Azure Cosmos DB
An Azure NoSQL database service for app development.
1,440 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMB%3C/text%3E%3C/svg%3E)
Hi, I am facing issue to store Unicode car with accent in CosmosDB, after loading the data from csv file using Azure CosmoDB data migration tool é for example is converted to �, so Héctor is converted to H�ctor !
In the first place I thought it's Azure portal render issue, but I was wrong, I have the same result using Azure Storage Explorer and in Xamarin app, any idea how to fix this issue, seems there is no concept off collation in azure CosmoDB
Best regards
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ENS%3C/text%3E%3C/svg%3E)
Please confirm which API you are using for Azure Cosmos DB. Also confirm how you are checking the data has changed e.g. with Data Explorer etc.
Regards
Navtej S
Hi, I am using SQL Api and use Azure CosmoDB data migration tool for data migration and Azure Data Explorer and Azure Portal to validate the data, the issue with accent caracters (é for example converted to �) seems to be generated by the data migration tool, if I update � to é manually in Azure Portal, I can see the correct character in Azure Portal, in Azure Storage Explorer and in Xamarin mobile app
Best regards
Also, this is very easy to reproduce the issue, create a scv file with one line:
Héctor Bellerín
and after you upload the data in Cosmodb new collection, this will be converted to
Hé�tor Beller�n
Best regards
Our team has suggested few things for you to test:
"There is no “team responsible for the data migration tool”. It is provided as a free, open-source example with community contributions and no intrinsic support provision. Customers with a Premier contract can lean on their Premier support contacts for paid assistance with custom code (including this).
From my keyboard to the customer, it doesn’t seem to have come through quite how complicated this is at the byte level if they are relying on screenshots. LibreOffice has its own encoding habits, expectations, and bugs. Sharing a screenshot doesn’t tell us what bytes are landing on disk to be then interpreted by the migration tool; instead, you can use this tiny PowerShell command: Get-Content -Encoding Byte -Path "path:\to\file.csv"
To put some concrete examples to this, I can produce four files with different bytes on disk that all open in Notepad appearing to show “Héctor”.
In the simplest case (new file, copy-paste the string, default save encoding), Notepad writes the file with no header, encodes the e-with-rising-accent as bytes 0xC3A9, and encodes the other 5 letters with their ANSI values such that the full file is 0x48C3A963746F72.
The same string, saved with the ANSI encoding setting: still no header, but the e-with-rising-accent uses its ANSI character 233 / 0xE9 with a full file of 0x48E963746F72.
The same string, saved with UTF-8 with BOM: header of 0xEFBBBF, e-with-rising-accent encoded as 0xC3A9 and all five other characters encoded with ANSI bytes resulting in: 0xEFBBBF48C3A963746F72
The same string pasted into PowerShell and written using Out-File: header of 0xFFFE, all six letters using their ANSI values but padded to 2 bytes (little endian), resulting in a full file of: 0xFFFE4800E900630074006F007200
I will reiterate that all four files look identical when opened in a GUI like Notepad. The only step forward here is to use a tool like the PowerShell command I mentioned above to extract the raw bytes, which may be able to pin down where the tools are disagreeing."
Please check this and get back to us with your questions.
Regards
Navtej S
Hi NavtejSaini
We have saved the csv file in UFT8 format instead of ANSI default format and the import worked fine, all accent characters have been imported to CosmoDB correctly
Thank you very much for your help
@Mohamed B We are glad this issue is resolved for you and we could help. Please do accept the answer it helped.
Regards
Navtej S
We had raised this issue with our internal team. Here is the response:
Cosmos will emit whatever bytes were sent to it. What those bytes mean is dependent on the client application(s) and if you have two client applications with different encoding expectations, then you will see issues like this.
Storing Unicode in flat files has a long and sordid history of problems and incompatible implementation tricks, and that’s where I suspect your issue lies. The migration tool you’re referring to uses a .Net System.StreamReader to do (most of) the heavy lifting of reading file bytes and interpreting them into .Net characters and strings which uses the System.Text.Encoding to guess at the intended encoding for the file – which may or may not match the expectations and encoding used by whatever tool created your test file. And just to make things even more confusing, some text editors understand multiple of these encoding methods and will preserve whatever the previously-seen encoding method was in the file during editing but will use a different (preferred) one when creating a new file from scratch.
Please let us know if you need any further info.
Regards
Navtej S
Hi
Thanks for the clarification, our need is very basic, we need a tool that can migrate the data from a csv file to CosmoDB and keep the special caracters (like accent caracter é), please F.W this request to the team responsible for Azure CosmoDB Data migration tool, they can use a csv file with 1 line for tests:
Héctor Bellerín
here is the print screen with the issue we are facing now when we upload the csv file
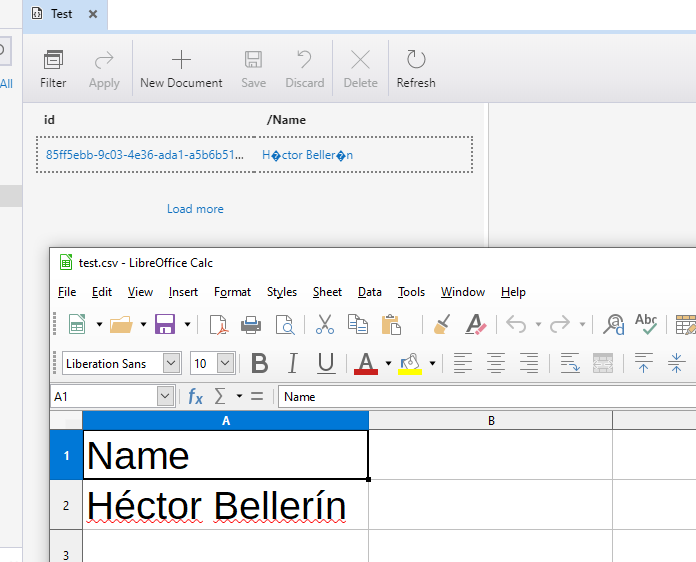
Best regards
@Mohamed B We are checking this,