Recommendations for security incident response
Applies to Azure Well-Architected Framework Security checklist recommendation:
| SE:12 | Define and test effective incident response procedures that cover a spectrum of incidents, from localized issues to disaster recovery. Clearly define which team or individual runs a procedure. |
|---|
This guide describes the recommendations for implementing a security incident response for a workload. If there's a security compromise to a system, a systematic incident response approach helps to reduce the time that it takes to identify, manage, and mitigate security incidents. These incidents can threaten the confidentiality, integrity, and availability of software systems and data.
Most enterprises have a central security operation team (also known as Security Operations Center (SOC), or SecOps). The responsibility of the security operation team is to rapidly detect, prioritize, and triage potential attacks. The team also monitors security-related telemetry data and investigates security breaches.
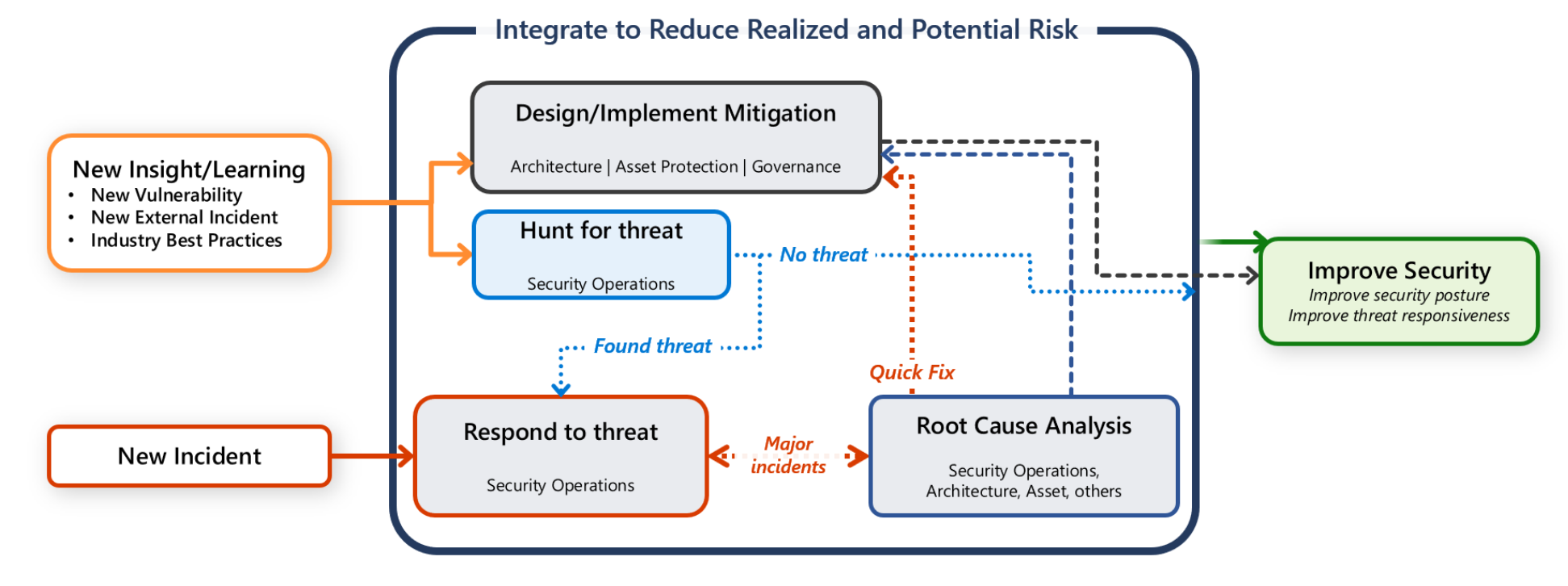
However, you also have a responsibility to protect your workload. It's important that any communication, investigation, and hunting activities are a collaborative effort between workload team and SecOps team.
This guide provides recommendations for you and your workload team to help you rapidly detect, triage, and investigate attacks.
Definitions
| Term | Definition |
|---|---|
| Alert | A notification that contains information about an incident. |
| Alert fidelity | The accuracy of the data that determines an alert. High-fidelity alerts contain the security context that's needed to take immediate actions. Low-fidelity alerts lack information or contain noise. |
| False positive | An alert that indicates an incident that didn't happen. |
| Incident | An event that indicates unauthorized access to a system. |
| Incident response | A process that detects, responds to, and mitigates risks that are associated with an incident. |
| Triage | An incident response operation that analyzes security issues and prioritizes their mitigation. |
Key design strategies
You and your team perform incident response operations when there's a signal or alert for a potential compromise. High-fidelity alerts contain ample security context that makes it easy for analysts to make decisions. High-fidelity alerts result in a low number of false positives. This guide assumes that an alerting system filters low-fidelity signals and focuses on high-fidelity alerts that might indicate a real incident.
Designate incident notification contacts
Security alerts need to reach the appropriate people on your team and in your organization. Establish a designated point of contact on your workload team to receive incident notifications. These notifications should include as much information as possible about the resource that's compromised and the system. The alert must include the next steps, so your team can expedite actions.
We recommend that you log and manage incident notifications and actions by using specialized tooling that keeps an audit trail. By using standard tools, you can preserve evidence that might be required for potential legal investigations. Look for opportunities to implement automation that can send notifications based on the responsibilities of accountable parties. Keep a clear chain of communication and reporting during an incident.
Take advantage of security information event management (SIEM) solutions and security orchestration automated response (SOAR) solutions that your organization provides. Alternatively, you can procure incident management tools and encourage your organization to standardize them for all workload teams.
