Active Directory
A set of directory-based technologies included in Windows Server.
5,822 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.

I'm trying to confirm if Microsoft LDAP API supports multi-byte UTF-8 variable-length encoding for DNs.
RFC2251 - Section 4.1.3 Distinguished Name and Relative Distinguished Name, states that DNs use LDAPString format
RFC2251 - Section 4.1.2 String Type, states that an LDAPString is a Octet String using UTF-8 encoded based on RFC2044 which supports variable-length encoding
RFC2253 - Section 5 Examples provides examples of UTF-8 encoding for unicode characters
Unicode Letter Description 10646 code UTF-8 Quoted
=============================== ========== ====== =======
LATIN CAPITAL LETTER L U0000004C 0x4C L
LATIN SMALL LETTER U U00000075 0x75 u
LATIN SMALL LETTER C WITH CARON U0000010D 0xC48D \C4\8D
LATIN SMALL LETTER I U00000069 0x69 i
LATIN SMALL LETTER C WITH ACUTE U00000107 0xC487 \C4\87
The Microsoft LDAP Protocol Distinguished Names reference page does state that UTF-8 encoding is used, and notation that should be used:
If an attribute value contains other reserved characters, such as the equals sign (=) or non-printable characters, it must be encoded in hexadecimal by replacing the character with a backslash followed by two hex digits.
And this works if for non-printable and printable characters, all of the following examples work with the ldap_search_s API as the base parameter as the distinguished name
CN=Gary Reynolds,OU=Domain Users,DC=w2k12,DC=local
CN=G\41ry Reynolds,OU=Domain Users,DC=w2k12,DC=local
CN=G\41\52y Reynolds,OU=Domain Users,DC=w2k12,DC=local
CN=Before\0DAfter,OU=Domain Users,DC=w2k12,DC=local
However, if you try to use multi-byte UTF-8 encoding of the DN , the object is not found. The object has the following unicode DN
CN=Gačy Reynolds,OU=test1,DC=w2k12,DC=local
Encoded as UTF-8 this is:
CN=Ga\C4\8Dy Reynolds,OU=test1,DC=w2k12,DC=local
This fails, if you encode the normal char 'a' as hex \41 this works as in the example above, if you encode the same char 'a' Hex 41 using two byte encoding of \C1\81, this also fails.
Does anyone know if multi-byte UTF-8 encoding is supported for DN and if there is an alternative format that must be used for ANSI LDAP APIs?
Gary.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMY%3C/text%3E%3C/svg%3E)
Hi,
Since the question is more related to UTF-8 encoding and LDAP, I removed the C++ tag.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EDL%3C/text%3E%3C/svg%3E)
Gary,
Just to clarify on the "Gač" portion, if you use "Ga\C4\8D", it fails, but if you use "G\41\C4\8D" it succeeds?
Hi David,
Both Ga\C4\8D and G\41\C4\8D will fail as the č is encoded as a multi-byte, however, Gary encoded as G\41ry will work, as it uses a single byte encoding.
Also encoding the A (0x41) using a multi-byte encoding \C1 \81, which technically is the wrong encoding for a <255 number but should still decode 0x41, also fails.
Gary.

Hello Gary,
An interesting problem!
I guess that you looked at a trace of the LDAP traffic. I traced a search from base "cn=G\41\C4\8Dy,cn=Users,dc=home,dc=org" with filter "(!(|(cn=Ga\C4\8Dx)(cn=Gačz)))" and noticed that the filter strings are "unescaped" on the client but that the DN string is sent without alteration to the server.
On the server, the DN seems to be put through a "normalization" process which "unquotes" and then "requotes" the DN. This explains why \41 works - it is unquoted as "a" and does not need to be quoted when "quoting" the DN.
The only way that I could find (so far) to reference Gačy was to use a BER encoding of a octet string containing the UTF-8 representation of the name: "cn=#04054761c48d79,cn=Users,dc=home,dc=org"; the leading 04 is the tag for "octet string" and the following 05 is the length in bytes of the string.
Gary
Hi Gary,
This is the network trace of the filter (&(objectclass=*)(name=ga\c4\8dy)), this is the same for both ANSI and Unicode version:
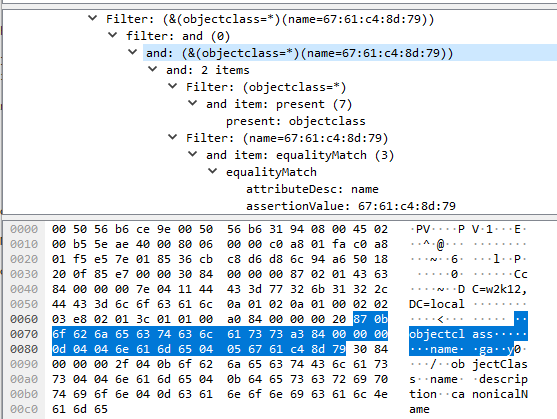
If I use LDP which uses unicode\wide versions of the LDAP API with the unicode DN it is able to return the CN=Gačy Reynolds,OU=test1,DC=w2k12,DC=local entry. Looking at the network traces you can see that the unicode char has been encoded as a multi-byte UTF-8 value.
