Azure AI Speech
An Azure service that integrates speech processing into apps and services.
1,391 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKW%3C/text%3E%3C/svg%3E)
I would like to use the custom model trained by both text and audio( or pronunciation),
but now just text is supported in Japanese.
https://learn.microsoft.com/en-us/azure/cognitive-services/speech-service/language-support
Speech studio UI seems to be able to train the model by both audio and text, but there is a notification below;
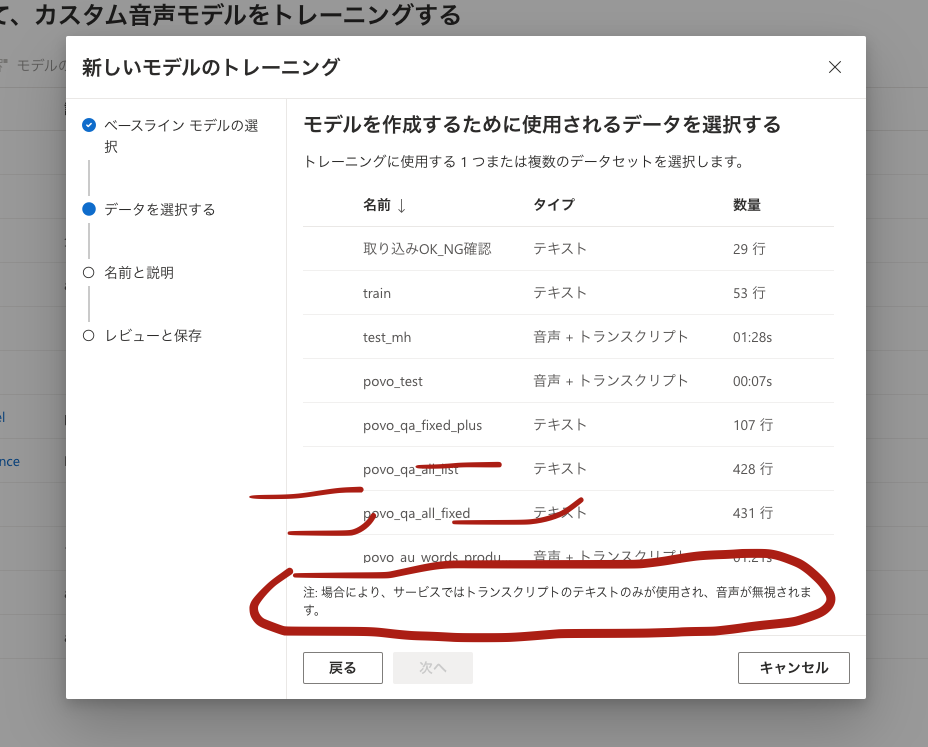
So maybe the feature of training the custom speech model by both audio and text is NOT supported in Japanese, right?
If so, do you have a plan to support the Japanese custom model to train by both text and audio?
I would like to know the roadmap of Azure Speech-to-Text.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EGM%3C/text%3E%3C/svg%3E)
Hi, currently, you can customize by text only. Roadmap information for voice isn't available at the moment.
--- *Kindly Accept Answer if the information helps. Thanks.*