Ereignisse
29. Apr., 14 Uhr - 30. Apr., 19 Uhr
Nehmen Sie am ultimativen virtuellen Windows Server-Ereignis vom 29. bis 30. April teil, um technische Deep-Dive-Sitzungen und Live-Q&A mit Microsoft-Technikern zu erhalten.
Jetzt anmeldenDieser Browser wird nicht mehr unterstützt.
Führen Sie ein Upgrade auf Microsoft Edge durch, um die neuesten Features, Sicherheitsupdates und den technischen Support zu nutzen.
Verwenden Sie die folgenden Informationen, um Probleme bei Ihrer Bereitstellung von „Direkte Speicherplätze“ zu beheben.
Im Allgemeinen beginnen Sie mit den folgenden Schritten:
Wenn weiterhin Probleme auftreten, lesen Sie die Informationen zur Problembehandlung für die einzelnen Probleme in diesem Artikel.
Die Knoten eines „Direkte Speicherplätze“-Systems werden aufgrund eines Absturzes oder Stromausfalls unerwartet neu gestartet. Anschließend werden ein oder mehrere virtuelle Datenträger möglicherweise nicht online geschaltet, und die Beschreibung „Nicht genügend Redundanzinformationen“ wird angezeigt.
| FriendlyName | ResiliencySettingName | OperationalStatus | HealthStatus | IsManualAttach | Size | PSComputerName |
|---|---|---|---|---|---|---|
| Disk4 | Spiegel | OK | Healthy | True | 10 TB | Node-01.conto... |
| Disk3 | Spiegel | OK | Healthy | True | 10 TB | Node-01.conto... |
| Disk2 | Spiegel | No Redundancy | Fehlerhaft | True | 10 TB | Node-01.conto... |
| Disk1 | Spiegel | {No Redundancy, InService} | Fehlerhaft | True | 10 TB | Node-01.conto... |
Zusätzlich werden nach dem Versuch, den virtuellen Datenträger online zu schalten, die folgenden Informationen im Clusterprotokoll (DiskRecoveryAction) erfasst.
[Verbose] 00002904.00001040::YYYY/MM/DD-12:03:44.891 INFO [RES] Physical Disk <DiskName>: OnlineThread: SuGetSpace returned 0.
[Verbose] 00002904.00001040:: YYYY/MM/DD -12:03:44.891 WARN [RES] Physical Disk < DiskName>: Underlying virtual disk is in 'no redundancy' state; its volume(s) may fail to mount.
[Verbose] 00002904.00001040:: YYYY/MM/DD -12:03:44.891 ERR [RES] Physical Disk <DiskName>: Failing online due to virtual disk in 'no redundancy' state. If you would like to attempt to online the disk anyway, first set this resource's private property 'DiskRecoveryAction' to 1. We will try to bring the disk online for recovery, but even if successful, its volume(s) or CSV may be unavailable.
Der Betriebsstatus „Keine Redundanz“ kann auftreten, wenn ein Datenträger ausgefallen ist oder das System nicht auf Daten auf dem virtuellen Datenträger zugreifen kann. Dieses Problem kann auftreten, wenn während einer Wartung der Knoten ein Neustart auf einem Knoten stattfindet.
Zur Behebung dieses Problems führen Sie die folgenden Schritte aus:
Entfernen Sie die betroffenen virtuellen Datenträger aus dem CSV. Dadurch werden sie in der verfügbaren Speichergruppe im Cluster platziert und als ResourceType von Physical Diskangezeigt.
Remove-ClusterSharedVolume -Name "CSV Name"
Führen Sie auf dem Knoten, der die Gruppe „Verfügbarer Speicher“ besitzt, den folgenden Befehl auf jedem Datenträger mit dem Status „Keine Redundanz“ aus. Um zu ermitteln, auf welchem Knoten sich die Gruppe „Verfügbarer Speicher“ befindet, können Sie den folgenden Befehl ausführen.
Get-ClusterGroup
Legen Sie die Aktion zur Datenträgerwiederherstellung fest, und starten Sie dann die Datenträger.
Get-ClusterResource "Physical Disk Resource Name" | Set-ClusterParameter -Name DiskRecoveryAction -Value 1
Start-ClusterResource -Name "Physical Disk Resource Name"
Es sollte automatisch eine Reparatur gestartet werden. Warten Sie, bis die Reparatur abgeschlossen ist. Möglicherweise wechselt sie in den angehaltenen Zustand und wird erneut gestartet. Überwachen Sie den Fortschritt wie folgt:
Nachdem die Reparatur abgeschlossen ist und die virtuellen Datenträger fehlerfrei sind, ändern Sie die Parameter des virtuellen Datenträgers wieder.
Get-ClusterResource "Physical Disk Resource Name" | Set-ClusterParameter -Name DiskRecoveryAction -Value 0
Schalten Sie die Datenträger offline und dann wieder online, damit die Aktion zur Datenträgerwiederherstellung (DiskRecoveryAction) in Kraft tritt:
Stop-ClusterResource "Physical Disk Resource Name"
Start-ClusterResource "Physical Disk Resource Name"
Fügen Sie die betroffenen virtuellen Datenträger wieder zum CSV hinzu.
