen und fügt sie an das Bereitstellungsobjekt an, das an die Bereitstellungsinfrastruktur übergeben wird. Das Bereitstellungsobjekt wird dann deserialisiert, stellt eine Verbindung zur SSAD-Datenbank her und erstellt die Objekte, indem es die entsprechenden Anfragen an den Server sendet.
Nur Hauptobjekte können serialisiert werden. In AMO gelten Hauptobjekte als Klassen, die ein vollständiges Objekt als vollständige Entität und nicht als Teil eines anderen Objekts darstellen. Hauptobjekte umfassen z. B. Server, Cube und Dimension, die alle eigenständigen Entitäten sind. Das „DimensionAttribute“ ist jedoch kein Hauptobjekt, da es nur als Teil eines übergeordneten Hauptobjekts von Dimension erstellt werden kann. DimensionAttribute ist daher ein nebensächliches Objekt. Der OLAP-Cubeentwurf konzentriert sich auf das Erstellen aller wichtigen Objekte, die für Cubes erforderlich sind, sowie alle abhängigen Nebenobjekte. Diese Hauptobjekte sind die Objekte, die serialisiert und schließlich deserialisiert werden, bevor die Objekte in der SSAS-Datenbank erstellt werden.
Ressourcen, die Hauptobjekte umschließen, müssen in einer bestimmten Reihenfolge erstellt werden, damit die Bereitstellung erfolgreich abgeschlossen werden kann, und die Abhängigkeitsanforderungen der OLAP-Cubeelemente erfüllen. Die folgenden beiden Listen veranschaulichen die Bereitstellungssequenz für die Elemente „SystemCenterCube“ bzw. „CubeExtension“:
- DataSourceView-Elemente
- Dimensionselemente
- Datumsdimensions-Elemente
- Würfelelement
- DataSourceView-Elemente
- Würfelelement
Service Manager OLAP-Cubeverarbeitung
Wenn ein OLAP-Cube (analytische Onlineverarbeitung) bereitgestellt wurde und alle seine Partitionen erstellt wurden, kann er so verarbeitet werden, dass er sichtbar ist. Die Verarbeitung eines Cubes ist der letzte Schritt nach den ETL-Läufen (Extrahieren, Transformieren, Laden). Diese Schritte erfolgen wie folgt:
- Extrahieren: Extrahieren von Daten aus dem Quellsystem
- Transformieren: Anwenden von Funktionen, um Daten an ein Standard-Dimensionsschema anzupassen
- Daten laden: Daten in den Data Mart zur Nutzung laden
- Prozess: Laden der Daten aus dem Data Mart in den OLAP-Cube zum Durchsuchen
Die Verarbeitung eines OLAP-Cubes erfolgt, wenn alle Aggregationen für den Cube berechnet werden und der Cube mit diesen Aggregationen und Daten geladen wird. Dimensions- und Faktentabellen werden gelesen, und die Daten werden berechnet und in den Cube geladen. Wenn Sie einen OLAP-Cube entwerfen, muss die Verarbeitung sorgfältig bedacht werden, da sie in einer Produktionsumgebung, in der Millionen von Datensätzen vorhanden sein können, möglicherweise erhebliche Auswirkungen hat. Ein vollständiger Prozess aller Partitionen in einer solchen Umgebung kann von Tagen bis zu Wochen dauern, wodurch die Service Manager-Infrastruktur und Cubes für Endbenutzende unbrauchbar werden können. Eine Empfehlung besteht darin, den Verarbeitungszeitplan aller Cubes zu deaktivieren, die nicht verwendet werden, um den Aufwand für das System zu verringern.
Die OLAP-Cubeverarbeitung besteht aus zwei separaten Aufgaben:
- Dimensionsverarbeitung
- Partitionsverarbeitung
Jeder OLAP-Cube verfügt über einen entsprechenden Verarbeitungsauftrag in der Service Manager-Konsole und wird in einem benutzerdefinierten Zeitplan ausgeführt. Die einzelnen Verarbeitungsaufgaben werden in den folgenden Abschnitten beschrieben.
