Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ED%3C/text%3E%3C/svg%3E)
I'm trying to flatten the following JSON structure in Azure Data Factory so that the users details roll up to the results.id. I have tried using an ADF Data Flow & the flatten transformation but results[] is the only selection available for 'unroll by' and 'unroll root' in the transformation settings. New to Azure ADF and JSON so any help or suggestions would be much appreciated.
Desired flattened result is:
results.id,users.full_name,users.photo_path,users.email_address,users.headline,users.generic,users.disabled,update_whitelist.full_name,update_whitelist.headline,update_whitelist.email_address,update_whitelist.phone
Sample JSON File Structure is below.
{
"count": 2,
"results": [
{
"key": "users",
"id": "1000000"
},
{
"key": "users",
"id": "2000000"
}
],
"users": {
"1000000": {
"full_name": "Jane Doe",
"photo_path": "https://www.google.com",
"email_address": "janedoe@Stuff .com",
"headline": "Senior Engineer",
"generic": false,
"disabled": false,
"update_whitelist": [
"full_name",
"headline",
"email_address",
"phone"
],
"account_id": "7777777",
"id": "1000000"
},
"2000000": {
"full_name": "John Doe,
"photo_path": "https://www.yahoo.com",
"email_address": "johndoe@réalisations .com",
"headline": "Senior Project Manager",
"generic": false,
"disabled": false,
"update_whitelist": [
"full_name",
"headline",
"email_address",
"phone"
],
"account_id": "7777777",
"id": "2000000"
}
},
"meta": {
"count": 2,
"page_count": 1,
"page_number": 1,
"page_size": 20
}
}

Hi @dmstech72 ,
Just following up to check if the below answer helped. Please do consider clicking Accept Answer as accepted answers help community as well.
This comment has been deleted due to a violation of our Code of Conduct. The comment was manually reported or identified through automated detection before action was taken. Please refer to our Code of Conduct for more information.

To access the attributes that are inside of arrays (i.e. results.id), use the Flatten transformation first. For the attributes that are properties of a struct (like users.full_name), you do not need to unroll first. After unrolling the array "results" with a Flatten transformation, add a Select transformation. Inside of the Select, you will now see those columns that you can pick from the Input columns list.
Hi @dmstech72 ,
Just checking in to see if the above answer helped. Please do consider clicking Accept Answer and Up-Vote for the same as accepted answers help community as well. If you have any further query do let us know.
Thank you for your feedback. I flattened (unrolled by results) then added a Select but the string data is still nested under the unique id structs (i.e. '1000000', '2000000'). See screenshots of select transformation data preview & sample schema below. I need the string objects under the '1000000' and '2000000' structs to be flattened into individual rows. Will be a nested struct for each unique user id so could have hundreds of these.
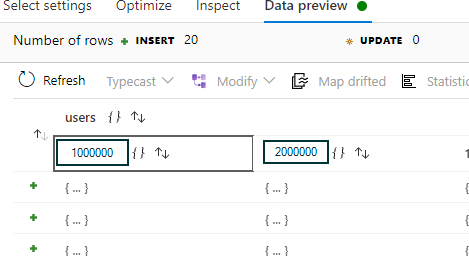

I've added an update with screenshots - perhaps missing something but still unable to flatten.
Hi @dmstech72 ,
Welcome to Microsoft Q&A platform and thanks for posting your query.
As I understand your issue, you want to flatten the provided JSON data . However, you are able to flatten the results[] but users property is not coming as an option in flatten transformation. Please let me know if my understanding about your query is incorrect.
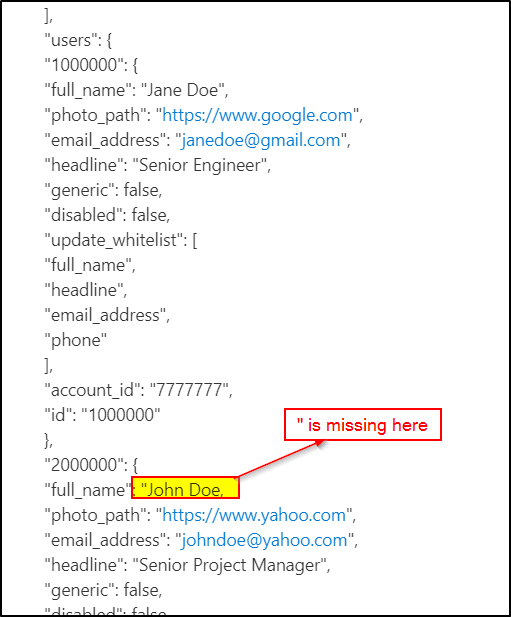
First of all, the JSON content which you have provided is invalid.