Add-ClusterSharedVolume -Name "Physical Disk Resource Name"
DiskRecoveryAction ist ein Außerkraftsetzungsschalter, der das Anfügen des Speicherplatzvolumes im Lese-/Schreibmodus ohne Überprüfungen ermöglicht. Mit der Eigenschaft können Sie diagnostizieren, warum ein Volume nicht online verfügbar ist. Dies ähnelt dem Wartungsmodus, doch kann sie für eine Ressource im Fehlerstatus aufgerufen werden. Außerdem können Sie auf die Daten zugreifen, damit Sie sie kopieren können. Dieser Zugriff ist in Nichtredundanzsituationen hilfreich. Die Eigenschaft „DiskRecoveryAction“ wurde im Update vom 22. Februar 2018 (KB 4077525) hinzugefügt.
Wenn Sie das Cmdlet Get-VirtualDiskGet-VirtualDiskOperationalStatus ausführen, lautet der Betriebsstatus (OperationalStatus) für einen oder mehrere virtuelle „Direkte Speicherplätze“-Datenträger „Detached“ (Getrennt). Der vom Cmdlet Get-PhysicalDisk gemeldete Integritätsstatus (HealthStatus) gibt jedoch an, dass sich alle physischen Datenträger im fehlerfreien Zustand befinden.
Dieses Beispiel zeigt die Ausgabe des Get-VirtualDisk Cmdlets.
| FriendlyName | ResiliencySettingName | OperationalStatus | HealthStatus | IsManualAttach | Size | PSComputerName |
|---|---|---|---|---|---|---|
| Disk4 | Spiegel | OK | Healthy | True | 10 TB | Node-01.conto... |
| Disk3 | Spiegel | OK | Healthy | True | 10 TB | Node-01.conto... |
| Disk2 | Spiegel | Getrennt | Unbekannt | True | 10 TB | Node-01.conto... |
| Disk1 | Spiegel | Getrennt | Unbekannt | True | 10 TB | Node-01.conto... |
Zusätzlich können die folgenden Ereignisse auf den Knoten protokolliert werden:
Log Name: Microsoft-Windows-StorageSpaces-Driver/Operational
Source: Microsoft-Windows-StorageSpaces-Driver
Event ID: 311
Level: Error
User: SYSTEM
Computer: Node#.contoso.local
Description: Virtual disk {GUID} requires a data integrity scan.
Data on the disk is out-of-sync and a data integrity scan is required.
To start the scan, run this command:
Get-ScheduledTask -TaskName "Data Integrity Scan for Crash Recovery" | Start-ScheduledTask
Once you have resolved that condition, you can online the disk by using these commands in PowerShell:
Get-VirtualDisk | ?{ $_.ObjectId -Match "{GUID}" } | Get-Disk | Set-Disk -IsReadOnly $false
Get-VirtualDisk | ?{ $_.ObjectId -Match "{GUID}" } | Get-Disk | Set-Disk -IsOffline $false
------------------------------------------------------------
Log Name: System
Source: Microsoft-Windows-ReFS
Event ID: 134
Level: Error
User: SYSTEM
Computer: Node#.contoso.local
Description: The file system was unable to write metadata to the media backing volume <VolumeId>. A write failed with status "A device which does not exist was specified." ReFS will take the volume offline. It might be mounted again automatically.
------------------------------------------------------------
Log Name: Microsoft-Windows-ReFS/Operational
Source: Microsoft-Windows-ReFS
Event ID: 5
Level: Error
User: SYSTEM
Computer: Node#.contoso.local
Description: ReFS failed to mount the volume.
Context: 0xffffbb89f53f4180
Error: A device which does not exist was specified.
Volume GUID:{00000000-0000-0000-0000-000000000000}
DeviceName:
Volume Name:
Dies Detached Operational Status tritt auf, wenn das DRT-Protokoll (Dirty Region Tracking) voll ist. Speicherplätze verwenden DRT (Dirty Region Tracking) für gespiegelte Räume, um sicherzustellen, dass beim Auftreten eines Stromausfalls alle In-Flight-Updates für Metadaten protokolliert werden. Protokollierte Updates stellen sicher, dass der Speicherplatz Vorgänge wiederholen oder rückgängig machen kann. Sie geben den Speicherplatz nach der Wiederherstellung des Stroms in einen flexiblen und konsistenten Zustand zurück, und das System wird wieder aufgenommen. Wenn das DRT-Protokoll voll ist, kann der virtuelle Datenträger erst nach dem Synchronisieren und Leeren der DRT-Metadaten online geschaltet werden. Dieser Prozess erfordert eine vollständige Überprüfung, die mehrere Stunden dauern kann.
Zur Behebung dieses Problems führen Sie die folgenden Schritte aus:
Entfernen Sie die betroffenen virtuellen Datenträger aus dem CSV.
Remove-ClusterSharedVolume -Name "CSV Name"
Führen Sie die folgenden Befehle auf jedem Datenträger aus, der nicht online geschaltet wird.
Get-ClusterResource -Name "Physical Disk Resource Name" | Set-ClusterParameter DiskRunChkDsk 7
Start-ClusterResource -Name "Physical Disk Resource Name"
Führen Sie den folgenden Befehl auf jedem Knoten aus, auf dem das getrennte Volume online ist.
