Azure Databricks
An Apache Spark-based analytics platform optimized for Azure.
1,915 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJB%3C/text%3E%3C/svg%3E)
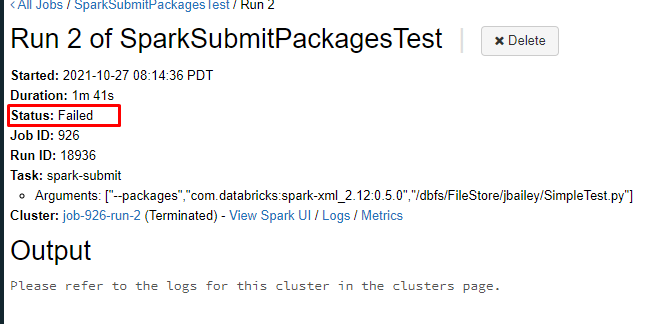
We run spark-submit jobs in databricks and I would like to use databricks 9.1. However, passing maven packages in the --packages parameter on any version of databricks newer than 8.2 causes an exception when initializing the job:
Exception in thread "main" java.lang.ExceptionInInitializerError
at com.databricks.backend.daemon.driver.WSFSCredentialForwardingHelper.withWSFSCredentials(WorkspaceLocalFileSystem.scala:157)
at com.databricks.backend.daemon.driver.WSFSCredentialForwardingHelper.withWSFSCredentials$(WorkspaceLocalFileSystem.scala:156)
To reproduce:
Spark submit job
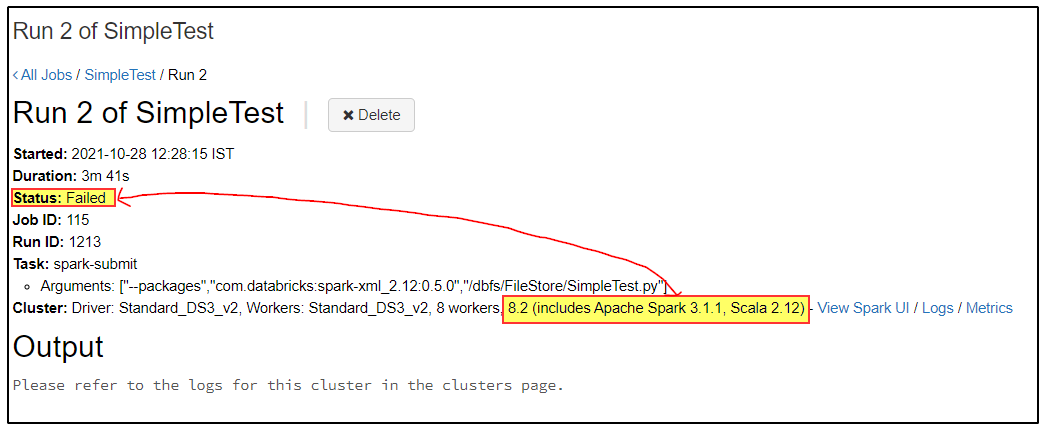
Runtime 9.1 LTS (running with 8.2 and below will succeed)
Standard DS3_v2 1 worker
Default options, no init scripts
["--packages","com.databricks:spark-xml_2.12:0.5.0","/dbfs/FileStore/jbailey/SimpleTest.py"]
SimpleTest.py:
import sys
from random import random
from operator import add
from pyspark.sql import SparkSession
if __name__ == "__main__":
"""
Usage: pi [partitions]
"""
spark = SparkSession\
.builder\
.appName("PythonPi")\
.getOrCreate()
partitions = int(sys.argv[1]) if len(sys.argv) > 1 else 2
n = 100000 * partitions
def f(_):
x = random() * 2 - 1
y = random() * 2 - 1
return 1 if x ** 2 + y ** 2 <= 1 else 0
count = spark.sparkContext.parallelize(range(1, n + 1), partitions).map(f).reduce(add)
print("Pi is roughly %f" % (4.0 * count / n))
spark.stop()

Hello @Jeff Bailey ,
Thanks for the question and using MS Q&A platform.