Investigate with a triage team
The team member that receives an incident notification is responsible for setting up a triage process that involves the appropriate people based on the available data. The triage team, often called the bridge team, must agree on the mode and process of communication. Does this incident require asynchronous discussions or bridge calls? How should the team track and communicate the progress of investigations? Where can the team access incident assets?
Incident response is a crucial reason to keep documentation up to date, like the architectural layout of the system, information at a component level, privacy or security classification, owners, and key points of contact. If the information is inaccurate or outdated, the bridge team wastes valuable time trying to understand how the system works, who's responsible for each area, and what the effect of the event might be.
For further investigations, involve the appropriate people. You might include an incident manager, security officer, or workload-centric leads. To keep the triage focused, exclude people that are outside of the scope of the problem. Sometimes separate teams investigate the incident. There might be a team that initially investigates the issue and tries to mitigate the incident, and another specialized team that might perform forensics for a deep investigation to ascertain wide issues. You can quarantine the workload environment to enable the forensics team to do their investigations. In some cases, the same team might handle the entire investigation.
In the initial phase, the triage team is responsible for determining the potential vector and its effect on the confidentiality, integrity, and availability (also called the CIA) of the system.
Within the categories of CIA, assign an initial severity level that indicates the depth of the damage and the urgency of remediation. This level is expected to change over time as more information is discovered in the levels of triage.
In the discovery phase, it's important to determine an immediate course of action and communication plans. Are there any changes to the running state of the system? How can the attack be contained to stop further exploitation? Does the team need to send out internal or external communication, such as a responsible disclosure? Consider detection and response time. You might be legally obligated to report some types of breaches to a regulatory authority within a specific time period, which is often hours or days.
If you decide to shut down the system, the next steps lead to the workload's disaster recovery (DR) process.
If you don't shut down the system, determine how to remediate the incident without affecting the functionality of the system.
Recover from an incident
Treat a security incident like a disaster. If the remediation requires complete recovery, use proper DR mechanisms from a security perspective. The recovery process must prevent chances of recurrence. Otherwise, recovery from a corrupted backup reintroduces the issue. Redeploying a system with the same vulnerability leads to the same incident. Validate failover and failback steps and processes.
If the system remains functioning, assess the effect on the running parts of the system. Continue to monitor the system to ensure that other reliability and performance targets are met or readjusted by implementing proper degradation processes. Don't compromise privacy due to mitigation.
Diagnosis is an interactive process until the vector, and a potential fix and fallback, is identified. After diagnosis, the team works on remediation, which identifies and applies the required fix within an acceptable period.
Recovery metrics measure how long it takes to fix an issue. In the event of a shutdown, there might be an urgency regarding the remediation times. To stabilize the system, it takes time to apply fixes, patches, and tests, and deploy updates. Determine containment strategies to prevent further damage and the spread of the incident. Develop eradication procedures to completely remove the threat from the environment.
Tradeoff: There's a tradeoff between reliability targets and remediation times. During an incident, it's likely that you don't meet other nonfunctional or functional requirements. For example, you might need to disable parts of your system while you investigate the incident, or you might even need to take the entire system offline until you determine the scope of the incident. Business decision-makers need to explicitly decide what the acceptable targets are during the incident. Clearly specify the person that's accountable for that decision.
Learn from an incident
An incident uncovers gaps or vulnerable points in a design or implementation. It's an improvement opportunity that's driven by lessons in technical design aspects, automation, product development processes that include testing, and the effectiveness of the incident response process. Maintain detailed incident records, including actions taken, timelines, and findings.
We highly recommended that you conduct structured post-incident reviews, such as root-cause analysis and retrospectives. Track and prioritize the outcome of those reviews, and consider using what you learn in future workload designs.
Improvement plans should include updates to security drills and testing, like business continuity and disaster recovery (BCDR) drills. Use security compromise as a scenario for performing a BCDR drill. Drills can validate how the documented processes work. There shouldn't be multiple incident response playbooks. Use a single source that you can adjust based on the size of the incident and how widespread or localized the effect is. Drills are based on hypothetical situations. Conduct drills in a low-risk environment, and include the learning phase in the drills.
Conduct post-incident reviews, or postmortems, to identify weaknesses in the response process and areas for improvement. Based on the lessons you learn from the incident, update the incident response plan (IRP) and the security controls.
Define a communication plan
Implement a communication plan to notify users of a disruption and to inform internal stakeholders about the remediation and improvements. Other people in your organization need to be notified of any changes to the workload's security baseline to prevent future incidents.
Generate incident reports for internal use and, if necessary, for regulatory compliance or legal purposes. Also, adopt a standard format report (a document template with defined sections) that the SOC team uses for all incidents. Ensure that every incident has a report associated with it before you close the investigation.
Azure facilitation
Microsoft Sentinel is an SIEM and SOAR solution. It's a single solution for alert detection, threat visibility, proactive hunting, and threat response. For more information, see What's Microsoft Sentinel?
Ensure that the Azure enrollment portal includes administrator contact information so security operations can be notified directly via an internal process. For more information, see Update notification settings.
To learn more about establishing a designated point of contact that receives Azure incident notifications from Microsoft Defender for Cloud, see Configure email notifications for security alerts.
Organizational alignment
Cloud Adoption Framework for Azure provides guidance about incident response planning and security operations. For more information, see Security operations.
Related links
- Automatically create incidents from Microsoft security alerts
- Conduct end-to-end threat hunting by using the hunts feature
- Configure email notifications for security alerts
- Incident response overview
- Microsoft Azure incident readiness
- Navigate and investigate incidents in Microsoft Sentinel
- Security control: Incident response
- SOAR solutions in Microsoft Sentinel
- Training: Introduction to Azure incident readiness
- Update Azure portal notification settings
- What's an SOC?
- What's Microsoft Sentinel?
Security checklist
Refer to the complete set of recommendations.