Wiederherstellung
Die Unterteilung des Lebenszyklus der Reaktion auf Vorfälle in fünf Phasen, wie Sie es in diesem Modul gesehen haben, hilft Ihnen, den Prozess zu verstehen, aber die Phasen sind nicht immer so eindeutig, wie sie im Diagramm erscheinen. Insbesondere ist der Übergang zwischen der Response- und Behebungsphase oft fließend. Dies trifft vor allem dann zu, wenn Maßnahmen zur Entschärfung oder Verbesserung der Situation den gegenteiligen Effekt haben. In diesem Fall überlappen sich die Phasen der Response und Behebung oder es wird zwischen den Phasen hin und her gesprungen.
In dieser Lektion erfahren Sie mehr über die Behebung sowie die einzelnen Schritte dieser Phase und bekommen einige hilfreiche Tipps und Tools an die Hand. Ein wichtiger Hinweis: Sie sollten die hier skizzierten Maßnahmen nicht als verbindliche Checkliste betrachten.
Wenn Sie tatsächlich bereits eine Checkliste für die Maßnahmen zur Behebung vorliegen haben, ist das oft ein Hinweis darauf, dass es Zeit ist, eine Automatisierung in Betracht zu ziehen. Wenn Sie genau beschreiben können, was in welcher Reihenfolge getan werden muss, um ein Problem zu beheben, ist es der perfekte Zeitpunkt, um diese Schritte einem Computer beizubringen, damit das System sie für Sie erledigt.
Erste Schritte
Sie haben gelernt, wie wichtig es ist, die Zeit zum Einleiten einer Response für einen Incident zu verkürzen. Nun sehen wir uns einige Aspekte an, die dazu beitragen können, den Prozess der Behebung bzw. Lösung des Problems zu beschleunigen.
Verschiedene Teammitglieder haben möglicherweise unterschiedliche mentale Modelle, wie die Dinge funktionieren, und unterschiedliche Vorstellungen davon, was der erste Schritt sein sollte. Der eine sieht sich vielleicht zuerst die Protokolle an, während der andere zuerst Abfragen durchführt und sich die Metriken ansieht. Es gibt nicht nur einen Weg zum Ziel.
Es hilft jedoch, Mitarbeitern Menschen einen Kontext und eine Anleitung bereitzustellen, damit sie wissen, wie sie vorgehen und was sie sich ansehen sollten.
Wie und an wen eskaliert wird
Es gibt eine wichtige Frage, die Sie bei der Formulierung Ihres Ausgangspunkts für die Problembehebung beantworten müssen: An wen können Sie sich wenden, um das Problem zu eskalieren, wenn Sie nicht weiterkommen? Sie sollten versuchen, dem Team allgemein mehr Verantwortung für die Rufbereitschaft zu übertragen, und nicht nur für Operations oder Site Reliability Engineering. Es sollte in der Verantwortung aller Teammitglieder liegen, die Systeme einsatzbereit zu halten, um Ihre Vorgaben in Hinblick auf Zuverlässigkeit zu erreichen.
Welche Ressourcen sind für die Ersthelfer hilfreich?
Die nächste Überlegung ist, die Maßnahmen festzulegen, mit denen die Ersthelfer den Prozess in Gang setzen können. Hierzu könnten relevante Metriken, Protokolle, Abfragen usw. gehören. Diese sollten möglichst in einer Azure-Arbeitsmappe oder in einem Leitfaden zur Problembehebung bereitgestellt werden. Wir werden gleich über sie sprechen.
Es ist auch nützlich, einfache Links zu Ressourcen bereitzustellen (oft in einer Führungslinie zur Problembehebung). Wenn Sie so schnell wie möglich eine Response einleiten und das Problem beheben möchten, können Sie den Prozess beschleunigen. Helfen Sie hierzu den Betreffenden, Antworten auf Fragen zu finden, ohne nach dem richtigen Dokument oder der entsprechenden URL suchen zu müssen.
Beteiligte auf dem Laufenden halten
Sie können sich so sehr auf die Behebung des Problems konzentrieren, dass Sie vergessen, dass es viele Menschen gibt, die nicht direkt an der Reaktion auf den Vorfall beteiligt sind, die aber wissen wollen und müssen, was vor sich geht.