1. In the source transformation option, select Document form as 'Array of documents' . This is how your source data looks like: Results[] is an array but users is a JSON. So, we need to convert users Json to array in order to flatten the data within users property.
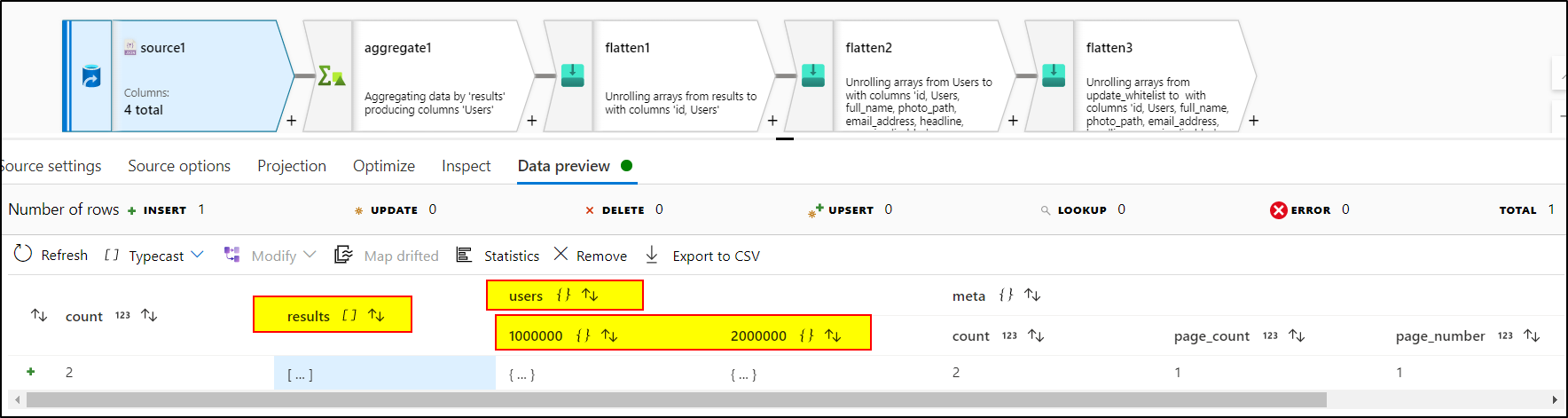
2. Use collect function inside aggregate transformation convert json object into array.
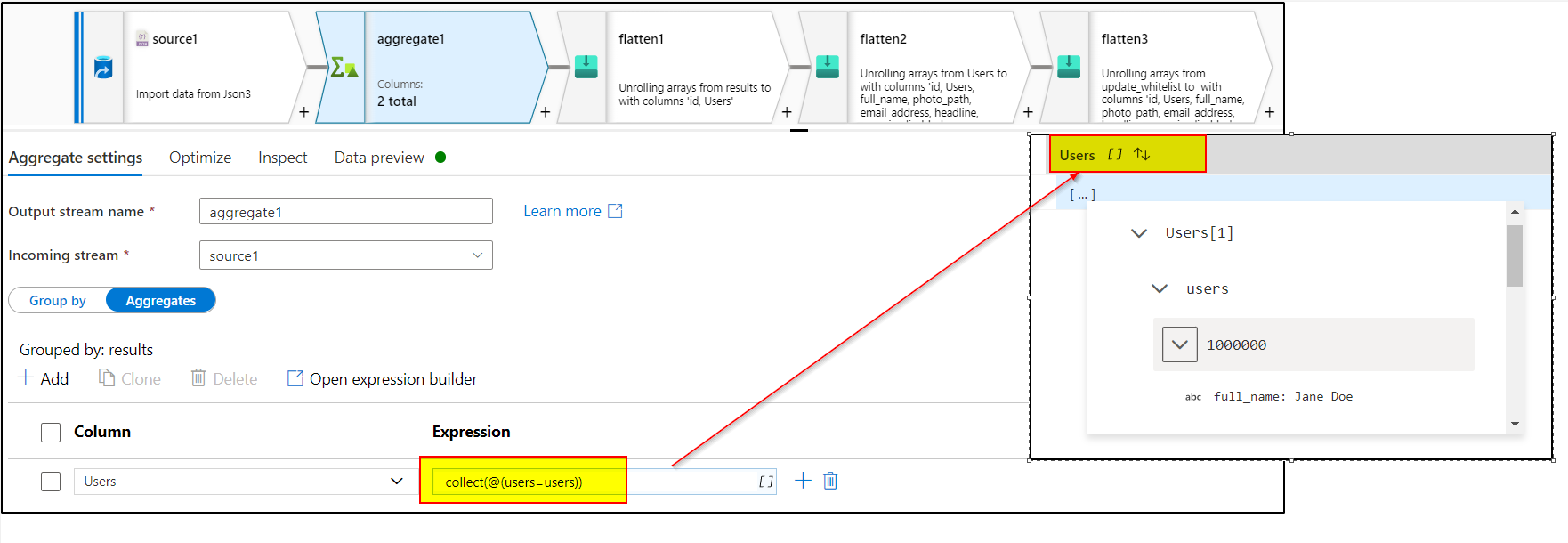
3. Unroll by results[] in first Flatten transformation
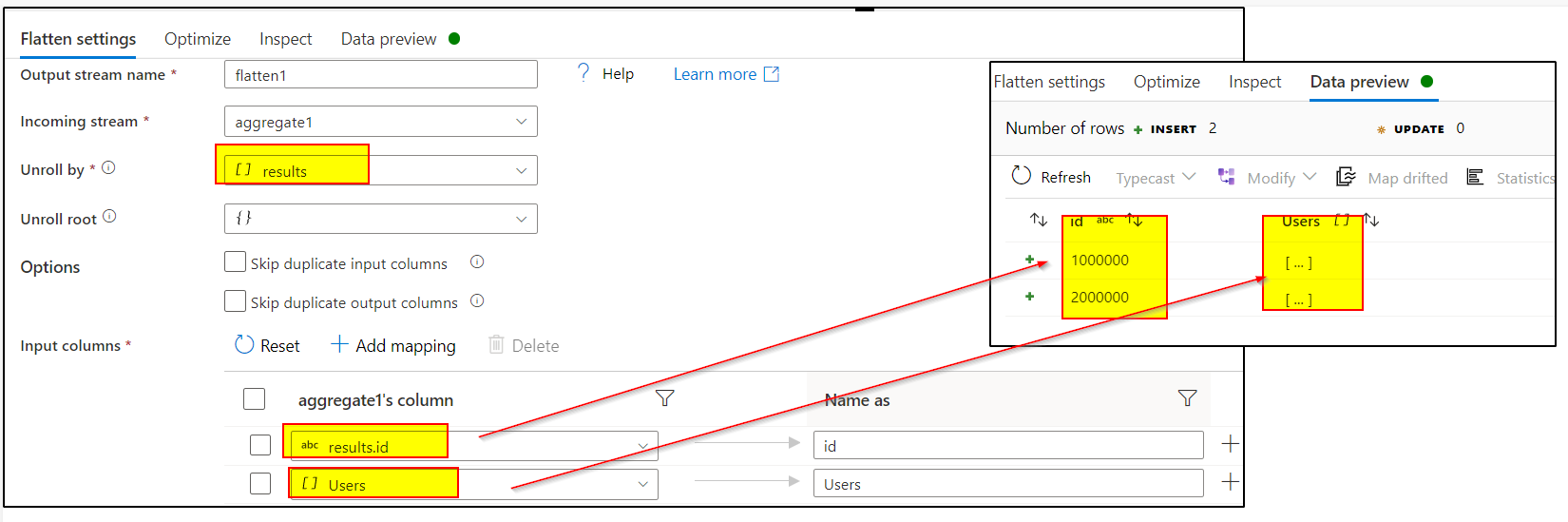
4. Use Flatten transformation again and unroll by users[] and select all the fields needed
