Machine learning operations
Machine learning operations (also called MLOps) is the application of DevOps principles to AI-infused applications. To implement machine learning operations in an organization, specific skills, processes, and technology must be in place. The objective is to deliver machine learning solutions that are robust, scalable, reliable, and automated.
In this article, learn how to plan resources to support machine learning operations at the organization level. Review best practices and recommendations that are based on using Azure Machine Learning to adopt machine learning operations in the enterprise.
What is machine learning operations?
Modern machine learning algorithms and frameworks make it increasingly easier to develop models that can make accurate predictions. Machine learning operations is a structured way to incorporate machine learning in application development in the enterprise.
In an example scenario, you've built a machine learning model that exceeds all your accuracy expectations and impresses your business sponsors. Now it's time to deploy the model to production, but that might not be as easy as you had expected. The organization likely will need to have people, processes, and technology in place before it can use your machine learning model in production.
Over time, you or a colleague might develop a new model that works better than the original model. Replacing a machine learning model that's used in production introduces some concerns that are important to the organization:
- You'll want to implement the new model without disrupting the business operations that rely on the deployed model.
- For regulatory purposes, you might be required to explain the model's predictions or re-create the model if unusual or biased predictions result from data in the new model.
- The data you use in your machine learning training and model might change over time. With changes in the data, you might need to periodically retrain the model to maintain its prediction accuracy. A person or role will need to be assigned responsibility to feed the data, monitor the model's performance, retrain the model, and fix the model if it fails.
Suppose you have an application that serves a model's predictions via REST API. Even a simple use case like this one might cause problems in production. Implementing a machine learning operations strategy can help you address deployment concerns and support business operations that rely on AI-infused applications.
Some machine learning operations tasks fit well in the general DevOps framework. Examples include setting up unit tests and integration tests and tracking changes by using version control. Other tasks are more unique to machine learning operations and might include:
- Enable continuous experimentation and comparison against a baseline model.
- Monitor incoming data to detect data drift.
- Trigger model retraining and set up a rollback for disaster recovery.
- Create reusable data pipelines for training and scoring.
The goal of machine learning operations is to close the gap between development and production and to deliver value to customers faster. To achieve this goal, you must rethink traditional development and production processes.
Not every organization's machine learning operations requirements are the same. The machine learning operations architecture of a large, multinational enterprise probably won't be the same infrastructure that a small startup establishes. Organizations typically begin small and build up as their maturity, model catalog, and experience grows.
The machine learning operations maturity model can help you see where your organization is on the machine learning operations maturity scale and help you plan for future growth.
Machine learning operations vs. DevOps
Machine learning operations is different from DevOps in several key areas. Machine learning operations has these characteristics:
- Exploration precedes development and operations.
- The data science lifecycle requires an adaptive way of working.
- Limits on data quality and availability limit progress.
- A greater operational effort is required than in DevOps.
- Work teams require specialists and domain experts.
For a summary, review the seven principles of machine learning operations.
Exploration precedes development and operations
Data science projects are different from application development or data engineering projects. A data science project might make it to production, but often more steps are involved than in a traditional deployment. After an initial analysis, it might become clear that the business outcome can't be achieved with the available datasets. A more detailed exploration phase usually is the first step in a data science project.
The goal of the exploration phase is to define and refine the problem. During this phase, data scientists run exploratory data analysis. They use statistics and visualizations to confirm or falsify the problem hypotheses. Stakeholders should understand that the project might not extend beyond this phase. At the same time, it's important to make this phase as seamless as possible for a quick turnaround. Unless the problem to solve includes a security element, avoid restricting the exploratory phase with processes and procedures. Data scientists should be allowed to work with the tools and data they prefer. Real data is needed for this exploratory work.
The project can move to the experimentation and development stages when stakeholders are confident that the data science project is feasible and can provide real business value. At this stage, development practices become increasingly important. It's a good practice to capture metrics for all of the experiments that are done at this stage. It's also important to incorporate source control so that you can compare models and toggle between different versions of the code.
Development activities include refactoring, testing, and automating exploration code in repeatable experimentation pipelines. The organization must create applications and pipelines to serve the models. Refactoring code in modular components and libraries helps increase reusability, testing, and performance optimization.
Finally, the application or batch inference pipelines that serve the models are deployed to staging or production environments. In addition to monitoring infrastructure reliability and performance like for a standard application, in a machine learning model deployment, you must continuously monitor the quality of the data, the data profile, and the model for degradation or drift. Machine learning models also require retraining over time to stay relevant in a changing environment.