Dimensionsverarbeitung
Immer wenn der SQL Server Analysis Server (SSAS)-Datenbank eine neue Dimension hinzugefügt wird, muss ein vollständiger Prozess für die Dimension ausgeführt werden, um sie in einen vollständig verarbeiteten Zustand zu bringen. Nachdem eine Dimension verarbeitet wurde, gibt es jedoch keine Garantie dafür, dass sie erneut verarbeitet wird, wenn ein anderer Cube, der auf dieselbe Dimension abzielt, verarbeitet wird. Durch das Nicht-Automatische Neuprozessieren der Dimension wird verhindert, dass der Service Manager jede Dimension für jeden Cube neu verarbeitet. Dies gilt insbesondere dann, wenn die Dimension kürzlich verarbeitet wurde, da es unwahrscheinlich ist, dass neue Daten vorliegen, die noch nicht verarbeitet wurden. Zur Optimierung der Verarbeitungseffizienz gibt es eine Singleton-Klasse, die im Management Pack „Microsoft.SystemCenter.Datawarehouse.OLAP.Base“ definiert ist und den Namen „Microsoft.SystemCenter.Warehouse.Dimension.ProcessingInterval“ trägt. Nachfolgend finden Sie ein Beispiel für diese Klasse:
<!-- This singleton class defines the minimum interval of time in minutes that must elapse before a shared dimension is reprocessed. -->
<ClassType ID="Microsoft.SystemCenter.Warehouse.Dimension.ProcessingInterval" Accessibility="Public" Abstract="false" Base="AdminItem!System.AdminItem" Singleton="true">
<Property ID="IntervalInMinutes" Type="int" Required="true" DefaultValue="60"/>
</ClassType>
Diese Singleton-Klasse enthält eine Eigenschaft, IntervalInMinutes, die beschreibt, wie oft eine Dimension verarbeitet werden soll. Standardmäßig beträgt diese Eigenschaft 60 Minuten. Wenn beispielsweise eine Dimension um 15:05 Uhr verarbeitet wurde und ein anderer Cube, der auf dieselbe Dimension abzielt, um 15:45 Uhr verarbeitet wird, wird die Dimension nicht erneut verarbeitet. Ein Nachteil dieses Ansatzes ist die erhöhte Wahrscheinlichkeit von Fehlern bei den Dimensionsschlüsseln. Ein Wiederholungsmechanismus behandelt Fehler bei den Dimensionsschlüsseln, um die Dimension und dann die Würfelpartition neu zu verarbeiten. Weitere Informationen zu Verarbeitungsfehler finden Sie im Abschnitt „Häufige Probleme beim Debugging und bei der Problembehandlung“.
Nachdem eine Dimension vollständig verarbeitet wurde, wird eine inkrementelle Verarbeitung mit ProcessUpdate ausgeführt. ProcessFull wird nur dann ausgeführt, wenn sich ein Dimensionsschema ändert, da dies dazu führt, dass die Dimension in einen unverarbeiteten Zustand zurückkehrt. Denken Sie daran, dass, wenn ProcessFull auf einer Dimension ausgeführt wird, alle betroffenen Cubes und ihre Partitionen dann in einem unverarbeiteten Zustand vorliegen und bei der nächsten geplanten Ausführung vollständig verarbeitet werden müssen.
Partitionsverarbeitung
Die Verarbeitung von Partitionen muss sorgfältig abgewogen werden, da die erneute Verarbeitung einer großen Partition langsam ist und viele CPU-Ressourcen auf dem Server verbraucht, der SSAS hostet. Die Partitionsverarbeitung dauert in der Regel länger als die Dimensionsverarbeitung. Im Gegensatz zur Dimensionsverarbeitung hat die Verarbeitung einer Partition keine Nebenwirkungen auf andere Objekte. Die einzigen beiden Verarbeitungsarten, die auf System Center – Service Manager-OLAP-Cubes ausgeführt werden, sind ProcessFull und ProcessAdd.
Ähnlich wie bei Dimensionen erfordert das Erstellen neuer Partitionen in einem OLAP-Cube eine ProcessFull-Aufgabe, damit sich die Partition in einem Zustand befindet, in dem sie abgefragt werden kann. Da eine ProcessFull-Aufgabe ein teurer Vorgang ist, sollten Sie eine ProcessFull-Aufgabe nur bei Bedarf ausführen, z. B. wenn Sie eine Partition erstellen oder wenn eine Zeile aktualisiert wurde. In Szenarien, in denen Zeilen hinzugefügt und keine Zeilen aktualisiert wurden, kann Service Manager eine ProcessAdd-Aufgabe ausführen. Zu diesem Zweck verwendet Service Manager Wasserzeichen und andere Metadaten. Insbesondere werden die Tabellen „etl.cubepartition“ und „etl.tablepartition“ abgefragt, um zu bestimmen, welche Art von Verarbeitung durchgeführt werden soll.
Das folgende Diagramm veranschaulicht, wie Service Manager anhand der Wasserzeichendaten bestimmt, welche Art der Verarbeitung durchgeführt werden soll.