Get-ScheduledTask -TaskName "Data Integrity Scan for Crash Recovery" | Start-ScheduledTask
Dieser Task sollte auf allen Knoten initiiert werden, auf denen das getrennte Volume online ist. Es sollte automatisch eine Reparatur gestartet werden. Warten Sie, bis die Reparatur abgeschlossen ist. Möglicherweise wechselt sie in den angehaltenen Zustand und wird erneut gestartet. Überwachen Sie den Fortschritt wie folgt:
Die Datenintegritätsüberprüfung für die Wiederherstellung nach Systemabsturz (Data Integrity Scan for Crash Recovery) ist ein Task, der nicht als Speicherauftrag angezeigt wird, und es erfolgt keine Statusanzeige. Wenn der Task als ausgeführt angezeigt wird, wird er ausgeführt. Wenn er abgeschlossen ist, wird er als abgeschlossen angezeigt.
Zusätzlich können Sie den Status eines ausgeführten Zeitplantasks mithilfe des folgenden Cmdlets anzeigen:
Get-ScheduledTask | ? State -eq running
Nachdem die Datenintegritätsüberprüfung für die Absturzwiederherstellung abgeschlossen ist, ist die Reparatur abgeschlossen, und die virtuellen Datenträger sind fehlerfrei. Ändern Sie die Parameter für virtuelle Datenträger wieder.
Get-ClusterResource -Name "Physical Disk Resource Name" | Set-ClusterParameter DiskRunChkDsk 0
Schalten Sie die Datenträger offline und dann wieder online, damit die Aktion zur Datenträgerwiederherstellung (DiskRecoveryAction) in Kraft tritt:
Stop-ClusterResource "Physical Disk Resource Name"
Start-ClusterResource "Physical Disk Resource Name"
Fügen Sie die betroffenen virtuellen Datenträger wieder zum CSV hinzu.
Add-ClusterSharedVolume -Name "Physical Disk Resource Name"
Wird DiskRunChkdsk value 7 verwendet, um das Space-Volume anzufügen und die Partition auf den schreibgeschützten Modus festzulegen. Dadurch können Speicherplätze durch Auslösen einer Reparatur eine Selbsterkennung und Selbstinstandsetzung auszuführen. Die Reparatur wird nach der Einbindung automatisch ausgeführt. Außerdem können Sie auf die Daten zugreifen, um sie zu kopieren. Bei einigen Fehlerbedingungen, z. B. einem vollen DRT-Protokoll, müssen Sie den geplanten Task zur Datenintegritätsüberprüfung für die Wiederherstellung nach Systemabsturz (Data Integrity Scan for Crash Recovery) ausführen.
Der Task zur Datenintegritätsüberprüfung für die Wiederherstellung nach Systemabsturz (Data Integrity Scan for Crash Recovery) wird verwendet, um ein volles DRT-Protokoll (Dirty Region Tracking) zu synchronisieren und zu löschen. Dieser Task kann mehrere Stunden dauern. Die Datenintegritätsüberprüfung für die Wiederherstellung nach Systemabsturz (Data Integrity Scan for Crash Recovery) ist ein Task, der nicht als Speicherauftrag angezeigt wird, und es erfolgt keine Statusanzeige. Wenn der Task als ausgeführt angezeigt wird, wird er ausgeführt. Wenn er abgeschlossen ist, wird er als abgeschlossen angezeigt. Wenn Sie den Task abbrechen oder einen Knoten neu starten, während dieser Task ausgeführt wird, muss der Task von Anfang an neu gestartet werden.
Weitere Informationen finden Sie unter Problembehandlung für Integritäts- und Betriebsstatus von „Direkte Speicherplätze“.
Wichtig
Für Windows Server 2016: Um die Wahrscheinlichkeit zu verringern, dass diese Symptome während des Updates mit dem Fix auftreten, wird das folgende Verfahren im Speicherwartungsmodus empfohlen, um das kumulative Update für Windows Server 2016 vom 18. Oktober 2018 oder eine höhere Version zu installieren, wenn auf den Knoten derzeit ein kumulatives Update für Windows Server 2016 installiert ist, das zwischen dem 8. Mai 2018 und dem 9. Oktober 2018 veröffentlicht wurde.
Möglicherweise wird Ereignis 5120 mit STATUS_IO_TIMEOUT c00000b5 ausgegeben, nachdem Sie einen Knoten unter Windows Server 2016 mit einem kumulativen Update, das zwischen dem 8. Mai 2018 (KB 4103723) und dem 9. Oktober 2018 (KB 4462917) veröffentlicht wurde, neu gestartet haben.
Beim Neustart des Knotens wird Ereignis 5120 im Systemereignisprotokoll erfasst und einer der folgenden Fehlercodes eingefügt:
Event Source: Microsoft-Windows-FailoverClustering
Event ID: 5120
Description: Cluster Shared Volume 'CSVName' ('Cluster Virtual Disk (CSVName)') has entered a paused state because of 'STATUS_IO_TIMEOUT(c00000b5)'. All I/O will temporarily be queued until a path to the volume is reestablished.