Es ist wichtig, mit anderen internen Teams zu kommunizieren und sie über den Stand der Dinge auf dem Laufenden zu halten, wenn sich ein Vorfall ereignet. Wenn Sie diese nicht regelmäßig auf dem Laufenden halten, werden sie wahrscheinlich nach einem Status-Update fragen. Sie haben jedes Recht auf diese Informationen, aber Sie brauchen einen besseren Weg, um sie auf das Problem (Issue) aufmerksam zu machen und darauf, was dagegen unternommen wird.
Sie müssen eine klare Botschaft an Ihre internen Teams senden. Präsentieren Sie klar und deutlich, was Sie wissen und was getan wird, und setzen Sie Erwartungen in Bezug darauf, wann man von Ihnen hören wird.
Die Formel für Ihre Kommunikation mit den Beteiligten ist einfach:
- Das wissen wir.
- Das tun wir gerade.
- Wir melden uns zum Zeitpunkt X wieder bei Ihnen.
Dadurch wird verhindert, dass Sie von Beteiligten immer wieder unterbrochen werden, wenn Sie gerade dabei sind, die Probleme zu lösen.
Eine Möglichkeit, derartige Informationen weiterzugeben, ist eine leicht zu bearbeitende Statuswebseite, wie wir sie in der letzten Lerneinheit erwähnt haben. In vielen Fällen möchten Sie vielleicht eine separate, detailliertere Statusseite für interne Beteiligte und eine externe Seite für Ihre Kunden haben. Die vorangehende Formel funktioniert für beide Fälle.
Verwenden von Azure Monitor-Arbeitsmappen und Leitfäden zur Problembehandlung
Azure verfügt über zwei eng miteinander verbundene Features, die für ein Team in der Behebungsphase enorm hilfreich sein können: Azure Monitor-Arbeitsmappen und Leitfäden zur Problembehandlung von Application Insights. Für die Zwecke dieses Moduls sind sie austauschbar und haben auch die gleiche Benutzeroberfläche. Sie finden Azure Monitor-Arbeitsmappen im Azure-Portal unter Azure Monitor. Sie finden Azure Insights-Anleitungen zur Problembehandlung im Azure-Portal, wenn eine Applications Insight-Instanz ausgewählt wurde.
Sie können sich Arbeitsmappen und Anleitungen zur Fehlerbehebung als „Live-Dokumente" vorstellen, die Sie über eine Schnittstelle zur Seitenerstellung erstellen können. Wenn Sie eine neue erstellen, können Sie zu der Seite Folgendes hinzufügen:
- Beliebiger Text, z. B. eine Aufzählung von Aufgaben oder andere hilfreiche Informationen für jemanden, der die Seite besucht
- Links zu anderen Systemen, zum Beispiel Links zu anderen Dashboards oder Dokumentationen
- Abfragen in der Kusto-Abfragesprache (KQL)
Dies ist das letzte Element, durch das Sie schließlich ein „Live-Dokument“ erhalten. In einem früheren Modul in diesem Lernpfad haben wir uns mit der in Log Analytics und anderen Teilen von Azure Monitor integrierten KQL-Abfragesprache befasst. Mit dieser Sprache könnten wir unsere eigenen Abfragen schreiben, um Diagnoseinformationen aus unserer Anwendung und Azure-Infrastruktur zurückzugeben und anzuzeigen. Wenn eine KQL-Abfrage in eine Arbeitsmappe oder eine Anleitung zur Fehlerbehebung eingefügt wird, werden die aktuellen Ergebnisse dieser Abfrage für die Leser des Dokuments live angezeigt. Das bedeutet, dass Ihr Leitfaden zur Problembehebung nicht nur den Hinweis „Beachten Sie die Fehlerrate auf dem Webserver“ enthalten kann, sondern auch ein aktuelles Diagramm zu dieser Fehlerrate direkt neben den Anweisungen anzeigen kann. Es kann über einen Link wie „Die Dokumentation zum Neustart des Webservers finden Sie hier“ verfügen, der den Ersthelfer direkt zu der von ihm benötigten Dokumentation führt.