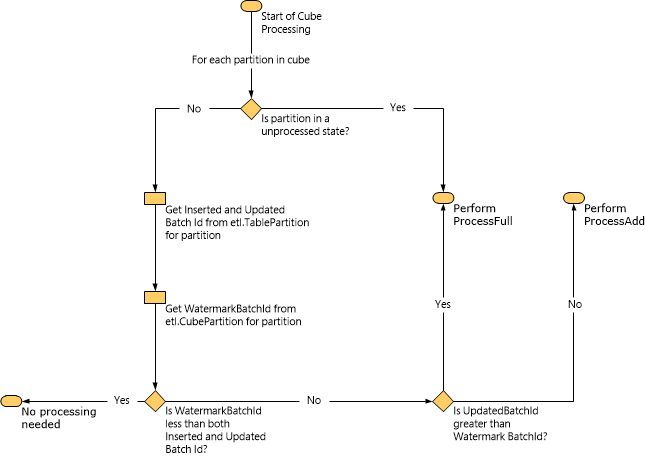
Wenn eine ProcessAdd-Aufgabe ausgeführt wird, schränkt Service Manager den Umfang der Abfrage mit Wasserzeichen ein. Wenn beispielsweise der Wert „InsertedBatchId“ 100 und der Wert „WatermarkBatchId“ 50 ist, lädt die Abfrage nur Daten aus dem Data Mart, in dem „InsertedBatchId“ größer als 50 und kleiner als 100 ist.
Schließlich ist es wichtig zu beachten, dass Service Manager die manuelle Verarbeitung von OLAP-Cubes mit SSAS oder Business Intelligence Development Studio nicht unterstützt. Bei der Verarbeitung von Cubes außerhalb der in System Center - Service Manager bereitgestellten Methoden, einschließlich der Service Manager-Konsole und der Service Manager-Cmdlets, werden die Wasserzeichentabellen nicht aktualisiert. Daher ist es möglich, dass Probleme mit der Datenintegrität auftreten können. Wenn Sie den Cube versehentlich manuell neu verarbeitet haben, besteht eine mögliche Problemumgehung darin, den OLAP-Cube manuell auf die gleiche Weise aufzuheben. Wenn Service Manager den Cube das nächste Mal verarbeitet, wird automatisch eine ProcessFull-Aufgabe ausgeführt, da sich die Partitionen in einem unverarbeiteten Zustand befinden. Dadurch werden alle Wasserzeichen und Metadaten korrekt aktualisiert, sodass mögliche Datenintegritätsprobleme behoben werden.
Verwalten von Service Manager-OLAP-Cubes
Die Informationen in den folgenden Abschnitten beschreiben Best Practices für die Wartung von OLAP-Cubes (analytische Onlineverarbeitung).
Regelmäßige Neuverarbeitung der Dimensionen von Analysis Services
Die Best Practices für SQL Server Analysis Services (SSAS) empfehlen, dass SSAS-Dimensionen regelmäßig vollständig verarbeitet werden sollten. Die vollständige Verarbeitung der Dimensionen erstellt Indizes neu und optimiert die Datenspeicherung multidimensionaler Daten, wodurch die Abfrage- und Cubeleistung verbessert wird, die im Laufe der Zeit beeinträchtigt werden kann. Dies ähnelt der regelmäßigen Defragmentierung einer Festplatte auf einem Computer.
Ein Nachteil der vollständigen Verarbeitung einer SSAS-Dimension besteht jedoch darin, dass alle betroffenen OLAP-Cubes unverarbeitet werden und ebenfalls vollständig verarbeitet werden müssen, um sie in den Zustand zurückzuversetzen, in dem Sie sie abfragen können. Der Service Manager verarbeitet SSAS-Dimensionen nicht explizit vollständig. Daher müssen Sie entscheiden, wann diese Wartungsaufgabe ausgeführt werden soll.
Überlegungen zum Arbeitsspeicher
Wenn Sie alle Vorgänge zur Extraktion, Transformation und zum Laden (ETL) von Datenlagern sowie OLAP-Cube-Funktionen auf einem Server ausführen, sollten Sie den Speicherbedarf des Betriebssystems, von Data Warehouse und von SSAS sorgfältig abwägen, um sicherzustellen, dass der Server alle datenintensiven Vorgänge, die gleichzeitig ausgeführt werden können, bewältigen kann. Dies ist besonders wichtig, da die Verarbeitung von OLAP-Cubes ein speicherintensiver Vorgang ist.