Verwalten von „Direkte Speicherplätze“ in VMM
Wichtig
Diese Version von Virtual Machine Manager (VMM) hat das Ende des Supports erreicht. Es wird empfohlen, ein Upgrade auf VMM 2022 durchzuführen.
Dieser Artikel bietet eine Übersicht über „Direkte Speicherplätze“ (Storage Spaces Direct, S2D) und deren Bereitstellung im Fabric von System Center – Virtual Machine Manager (VMM).
Windows Server 2016 bietet erstmals „Direkte Speicherplätze“ (Storage Spaces Direct, S2D). Physische Speicherlaufwerke werden in virtuelle Speicherpools gruppiert, um virtualisierten Speicher bereitzustellen. Mit virtualisiertem Speicher haben Sie folgende Möglichkeiten:
- Mehrere physische Speicherquellen als eine einzige virtuelle Einheit verwalten.
- Preiswerten Speicher mit oder ohne externe Speichergeräte erhalten.
- Verschiedene Speichertypen in einem einzigen virtuellen Speicherpool sammeln.
- Speicher ganz leicht bereitstellen und virtualisierten Speicher nach Bedarf erweitern, indem Sie neue Datenträger hinzufügen.
Hinweis
VMM 2019 UR3 und höher unterstützt die Azure Stack Hyperkonvergente Infrastruktur (HCI, Version 20H2).
Hinweis
VMM 2022 unterstützt die hyperkonvergierte Infrastruktur (HCI, Version 20H2 und 21H2) von Azure Stack.
Wie funktioniert dies?
S2D erstellt Speicherpools aus dem Speicher, der bestimmten Knoten in einem Windows Server-Cluster zugeordnet ist. Der Speicher kann auf den Knoten- oder Datenträgergeräten, die direkt an einen einzelnen Knoten angefügt sind, intern sein. Unterstützte Speicherdatenträger sind unter anderem NVMe, SSD (über SATA oder SAS verbunden) und HDD. Weitere Informationen
- Wenn Sie S2D in einem Windows Server-Cluster aktivieren, ermittelt S2D automatisch den berechtigten Speicher und fügt ihn einem Speicherpool für den Cluster hinzu.
- S2D erstellt außerdem einen eingebauten serverseitigen Zwischenspeicher, um die Leistung zu erhöhen. Die schnellsten Laufwerke werden für die Zwischenspeicherung und die übrigen Laufwerke für die Kapazität verwendet. Weitere Informationen zum Zwischenspeicher.
- Sie erstellen Volumes aus einem Speicherpool. Beim Erstellen eines Volumes wird der virtuelle Datenträger (Speicherplatz) erstellt, partitioniert und formatiert, dem Cluster hinzugefügt und in ein freigegebenes Clustervolume (CSV) konvertiert.
- Sie können für ein Volume verschiedene Fehlertoleranzebenen konfigurieren, um anzugeben, wie virtuelle Datenträger auf die physischen Datenträger im Pool mit SMB 3.0 aufgeteilt werden. Sie können ein Volume ohne Resilienz oder mit Spiegel oder Paritätsresilienz konfigurieren. Weitere Informationen
Konvergente und nicht konvergente Bereitstellung
Ein Cluster, auf dem S2D ausgeführt wird, kann auf verschiedene Arten bereitgestellt werden:
- Hyperkonvergente Bereitstellung: Hyper-V und S2D-Speicher werden ohne Trennung auf demselben Cluster ausgeführt. Dies ermöglicht eine gleichzeitige Skalierung der Computer- und Speicherressourcen.
- Disaggregierte Bereitstellung: Computeressourcen werden auf einem Hyper-V-Cluster ausgeführt. S2D-Speicher wird auf einem anderen Cluster ausgeführt. Sie können die Cluster für eine besser abgestimmte Verwaltung getrennt skalieren.
