Applying DataOps to Azure Data Factory
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
Azure Data Factory is Microsoft’s Data Integration and ETL service in the cloud. This paper provides guidance for DataOps in data factory. It isn't intended to be a complete tutorial on CI/CD, Git, or DevOps. Rather, you'll find the data factory team’s guidance for achieving DataOps in the service with references to detailed implementation links for data factory deployment best practices, factory management, and governance. There's a resources section at the end of this paper with links to tutorials.
What is DataOps?
DataOps is a process that data organizations practice for collaborative data management intended to provide faster value to decision makers.
Gartner provides this clear definition of DataOps:
DataOps is a collaborative data management practice focused on improving communication, integration and automation of data flows between data managers and data consumers across an organization. The goal of DataOps is to deliver value faster by creating predictable delivery and change management of data, data models, and related artifacts. DataOps uses technology to automate the design, deployment, and management of data delivery with appropriate levels of governance and uses metadata to improve the usability and value of data in a dynamic environment.
How do you achieve DataOps in Azure Data Factory?
Azure Data Factory provides data engineers with a visually based data pipeline paradigm for easily building cloud-scale data integration and ETL projects. Data factory relies on native integrations with mature version control tools such as GitHub and Azure DevOps, as well as the broader Azure ecosystem, to provide many built-in features to facilitate DataOps that include rich collaboration, governance, and artifact relationships.
Specifically, once you bring your own GitHub or Azure DevOps repository into data factory, the service provides intuitive built-in UI options for common commands, such as commits, saving artifacts, and version control. The service also provides the option to provide CI/CD and code check-in best practices, to protect the sanity and health of your production environment.
"Code" in Azure Data Factory
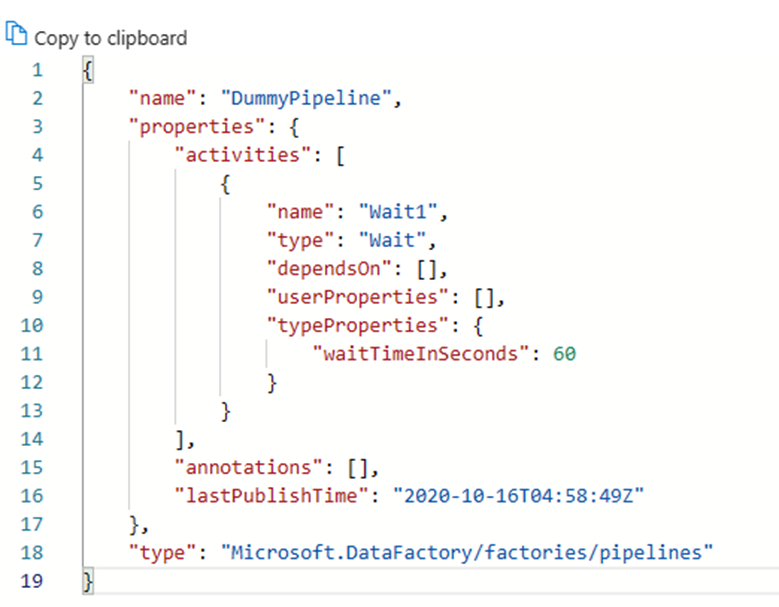
All artifacts in Azure Data Factory, whether they're pipelines, linked services, triggers, etc. have corresponding “code” representations in JSON behind the visual UI integration. These artifacts act in compliance with Azure Resource Manager templates standards. You can find the code by clicking on the bracket icon on the top right of the canvas. Sample JSON “code” would look like this:
Live mode and Git version control
Every factory has one single source of truth: pipelines, linked services, and trigger definitions stored within the service. This source of truth is what the pipeline runs execute and what determines the behaviors of triggers. If you are in live mode, every time you publish, you directly modify the single source of truth. The following image shows what the Publish All button looks like in live mode.

Live mode can be convenient for single person working on side projects, as it allows developers to see immediate effects of their code changes. However, it's discouraged for a team of developers working on production-level work projects. The dangers include fat fingers, accidental deletions of critical resources, publishing of untested codes, etc., just to name a few. When working on mission critical projects and platforms, consider bringing in a Git repository and use the Git mode in data factory to streamline the development process. Version control and gated check-in capabilities of the Git mode helps you prevent most, if not all, of the accidents associated with touching live mode directly.
Note
In Git mode, the Publish or Publish All button will be replaced by Save or Save All, and your changes are committed to your own branches (not directly changing the live code bases).