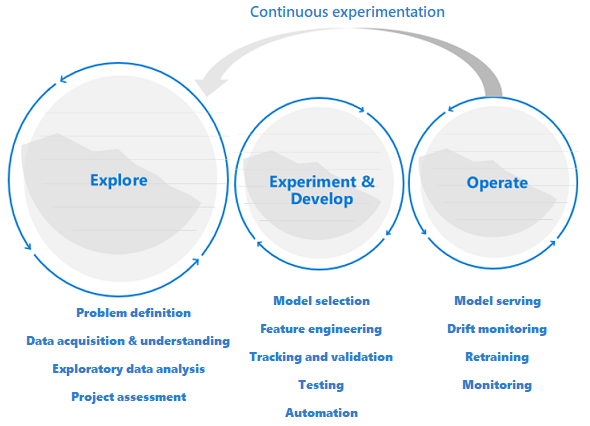
Data science lifecycle requires an adaptive way of working
Because the nature and quality of data initially is uncertain, you might not accomplish your business goals if you apply a typical DevOps process to a data science project. Exploration and experimentation are recurring activities and needs throughout the machine learning process. Teams at Microsoft use a project lifecycle and a working process that reflect the nature of data science-specific activities. The Team Data Science Process and The Data Science Lifecycle Process are examples of reference implementations.
Limits on data quality and availability limit progress
For a machine learning team to effectively develop machine learning-infused applications, access to production data is preferred for all relevant work environments. If production data access isn't possible due to compliance requirements or technical constraints, consider implementing Azure role-based access control (Azure RBAC) with Azure Machine Learning, just-in-time access, or data movement pipelines to create production data replicas and enhance user productivity.
Machine learning requires a greater operational effort
Unlike traditional software, the performance of a machine learning solution is constantly at risk because the solution is dependent on data quality. To maintain a qualitative solution in production, it's critical that you continuously monitor and reevaluate both data and model quality. It's expected that a production model requires timely retraining, redeployment, and tuning. These tasks come on top of day-to-day security, infrastructure monitoring, and compliance requirements, and they require specialized expertise.
Machine learning teams require specialists and domain experts
Although data science projects share roles with regular IT projects, the success of a machine learning effort highly depends on having essential machine learning technology specialists and domain subject matter experts. A technology specialist has the right background to do end-to-end machine learning experimentation. A domain expert can support the specialist by analyzing and synthesizing data or by qualifying data for use.
Common technical roles that are unique to data science projects are domain expert, data engineer, data scientist, AI engineer, model validator, and machine learning engineer. To learn more about roles and tasks in a typical data science team, see the Team Data Science Process.
Seven principles of machine learning operations
As you plan to adopt machine learning operations in your organization, consider applying the following core principles as the foundation:
Use version control for code, data, and experimentation outputs. Unlike in traditional software development, data has a direct influence on the quality of machine learning models. You should version your experimentation code base, but also version your datasets to ensure that you can reproduce experiments or inference results. Versioning experimentation outputs like models can save effort and the computational cost of re-creating them.
Use multiple environments. To separate development and testing from production work, replicate your infrastructure in at least two environments. Access control for users might be different for each environment.
Manage your infrastructure and configurations as code. When you create and update infrastructure components in your work environments, use infrastructure as code, so inconsistencies don't develop in your environments. Manage machine learning experiment job specifications as code so that you can easily rerun and reuse a version of your experiment in multiple environments.
Track and manage machine learning experiments. Track key performance indicators and other artifacts for your machine learning experiments. When you keep a history of job performance, you can do a quantitative analysis of experimentation success and enhance team collaboration and agility.
Test code, validate data integrity, and ensure model quality. Test your experimentation code base for correct data preparation and feature extraction functions, data integrity, and model performance.
Machine learning continuous integration and delivery. Use continuous integration (CI) to automate testing for your team. Include model training as part of continuous training pipelines. Include A/B testing as part of your release to ensure that only a qualitative model is used in production.
Monitor services, models, and data. When you serve models in a machine learning operations environment, it's critical to monitor the services for their infrastructure uptime, compliance, and model quality. Set up monitoring to identify data and model drift and to understand whether retraining is required. Consider setting up triggers for automatic retraining.
Best practices from Azure Machine Learning
Azure Machine Learning offers asset management, orchestration, and automation services to help you manage the lifecycle of your machine learning model training and deployment workflows. Review the best practices and recommendations to apply machine learning operations in the resource areas of people, process, and technology, all supported by Azure Machine Learning.
People
Work in project teams to best use specialist and domain knowledge in your organization. Set up Azure Machine Learning workspaces for each project to comply with use case segregation requirements.
Define a set of responsibilities and tasks as a role so that any team member on a machine learning operations project team can be assigned to and fulfill multiple roles. Use custom roles in Azure to define a set of granular Azure RBAC operations for Azure Machine Learning that each role can perform.