Hyperkonvergente Bereitstellung
Hier sehen Sie eine Darstellung für die hyperkonvergente Bereitstellung
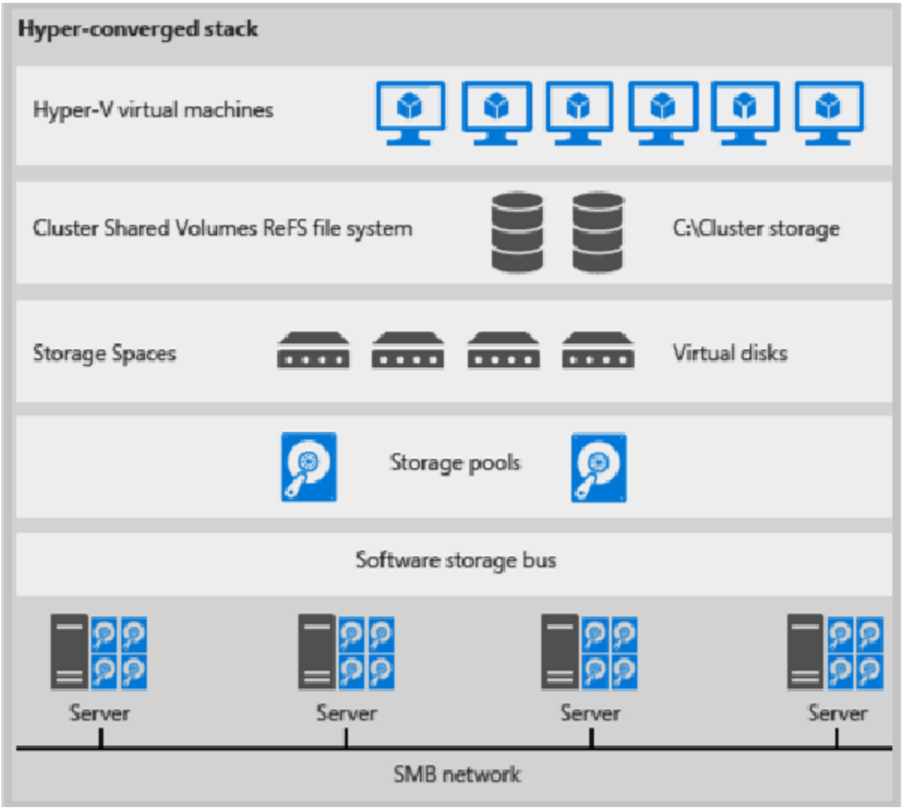
Abbildung 1: Hyperkonvergente Bereitstellung
- Die Dateien virtueller Computer werden auf lokalen CSVs gespeichert.
- Freigegebene Dateien und SMB werden nicht verwendet.
- Wenn CSV-Volumes von S2D zur Verfügung stehen, können Sie diese genau wie jede andere Hyper-V-Bereitstellung bereitstellen.
- Sie skalieren den Hyper-V-Computecluster zusammen mit dessen S2D-Speicher.
Disaggregierte Bereitstellung
Hier sehen Sie eine Darstellung für die disaggregierte Bereitstellung
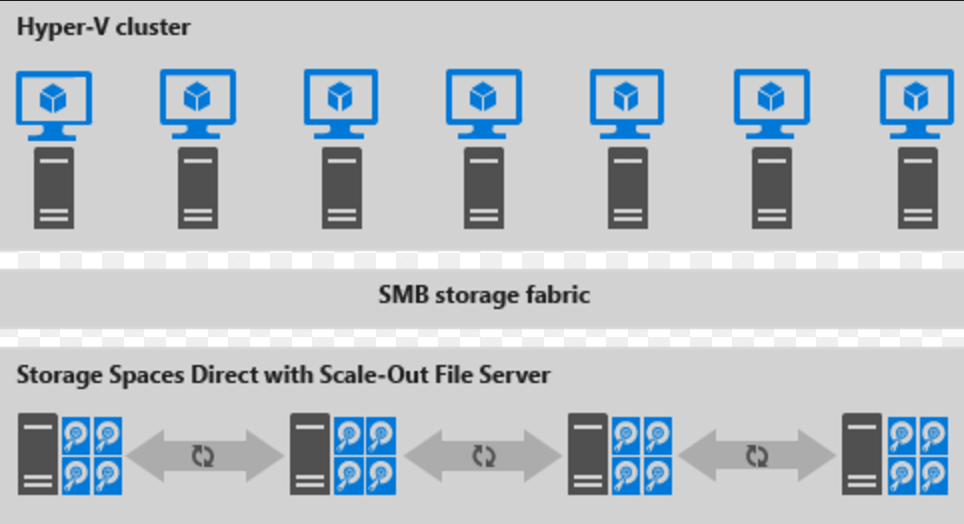
Abbildung 2: Disaggregierte Bereitstellung
- Freigegebene Dateien werden in den CSVs von S2D erstellt.
- Hyper-V-VMs werden so konfiguriert, dass sie ihre Dateien auf dem dateiskalierten Dateiserver (Scaled-Out File Server, SOFS) speichern und mit SMB 3.0 darauf zugreifen.
- Sie können die Hyper-V- und SOFS-Cluster für eine besser abgestimmte Verwaltung getrennt skalieren. Beispielsweise können Computeknoten für viele VMs nahezu voll ausgelastet sein, aber Speicherknoten verfügen möglicherweise über eine übermäßig hohe Datenträger- und IOPS-Kapazität. Daher fügen Sie nur weitere Computeknoten hinzu.
Nächste Schritte
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für