Azure Databricks
An Apache Spark-based analytics platform optimized for Azure.
1,916 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EA%3C/text%3E%3C/svg%3E)
As mentioned in the title there are newlines ({CRLF}) embedded in text fields of csv files such as
,,,,,"this is text field {CRLF} which finishes here",,,,,
Normally you will use a function like: regexReplace(<Column name>, ,"([\r\n|\r|\n]+)",, ' ') https://learn.microsoft.com/en-us/azure/data-factory/data-flow-expression-functions to replace {CRLF} with a space. The issue is the <Column name> is dynamic. Here is the simplified extract of a csv file:

As one can see the text field denoted by a pair of double quotes has span multiple lines as the result of the embedded {CRLF} within the text field. The dynamic <Column name> means you don't know which column in a csv file is a text field. Also there would be multiple csv files through a single pipeline. The schema in each csv file is different. Please chip in your thoughts.

@AMJ : Can you let me know how the CSV is generated, is the CSV is generated from a database as source via query or any other form?
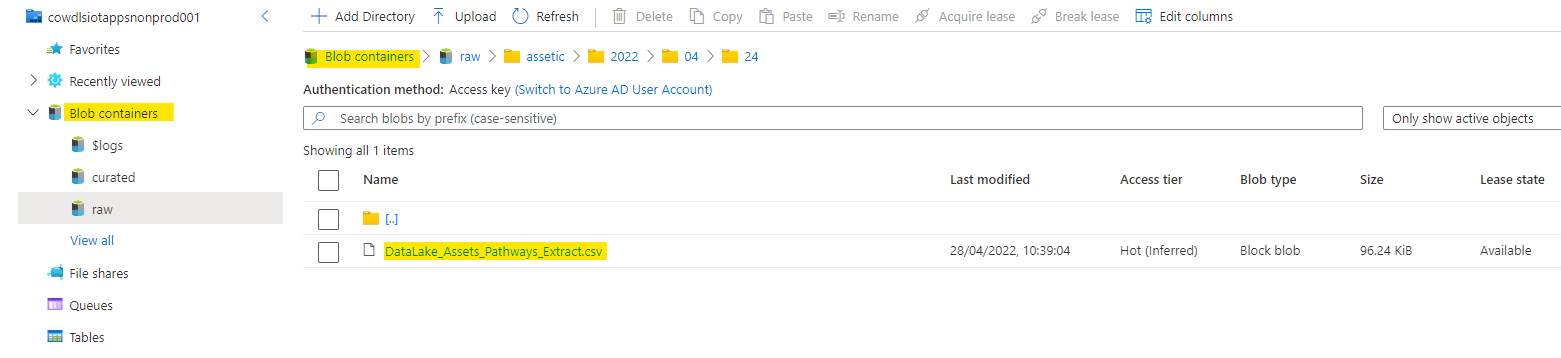
@Pratik Somaiya The csv was generated via a API call and stored to a data lake as below:

Hi @AMJ ,
Thank you for posting query in Microsoft Q&A Platform.
If possible try to see if you can apply your replace logic on response itself and then storing it as csv file. That way it will reduce lot of efforts.