Cluster Shared Volume 'CSVName' ('Cluster Virtual Disk (CSVName)') has entered a paused state because of 'STATUS_CONNECTION_DISCONNECTED(c000020c)'. All I/O will temporarily be queued until a path to the volume is reestablished.
Bei der Protokollierung des Ereignisses 5120 wird ein Liveabbild generiert, um Debuginformationen zu sammeln, die möglicherweise zusätzliche Symptome verursachen oder sich auf die Leistung auswirken. Wenn das Liveabbild generiert wird, wird eine kurze Pause ausgelöst. Die Pause ermöglicht eine Momentaufnahme des Speichers, um die Speicherabbilddatei zu schreiben. Systeme mit viel Arbeitsspeicher und hoher Belastung können dazu führen, dass Knoten aus der Clustermitgliedschaft herausfallen und außerdem das folgende Ereignis 1135 protokolliert wird.
Event source: Microsoft-Windows-FailoverClustering
Event ID: 1135
Description: Cluster node 'NODENAME'was removed from the active failover cluster membership. The Cluster service on this node might have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapters on this node. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Am 8. Mai 2018 wurde eine Änderung in Windows Server 2016 eingeführt, bei der es sich um ein kumulatives Update zum Hinzufügen stabiler SMB-Handles für die clusterinternen SMB-Netzwerksitzungen von „Direkte Speicherplätze“ handelte. Dies geschah, um die Resilienz bei vorübergehenden Netzwerkausfällen und die Handhabung einer Netzwerküberlastung durch RoCE zu verbessern. Durch diese Verbesserungen wurden unbeabsichtigt auch die Timeouts erhöht, wenn SMB-Verbindungen versuchen, die Verbindung wiederherzustellen, und beim Neustart eines Knotens auf ein Timeout warten. Diese Probleme können sich auf ein System unter Belastung auswirken. Während ungeplanter Ausfallzeiten wurden auch E/A-Pausen von bis zu 60 Sekunden beobachtet, während das System auf das Timeout von Verbindungen wartet. Um dieses Problem zu beheben, installieren Sie das kumulative Update für Windows Server 2016 vom 18. Oktober 2018 oder eine neuere Version.
Hinweis
Hinweis Mit diesem Update werden zur Behebung des Problems die CSV-Timeouts an die Timeouts der SMB-Verbindungen angepasst. Es werden nicht die Änderungen zum Deaktivieren der Generierung von Liveabbildern implementiert, die im Abschnitt zur Problemumgehung beschrieben sind.
Führen Sie das Cmdlet „Get-VirtualDisk“ aus, und stellen Sie sicher, dass der Integritätsstatus (HealthStatus) den Wert „Healthy“ aufweist.
Entwässern Sie den Knoten, indem Sie dieses Cmdlet ausführen:
Suspend-ClusterNode -Drain
Setzen Sie die Datenträger auf diesem Knoten in den Speicherwartungsmodus, indem Sie das folgende Cmdlet ausführen:
Get-StorageFaultDomain -Type StorageScaleUnit | Where-Object {$_.FriendlyName -eq "<NodeName>"} | Enable-StorageMaintenanceMode
Führen Sie das Get-PhysicalDisk Cmdlet aus, und stellen Sie sicher, dass der OperationalStatus Wert modus ist In Maintenance .
Führen Sie das Restart-Computer Cmdlet aus, um den Knoten neu zu starten.
Nachdem der Knoten neu gestartet wurde, entfernen Sie die Datenträger auf diesem Knoten aus dem Speicherwartungsmodus, indem Sie das folgende Cmdlet ausführen:
Get-StorageFaultDomain -Type StorageScaleUnit | Where-Object {$_.FriendlyName -eq "<NodeName>"} | Disable-StorageMaintenanceMode
Setzen Sie die Ausführung des Knotens fort, indem Sie das folgende Cmdlet ausführen:
Resume-ClusterNode
Überprüfen Sie den Status der Neusynchronisierungsaufträge, indem Sie das folgende Cmdlet ausführen:
Get-StorageJob
Um die Auswirkungen der Generierung von Liveabbildern auf Systeme mit viel Arbeitsspeicher und hoher Belastung zu verringern, sollten Sie zusätzlich die Generierung von Liveabbildern deaktivieren. Diese drei Optionen werden bereitgestellt:
Achtung
Durch dieses Verfahren kann die Erfassung von Diagnoseinformationen verhindert werden, die der Microsoft-Support möglicherweise zur Untersuchung dieses Problems benötigt. Ein Support-Mitarbeiter muss Sie möglicherweise bitten, die Generierung von Liveabbildern basierend auf bestimmten Problembehandlungsszenarien erneut zu aktivieren.
Führen Sie die folgenden Schritte aus, um alle Speicherabbilder vollständig zu deaktivieren, einschließlich der systemweiten Liveabbilder: Verwenden Sie dieses Verfahren für dieses Szenario:
Hinweis
Sie müssen den Computer neu starten, damit die Registrierungsänderung in Kraft tritt.
Nachdem dieser Registrierungsschlüssel festgelegt wurde, tritt bei der Generierung von Liveabbildern der Fehler „STATUS_NOT_SUPPORTED“ auf.