Standardize on a project lifecycle and Agile methodology. The Team Data Science Process provides a reference lifecycle implementation.
Balanced teams can run all machine learning operations stages, including exploration, development, and operations.
Process
Standardize on a code template for code reuse and to accelerate ramp-up time on a new project or when a new team member joins the project. Use Azure Machine Learning pipelines, job submission scripts, and CI/CD pipelines as a basis for new templates.
Use version control. Jobs that are submitted from a Git-backed folder automatically track repo metadata with the job in Azure Machine Learning for reproducibility.
Use versioning for experiment inputs and outputs for reproducibility. Use Azure Machine Learning datasets, model management, and environment management capabilities to facilitate versioning.
Build up a run history of experiment runs for comparison, planning, and collaboration. Use an experiment-tracking framework like MLflow to collect metrics.
Continuously measure and control the quality of your team's work through CI on the full experimentation code base.
Terminate training early in the process when a model doesn't converge. Use an experiment-tracking framework and the run history in Azure Machine Learning to monitor job runs.
Define an experiment and model management strategy. Consider using a name like champion to refer to the current baseline model. A challenger model is a candidate model that might outperform the champion model in production. Apply tags in Azure Machine Learning to mark experiments and models. In a scenario like sales forecasting, it might take months to determine whether the model's predictions are accurate.
Elevate CI for continuous training by including model training in the build. For example, begin model training on the full dataset with each pull request.
Shorten the time it takes to get feedback on the quality of the machine learning pipeline by running an automated build on a data sample. Use Azure Machine Learning pipeline parameters to parameterize input datasets.
Use continuous deployment (CD) for machine learning models to automate deployment and testing real-time scoring services in your Azure environments.
In some regulated industries, you might be required to complete model validation steps before you can use a machine learning model in a production environment. Automating validation steps might accelerate time to delivery. When manual review or validation steps are still a bottleneck, consider whether you can certify the automated model validation pipeline. Use resource tags in Azure Machine Learning to indicate asset compliance and candidates for review or as triggers for deployment.
Don't retrain in production, and then directly replace the production model without doing integration testing. Even though model performance and functional requirements might appear good, among other potential issues, a retrained model might have a larger environment footprint and break the server environment.
When production data access is available only in production, use Azure RBAC and custom roles to give a select number of machine learning practitioners read access. Some roles might need to read the data for related data exploration. Alternatively, make a data copy available in nonproduction environments.
Agree on naming conventions and tags for Azure Machine Learning experiments to differentiate retraining baseline machine learning pipelines from experimental work.
Technology
If you currently submit jobs via the Azure Machine Learning studio UI or CLI, instead of submitting jobs via the SDK, use the CLI or Azure DevOps Machine Learning tasks to configure automation pipeline steps. This process might reduce the code footprint by reusing the same job submissions directly from automation pipelines.
Use event-based programming. For example, trigger an offline model testing pipeline by using Azure Functions after a new model is registered. Or, send a notification to a designated email alias when a critical pipeline fails to run. Azure Machine Learning creates events in Azure Event Grid. Multiple roles can subscribe to be notified of an event.
When you use Azure DevOps for automation, use Azure DevOps Tasks for Machine Learning to use machine learning models as pipeline triggers.
When you develop Python packages for your machine learning application, you can host them in an Azure DevOps repository as artifacts and publish them as a feed. By using this approach, you can integrate the DevOps workflow for building packages with your Azure Machine Learning workspace.
Consider using a staging environment to test machine learning pipeline system integration with upstream or downstream application components.
Create unit and integration tests for your inference endpoints for enhanced debugging and to accelerate time to deployment.
To trigger retraining, use dataset monitors and event-driven workflows. Subscribe to data drift events and automate the trigger of machine learning pipelines for retraining.
AI factory for organization machine learning operations
A data science team might decide it can manage multiple machine learning use cases internally. Adopting machine learning operations helps an organization set up project teams for better quality, reliability, and maintainability of solutions. Through balanced teams, supported processes, and technology automation, a team that adopts machine learning operations can scale and focus on developing new use cases.
As the number of use cases grows in an organization, the management burden of supporting the use cases grows linearly, or even more. The challenge for the organization becomes how to accelerate time to market, support quicker assessment of use case feasibility, implement repeatability, and best use available resources and skill sets on a range of projects. For many organizations, developing an AI factory is the solution.
An AI factory is a system of repeatable business processes and standardized artifacts that facilitates developing and deploying a large set of machine learning use cases. An AI factory optimizes team setup, recommended practices, machine learning operations strategy, architectural patterns, and reusable templates that are tailored to business requirements.
A successful AI factory relies on repeatable processes and reusable assets to help the organization efficiently scale from tens of use cases to thousands of use cases.
