' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EHC%3C/text%3E%3C/svg%3E)
Windows for business | Windows Server | Storage high availability | Clustering and high availability
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESG%3C/text%3E%3C/svg%3E)
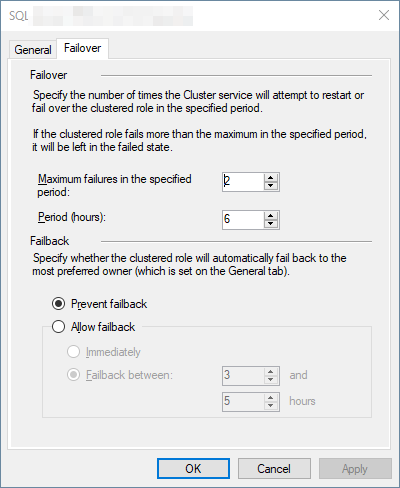
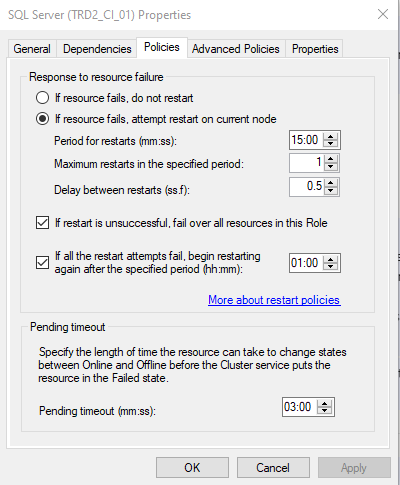
The cluster service however tried to restart the SQL role a couple of times on the same original node that it crashed on.
Unless you've gone in and changed the cluster settings, this is the default behavior.
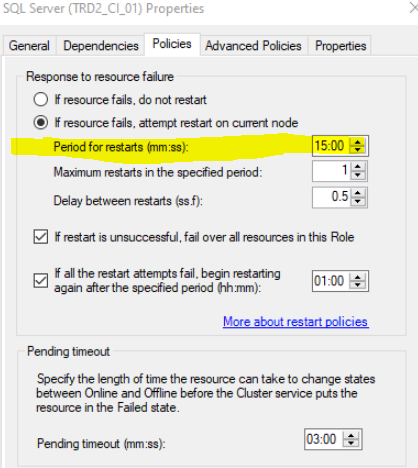
Then after about 15 minutes it finally failed over to node B. Why would it take so long for node B to take over the role?
You'll have to look at the cluster log to determine exactly why, but it's most likely the timing based on your cluster configuration along with the set (or default, most likely) values for the resource and role.