Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
9,487 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.

Hi,
I try to use "Unpivot" transformation on a Source that don't have schema pre-defined (Schema Drift is activated).
The "unpivot" transformation generates the following error:
Error: DF-SYS-01 at : scala.MatchError: 1 (of class java.lang.Integer) - RunId: 700ee826-2737-4a4a-b9bb-daf65b52fb31
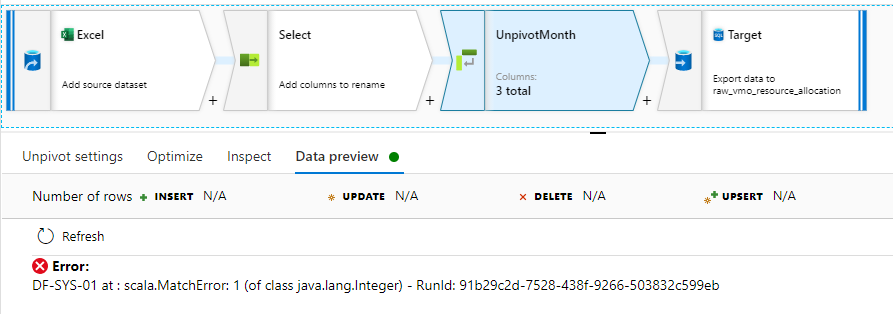
Could you help me understand the meaning of this error and how to fix it?
Is "unpivot" unable to work with schema drift?
For information, I put more detail about the other component below.
The input file looks like this:
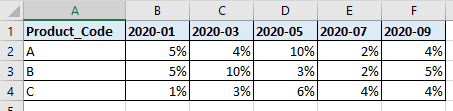
The file format will change regularly, a new column will be added every month, so I want to use Schema Drift.
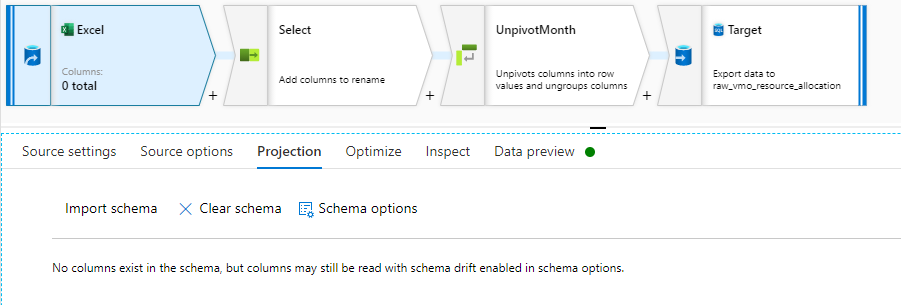
The source looks like this:
As you can see there is no schema prepared.
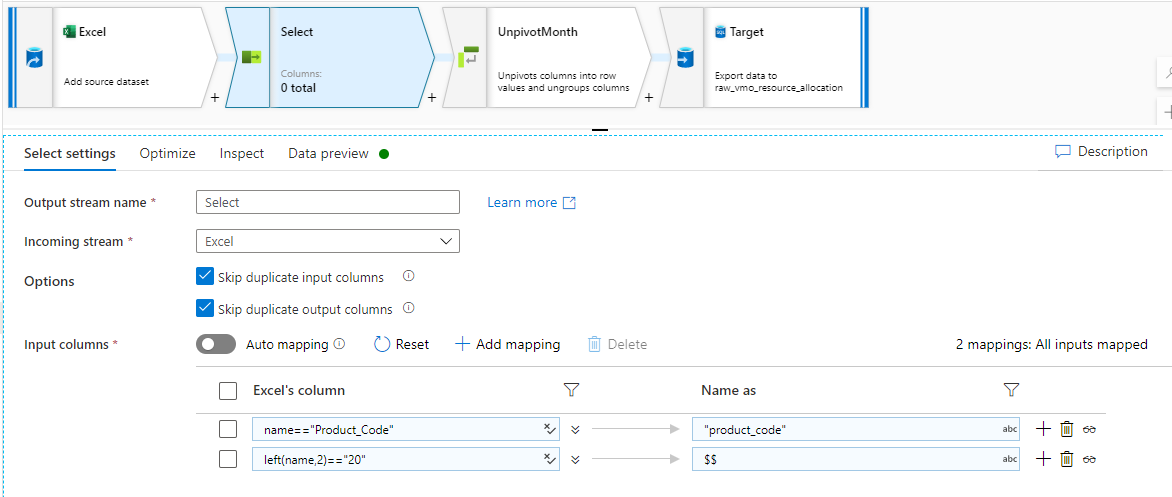
My select transformation looks like this:
I retrieve the product code by using "name" and I retrieve all columns prefixed by 20 (ex: 2020-01)
The unpivot is configured as follow, using "byName" to retrieve the product code column:
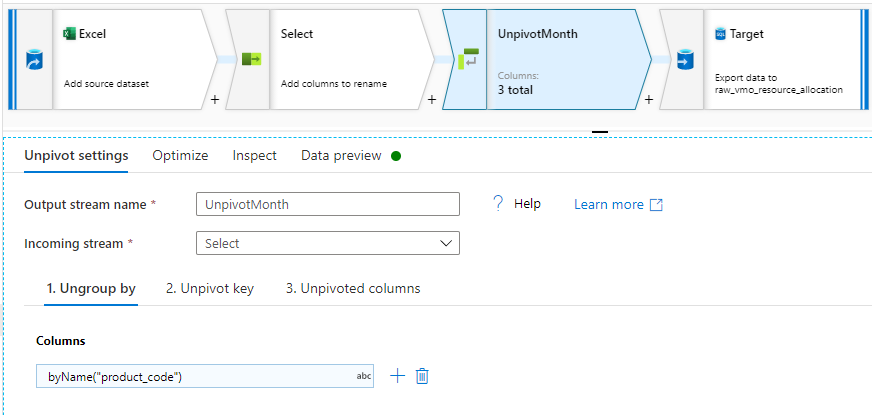
I create a column year_month which will contain the column headers that have been unpivoted.
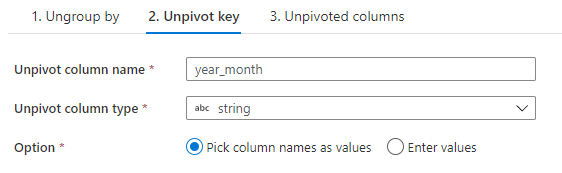
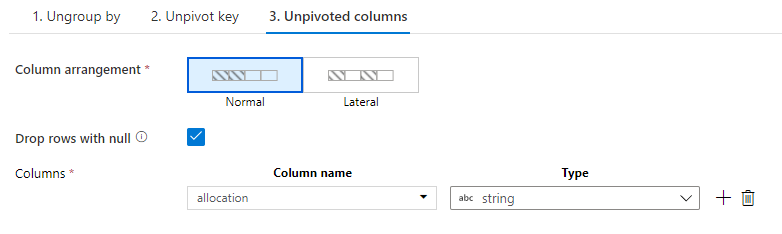
I create a column allocation which will contain the values that have been unpivoted.
If you have any other suggestion I'm happy to hear too.
Thank you
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKM%3C/text%3E%3C/svg%3E)
Can you post what the DSL script looks like? (Click on the script NOT code button on top right)
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
Hello @Pestre Remi and welcome to Microsoft Q&A.
I have attempted to reproduce your issue. See below images. Slight alteration, I used auto-mapping in the select.