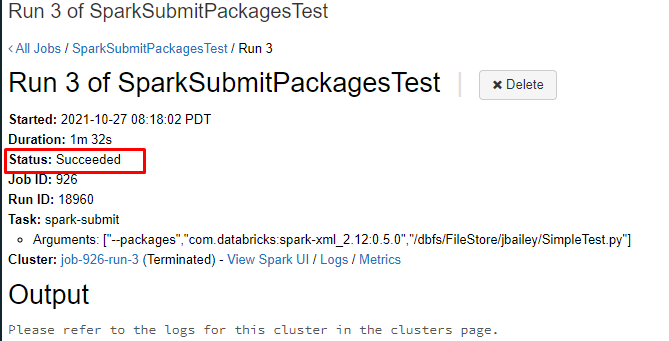
As per the repro from our side, we are unable to run the above sampleTest file on both 8.2 and 9.1 LTS runtime times?
SampleTest on DBR 9.0:
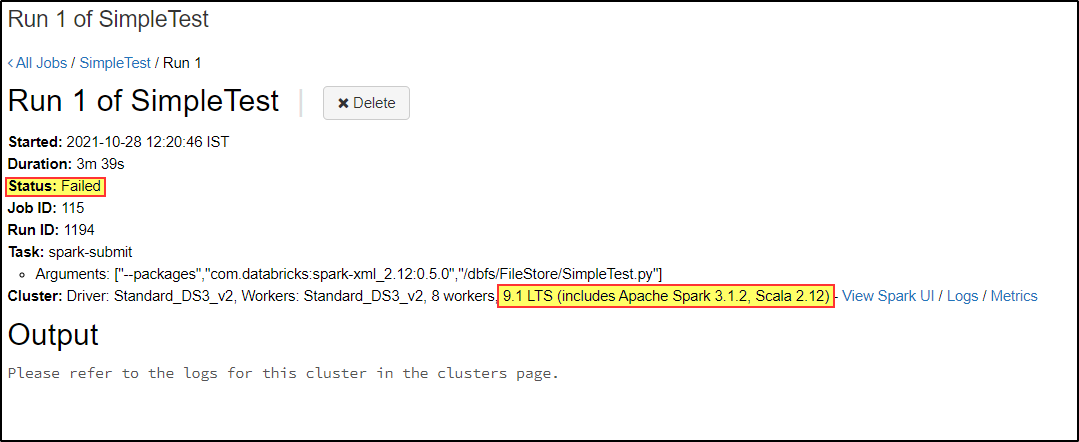
SampleTest on DBR 8.2:
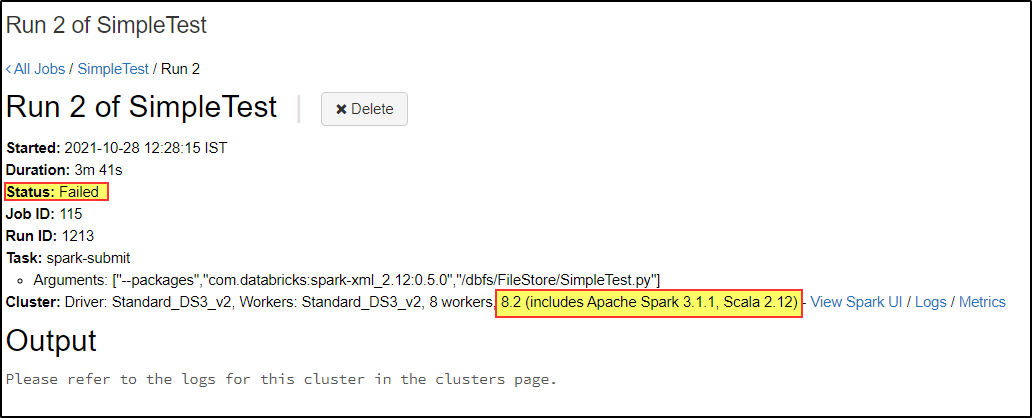
Note: I'm able to run this script in the interactive cluster with DBR 9.1 LTS.