Setting up GitHub and Azure DevOps integration
In Azure Data Factory, it's highly recommended to store your repository in either GitHub or Azure DevOps. The service fully supports both methods and the choice of which repo to use depends upon your individual organizational standards. There are two methods to set up a new repository or to connect to an existing repository: using the Azure portal or creating from the Azure Data Factory Studio UI
Azure portal factory creation
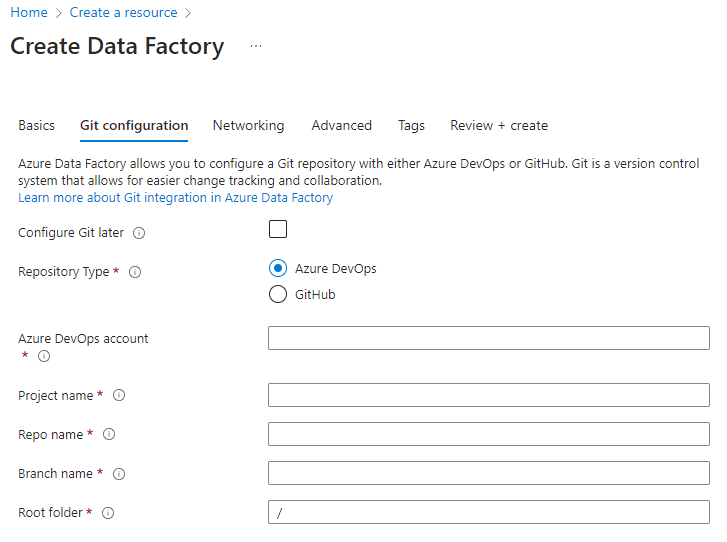
When you create a new data factory from the Azure portal, the default Git repo is Azure DevOps. You can also select GitHub as your repo and configure your repo settings.
From the Azure portal, select the repo type and enter the repo and branch names to create a new factory natively integrated with Git.
Enforcing use of Git with Azure Policy in your organization
The use of Git in your Azure Data Factory projects is a highly recommended best practice. Even if you aren't implementing a complete CI/CD process, Git integration with ADF enables saving of your resource artifacts in your own sandbox environment (Git branch) where you can test your changes independently from the rest of the factory branches. You can use Azure Policy to enforce use of Git in your organization’s factory.
Azure Data Factory Studio
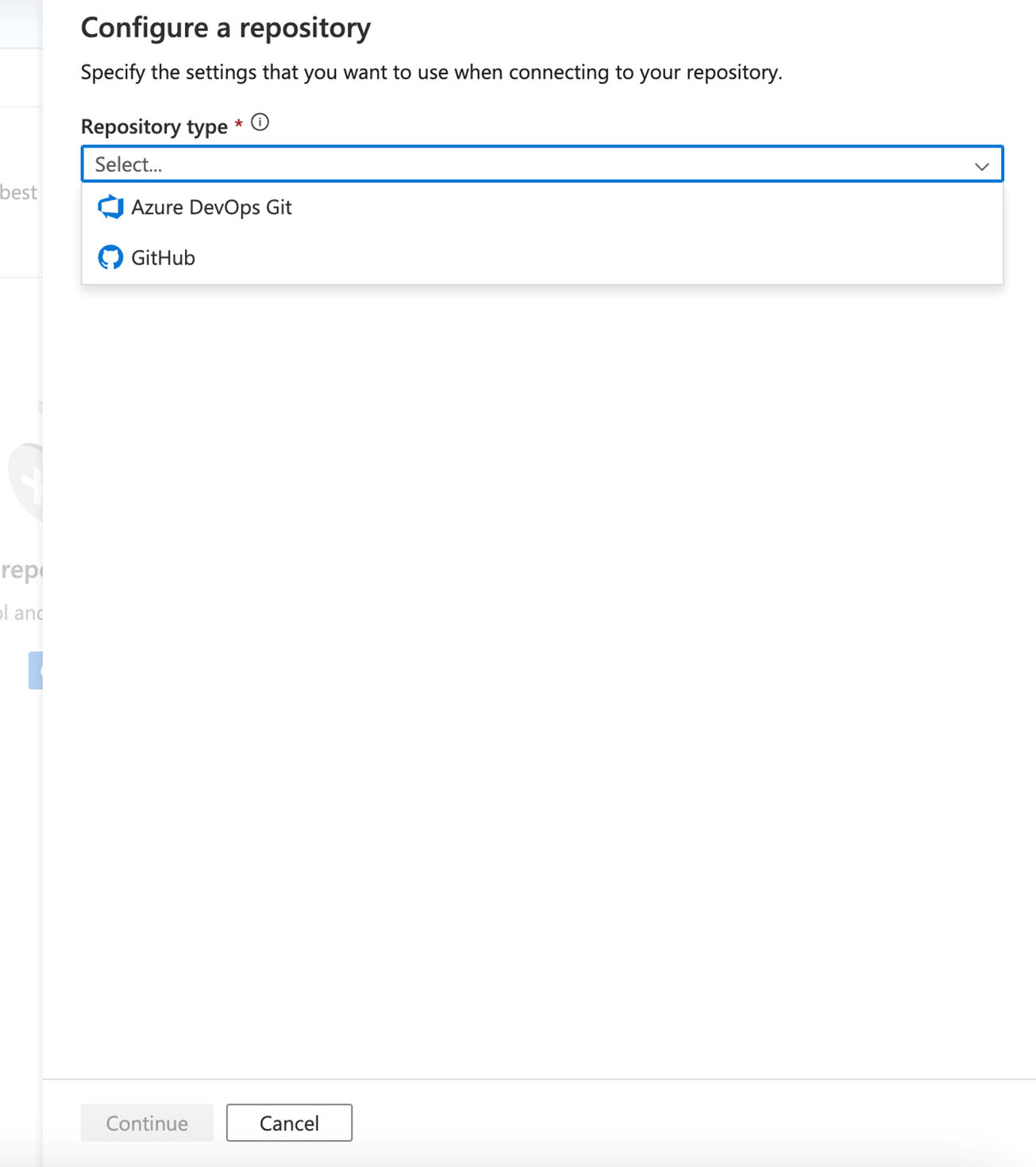
After you create your data factory, you can also connect to your repo through the Azure Data Factory Studio. In the Manage tab, you'll see the option to configure your repo and repo settings.

Through a guided process, you're directed through a series of steps to help you easily configure and connect to your repository of choice. Once fully set up, you can start to work collaboratively and save your resources to your repo.
Continuous integration and continuous delivery (CI/CD)
CI/CD is a paradigm of code development where changes are inspected and tested as they move through various stages - development, test, staging, etc. After being reviewed and tested through each stage they are finally published to live code bases in a production environment.
Continuous integration (CI) is the practice of automatically testing and validating every time a developer makes a change to your codebase. Continuous delivery (CD) means that after Continuous Integration tests succeed, the changes are brought to the next stage continuously.