Standardmäßig lässt die Windows-Fehlerberichterstattung nur ein Liveabbild pro Berichtstyp alle sieben Tage und nur ein Liveabbild pro Computer alle fünf Tage zu. Sie können dies ändern, indem Sie die folgenden Registrierungsschlüssel so festlegen, dass nur ein dauerhaftes Liveabbild auf dem Computer zulässig ist.
reg add "HKLM\Software\Microsoft\Windows\Windows Error Reporting\FullLiveKernelReports" /v SystemThrottleThreshold /t REG_DWORD /d 0xFFFFFFFF /f
reg add "HKLM\Software\Microsoft\Windows\Windows Error Reporting\FullLiveKernelReports" /v ComponentThrottleThreshold /t REG_DWORD /d 0xFFFFFFFF /f
Hinweis
Sie müssen den Computer neu starten, damit diese Änderungen wirksam werden.
Führen Sie das folgende Cmdlet aus, um die Clustergenerierung von Liveabbildern zu deaktivieren (z. B. wenn ein Ereignis 5120 protokolliert wird):
(Get-Cluster).DumpPolicy = ((Get-Cluster).DumpPolicy -Band 0xFFFFFFFFFFFFFFFE)
Dieses Cmdlet hat ohne Neustart des Computers sofortige Auswirkungen auf alle Clusterknoten.
Überprüfen Sie bei langsamer E/A-Leistung, ob der Cache in Ihrer Konfiguration von „Direkte Speicherplätze“ aktiviert ist.
Dies kann auf zwei Arten geprüft werden:
Verwenden der Clusterbenutzeroberfläche Öffnen Sie das Clusterprotokoll in einem Text-Editor Ihrer Wahl, und suchen Sie nach „[=== SBL Disks ===]“. Dies ist eine Liste der Datenträger auf dem Knoten, auf dem das Protokoll generiert wurde.
Beispiel für cachefähige Datenträger: Beachten Sie, dass der Zustand vorhanden ist CacheDiskStateInitializedAndBound und hier eine GUID vorhanden ist.
[=== SBL Disks ===]
{26e2e40f-a243-1196-49e3-8522f987df76},3,false,true,1,48,{1ff348f1-d10d-7a1a-d781-4734f4440481},CacheDiskStateInitializedAndBound,1,8087,54,false,false,HGST,HUH721010AL4200,7PG3N2ER,A21D,{d5e27a3b-42fb-410a-81c6-9d8cc12da20c},[R/M 0 R/U 0 R/T 0 W/M 0 W/U 0 W/T 0],
Cache nicht aktiviert: Hier sehen Sie, dass keine GUID vorhanden ist und der Status „CacheDiskStateNonHybrid“ lautet.
[=== SBL Disks ===]
{426f7f04-e975-fc9d-28fd-72a32f811b7d},12,false,true,1,24,{00000000-0000-0000-0000-000000000000},CacheDiskStateNonHybrid,0,0,0,false,false,HGST,HUH721010AL4200,7PGXXG6C,A21D,{d5e27a3b-42fb-410a-81c6-9d8cc12da20c},[R/M 0 R/U 0 R/T 0 W/M 0 W/U 0 W/T 0],
Cache nicht aktiviert: Wenn alle Datenträger vom selben Typ sind, ist der Cache nicht standardmäßig aktiviert. Hier sehen Sie, dass keine GUID vorhanden ist, und der Zustand ist CacheDiskStateIneligibleDataPartition.
{d543f90c-798b-d2fe-7f0a-cb226c77eeed},10,false,false,1,20,{00000000-0000-0000-0000-000000000000},CacheDiskStateIneligibleDataPartition,0,0,0,false,false,NVMe,INTEL SSDPE7KX02,PHLF7330004V2P0LGN,0170,{79b4d631-976f-4c94-a783-df950389fd38},[R/M 0 R/U 0 R/T 0 W/M 0 W/U 0 W/T 0],
Mithilfe von „Get-PhysicalDisk.xml“ aus „SDDCDiagnosticInfo“
ipmo storage.$d. Beachten Sie, dass die Verwendung "Automatisch auswählen" und nicht "Journal" ist.Daraufhin sollte eine Ausgabe ähnlich der folgenden angezeigt werden:
| FriendlyName | SerialNumber | MediaType | CanPool | OperationalStatus | HealthStatus | Verwendung | Size |
|---|---|---|---|---|---|---|---|
| NVMe INTEL SSDPE7KX02 | PHLF733000372P0LGN | SSD | Falsch | OK | Healthy | Auto-Select | 1.82 TB |
| NVMe INTEL SSDPE7KX02 | PHLF7504008J2P0LGN | SSD | Falsch | OK | Healthy | Auto-Select | 1.82 TB |
| NVMe INTEL SSDPE7KX02 | PHLF7504005F2P0LGN | SSD | Falsch | OK | Healthy | Auto-Select | 1.82 TB |
| NVMe INTEL SSDPE7KX02 | PHLF7504002A2P0LGN | SSD | Falsch | OK | Healthy | Auto-Select | 1.82 TB |
| NVMe INTEL SSDPE7KX02 | PHLF7504004T2P0LGN | SSD | Falsch | OK | Healthy | Auto-Select | 1.82 TB |
| NVMe INTEL SSDPE7KX02 | PHLF7504002E2P0LGN | SSD | Falsch | OK | Healthy | Auto-Select | 1.82 TB |
| NVMe INTEL SSDPE7KX02 | PHLF7330002Z2P0LGN | SSD | Falsch | OK | Healthy | Auto-Select | 1.82 TB |
| NVMe INTEL SSDPE7KX02 | PHLF733000272P0LGN | SSD | Falsch | OK | Healthy | Auto-Select | 1.82 TB |
| NVMe INTEL SSDPE7KX02 | PHLF7330001J2P0LGN | SSD | Falsch | OK | Healthy | Auto-Select | 1.82 TB |
| NVMe INTEL SSDPE7KX02 | PHLF733000302P0LGN | SSD | Falsch | OK | Healthy | Auto-Select | 1.82 TB |
| NVMe INTEL SSDPE7KX02 | PHLF7330004D2P0LGN | SSD | Falsch | OK | Healthy | Auto-Select | 1.82 TB |
Deaktivieren Sie in einem Direkten Speicherplätze-Cluster "Direkte Speicherplätze" den in Clean-Laufwerken beschriebenen Bereinigungsprozess. Der Clusterspeicherpool verbleibt weiterhin im Offlinezustand, und der Integritätsdienst wird aus dem Cluster entfernt.