Could you please helps with the both output of the both 8.2 and 9.1 LTS runtime times?
Thank you so much for your quick response. To clarify, the actual .py script is inconsequential. I pulled the sample one I am using from the spark samples just to eliminate any of my code from the equation. Here is the stderr results for both:
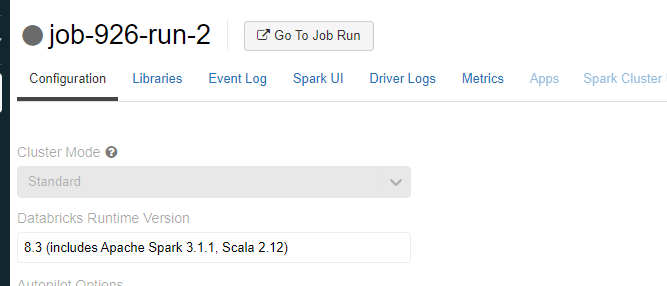
version 8.3:
OpenJDK 64-Bit Server VM warning: ignoring option MaxPermSize=512m; support was removed in 8.0
Warning: Ignoring non-Spark config property: libraryDownload.sleepIntervalSeconds
Warning: Ignoring non-Spark config property: libraryDownload.timeoutSeconds
Warning: Ignoring non-Spark config property: eventLog.rolloverIntervalSeconds
Ivy Default Cache set to: /root/.ivy2/cache
The jars for the packages stored in: /root/.ivy2/jars
com.databricks#spark-xml_2.12 added as a dependency
:: resolving dependencies :: org.apache.spark#spark-submit-parent-f55831a4-b299-495a-afee-f856d80be4cf;1.0
confs: [default]
found com.databricks#spark-xml_2.12;0.5.0 in central
downloading https://repo1.maven.org/maven2/com/databricks/spark-xml_2.12/0.5.0/spark-xml_2.12-0.5.0.jar ...
[SUCCESSFUL ] com.databricks#spark-xml_2.12;0.5.0!spark-xml_2.12.jar (20ms)
:: resolution report :: resolve 457ms :: artifacts dl 22ms
:: modules in use:
com.databricks#spark-xml_2.12;0.5.0 from central in [default]
| | modules || artifacts |
| conf | number| search|dwnlded|evicted|| number|dwnlded|
| default | 1 | 1 | 1 | 0 || 1 | 1 |
:: retrieving :: org.apache.spark#spark-submit-parent-f55831a4-b299-495a-afee-f856d80be4cf
confs: [default]
1 artifacts copied, 0 already retrieved (122kB/18ms)
Exception in thread "main" java.lang.ExceptionInInitializerError
at com.databricks.backend.daemon.driver.WSFSCredentialForwardingHelper.withWSFSCredentials(WorkspaceLocalFileSystem.scala:157)
at com.databricks.backend.daemon.driver.WSFSCredentialForwardingHelper.withWSFSCredentials$(WorkspaceLocalFileSystem.scala:156)
at com.databricks.backend.daemon.driver.WorkspaceLocalFileSystem.withWSFSCredentials(WorkspaceLocalFileSystem.scala:31)
at com.databricks.backend.daemon.driver.WorkspaceLocalFileSystem.getFileStatus(WorkspaceLocalFileSystem.scala:64)
at org.apache.hadoop.fs.Globber.getFileStatus(Globber.java:57)
at org.apache.hadoop.fs.Globber.glob(Globber.java:252)
at org.apache.hadoop.fs.FileSystem.globStatus(FileSystem.java:1657)
at org.apache.spark.deploy.DependencyUtils$.resolveGlobPath(DependencyUtils.scala:192)
at org.apache.spark.deploy.DependencyUtils$.$anonfun$resolveGlobPaths$2(DependencyUtils.scala:147)
at org.apache.spark.deploy.DependencyUtils$.$anonfun$resolveGlobPaths$2$adapted(DependencyUtils.scala:145)
at scala.collection.TraversableLike.$anonfun$flatMap$1(TraversableLike.scala:245)
at scala.collection.IndexedSeqOptimized.foreach(IndexedSeqOptimized.scala:36)
at scala.collection.IndexedSeqOptimized.foreach$(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.WrappedArray.foreach(WrappedArray.scala:38)