As discussed briefly previously, “code” in Azure Data Factory takes the form of Azure Resource Manager template JSON. Hence, the changes going through the continuous integration and delivery (CI/CD) process comprise additions, deletions, and edits to JSON blobs.
Pipeline runs in Azure Data Factory
Before talking about CI/CD in Azure Data Factory, we first need to talk about how the service runs a pipeline. Before data factory runs a pipeline, it does following things:
- Pulls the latest published definition of the pipeline, and its associated assets, such as dataset(s), linked service(s), etc.
- Compiles it down to actions; if data factory executed it recently, it retrieves the actions from cached compilations.
- Runs the pipeline.
Running the pipeline entails the following steps:
- The service takes the point in time snapshot of the pipeline definition.
- Throughout the pipeline duration, the definitions don't change.
- Even if your pipelines run for a long time, they are unaffected by subsequent changes made after they were started. If you publish changes to the linked service, pipelines, etc., during the run, these do not affect in-progress runs.
- When you publish changes, subsequent runs started after publication use the updated definitions.
Publishing in Azure Data Factory
Regardless of whether you're deploying pipelines with Azure Release Pipeline to automate publishing, or with manual deployment of Resource Manager templates, in the backend, publishing is a series of create/update operations on datasets, linked services, pipelines, and triggers, for each of the artifacts. The effect is the same as making the underlying Rest API calls directly.
A few things come from the actions here:
- All of these API calls are synchronous, meaning that the call only returns when the publishing succeeds/fails. There won't be a state of partial deployment for the artifact.
- API calls are to a large extent sequential. We try to parallelize the calls, while maintaining the referential dependencies of the artifacts. The order of deployments is linked service -> dataset/integration runtime -> pipeline -> trigger. This order ensures that dependent artifacts can properly reference its dependencies. For example, pipelines depend on datasets and so data factory deploys them after datasets.
- Deployment of linked services, datasets, etc. are independent from the pipelines. There are situations where data factory updates linked services before a pipeline updates. We'll talk about this situation in the section When to Stop a Trigger.
- Deployment won't delete artifacts from the factories. You need to explicitly call delete APIs for each artifact type (pipeline, dataset, linked service, etc.) to clean up a factory. Refer to the sample post deployment script from Azure Data Factory for example.
- Even if you haven’t touched a pipeline, dataset, or linked service, it still invokes a quick update API call to the factory.
Publishing triggers
- Triggers have states: started or stopped.
- You can't make changes to a trigger in started mode. You need to stop a trigger before publishing any changes.
- You can invoke the Create or Update Trigger API on a trigger in started mode.
- If the payload changes, the API fails.
- If the payload remains unchanged, the API succeeds.
- This behavior has profound impact on when to stop a trigger.
When to stop a trigger
When it comes to deployment into a production data factory, with live triggers kicking off pipeline runs all the time, the question becomes “Should we stop them?”.
The short answer is that only in the following few scenarios should you consider stopping the trigger:
- You need to stop the trigger if you're updating the trigger definitions, including fields such as end date, frequency, and pipeline association.
- It's recommended to stop the trigger if you're updating the datasets or linked services referenced in a live pipeline. For example, if you're rotating the credentials for SQL Server.
- You may choose to stop the trigger if the associated pipeline is throwing errors and failing and burdening your servers.
Here are the few points to consider regarding stopping triggers:
- As explained in section Pipeline Runs in Azure Data Factory, when a trigger kicks off a pipeline run, it takes a snapshot of the pipeline, dataset, integration runtime, and linked service definitions. If the pipeline runs before the changes populate into the backend, the trigger starts a run with the old version. In most cases, this should be fine.
- As explained in section Publishing Triggers. When a trigger is in started state, it can't be updated. Therefore, if you need to change details about the trigger definition, stop the trigger before publishing the changes.
- As explained in section Publishing in Azure Data Factory, modifications to the datasets or linked services publish before pipeline changes. To ensure the pipeline runs use the correct credentials and communicate with the right servers, we recommend that you stop the associated trigger too.
Preparing "code" changes
We recommend that you follow these best practices for pull requests.
- Each developer should work on their own individual branches, and at the end of day, create pull requests to the main branch of the repository. See tutorials on pull requests in GitHub and DevOps.
- When gate keepers approve the pull requests and merge the changes into the main branch, the CI/CD process can start. There are two suggested methods to promote changes throughout environments: automated and manual.
- Once you're ready to kick off CI/CD pipelines, you can do so generally using Azure Pipeline Release or make deployments of specific individual pipelines using this open source utility from Azure Player.
Automated deployment of changes
To help with automated deployments, we recommend using the Azure Data Factory utilities npm package. Using the npm package helps validate all the resources in a pipeline and generate the ARM templates for the user.
To get started with the Azure Data Factory utilities npm package, refer to Automated publishing for continuous integration and delivery.
Manual deployment of changes
After you've merged your branch back to the main collaboration branch in your Git repository, you can manually publish your changes to the live Azure Data Factory service. The service provides UI control over publishing from non-development factories with the Disable publish (from ADF Studio) option.
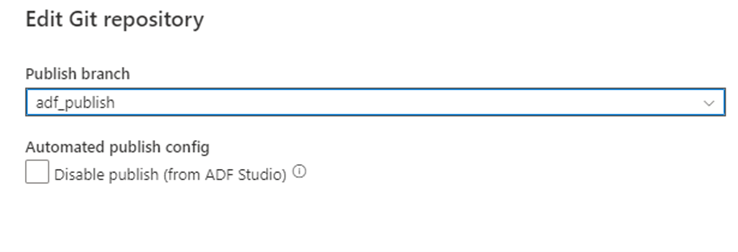
Selective deployment
Selective deployment relies on a feature of GitHub and Azure DevOps, known as cherry picking. This feature allows you to deploy only certain changes but not others. For instance, one developer has made changes to multiple pipelines, but for today’s deployment, we may only want to deploy changes to one.
Follow the tutorials from Azure DevOps and GitHub to select the commits relevant to the pipeline you need. Ensure that all changes, including relevant changes made to the triggers, linked services, and dependencies associated with the pipeline, have been cherry picked.
Once you've cherry picked the changes and merged to the main collaboration pipeline, you can kick off the CI/CD process for the proposed changes. Additional information on how to hot fix, cherry pick, or utilize external frameworks for selective deployment as described in the Automated testing section of this article.
