Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
4,358 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EGH%3C/text%3E%3C/svg%3E)
Hello,
In Azure Synapse Analytics studio I am trying to access data from a view from a data warehouse.
It works when I am using SQL, but not when I try to excecute Scala or PySpark code from a notebook.
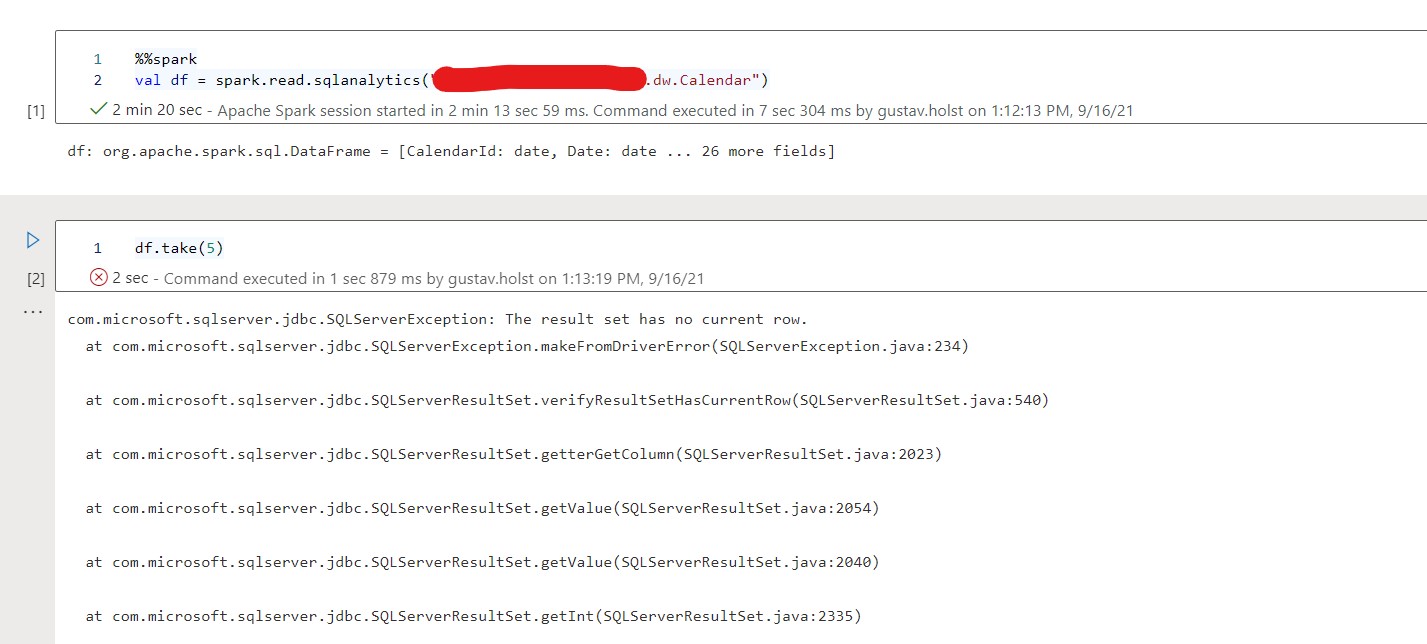
In the attached image we can see that the first cell runs without any problems.
It also outputs the correct headers.
However, when I try to do anything with the dataframe stored in the variable df (see cell 2) I recieve the following error:
com.microsoft.sqlserver.jdbc.SQLServerException: The result set has no current row.