Im nächsten Schritt wird der Phantomspeicherpool entfernt:
Get-ClusterResource -Name "Cluster Pool 1" | Remove-ClusterResource
Wenn Sie nun Get-PhysicalDisk auf einem der Knoten ausführen, werden alle Datenträger angezeigt, die sich im Pool befanden. Beispiel: In einem Lab mit einem Cluster mit vier Knoten und vier SAS-Datenträgern werden jedem Knoten jeweils 100 GB bereitgestellt. Wenn Sie in diesem Fall nach dem Deaktivieren von „Direkte Speicherplätze“ (wodurch die SBL (Storage Bus Layer) entfernt, der Filter jedoch beibehalten wird) das Cmdlet Get-PhysicalDisk ausführen, sollten vier Datenträger mit Ausnahme des lokalen Betriebssystemdatenträgers angezeigt werden. Stattdessen werden 16 angegeben. Dies ist für alle Knoten im Cluster gleich. Wenn Sie einen Get-Disk-Befehl ausführen, werden die lokal angefügten Datenträger mit den Nummern 0, 1, 2 usw. angezeigt, wie es in der folgenden Beispielausgabe zu sehen ist:
| Number | Anzeigename | Seriennummer | HealthStatus | OperationalStatus | Gesamtgröße | Partition Style |
|---|---|---|---|---|---|---|
| 0 | Msft Virtu... | Healthy | Online | 127 GB | GPT | |
| Msft Virtu... | Healthy | Offline | 100 GB | RAW | ||
| Msft Virtu... | Healthy | Offline | 100 GB | RAW | ||
| Msft Virtu... | Healthy | Offline | 100 GB | RAW | ||
| Msft Virtu... | Healthy | Offline | 100 GB | RAW | ||
| 1 | Msft Virtu... | Healthy | Offline | 100 GB | RAW | |
| Msft Virtu... | Healthy | Offline | 100 GB | RAW | ||
| 2 | Msft Virtu... | Healthy | Offline | 100 GB | RAW | |
| Msft Virtu... | Healthy | Offline | 100 GB | RAW | ||
| Msft Virtu... | Healthy | Offline | 100 GB | RAW | ||
| Msft Virtu... | Healthy | Offline | 100 GB | RAW | ||
| Msft Virtu... | Healthy | Offline | 100 GB | RAW | ||
| 4 | Msft Virtu... | Healthy | Offline | 100 GB | RAW | |
| 3 | Msft Virtu... | Healthy | Offline | 100 GB | RAW | |
| Msft Virtu... | Healthy | Offline | 100 GB | RAW | ||
| Msft Virtu... | Healthy | Offline | 100 GB | RAW | ||
| Msft Virtu... | Healthy | Offline | 100 GB | RAW |
Beim Ausführen des Cmdlets Enable-ClusterS2D werden möglicherweise Fehlermeldungen wie die folgenden angezeigt:
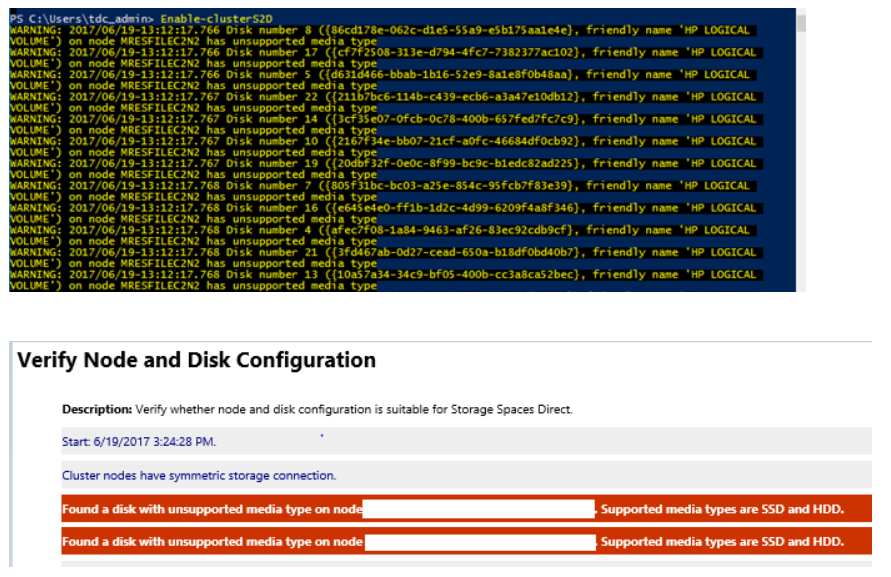
Um dieses Problem zu beheben, stellen Sie sicher, dass der HBA-Adapter im HBA-Modus konfiguriert ist. Es sollte kein HBA im RAID-Modus konfiguriert sein.