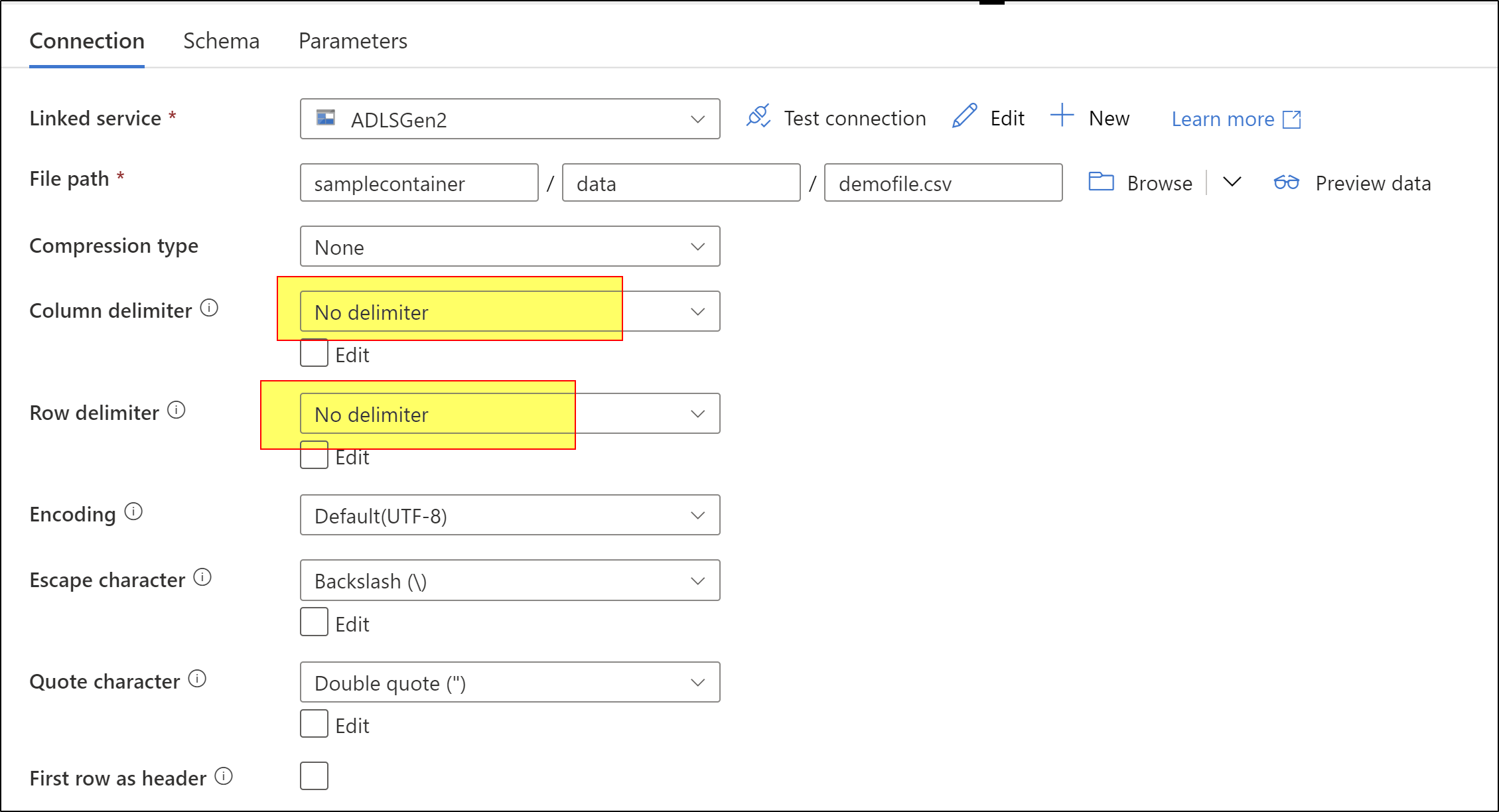
If you would like to play around the logic on csv file after loading data from API then we should consider using data flows. Firstly, try to read entire file data as single column. For the you should have your dataset settings as below.
