Conditional split transformation in mapping data flow
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
Data flows are available both in Azure Data Factory and Azure Synapse Pipelines. This article applies to mapping data flows. If you are new to transformations, please refer to the introductory article Transform data using a mapping data flow.
The conditional split transformation routes data rows to different streams based on matching conditions. The conditional split transformation is similar to a CASE decision structure in a programming language. The transformation evaluates expressions, and based on the results, directs the data row to the specified stream.
Configuration
The Split on setting determines whether the row of data flows to the first matching stream or every stream it matches to.
Use the data flow expression builder to enter an expression for the split condition. To add a new condition, click on the plus icon in an existing row. A default stream can be added as well for rows that don't match any condition.
Data flow script
Syntax
<incomingStream>
split(
<conditionalExpression1>
<conditionalExpression2>
...
disjoint: {true | false}
) ~> <splitTx>@(stream1, stream2, ..., <defaultStream>)
Example
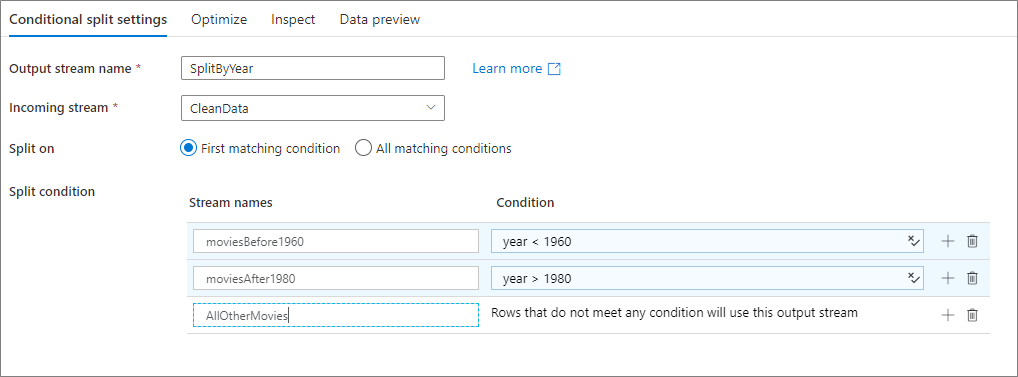
The below example is a conditional split transformation named SplitByYear that takes in incoming stream CleanData. This transformation has two split conditions year < 1960 and year > 1980. disjoint is false because the data goes to the first matching condition rather than all matching conditions. Every row matching the first condition goes to output stream moviesBefore1960. All remaining rows matching the second condition go to output stream moviesAFter1980. All other rows flow through the default stream AllOtherMovies.
In the service UI, this transformation looks like the below image:
The data flow script for this transformation is in the snippet below:
CleanData
split(
year < 1960,
year > 1980,
disjoint: false
) ~> SplitByYear@(moviesBefore1960, moviesAfter1980, AllOtherMovies)
Related content
Common data flow transformations used with conditional split are the join transformation, lookup transformation, and the select transformation
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for