Partitioning in Azure Cosmos DB for Apache Cassandra
APPLIES TO:
![]() Cassandra
Cassandra
This article describes how partitioning works in Azure Cosmos DB for Apache Cassandra.
API for Cassandra uses partitioning to scale the individual tables in a keyspace to meet the performance needs of your application. Partitions are formed based on the value of a partition key that is associated with each record in a table. All the records in a partition have the same partition key value. Azure Cosmos DB transparently and automatically manages the placement of partitions across the physical resources to efficiently satisfy the scalability and performance needs of the table. As the throughput and storage requirements of an application increase, Azure Cosmos DB moves and balances the data across a greater number of physical machines.
From the developer perspective, partitioning behaves in the same way for Azure Cosmos DB for Apache Cassandra as it does in native Apache Cassandra. However, there are some differences behind the scenes.
Differences between Apache Cassandra and Azure Cosmos DB
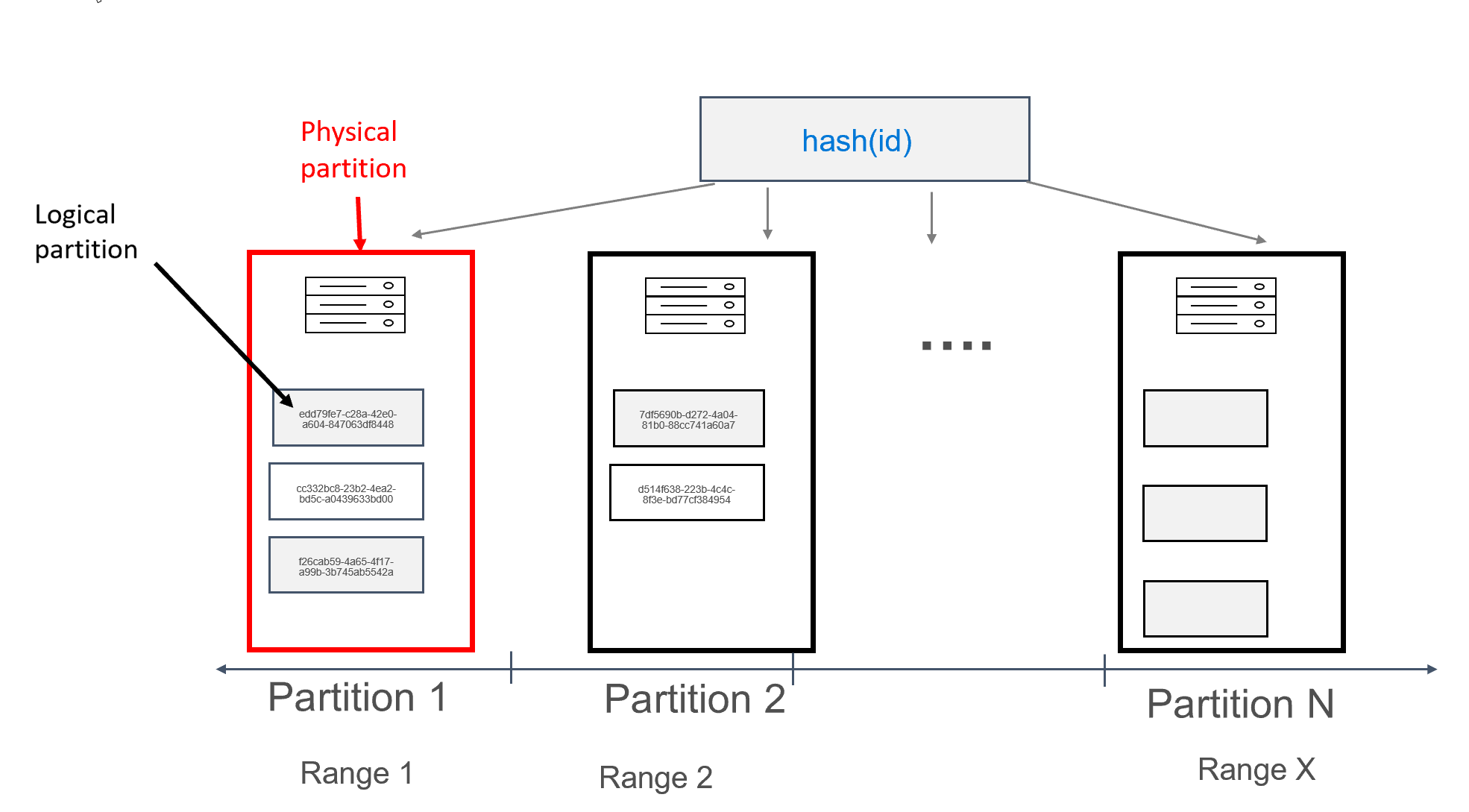
In Azure Cosmos DB, each machine on which partitions are stored is itself referred to as a physical partition. The physical partition is akin to a Virtual Machine; a dedicated compute unit, or set of physical resources. Each partition stored on this compute unit is referred to as a logical partition in Azure Cosmos DB. If you are already familiar with Apache Cassandra, you can think of logical partitions in the same way that you think of regular partitions in Cassandra.