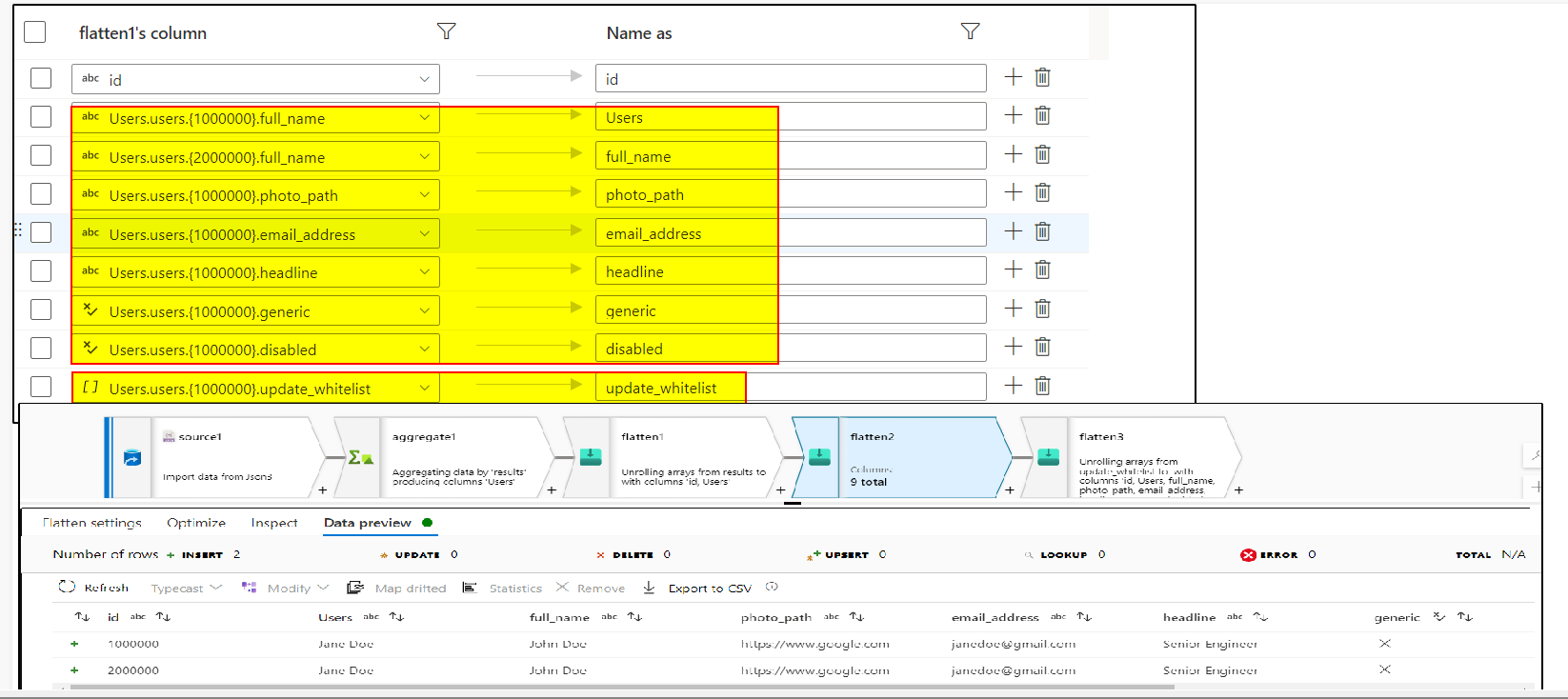
5. As the update_Whitelist[] array doesn't contain key-value pair , if we unroll it using another flatten transformation, it's gonna give us result like this, duplicating other columns :
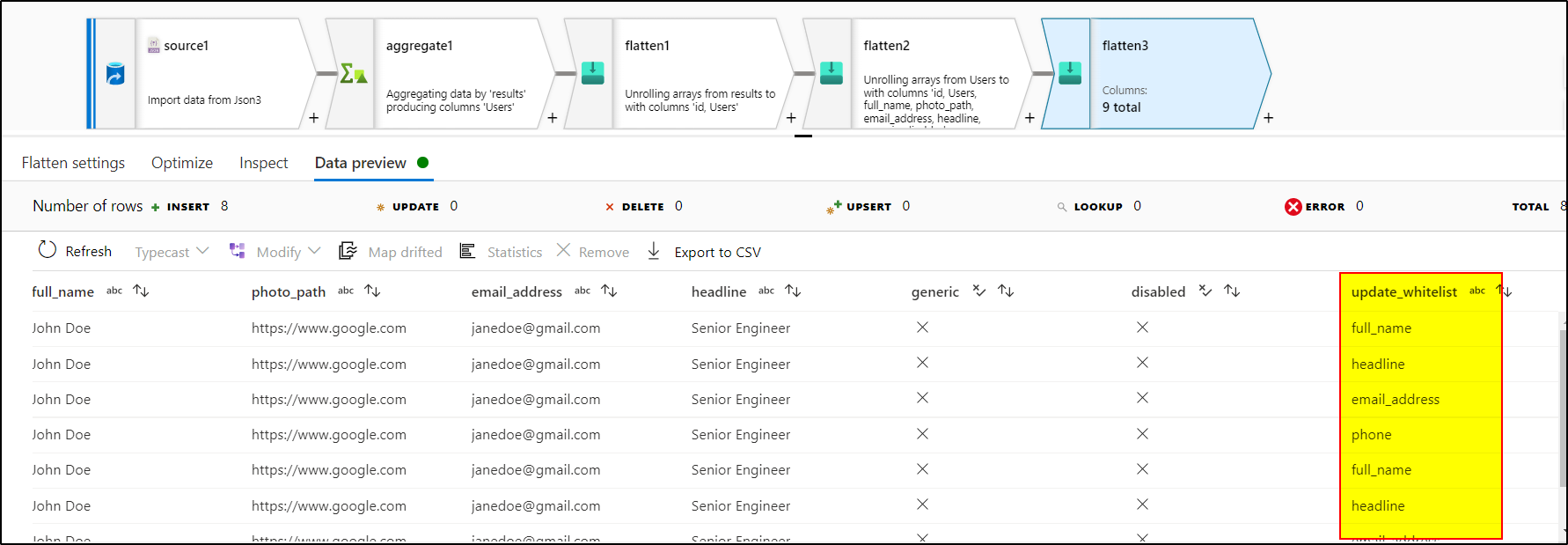
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.
Hi @dmstech72 ,
Just checking in to see if the above answer helped. Please do consider clicking Accept Answer and Up-Vote for the same as accepted answers help community as well. If you have any further query do let us know.
Hi @dmstech72 ,