at com.microsoft.sqlserver.jdbc.SQLServerException.makeFromDriverError(SQLServerException.java:234)
at com.microsoft.sqlserver.jdbc.SQLServerResultSet.verifyResultSetHasCurrentRow(SQLServerResultSet.java:540)
at com.microsoft.sqlserver.jdbc.SQLServerResultSet.getterGetColumn(SQLServerResultSet.java:2023)
at com.microsoft.sqlserver.jdbc.SQLServerResultSet.getValue(SQLServerResultSet.java:2054)
at com.microsoft.sqlserver.jdbc.SQLServerResultSet.getValue(SQLServerResultSet.java:2040)
at com.microsoft.sqlserver.jdbc.SQLServerResultSet.getInt(SQLServerResultSet.java:2335)
at com.microsoft.spark.sqlanalytics.utils.Utils$.getTableTypeAndId(Utils.scala:224)
at com.microsoft.spark.sqlanalytics.read.SQLAnalyticsReader$PlanInputPartitionsUtilities$.extractDataAndGetLocation(SQLAnalyticsReader.scala:209)
at com.microsoft.spark.sqlanalytics.read.SQLAnalyticsReader.planBatchInputPartitions(SQLAnalyticsReader.scala:119)
at org.apache.spark.sql.execution.datasources.v2.DataSourceV2ScanExec.batchPartitions$lzycompute(DataSourceV2ScanExec.scala:84)
at org.apache.spark.sql.execution.datasources.v2.DataSourceV2ScanExec.batchPartitions(DataSourceV2ScanExec.scala:80)
at org.apache.spark.sql.execution.datasources.v2.DataSourceV2ScanExec.outputPartitioning(DataSourceV2ScanExec.scala:60)
at org.apache.spark.sql.execution.exchange.EnsureRequirements$$anonfun$org$apache$spark$sql$execution$exchange$EnsureRequirements$$ensureDistributionAndOrdering$1.apply(EnsureRequirements.scala:150)
at org.apache.spark.sql.execution.exchange.EnsureRequirements$$anonfun$org$apache$spark$sql$execution$exchange$EnsureRequirements$$ensureDistributionAndOrdering$1.apply(EnsureRequirements.scala:149)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.immutable.List.foreach(List.scala:392)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:234)
at scala.collection.immutable.List.map(List.scala:296)
at org.apache.spark.sql.execution.exchange.EnsureRequirements.org$apache$spark$sql$execution$exchange$EnsureRequirements$$ensureDistributionAndOrdering(EnsureRequirements.scala:149)
at org.apache.spark.sql.execution.exchange.EnsureRequirements$$anonfun$apply$1.applyOrElse(EnsureRequirements.scala:327)
at org.apache.spark.sql.execution.exchange.EnsureRequirements$$anonfun$apply$1.applyOrElse(EnsureRequirements.scala:319)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$4.apply(TreeNode.scala:292)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$4.apply(TreeNode.scala:292)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:69)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:291)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$3.apply(TreeNode.scala:289)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$3.apply(TreeNode.scala:289)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$6.apply(TreeNode.scala:343)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:196)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:341)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:289)
at org.apache.spark.sql.execution.exchange.EnsureRequirements.apply(EnsureRequirements.scala:319)
at org.apache.spark.sql.execution.exchange.EnsureRequirements.apply(EnsureRequirements.scala:38)
at org.apache.spark.sql.execution.QueryExecution$$anonfun$prepareForExecution$1.apply(QueryExecution.scala:120)
at org.apache.spark.sql.execution.QueryExecution$$anonfun$prepareForExecution$1.apply(QueryExecution.scala:120)
at scala.collection.LinearSeqOptimized$class.foldLeft(LinearSeqOptimized.scala:124)
at scala.collection.immutable.List.foldLeft(List.scala:84)
at org.apache.spark.sql.execution.QueryExecution.prepareForExecution(QueryExecution.scala:120)
at org.apache.spark.sql.execution.QueryExecution$$anonfun$executedPlan$1.apply(QueryExecution.scala:102)
at org.apache.spark.sql.execution.QueryExecution$$anonfun$executedPlan$1.apply(QueryExecution.scala:102)
at org.apache.spark.sql.catalyst.QueryPlanningTracker.measureTime(QueryPlanningTracker.scala:97)
at org.apache.spark.sql.execution.QueryExecution.executedPlan$lzycompute(QueryExecution.scala:101)
at org.apache.spark.sql.execution.QueryExecution.executedPlan(QueryExecution.scala:94)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3375)
at org.apache.spark.sql.Dataset.head(Dataset.scala:2560)
at org.apache.spark.sql.Dataset.take(Dataset.scala:2774)
... 54 elided
I would appreciate any input on what might be the issue. I am a novice user of Spark DF:s and Azure in general.
Thank you!
Regards
Gustav
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESS%3C/text%3E%3C/svg%3E)
Hi @Gustav Holst ,
Thanks for using Microsoft Q&A !!
You are getting this error as querying SQL views from Spark pools is unfortunately not supported at this time. Please refer to the documentation to know more about connector limitations.
Also, it is recommended to use synapsesql() instead of using sqlanalytics() as this function will be deprecated in future. Refer to the above documentation.

Please let me know if you have any other questions.
Thanks
Saurabh
----------
Please do not forget to "Accept the answer" wherever the information provided helps you to help others in the community.
Hello Saurabh,
Ok, that makes sense. Thank you for your help, much appreciated!
Regards
Gustav