@Scott Mallory
CrashLoopBackOff means the pod has failed/exited unexpectedly/has an error code that is not zero.
There are a couple of ways to check this. I would recommend to go through below links and get the logs for the pod using kubectl logs.
Debug Pods and ReplicationControllers
Determine the Reason for Pod Failure
Use kubectl describe to get more data on the pod failure. If you do not see the issue when creating more pods on the node, then let a pod run on a single node to see how much resources it actually utilizes. There are other options such as reading Kubelet logs and more. This is the base I would suggest that could solves the issue.
A pod can also be in CrashLoopBackOff if it has completed and it’s configured to keep restarting (even with exit code 0). A good example is when you deploy a busybox image without any arguments: it will start, execute, and finish. It will keep restarting.
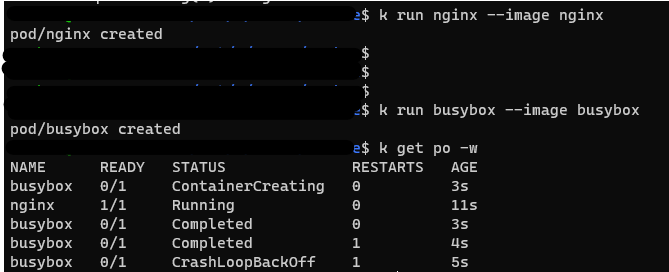
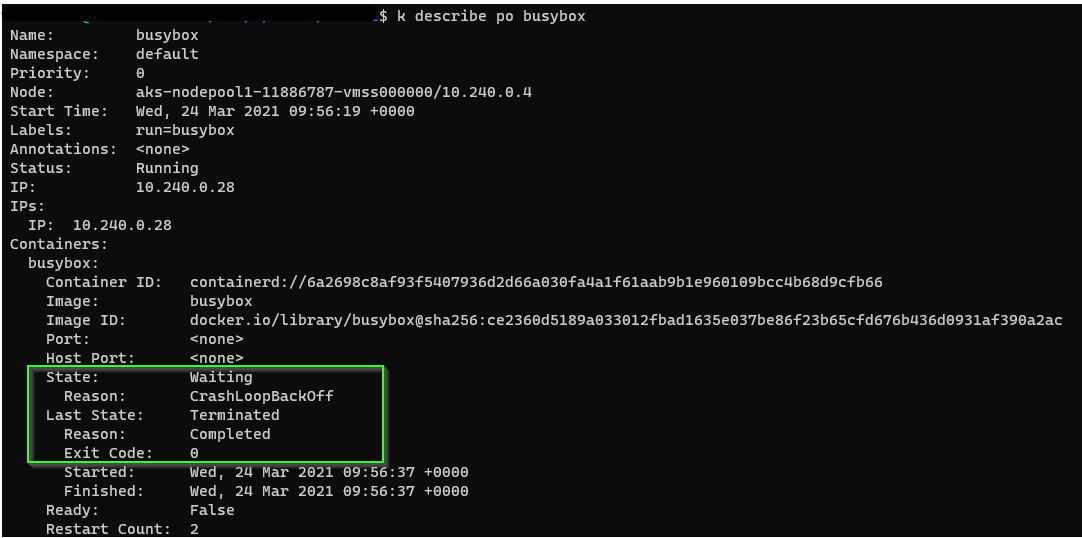
Hope this helps.
Please 'Accept as answer' if the provided information is helpful, so that it can help others in the community looking for help on similar topics.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESM%3C/text%3E%3C/svg%3E)