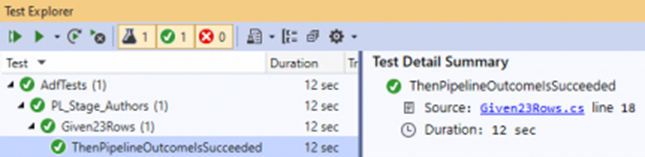
Unit testing
Unit testing is an important part of the process of developing new pipelines or editing existing data factory artifacts, which focuses on testing components of the code. Data Factory allows for individual unit testing at both the pipeline and data flow artifact level by using the pipeline debug feature.

When developing data flows, you'll be able to gain insights into each individual transformation and code change by using the data preview feature to achieve unit testing before deploying your changes to production.

The service provides live and interactive feedback of your pipeline activities in the UI when debugging and unit testing in Azure Data Factory.
Automated testing
There are several tools available for automated testing that you can use with Azure Data Factory. Since the service stores objects in the service as JSON entities, it can be convenient to use the open-source .NET unit testing framework NUnit with Visual Studio. Refer to this post Setup automated testing for Azure Data Factory that provides an in-depth explanation of how to set up an automated unit testing environment for your factory. (Special thanks to Richard Swinbank for permission to use this blog.)
Customers can also run TEST pipelines with PowerShell or AZ CLI as part of the CI/CD process for pre and post deployment steps.
A key strength of data factory lies in its parameterization of data sets. This feature empowers customers to run same pipelines with different data sets to make sure their new development meets all source and destination requirements.
Other CI/CD frameworks for Azure Data Factory
As described previously, built-in Git integration is available natively through the Azure Data Factory UI including merging, branching, comparison, and publication. However, there are other useful CI/CD frameworks that are popular in the Azure community, which provide alternative mechanisms to provide similar capabilities. The Azure Data Factory Git methodology is based on ARM templates, whereas frameworks like ADFTools by Kamil Nowinski take a different approach by relying on individual JSON artifacts from your factory instead. Data engineers who are savvy in Azure DevOps and prefer to work in that environment (as opposed to the ARM-based UI approach that the service offers out of the box) may find that this framework works well for them and for common scenarios like partial deployments. This framework can also simplify handling of triggers when deploying into environments that have running trigger states.
Data governance in Azure Data Factory
An important aspect of effective DataOps is data governance. For data integration ETL tools, providing data lineage and artifact relationships can provide important information for a data engineer to understand the impact of downstream changes. Data factory provides built-in related artifact views that constitute your factory implementation.
Native integration with Microsoft Purview further provides lineage, impact analysis, and data cataloging.
Microsoft Purview provides a unified data governance solution to help manage and govern your on-premises, multicloud, and software as a service (SaaS) data. It allows you to easily create a holistic, up-to-date map of your data landscape with automated data discovery, sensitive data classification, and end-to-end data lineage. These features enable data consumers to access valuable, trustworthy data management.
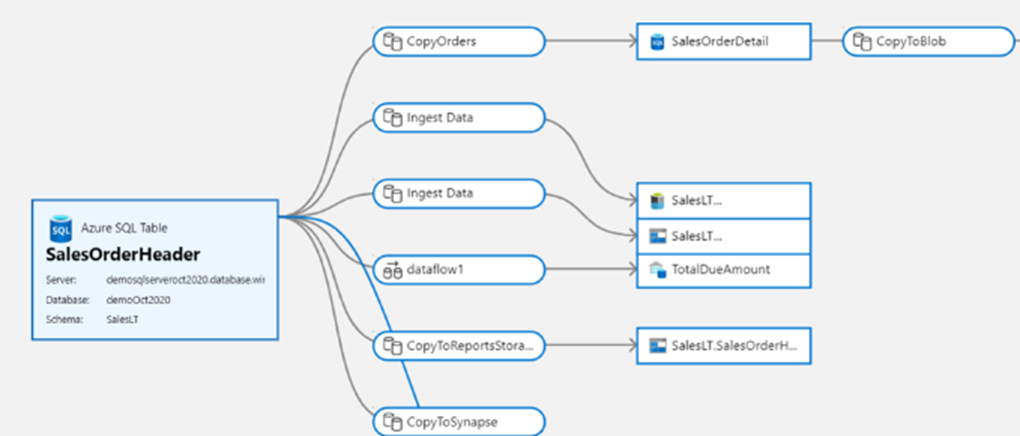
With native integration into your Purview Data Catalog, data factory enables easy search and discovery of data assets to use in your data integration pipelines across the full breadth of your organization’s data estate.

You can use the main search bar from the Azure Data Factory Studio to find data assets in your Purview catalog.

Related content
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for