Apache Cassandra recommends a 100-MB limit on the size of a data that can be stored in a partition. The API for Cassandra for Azure Cosmos DB allows up to 20 GB per logical partition, and up to 30GB of data per physical partition. In Azure Cosmos DB, unlike Apache Cassandra, compute capacity available in the physical partition is expressed using a single metric called request units, which allows you to think of your workload in terms of requests (reads or writes) per second, rather than cores, memory, or IOPS. This can make capacity planning more straight forward, once you understand the cost of each request. Each physical partition can have up to 10000 RUs of compute available to it. You can learn more about scalability options by reading our article on elastic scale in API for Cassandra.
In Azure Cosmos DB, each physical partition consists of a set of replicas, also known as replica sets, with at least 4 replicas per partition. This is in contrast to Apache Cassandra, where setting a replication factor of 1 is possible. However, this leads to low availability if the only node with the data goes down. In API for Cassandra there is always a replication factor of 4 (quorum of 3). Azure Cosmos DB automatically manages replica sets, while these need to be maintained using various tools in Apache Cassandra.
Apache Cassandra has a concept of tokens, which are hashes of partition keys. The tokens are based on a murmur3 64 byte hash, with values ranging from -2^63 to -2^63 - 1. This range is commonly referred to as the "token ring" in Apache Cassandra. The token ring is distributed into token ranges, and these ranges are divided amongst the nodes present in a native Apache Cassandra cluster. Partitioning for Azure Cosmos DB is implemented in a similar way, except it uses a different hash algorithm, and has a larger internal token ring. However, externally we expose the same token range as Apache Cassandra, i.e., -2^63 to -2^63 - 1.
Primary key
All tables in API for Cassandra must have a primary key defined. The syntax for a primary key is shown below:
column_name cql_type_definition PRIMARY KEY
Suppose we want to create a user table, which stores messages for different users:
CREATE TABLE uprofile.user (
id UUID PRIMARY KEY,
user text,
message text);
In this design, we have defined the id field as the primary key. The primary key functions as the identifier for the record in the table and it is also used as the partition key in Azure Cosmos DB. If the primary key is defined in the previously described way, there will only be a single record in each partition. This will result in a perfectly horizontal and scalable distribution when writing data to the database, and is ideal for key-value lookup use cases. The application should provide the primary key whenever reading data from the table, to maximize read performance.