Im Prüfbericht sind die folgenden Informationen enthalten:
Der mit Knoten <nodename> verbundene Datenträger <identifier> hat eine SCSI-Portzuordnung zurückgegeben, und das entsprechende Gehäusegerät konnte nicht gefunden werden. Die Hardware ist nicht mit Direkte Speicherplätze (S2D) kompatibel. Wenden Sie sich an den Hardwareanbieter, um die Unterstützung für SCSI-Gehäusedienste (SES) zu überprüfen.
Das Problem steht mit der HPE SAS-Erweiterungskarte im Zusammenhang, die sich zwischen den Datenträgern und der HBA-Karte befindet. Die SAS-Erweiterung erstellt eine doppelte ID zwischen dem ersten Laufwerk, das mit der Erweiterung verbunden ist, und der Erweiterung selbst. Dies wurde in HPE Smart Array Controllers SAS Expander Firmware: 4.02 behoben.
Möglicherweise wird ein Problem angezeigt, bei dem ein Gerät der Intel SSD DC P4600-Serie eine ähnliche 16-Byte-NGUID für mehrere Namespaces zu melden scheint, wie z. B. 0100000001000000E4D25C000014E214 oder 0100000001000000E4D25C0000EEE214 im folgenden Beispiel.
| UniqueId | deviceId | MediaType | BusType | SerialNumber | Größe | CanPool | FriendlyName | OperationalStatus |
|---|---|---|---|---|---|---|---|---|
| 5000CCA251D12E30 | 0 | Festplattenlaufwerk | SAS | 7PKR197G | 10000831348736 | Falsch | HGST | HUH721010AL4200 |
| eui.0100000001000000E4D25C000014E214 | 4 | SSD | NVMe | 0100_0000_0100_0000_E4D2_5C00_0014_E214. | 1600321314816 | True | INTEL | SSDPE2KE016T7 |
| eui.0100000001000000E4D25C000014E214 | 5 | SSD | NVMe | 0100_0000_0100_0000_E4D2_5C00_0014_E214. | 1600321314816 | True | INTEL | SSDPE2KE016T7 |
| eui.0100000001000000E4D25C0000EEE214 | 6 | SSD | NVMe | 0100_0000_0100_0000_E4D2_5C00_00EE_E214. | 1600321314816 | True | INTEL | SSDPE2KE016T7 |
| eui.0100000001000000E4D25C0000EEE214 | 7 | SSD | NVMe | 0100_0000_0100_0000_E4D2_5C00_00EE_E214. | 1600321314816 | True | INTEL | SSDPE2KE016T7 |
Um dieses Problem zu beheben, aktualisieren Sie die Firmware auf den Intel-Laufwerken auf die neueste Version. Es ist bekannt, dass Firmwareversion QDV101B1 vom Mai 2018 dieses Problem behebt.
Die Version des Intel SSD Data Center Tool vom Mai 2018 enthält ein Firmwareupdate (QDV101B1) für die Intel SSD DC P4600-Serie.
In einem „Direkte Speicherplätze“-Cluster unter Windows Server 2016 wird der Integritätsstatus (HealthStatus) für mindestens einen physischen Datenträger möglicherweise als „Fehlerfrei“ angezeigt, während der Betriebsstatus (OperationalStatus) mit „(Wird aus dem Pool entfernt, OK)“ angegeben wird.
„Wird aus dem Pool entfernt“ ist eine Absicht, die beim Aufrufen von Remove-PhysicalDisk festgelegt wird, aber in der Integrität gespeichert wird, um den Zustand beizubehalten und die Wiederherstellung zu ermöglichen, falls der Entfernungsvorgang fehlschlägt. Sie können den Betriebsstatus mit einer der folgenden Methoden manuell in „Fehlerfrei“ ändern:
Es folgen einige Beispiele für das Ausführen des Skripts:
Verwenden Sie den Parameter SerialNumber, um den Datenträger anzugeben, den Sie auf „Fehlerfrei“ festlegen müssen. Sie können die Seriennummer von WMI MSFT_PhysicalDisk oder Get-PhysicalDisk. In diesem Beispiel werden Nullen verwendet, um für die Seriennummer zu stehen.