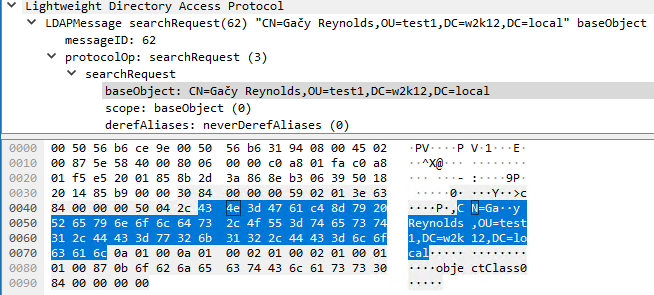
I did a quick hack of the code calling the ANSI API to update the DN string to directly encode the string:
String Temp;
char *ptr;
if (memActivePane != NULL && memActivePane->SelText!= ""){
Temp = "CN=Ga??y Reynolds,OU=test1,DC=w2k12,DC=local";
ptr = Temp.c_str();
*(ptr+5) = 0xc4;
*(ptr+6) = 0x8d;
TfrmObjectProperties *Prop = new TfrmObjectProperties(Application);
Prop->DisplayDetails( txtLDPServer->Text, Temp, "","","");
}
and this produces this network trace, which is identical to the LDP call, however, this still fails.
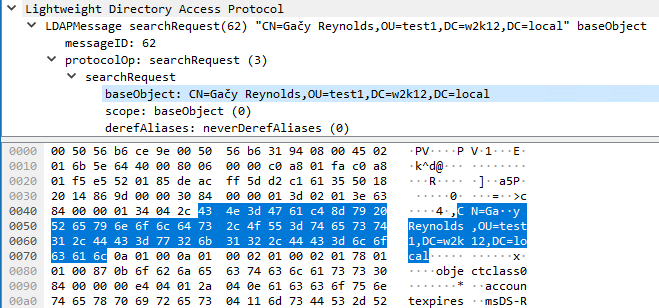
This is the side by side comparison, with the hacked ANSI call on the left and LDP call on the right
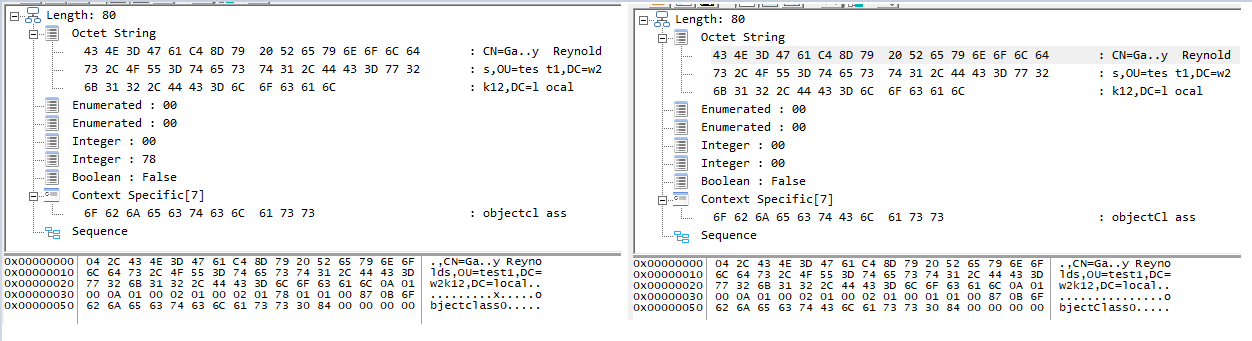
As you said if the DN is escaped then the escaped string is passed directly to the server, I haven't tested if the Unicode version does the same:
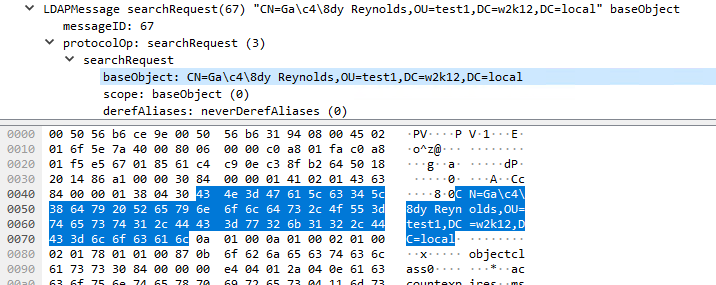
What tracing are you using on the server side to capture the quoting and unquoting of the traffic?
