Azure AI Speech
An Azure service that integrates speech processing into apps and services.
1,391 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EVT%3C/text%3E%3C/svg%3E)
Hello everybody,
i have just discovered the speech to text APIs and I'm amazed by them.
I use a power automate flow to transcript the audio files.
I have noticed though that the running time needed for the transcription varies in quite a relevant way: a fresh example, an audio POSTed for transcription with length 1:14:36 (mono) was successfully transcribed in 01:19:17, whereas a file lasting 03:14:59 (mono) has been running for 11:22:05 (and counting).
The parameter provided are always the same, namely:
"locale": "pl-PL",
"properties": {
"wordLevelTimestampsEnabled": "true",
"diarizationEnabled": "true",
"profanityFilterMode": "none",
"punctuationMode": "DictatedAndAutomatic"
}
So my question is, where can i find information on what impact the speed of the transcription?
Thank you in advance!
Best regards,
Vittorio
Addendum: could it be an issue of diarization and possibly more than 2 speakers (usually the audios are axtracted from meetings)?

@Vittorio Tison It looks like your second file transcription might be stuck in processing state because batch transcription jobs are scheduled on a best effort basis and we cannot estimate when a job will change into the running state, but it should happen within minutes under normal system load. Once in the running state, the transcription occurs faster than the audio runtime playback speed. I think this transcription might go into failed state or you can request for this to be terminated by raising a support issue.
With respect to diarization with the batch transcription API it is only possible for 2 users without enrollment. The API could be extended to support more users in the future. If the audio contains more than two speakers now it would not be able to process the file correctly, You can disable diarization and try again in this case. Thanks.
Hi @romungi-MSFT , thank you for your reply.
I am not sure i understand the meaning of processing state: from a "TranscriptionStatus" perspective, it switched into "Running" almost immediately, and ran for almost 15h (see the excerpt from the flow below)... more than 4 times the length of the audio... but maybe this occurred because of the diarization... could it be?
Anyway, from now on i will turn off the diarization as per your suggestion, thanks.
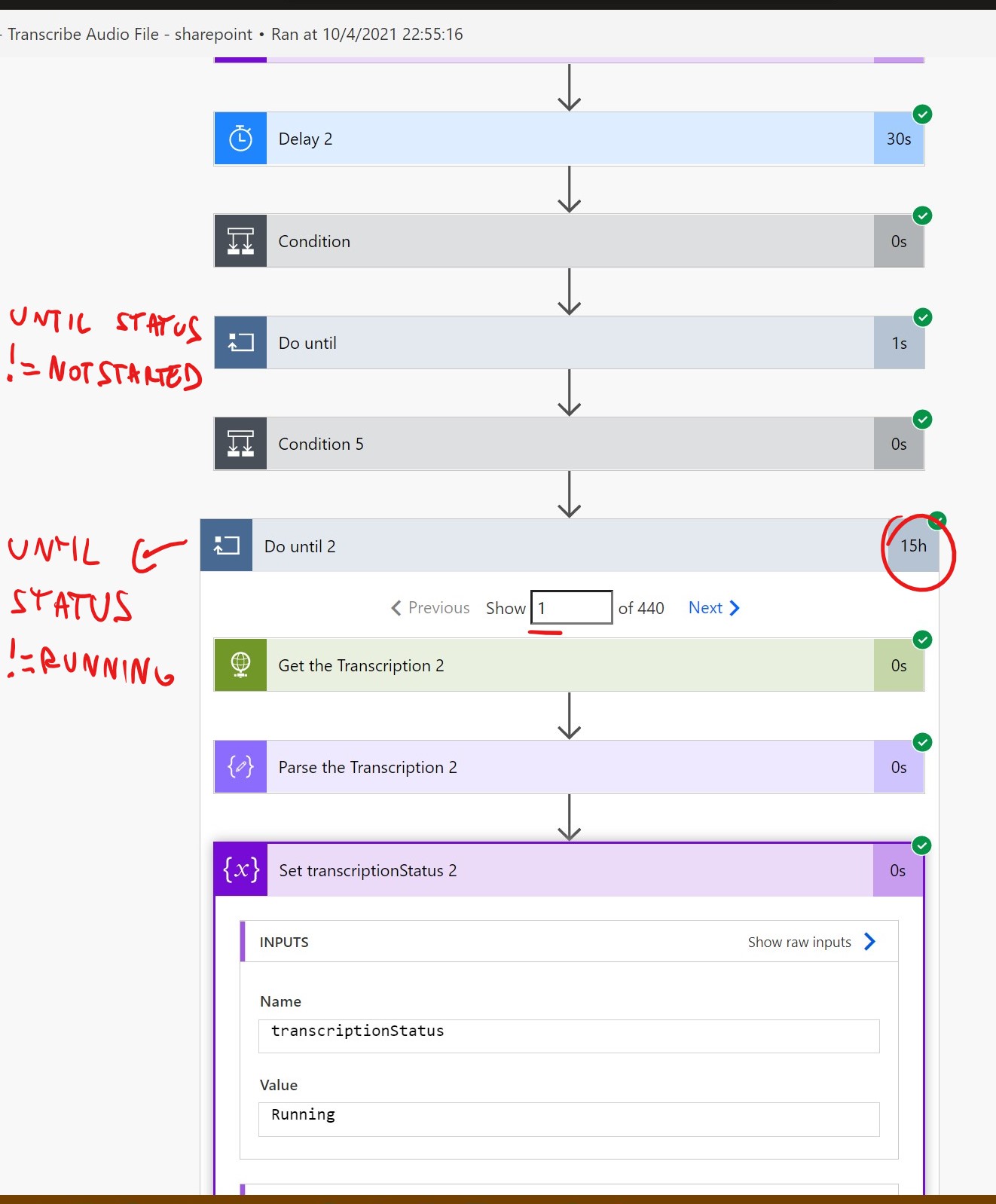
@Vittorio Tison I don't think the delay is due to diarization being turned on. Based on my experience it will try to list only Speaker 1 and 2 from the entire audio even though there are more than 2. The recommendation is to use this only there are 2 speakers, This particular file might be stuck in processing due to some other reason though.