Compound primary key
Apache Cassandra also has a concept of compound keys. A compound primary key consists of more than one column; the first column is the partition key, and any additional columns are the clustering keys. The syntax for a compound primary key is shown below:
PRIMARY KEY (partition_key_column_name, clustering_column_name [, ...])
Suppose we want to change the above design and make it possible to efficiently retrieve messages for a given user:
CREATE TABLE uprofile.user (
user text,
id int,
message text,
PRIMARY KEY (user, id));
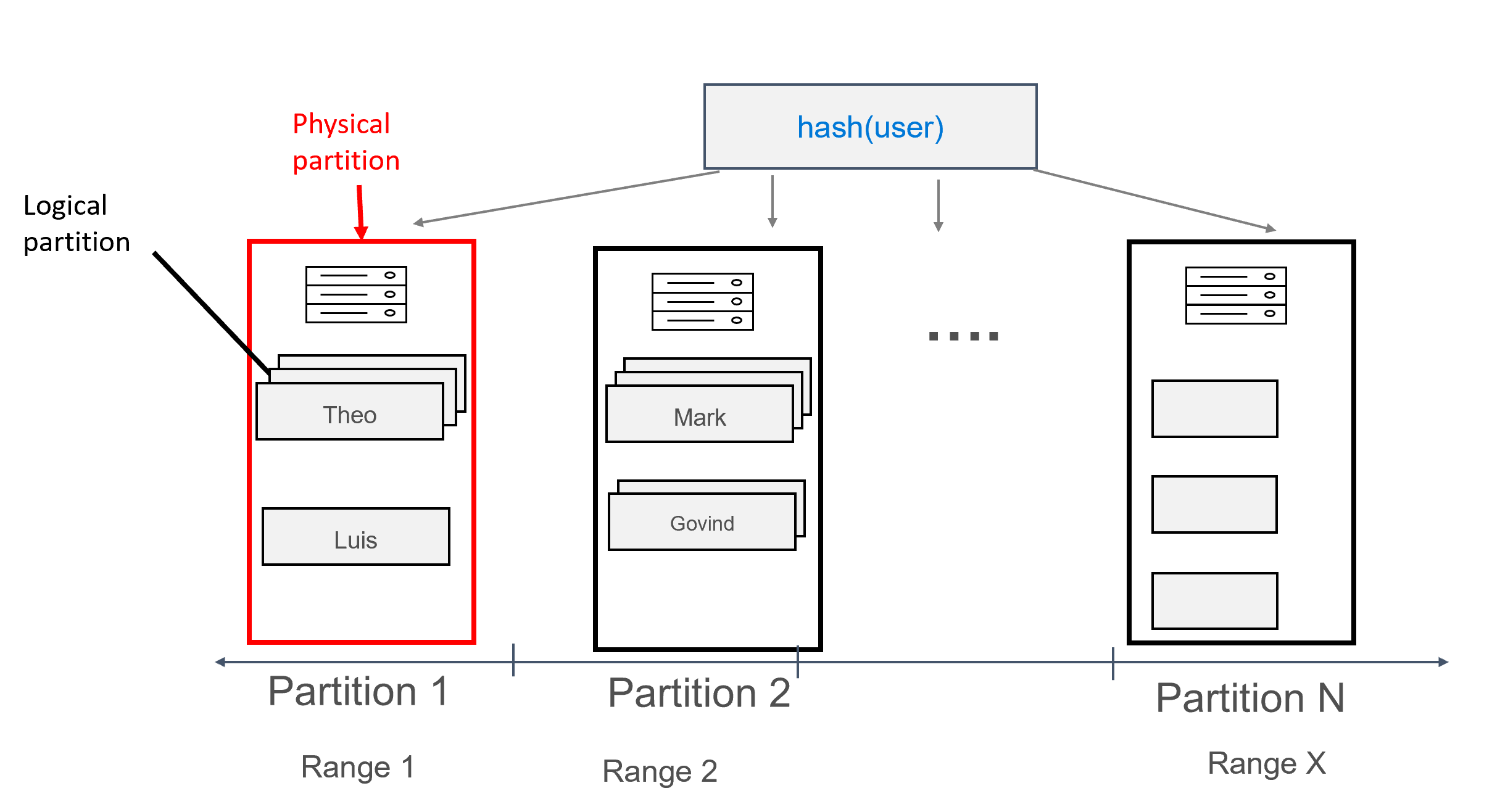
In this design, we are now defining user as the partition key, and id as the clustering key. You can define as many clustering keys as you wish, but each value (or a combination of values) for the clustering key must be unique in order to result in multiple records being added to the same partition, for example:
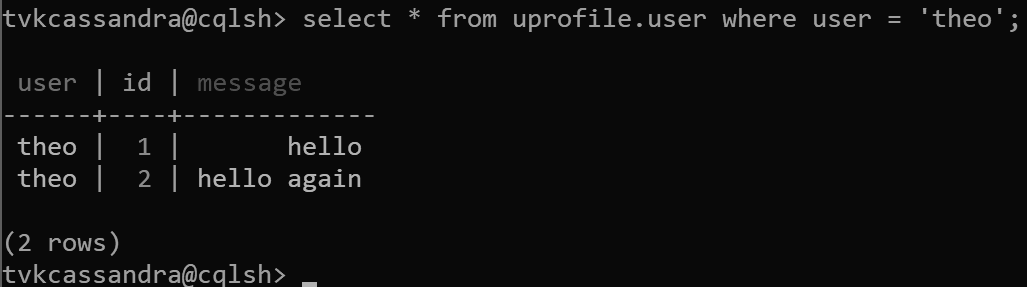
insert into uprofile.user (user, id, message) values ('theo', 1, 'hello');
insert into uprofile.user (user, id, message) values ('theo', 2, 'hello again');
When data is returned, it is sorted by the clustering key, as expected in Apache Cassandra:
Warning
When querying data in a table that has a compound primary key, if you want to filter on the partition key and any other non-indexed fields aside from the clustering key, ensure that you explicitly add a secondary index on the partition key:
CREATE INDEX ON uprofile.user (user);
Azure Cosmos DB for Apache Cassandra does not apply indexes to partition keys by default, and the index in this scenario may significantly improve query performance. Review our article on secondary indexing for more information.
With data modeled in this way, multiple records can be assigned to each partition, grouped by user. We can thus issue a query that is efficiently routed by the partition key (in this case, user) to get all the messages for a given user.
Composite partition key
Composite partition keys work essentially the same way as compound keys, except that you can specify multiple columns as a composite partition key. The syntax of composite partition keys is shown below:
PRIMARY KEY (
(partition_key_column_name[, ...]),
clustering_column_name [, ...]);
For example, you can have the following, where the unique combination of firstname and lastname would form the partition key, and id is the clustering key:
CREATE TABLE uprofile.user (
firstname text,
lastname text,
id int,
message text,
PRIMARY KEY ((firstname, lastname), id) );
Next steps
- Learn about partitioning and horizontal scaling in Azure Cosmos DB.
- Learn about provisioned throughput in Azure Cosmos DB.
- Learn about global distribution in Azure Cosmos DB.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for