.NET
Microsoft Technologies based on the .NET software framework.
3,363 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESC%3C/text%3E%3C/svg%3E)
I am trying to run sentiment analysis with flair through an Apache Spark session using a Spark Pool in Azure Synapse Analytics. I need to have several packages that are not pre-installed in synapse, so I am using a .yml file to upload the packages I need to the notebook session I am using. The .yml file is a clone of the anaconda environment that I am using offline which imports all of the packages I need perfectly. Here is the .yml file as it exists:
name: ClusteringNotes
channels:
I followed the steps outlined in the documentation on how to upload a .yml file to a session and then clicked 'apply'. However, when I try to initiate the Spark session, I keep getting this error message:
LIBRARY_MANAGEMENT_FAILED: Livy session has failed. Session state: Error. Error code: LIBRARY_MANAGEMENT_FAILED. [plugins.ftml-synapse.NotesSparkPool.1b413213-b39b-41a4-bd31-3467dff21d9a WorkspaceType:<Synapse> CCID:<>] MaxClusterCreationAttempts=[3] Attempt=[0] ComputeNodeSize=[Medium] ClusterId=[ef827175-db51-46b1-8e18-0db706b9f1ae] AdlaResourceId=[] [Creation] -> [Cleanup]. The cluster creation has failed more than the [3] of times. IsTimeout=[False] IsTerminal=[True] IsRetryable=[False] ErrorType=[UserError] ErrorMessage=[LIBRARY_MANAGEMENT_FAILED] Source: User.
I would love to understand how I can quickly and efficiently upload env files to sessions so that I can actually complete my work. any help is GREATLY appreciated.

Hello @Samuel Cannon (Allegis Group Holdings Inc) ,
Welcome to the Microsoft Q&A platform.
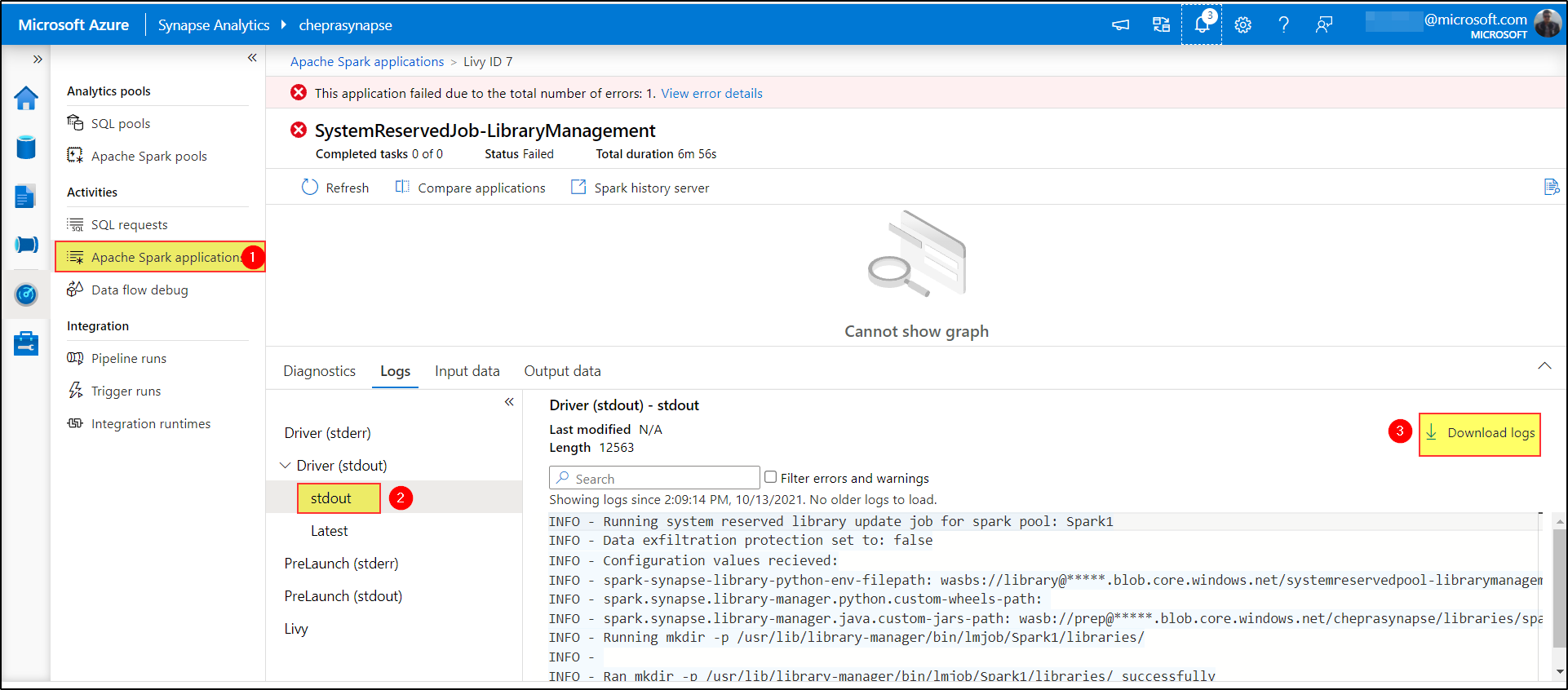
Could you please share the logs for the Apache Spark application which used to install the library?
Hello @Samuel Cannon (Allegis Group Holdings Inc) ,