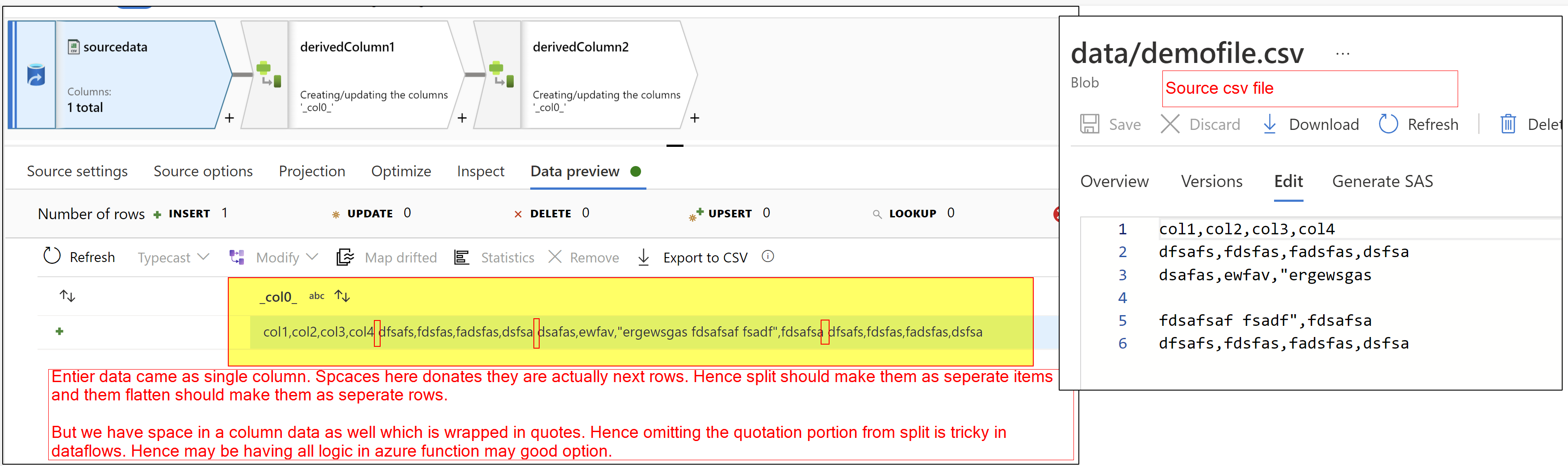
Once you get entire file data as single column then apply your replace logic using derived column. and then consider breaking your single column single data as multiple items using split() function on space. But if your any column has space in there data then that will also get splitted. Hence we should consider omit splitting of data which is wrapped insider quotes.
Once we splitted data as array then flatten that data as multiple rows and load as file. and then use this newly created file as source for further processes.
All above mentioned logic handling may be difficult and sometimes dataflows not much flexible to have this logic. So best way is having your custom code written in Azure functions to read your file data and do the replace() accordingly.
Hope this helps. Please let us know how it goes. Thank you.
--------
Please consider hitting Accept Answer. Accepted answers help community as well.
Can you apply the Replace function in your API query body itself? Are you using a Web Activity for API call or any via other way?
@Pratik Somaiya Please see below:
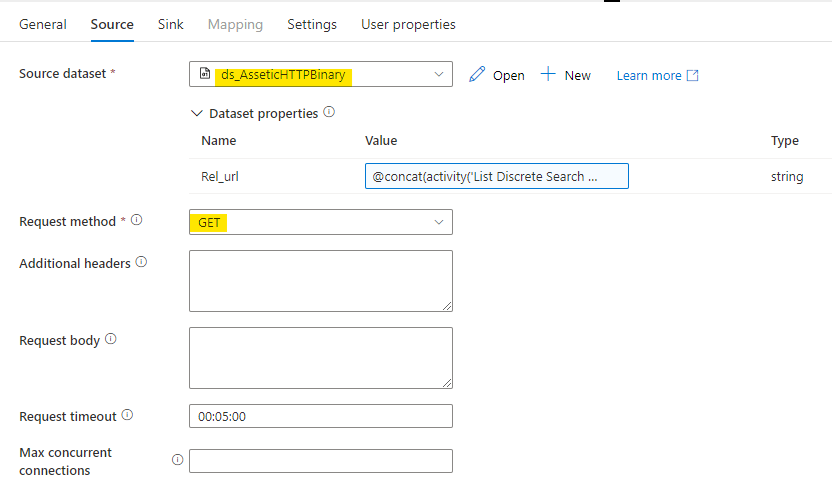
This was a HTTP call with binary format. The request body was empty. Could you supply a sample code regarding to using the function regexReplace() in this body? Bear in mind this would be a binary stream at the point of time before a csv file is formed.
@ShaikMaheer-MSFT Thank you so much for your thoughts. Unfortunately it won't work. I modified your sample data to closely imitate the real situation as below:

As you could see there are 2 issues applying your method to a read data: