Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
4,363 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJR%3C/text%3E%3C/svg%3E)
Hi.
In a Synapse notebook I'm trying to write a data frame to the Synapse database with a lake which is not set as the default.
I've tried different ways of doing this, specifying the path too, but I get the same error message implying that I'm trying to write to the default lake (to which I don't have the write permission).
What is the correct syntax for writing to the Synapse Database with a non-default lake?

Hi @Johan á Rogvi-Hansen ,
Thankyou for using Microsoft Q&A platform and thanks for posting your question here.
As I understand your requirement , you are trying to write data into lake database which is not a default DB. However, it's not working and is throwing an error. Please let me know if that is not the case.
Could you please share the code which you have been trying to run along with the error message screenshot. Thanks for your efforts in doing so.
Thankyou for the question on Microsoft Q&A platform.
As per my understanding, you are trying to write data from dataframe to lake database (non default DB).
You can explicitly mention the database name in which you want to write the dataframe by providing the fully qualified tablename in saveAsTable function.
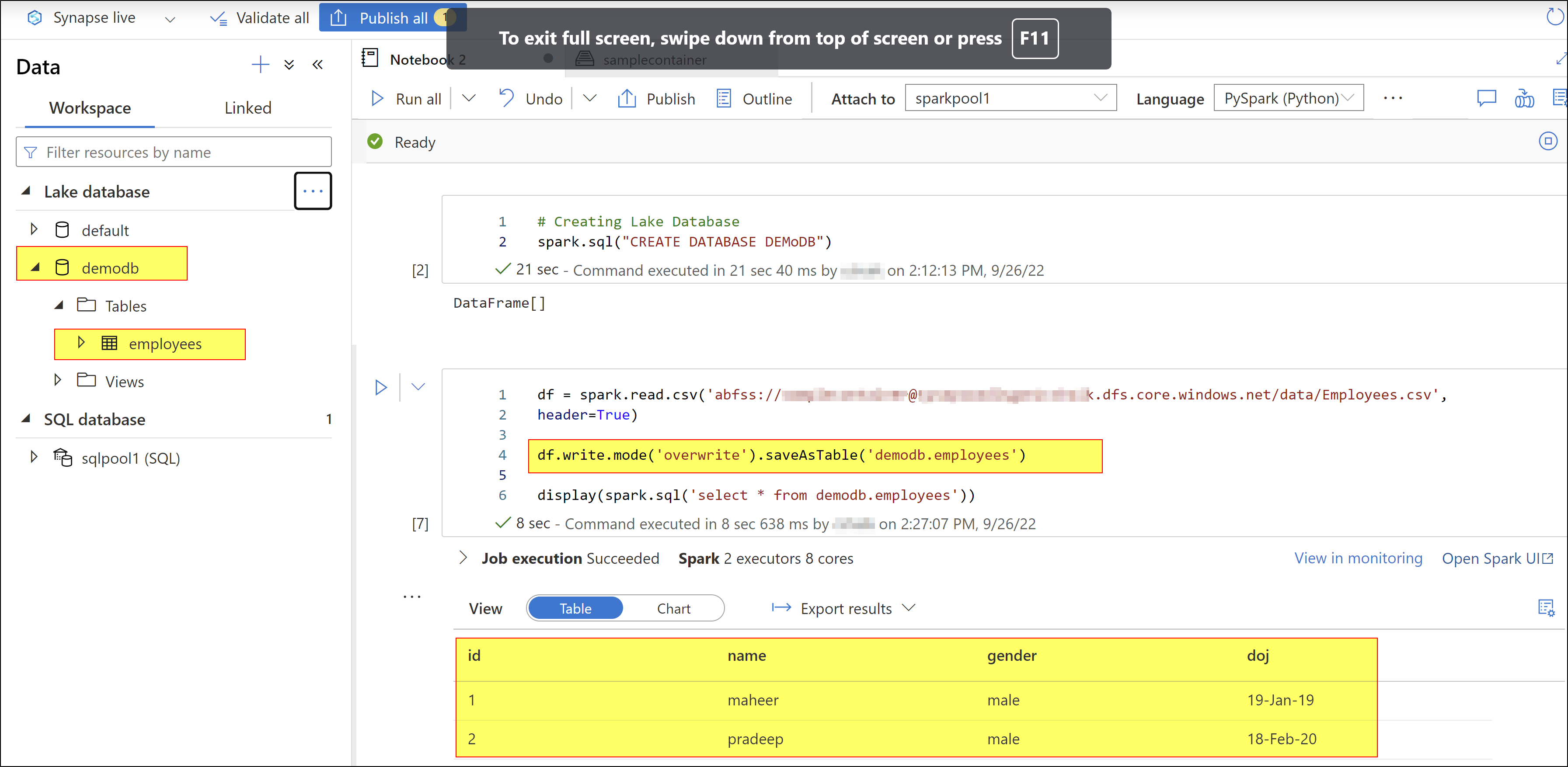
I tried to reproduce your requirement. Here, I created a new database named 'DemoDB' .
Afterwards, I am trying to read a .csv file from my ADLS and loaded it into a dataframe using the code df= spark.read.csv('<filepath>')
Then, I am loading the dataframe content into table in DemoDB database using the following code:
df.write.mode('overwrite').saveAsTable('demoDB.employees')
For more details, kindly check the following video: Analyze data with Server less Spark Pool in Azure Synapse Analytics
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.
Hi @AnnuKumari-MSFT ,
And thank you for looking into this. I think this works because you have permission to write to the storage account the data is saved in.
In my case, the default storage is a different lake that I only have read access to. If I try and execute the above, I get the same error as previously:
AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: MetaException(message:Got exception: java.nio.file.AccessDeniedException Operation failed: "This request is not authorized to perform this operation using this permission.", 403, HEAD, https://<"storage account">.dfs.core.windows.net<"folder path">/warehouse?upn=false&action=getStatus&timeout=90)
Hi @Johan á Rogvi-Hansen ,
Kindly provide Storage Blob Data contributor access to the synapse managed identity on the storage account from which you are trying to read the data. Also, kindly provide the same role to the active directory ID from which you are accessing the synapse workspace. Please let us know if it works. Thankyou.
------------
If the above answer helped, Please do consider clicking Accept Answer and Up-Vote for the same as accepted answers help community as well.
The issue is not that I can't read the data, the issue is that I can't write the data, specifically, that specifying the path to the storage account I want to write to is not having any effect, i.e. I get an error that I can't write to the default storage account (because I don't have permission, and won't get it either) even though I'm specifying the path of a storage account that I do have write permission to.
Hi @ JohanRogviHansen-5394 ,
Kindly check both AAD identity as well as Synapse workspace MSI has the Storage blob data contributor role to the storage account.
Please Check Using the workspace MSI to authenticate a Synapse notebook when accessing an Azure Storage account for more details.
Let me try and phrase it again:
There are two storage accounts, one which is the default and one which is not. The one which is default, I won't have and will not get 'storage blob data contributor' role - I'm only allowed to read data from that storage account.
The one which is not default is the one I'm trying to write to and both I and the Synapse MSI have the 'storage blob data contributor' role. The issue is, if I use the function '.saveAsTable()' defining both database and the path to this storage account, it throws an error saying I do not have permission to write to the default storage account. This doesn't make sense to me, as I have specified a different path.
Thus, it is not an issue with the role access.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJM%3C/text%3E%3C/svg%3E)
I am trying this, but it doesn't work. I get "database xyz is not found" error message even when the database clearly exists same as in your screenshot.
Edit: Needed to commit my new Lakehouse DB to Contributor branch for it to become a real boy.