Just checking in if you have had a chance to see the previous response. We need the following information to understand/investigate this issue further.
Hey! sorry for the late reply, I was able to solve this issue by essentially cutting down the .yml file to only the packages that I wanted installed, which begs the question of why we are suggesting uploading full .yml clones of anaconda envs instead of uploading a simple reqiurements.txt file like you are adding packages to a spark pool (not knocking it just curious), here is a picture of what I uploaded as a .yml file instead of the above .yml file I initially tried to upload:
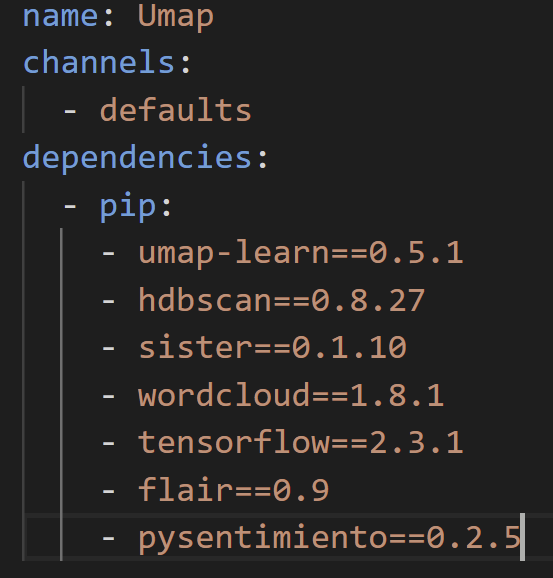
After I uploaded the .yml file this way it had no problems, but I essentially had to write a requirements.txt file in the .yml file format, I am delicately adding packages when I need to in order to see how many packages it will accept, but I feel like the process to upload these files on a session level could be improved to accept requirements.txt files instead, I also fear that if I do need to upload a fully cloned env from anaconda that I won't be able to do so...thank you so much for your response btw
Hello @Samuel Cannon (Allegis Group Holdings Inc) ,
This is excepted behaviour when you have long list of packages.
Glad to know that your issue has resolved. You can accept it as answer( ). This can be beneficial to other community members. Thank you.
). This can be beneficial to other community members. Thank you.
Pradeep,
so now that I have been able to upload the packages to the session level, the notebook runs, but once I upload the EXACT SAME .yml file to the spark pool, to add the packages to the pool itself, the notebook throws an error and tells me that I have the wrong packages installed. Why a I getting an error when uploading the same .yml file to the spark pool while I am not getting an error when it is uploaded at the session level?