Zudem finden Sie in Azure einige vorgefertigte Vorlagen, die Ihnen den Einstieg in die Erstellung eigener Dokumente erleichtern. Im folgenden Screenshot sehen Sie einige der vorgefertigten Vorlagen, die Ihnen eventuell angeboten werden:
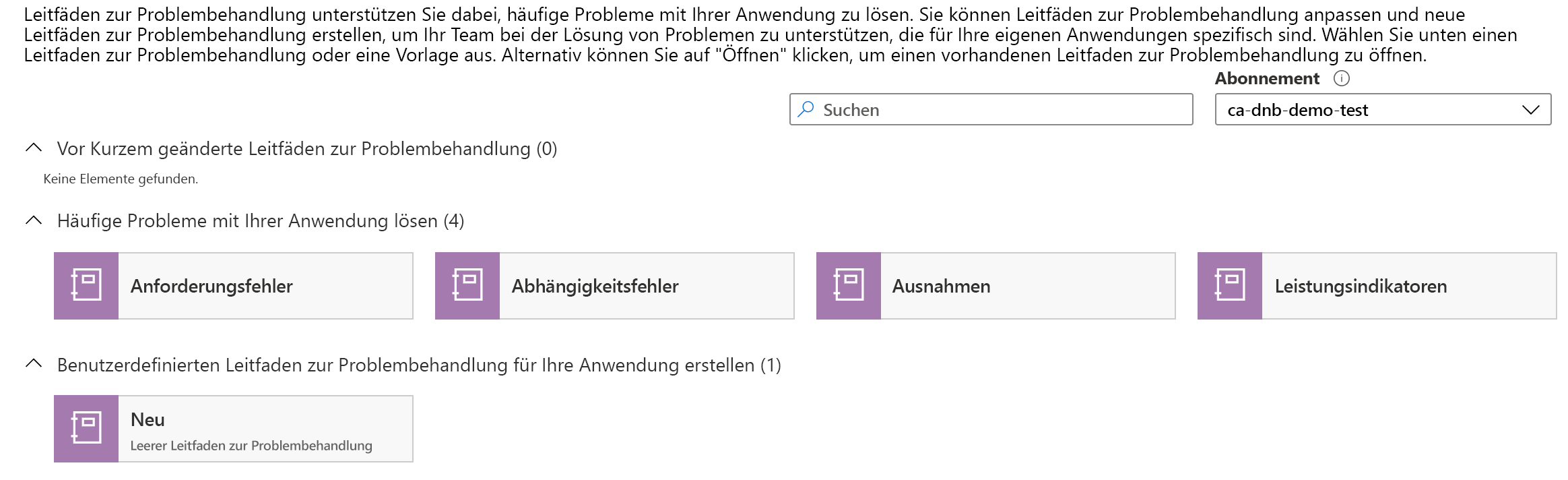
Außerdem gibt es die Funktion Erweiterter Editor für Arbeitsmappen und Führungslinien zur Problembehebung, mit der Sie entweder auf eine JSON- oder eine Azure Resource Manager-Vorlagendarstellung dieses Dokuments zugreifen und diese einfügen können. Das bedeutet, dass Sie diese Dokumente mit dem Quellkontrollsystem Ihrer Wahl nachverfolgen und verteilen können. Außerdem können Sie damit die Bereitstellung von Arbeitsmappen oder Anleitungen zur Fehlerbehebung automatisieren, was bei der Bereitstellung anderer Infrastrukturen nützlich ist. Die Erstellung mehrerer benutzerdefinierter Dokumente zur Problembehebung, die bei der Bereitstellung eines neuen Diensts erforderlich sind, wird mit dieser bewährten Vorgehensweise vereinfacht.
Weitere hilfreiche Tipps und Tools
In diesem Modul haben Sie die verschiedenen Tools und Abkürzungen kennengelernt, mit denen Sie die Effizienz steigern und die Reaktionszeit auf Vorfälle verkürzen können. Zum Abschluss dieser letzten Lektion werden wir einen kurzen Überblick über einige Tools und Techniken geben, die bei der Diagnose von Problemen in Ihren Systemen hilfreich sind.
- Sie können den Link „Anwendungsdashboard“ in Application Insights verwenden, um automatisch ein Dashboard zu erstellen, das die meisten der wichtigsten Elemente enthält, die Sie als Ausgangspunkt benötigen. Beachten Sie, dass dies nicht Azure Service Health beinhaltet. Diese Anwendung sollten Sie an Ihr Dashboard anheften, damit Sie überprüfen können, ob das Problem mit Ihren Systemen oder mit dem Clouddienst selbst zusammenhängt.
- Mit der Anwendungsübersicht in Application Insights können Sie genau untersuchen, was die Ursache für die Probleme ist. Sie können den Breadcrumbs folgen, um die Ursache des Fehlers zu finden (z. B. eine fehlerhafte URL).
- Sie können Log Analytics verwenden, um einen beliebigen Teil des Systems abzufragen.
Alle oben genannten Tools sind bei der Behebung von Problemen von unschätzbarem Wert.