Just following up to see if the above answer helped. Please do consider clicking Accept Answer and Up-Vote for the same as accepted answers help community as well. If you have any further query do let us know.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJK%3C/text%3E%3C/svg%3E)
I have the exact same data source from a REST API. However when i follow your steps, i get stuck with an issue at the source: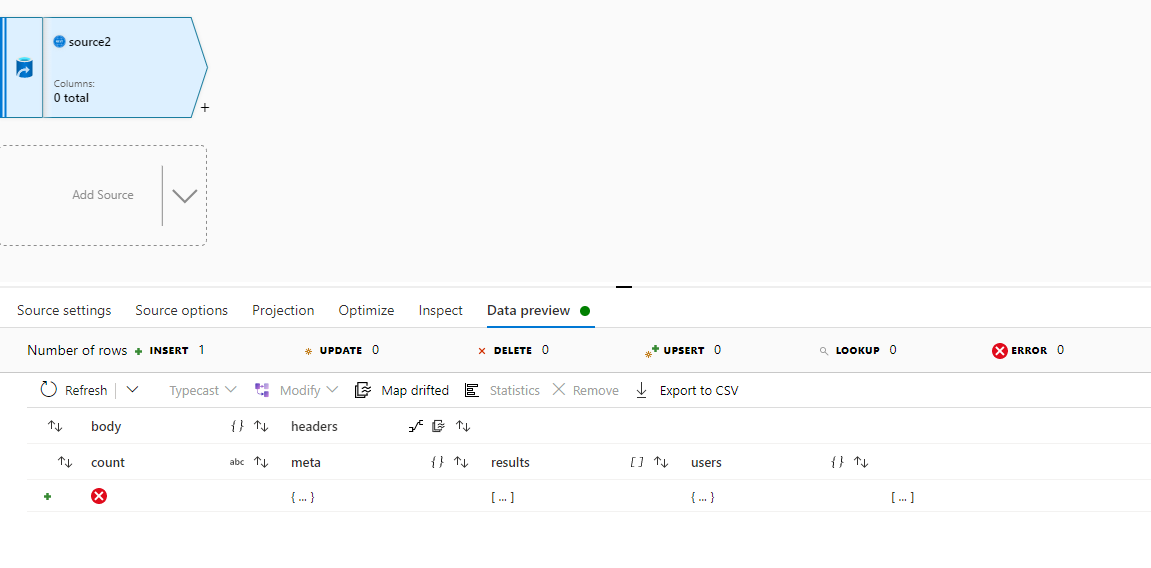
@AnnuKumari-MSFT i really need help on this ASAP, I am still stuck on the above screenshot, please help!
Hi @James Klein ,
Since I used the JSON file as source instead of REST API, it didn't give me any error related to Source.
If the URL which you are trying to hit is a public URL, could you please share the same?
