Azure SQL Database
An Azure relational database service.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESP%3C/text%3E%3C/svg%3E)
I have about fifteen million json type records saved in individual files in a single folder, I would like to know the best configuration that I can make in the copy data that I am using to optimize said migration, according to what I have read, the configurations can vary depending on the number of files to process and migrate, so I don't know what would be the best configuration with fifteen million records.
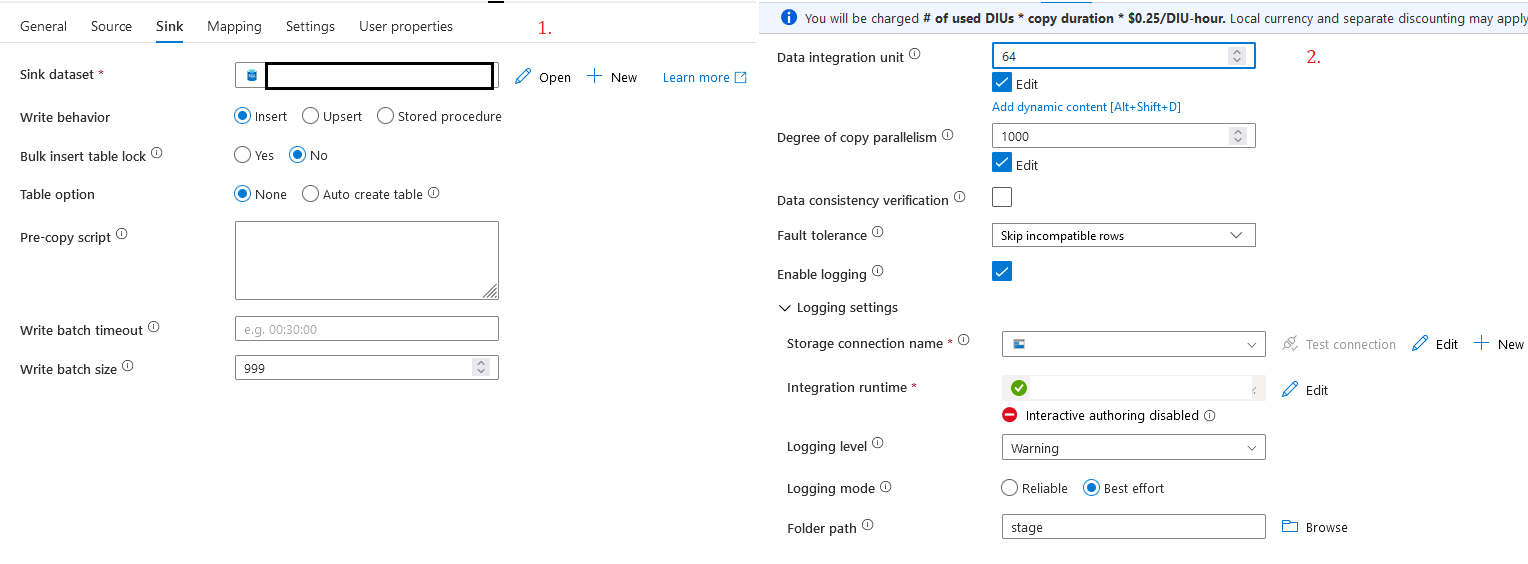
This is the configuration I have for the copy data, if I can change something to optimize the process, I would appreciate if you have any advice or suggestions regarding what to modify,Processing is from data lake to sql and from datalake to cosmos db.
Thank you very much.

Thankyou for using Microsoft Q&A platform and thanks for posting your question.
As I understand your ask, you want to optimize the process of data migration from ADLS to SQL server for which you are using Copy activity in Azure data factory pipeline. Please let me know if my understanding is incorrect.
The allowed DIUs or Data Integration Units to empower a copy activity run is between 2 and 256. However, ADF dynamically applies the optimal DIU setting based on your source-sink pair and data pattern.
You can consider increasing DIU to 256 . However, during the runtime , DIUs will be decided based on the data stores during the runtime. It depends on various factors like the copy is happening for single file or muliple files or is it between file store to non file store. So, depending on all these factors, DIUs will be assigned.
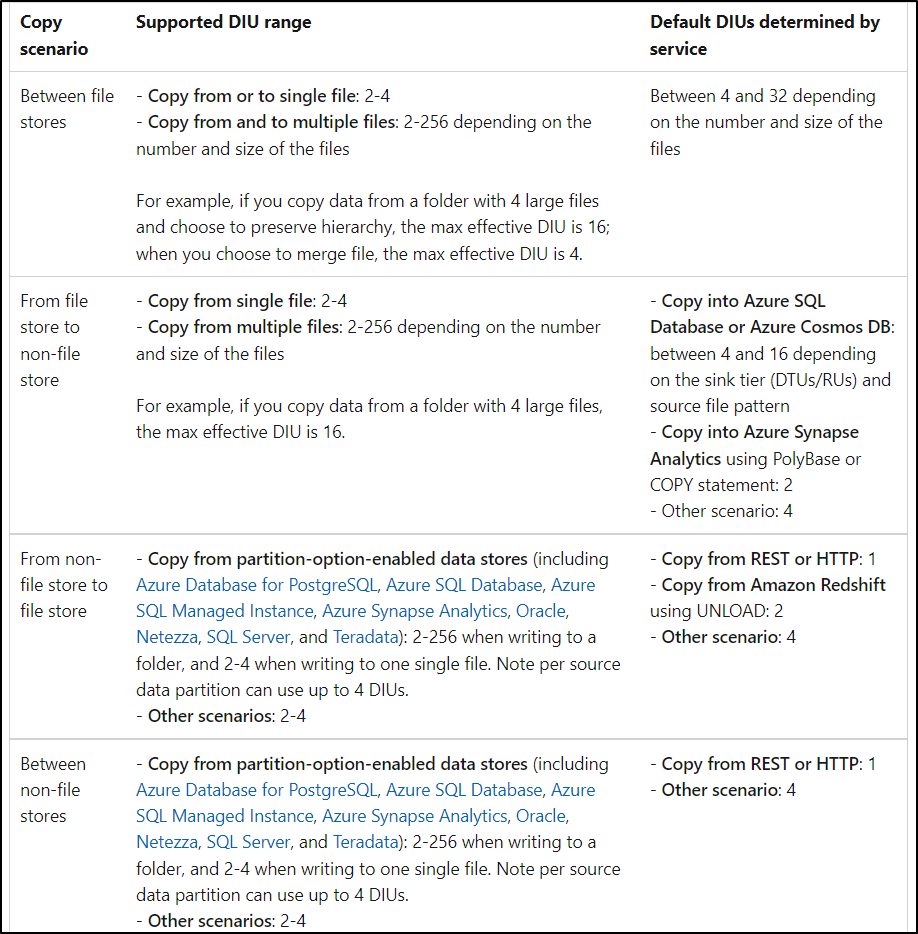
For more details, check Data Integration Units
Now coming to Degree of parallelism, when you specify a value for the parallelCopies property, take the load increase on your source and sink data stores into account. Also consider the load increase to the integration runtime if the copy activity is empowered by it.
This load increase happens especially when you have multiple activities or concurrent runs of the same activities that run against the same data store.
If you notice that either the data store or the self-hosted integration runtime is overwhelmed with the load, decrease the parallelCopies value to relieve the load.
For more information , please check : Performance tuning steps
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.