Which step did you error happen in?
@Pestre Remi
Actually I reproduced it now. In last attempt I forgot to get rid of the schema.
@Kiran-MSFT the script is:
source(allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false) ~> source1
source1 select(mapColumn(
each(match(name == "Product Code"),
"product_code" = $$),
each(match(left(name, 2) == "20"))
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> Select1
Select1 unpivot(output(
year_month as string,
allocation as string
),
ungroupBy({Product Code} = byName("product_code")),
lateral: false,
ignoreNullPivots: false) ~> Unpivot1
This looks more complicated that it needs to be. You can do something as simple as
yearly derive(
Product_Code = byName("Product_Code")
) ~> yearlyDerived
yearlyDerived unpivot(output(
year_month as string,
allocation as string
),
ungroupBy(Product_Code),
lateral: false,
ignoreNullPivots: false) ~> unpivotYearly
Unpivots do not allow expressions or assignments in ungroupBy expressions. The validation error will be made more user friendly
To make things far simple and avoiding byName, you can open the script and type
source(
output(
Product_Code as string
),
....
)
This will add Product_Code as a named column and rest of the columns will be drifted. The UI controls don't directly have this facility but you can edit the script and add this snippet.
Then you just need to unpivot nothing else.
yearlyDerived unpivot(output(
year_month as string,
allocation as string
),
ungroupBy(Product_Code),
lateral: false,
ignoreNullPivots: false) ~> unpivotYearly
Thank you all for your help.
After some attempts, I have been able to achieve it by adding a "Derived Column" step before the Unpivot and by creating the Product_Code column. The unpivot can then use this column directly.

I guess it's very similar to the approach that was suggested above.