I assume, in case if it's a public URL, the above error is due to too many requests hitting at the same time.
Could you please test the URL is working as expected using some third party tool eg: POSTMAN?
If it's working as expected, I would request you to try using copy activity and load the data to JSON file and then use dataflow on top of that. Kindly let us know how it goes. Thanks.
it does work in postman and the linked service connection works. So that piece is resolved. However, the columns do not appear as shown in your example. Unfortunatley, the api is not public, it is from a source called Mavenlink, which my company uses to track our billable hours for employees. Where would you reccomend storing the JSON file after it is copied from the API? Azure Blob? And then building the data flow from there?
Not sure if you could create an account just to see how it works or not but ill send the link anyway. https://developer.mavenlink.com/beta/#
@AnnuKumari-MSFT I copied the API data to a blob storage JSON file and tried to pull the data into the dataflow source, selected array of documents and my data still looks like this: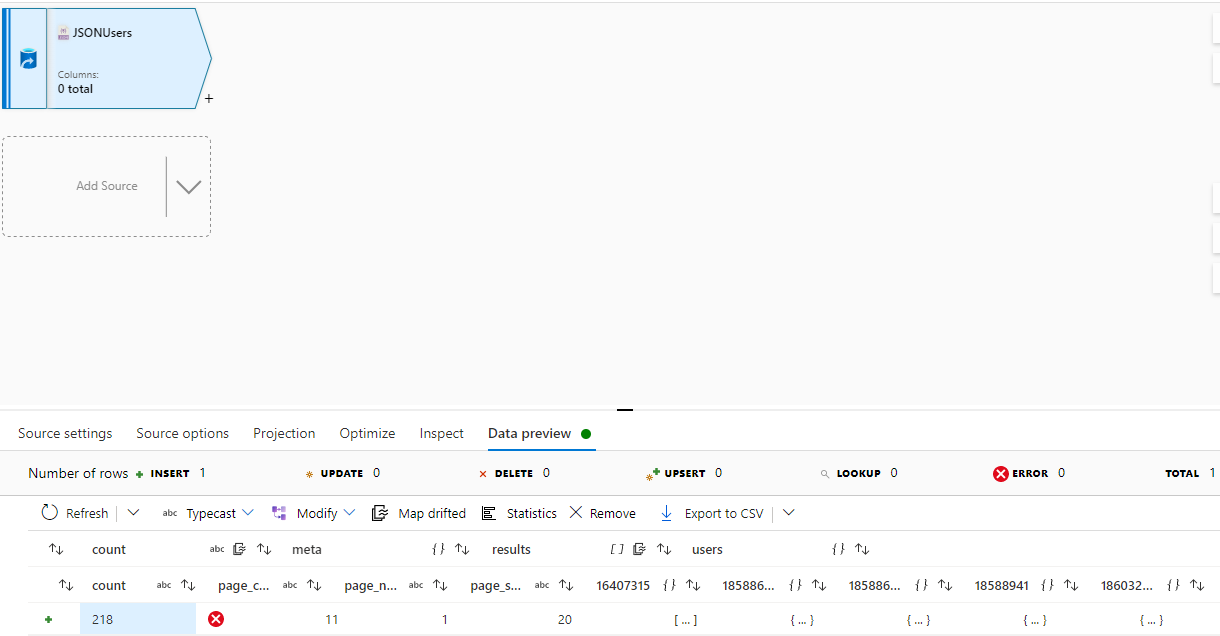
Hi @James Klein ,
Could you please share the JSON here.