Clear-PhysicalDiskHealthData -Intent -Policy -SerialNumber 000000000000000 -Verbose -Force
Verwenden Sie den UniqueId Parameter, um den Datenträger erneut von WMI MSFT_PhysicalDisk oder Get-PhysicalDiskaus anzugeben.
Clear-PhysicalDiskHealthData -Intent -Policy -UniqueId 00000000000000000 -Verbose -Force
Möglicherweise tritt ein Problem auf, wenn Sie mit dem Datei-Explorer eine große VHD auf den virtuellen Datenträger kopieren: Das Kopieren der Datei dauert länger als erwartet.
Es wird nicht empfohlen, den Datei-Explorer, Robocopy oder Xcopy zu verwenden, um eine große VHD auf den virtuellen Datenträger zu kopieren. Leistung bei erneuter Übertragung langsamer als erwartet Der Kopiervorgang durchlauft nicht den „Direkte Speicherplätze“-Stapel, der sich weiter unten im Speicherstapel befindet, sondern funktioniert stattdessen wie ein lokaler Kopiervorgang.
Wenn Sie die Leistung von „Direkte Speicherplätze“ testen möchten, wird empfohlen, VMFleet und Diskspd für Auslastungs- und Belastungstests der Server zu verwenden, um eine Basislinie zu erhalten und Erwartungen hinsichtlich der Leistung von „Direkte Speicherplätze“ festzulegen.
Die folgenden Ereignisse können ignoriert werden:
Event ID 205: Windows lost communication with physical disk {XXXXXXXXXXXXXXXXXXXX}. This can occur if a cable failed or was disconnected, or if the disk itself failed.
Event ID 203: Windows lost communication with physical disk {XXXXXXXXXXXXXXXXXXXX}. This can occur if a cable failed or was disconnected, or if the disk itself failed.
Wenn Sie Azure-VMs ausführen, können Sie dieses Ereignis ignorieren: Ereignis-ID 32: Der Treiber hat festgestellt, dass das Gerät \Device\Harddisk5\DR5 den Schreibcache aktiviert hat. Datenbeschädigung kann auftreten.
Es wurde ein kritisches Problem festgestellt, das einige Benutzer von „Direkte Speicherplätze“ betrifft, die Hardware nutzen, die auf der Intel P3x00-Familie von NVMe-Geräten (NVM Express) mit Firmwareversionen vor Maintenance Release 8 basiert.
Hinweis
Einzelne OEMs verfügen möglicherweise über Geräte, die auf der Intel P3x00-Familie von NVMe-Geräten mit eindeutigen Firmware-Versionszeichenfolgen basieren. Wenden Sie sich an Ihren OEM, um weitere Informationen zur neuesten Firmwareversion zu erhalten.
Wenn Sie in Ihrer Bereitstellung Hardware verwenden, die auf der Intel P3x00-Familie von NVMe-Geräten basiert, wird empfohlen, sofort die neueste verfügbare Firmware (mindestens Maintenance Release 8) zu verwenden.
Ereignisse
29. Apr., 14 Uhr - 30. Apr., 19 Uhr
Nehmen Sie am ultimativen virtuellen Windows Server-Ereignis vom 29. bis 30. April teil, um technische Deep-Dive-Sitzungen und Live-Q&A mit Microsoft-Technikern zu erhalten.
Jetzt anmeldenTraining
Lernpfad
Ausführen von HPC-Anwendungen (High Performance Computing) in Azure - Training
Azure HPC ist eine zweckorientierte Cloudfunktion für HPC- und KI-Workloads, die modernste Prozessoren und InfiniBand-Verbindungen der HPC-Klasse verwendet, um die beste Anwendungsleistung, Skalierbarkeit und den besten Nutzen zu erzielen. Mit Azure HPC können Benutzer Innovationen, Produktivität und geschäftliche Agilität mithilfe einer hochverfügbaren Palette von HPC- und KI-Technologien nutzen, die dynamisch zugeordnet werden können, wenn sich Ihre geschäftlichen und technischen Anforderungen ändern. Bei
Dokumentation
Integritäts- und Betriebszustände für Speicherplätze und Direkte Speicherplätze
Hier erfahren Sie, wie Sie die verschiedenen Integritäts- und Betriebszustände von Direkte Speicherplätze und Speicherplätzen (einschließlich physischer Datenträger, Pools und virtueller Datenträger) finden und verstehen, und wie Sie dagegen vorgehen können.
Hinzufügen von Servern oder Laufwerken zu „direkten Speicherplätzen“
So fügen Sie Server oder Laufwerke einem Direkte Speicherplätze-Cluster hinzu
Entfernen von Servern in Direkte Speicherplätze
Entfernen von Servern aus einem Direkte Speicherplätze-Cluster in Windows Server.
Bereitstellen von Direkten Speicherplätzen unter Windows Server
Schrittweise Anleitungen zum Bereitstellen von softwaredefiniertem Speicher mit „Direkte Speicherplätze“ unter Windows Server entweder als hyperkonvergente oder konvergente Infrastruktur (auch als getrennte Infrastruktur bezeichnet).