The following figure summarizes key elements of an AI factory:

Standardize on repeatable architectural patterns
Repeatability is a key characteristic of an AI factory. Data science teams can accelerate project development and improve consistency across projects by developing a few repeatable architectural patterns that cover most of the machine learning use cases for their organization. When these patterns are in place, most projects can use the patterns to get the following benefits:
- Accelerated design phase
- Accelerated approvals from IT and security teams when they reuse tools across projects
- Accelerated development due to reusable infrastructure as code templates and project templates
The architectural patterns can include but aren't limited to the following topics:
- Preferred services for each stage of the project
- Data connectivity and governance
- A machine learning operations strategy tailored to the requirements of the industry, business, or data classification
- Experiment management champion and challenger models
Facilitate cross-team collaboration and sharing
Shared code repositories and utilities can accelerate the development of machine learning solutions. Code repositories can be developed in a modular way during project development so that they're generic enough to be used in other projects. They can be made available in a central repository that all data science teams can access.
Share and reuse intellectual property
To maximize code reuse, review the following intellectual property at the beginning of a project:
- Internal code that was designed to reuse in the organization. Examples include packages and modules.
- Datasets that were created in other machine learning projects or which are available in the Azure ecosystem.
- Existing data science projects that have a similar architecture and business problems.
- GitHub or open source repositories that can accelerate the project.
Any project retrospective should include an action item to determine whether elements of the project can be shared and generalized for broader reuse. The list of assets the organization can share and reuse expands over time.
To help with sharing and discovery, many organizations have introduced shared repositories to organize code snippets and machine learning artifacts. Artifacts in Azure Machine Learning, including datasets, models, environments, and pipelines, can be defined as code, so you can share them efficiently across projects and workspaces.
Project templates
To accelerate the process of migrating existing solutions and to maximize code reuse, many organizations standardize on a project template to kickstart new projects. Examples of project templates that are recommended for use with Azure Machine Learning are Azure Machine Learning examples, the Data Science Lifecycle Process, and the Team Data Science Process.
Central data management
The process of getting access to data for exploration or production usage can be time consuming. Many organizations centralize data management to bring together data producers and data consumers for easier access to data for machine learning experimentation.
Shared utilities
Your organization can use enterprise-wide centralized dashboards to consolidate logging and monitoring information. The dashboards might include error logging, service availability and telemetry, and model performance monitoring.
Use Azure Monitor metrics to build a dashboard for Azure Machine Learning and associated services like Azure Storage. A dashboard helps you keep track of experimentation progress, compute infrastructure health, and GPU quota utilization.
Specialist machine learning engineering team
Many organizations have implemented the role of machine learning engineer. A machine learning engineer specializes in creating and running robust machine learning pipelines, drift monitoring and retraining workflows, and monitoring dashboards. The engineer has overall responsibility for industrializing the machine learning solution, from development to production. The engineer works closely with data engineering, architects, security, and operations to ensure that all necessary controls are in place.
Although data science requires deep domain expertise, machine learning engineering is more technical in focus. The difference makes the machine learning engineer more flexible, so they can work on various projects and with various business departments. Large data science practices might benefit from a specialist machine learning engineering team that drives repeatability and reuse of automation workflows across various use cases and business areas.
Enablement and documentation
It's important to provide clear guidance about the AI factory process for new and existing teams and users. Guidance helps ensure consistency and reduce the effort that's required from the machine learning engineering team when it industrializes a project. Consider designing content specifically for the various roles in your organization.
Everyone has a unique way of learning, so a mixture of the following types of guidance can help accelerate adoption of the AI factory framework:
- A central hub that has links to all artifacts. For example, this hub might be a channel on Microsoft Teams or a Microsoft SharePoint site.
- Training and an enablement plan designed for each role.
- A high-level summary presentation of the approach and a companion video.
- A detailed document or playbook.
- How-to videos.
- Readiness assessments.
Machine learning operations in Azure video series
A video series about machine learning operations in Azure shows you how to establish machine learning operations for your machine learning solution, from initial development to production.
Ethics
Ethics plays an instrumental role in the design of an AI solution. If ethical principles aren't implemented, trained models might exhibit the same bias that's present in the data they were trained on. The result might be that the project is discontinued. More importantly, the organization's reputation might be at risk.
To ensure that the key ethical principles that the organization stands for are implemented across projects, the organization should provide a list of these principles and ways to validate them from a technical perspective during the testing phase. Use the machine learning features in Azure Machine Learning to understand what responsible machine learning is and how to build it into your machine learning operations.
Next steps
Learn more about how to organize and set up Azure Machine Learning environments, or watch a hands-on video series about machine learning operations in Azure.
Learn more about how to manage budgets, quotas, and costs at the organization level by using Azure Machine Learning:
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for