at scala.collection.TraversableLike.flatMap(TraversableLike.scala:245)
at scala.collection.TraversableLike.flatMap$(TraversableLike.scala:242)
at scala.collection.AbstractTraversable.flatMap(Traversable.scala:108)
at org.apache.spark.deploy.DependencyUtils$.resolveGlobPaths(DependencyUtils.scala:145)
at org.apache.spark.deploy.SparkSubmit.$anonfun$prepareSubmitEnvironment$4(SparkSubmit.scala:363)
at scala.Option.map(Option.scala:230)
at org.apache.spark.deploy.SparkSubmit.prepareSubmitEnvironment(SparkSubmit.scala:363)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:894)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:203)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:90)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:1030)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1039)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.lang.NullPointerException
at org.apache.spark.api.python.WsfsHttpClient.<init>(WsfsHttpClient.scala:27)
at com.databricks.backend.daemon.driver.WSFSCredentialForwardingHelper$.<init>(WorkspaceLocalFileSystem.scala:274)
at com.databricks.backend.daemon.driver.WSFSCredentialForwardingHelper$.<clinit>(WorkspaceLocalFileSystem.scala)
... 28 more
Version 8.2
OpenJDK 64-Bit Server VM warning: ignoring option MaxPermSize=512m; support was removed in 8.0
Warning: Ignoring non-Spark config property: libraryDownload.sleepIntervalSeconds
Warning: Ignoring non-Spark config property: libraryDownload.timeoutSeconds
Warning: Ignoring non-Spark config property: eventLog.rolloverIntervalSeconds
Ivy Default Cache set to: /root/.ivy2/cache
The jars for the packages stored in: /root/.ivy2/jars
com.databricks#spark-xml_2.12 added as a dependency
:: resolving dependencies :: org.apache.spark#spark-submit-parent-69e22c34-f6f8-41d3-80e3-40da82cf21ce;1.0
confs: [default]
found com.databricks#spark-xml_2.12;0.5.0 in central
downloading https://repo1.maven.org/maven2/com/databricks/spark-xml_2.12/0.5.0/spark-xml_2.12-0.5.0.jar ...
[SUCCESSFUL ] com.databricks#spark-xml_2.12;0.5.0!spark-xml_2.12.jar (16ms)
:: resolution report :: resolve 448ms :: artifacts dl 17ms
:: modules in use:
com.databricks#spark-xml_2.12;0.5.0 from central in [default]
| | modules || artifacts |
| conf | number| search|dwnlded|evicted|| number|dwnlded|
| default | 1 | 1 | 1 | 0 || 1 | 1 |
:: retrieving :: org.apache.spark#spark-submit-parent-69e22c34-f6f8-41d3-80e3-40da82cf21ce
confs: [default]
1 artifacts copied, 0 already retrieved (122kB/7ms)
Hello @Jeff Bailey ,
As per the repro, I had tested it of multiple Databricks Runtime, I never saw any of the job is succeeded.
This issue looks strange. For a deeper investigation and immediate assistance on this issue, if you have a support plan you may file a support ticket.
Pradeep, when it failed for you did it fail with the same exception I get?
Hello @Jeff Bailey ,
I got the same error message as you shared above but status of the Job shows as failed on each and every Databricks Runtime.