Gary.
Hello Gary,
I am mostly using a debugger connected to the DSA process to see what is happening on the server side. This is what seems to happen:
This shows the "normalisation" process. First each component is unquoted and then each component is quoted. The value display is the "input" string to the routine.
Child-SP RetAddr Call Site
00000088`6aefe468 00007ff9`e8b30034 ntdsai!UnquoteRDNValue
0000022b`0c0a873e 6f 00 72 00 67 00 o.r.g.
Child-SP RetAddr Call Site
00000088`6aefe468 00007ff9`e8b30034 ntdsai!UnquoteRDNValue
0000022b`0c0a872e 68 00 6f 00 6d 00 65 00 h.o.m.e.
Child-SP RetAddr Call Site
00000088`6aefe468 00007ff9`e8b30034 ntdsai!UnquoteRDNValue
0000022b`0c0a871c 55 00 73 00 65 00 72 00-73 00 U.s.e.r.s.
Child-SP RetAddr Call Site
00000088`6aefe468 00007ff9`e8b30034 ntdsai!UnquoteRDNValue
0000022b`0c0a86fe 47 00 5c 00 34 00 31 00-5c 00 43 00 34 00 5c 00 G.\.4.1.\.C.4.\.
0000022b`0c0a870e 38 00 44 00 79 00 8.D.y.
Child-SP RetAddr Call Site
00000088`6aefe498 00007ff9`e8d48339 ntdsai!QuoteRDNValue
0000022b`0c0a8f20 47 00 41 00 c4 00 8d 00-79 00 G.A.....y.
Child-SP RetAddr Call Site
00000088`6aefe498 00007ff9`e8d48339 ntdsai!QuoteRDNValue
0000022b`0c0a8d10 55 00 73 00 65 00 72 00-73 00 U.s.e.r.s.
Child-SP RetAddr Call Site
00000088`6aefe498 00007ff9`e8d48339 ntdsai!QuoteRDNValue
0000022b`0c0a8b00 68 00 6f 00 6d 00 65 00 h.o.m.e.
Child-SP RetAddr Call Site
00000088`6aefe498 00007ff9`e8d48339 ntdsai!QuoteRDNValue
0000022b`0c0a88f0 6f 00 72 00 67 00 o.r.g.
The input string to the QuoteRDNValue in the extract above is the output of the UnquoteRDNValue - this shows how \C4\8D ends up as the four bytes 00 C4 00 8D.
Avoiding escaping printable Unicode characters in the DN by using a suitable API on the client side or handling the BER encoding explicitly (via a # escape) are both viable solutions.
I could not follow your hack - it looks as though you were just changing characters in the tool that uses the LDAP API and not in the LDAP API itself (e.g. a routine like ldap_search).
Gary
Hi Gary,
Thanks for the info. I found that the API in the debug dump are DsQuoteRdnValue and DsUnquoteRdnValue.
I've done some additional testing with these functions and confirmed that the unquoting function only relates to the following actions:
From the action list above and the testing I've completed the DsUnquoteRdnValue doesn't support any form of UTF-8 multi-byte escape encoding as covered in RFC2253, i.e. SN=Lu\C4\8Di\C4\87. The only alternative option, as you shared, is to use #hexstring option to encode the RDN and any unicode characters as a BER encoded block.
What I don't understand is why my code hack didn't work, as you guest, this was just a update of the DN string passed to the ldap_search_s with the UTF-8 code added directly to the string. While the data on the network wire was identical it's still failed. I'm still looking at this and it appears to be related to code pages and character mappings, but not sure where the codepage is specified in the LDAP connection conversation.
Gary.
Hello Gary,
DsQuoteRdnValue and DsUnquoteRdnValue seem to describe the functionality well. The routines used by NTDSAI.dll (QuoteRdnValue and UnquoteRdnValue) differ a little bit (they don't have the third parameter ([in, out] DWORD *pcRdnValueLength).
I think that the codepage used in a search can be specified by providing an LDAP_SERVER_SORT_OID extended control.
I looked very carefully at the trace extracts in your previous message and could not understand why it might behave differently. I am very happy to help in understanding this; are you directly using the wldap32.dll search APIs? If so, which one?
Gary