@AnnuKumari-MSFT the JSON is identical to the one in the original POST. but here is the link to the stack overflow post where you will find a code sample. This forum does not allow me to post a large code block. https://stackoverflow.com/questions/74145240/nested-json-transformation-to-insert-into-sql-table-azure-data-factory/74150014#74150014**strong text**
Hi @James Klein ,
I checked the JSON you have shared in stackoverflow. There are two validation errors present. One double quote is missing (shown in below image) and at the end closing paranthesis is missing.
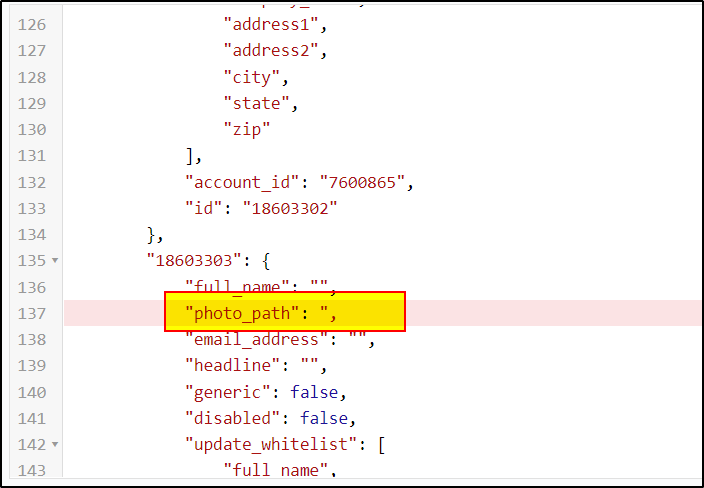
After correcting these two errors, I am able to preview the data.
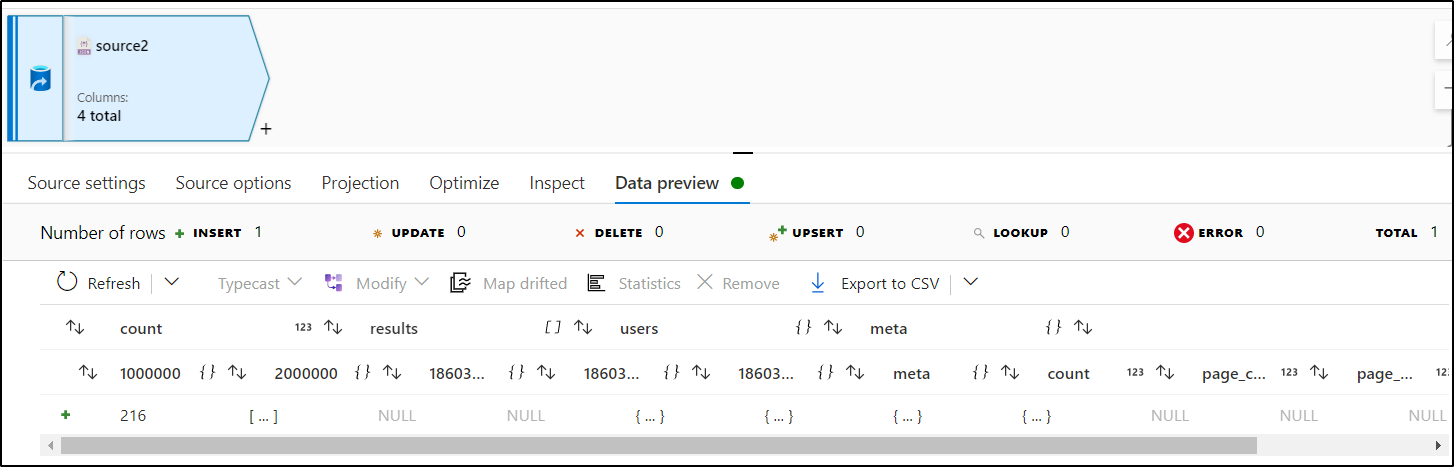
@AnnuKumari-MSFT this is due to me manually removing the information to hide sensitive information. I can assure you this error is not present when i copy directly from the API to the file in BLOB storage.
@AnnuKumari-MSFT I figured out what was wrong. I was using inline instead of a json dataset! it recgonizes the columns now. However, it appears this mapping will have to be done manually for each id which is not a sustainable solution, as there are hundreds of ids.
Hi @James Klein ,
Glad to know you rectified the issue. I used aggregate function to convert the JSON into array so that we can choose the same array to unroll by in flatten transformation since it expects array datatype only to unroll. Therefore, I selected 'users[]' array to unroll by and fetched Id column from results property and all columns from users property. Now here , the challenge is the key inside users[] array is different for every JSON i.e. 1000000 , 2000000 . We can't make it dynamic. So , you need to select each and every property of 1000000 as well as each and every property of 2000000. That's what I did using flatten.
@AnnuKumari-MSFT since the ID is also present with each object, is there any way we could we strip away the ID object so we are just left with the data within users?
so it would look something like this
"users": {
{
"full_name": "",
"photo_path": "",
"email_address": "",
"headline": "",
"generic": false,
"disabled": false,
"update_whitelist": [
"full_name",
"headline",
"email_address",
"external_reference",
"linkedin_url",
"bio",
"website",
"company_name",
"address1",
"address2",
"city",
"state",
"zip"
],
"account_id": "",
"id": "18603444" }
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESH%3C/text%3E%3C/svg%3E)
All the existing queries are about how we can deal a single list inside a json. How to deal multiple lists within a json.
Here is my payload.
Opening this payload inside flatten gives me the first list data only. The second list name and its column are not available in flatten.
This is my Payload
{
"result": "success",
"err": None,
"data": [
{
"outcome_percent_vs_average_score": [
{
"name":"sadaqat",
"id":12
},
{
"name":"sadaqat1",
"id":123
}
]
},
{
"average_criteria_score": [
{
"avg_id":123,
"avg_name":"hello"
},
{
"avg_id":1234,
"avg_name":"hello 1"
}
]
}
]
}
You can see the first list is being shown in the flatten activity not the others are there.
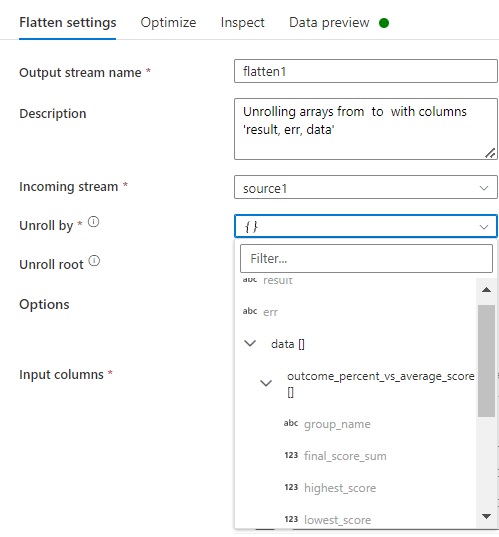
Thank you for this feedback, it was helpful even though I was never able to get ADF to unroll all the way...same issue as James Klein where I would have had to map every id. I ended up creating Notebook (Python) scripts to flatten each json object, write to parquet files, then load to Synapse...used outer pipeline to copy Metadata (for bulk copy) with a For Each that executed an inner pipeline that did the Rest API call and copied the json files to blob storage where they were flattened & loaded to Synapse.