Machine Learning para principiantes – Capítulo 4: entrenando y evaluando el modelo
Ahora que los datos están limpios y prepararados para el entrenamiento, es hora de crear un modelo entrenado que nos ayude a predecir los valores futuros del Player Efficiency Rating para cada jugador de la NBA. El primer punto a entender con respecto al entrenamiento es cómo funciona, que es básicamente comparando valores predichos con valores conocidos, para que podamos evaluar la precisión del modelo y seguir puliéndolo hasta obtener los mejores resultados posibles.
Para que podamos comparar estos valores predichos con los conocidos, tendremos que dividir nuestro conjunto de datos en dos:
- Training dataset: valores utilizados para formar el modelo que generará la predicción
- Testing dataset: a utilizar contra este modelo entrenado, y que tendrá el valor conocido (el valor real en el conjunto de datos) y el valor predicho por el modelo, por lo que se pueden comparar ambos
En este caso, al predecir un valor numérico, nos enfrentamos a un problema de regresión. En estos problemas, el resultado deseado es una representación gráfica con una línea diagonal de la predicción resultante cuando se traza con los valores conocidos, ya que indicará que los valores predichos son precisos o cercanos a los reales. Esta representación gráfica pondrá el valor conocido en un eje y el valor predicho en el otro eje, y pinta los puntos basados en esos pares de valores. Es por eso que cuanto más cercano a una diagonal exacta mejor, ya que más valores predichos coinciden o son cercanos a los valores reales. Pero no te preocupes, en un momento estaremos con ello.
Otros tipos de problemas a tratar con técnicas de Machine Learning podrían ser clasificaciones (aplicar 2 o más etiquetas o categorías a una determinada información de entrada), clustering y detección de anomalías. Afortunadamente para nosotros, no expertos en data science, hay una "chuleta" disponible para ayudarnos a decidir cuál es el mejor algoritmo para usar en nuestros experimentos (https://aka.ms/MLCheatSheet), y también te ayudará a obtener algo más de profundidad en los conceptos que hay tras este tipo de problemas y algoritmos.
Aquí, como nos enfrentamos a un problema de regresión típico, usaremos dos de los algoritmos de regresión más comunes: regresión lineal y regresión de redes neuronales, y los evaluaremos para decidir cuál rinde mejor y usar este modelo entrenado para predicciones futuras.
Pero lo primero es lo primero: vamos a dividir nuestro conjunto de datos para obtener tanto el training dataset como el testing dataset. Busca el modulo "Split Data" en "Data Transformation > Sample and Split" y arrástralo a tu canvas, conectando su entrada con la salida del modulo de "Clip Values" . Vamos a dejar "Split Rows" como el modo de división, y sólo seleccionaremos el porcentaje de filas para el primer conjunto de datos, en un valor entre 0 y 1. La mayoría de las veces, el 80% de las filas en el conjunto de datos están destinados a entrenamiento (training) y el otro 20% se deja para la puntuación/evaluación (testing), así que utilicemos estos valores por ahora. Como resultado, tendremos dos conjuntos de datos: uno con alrededor de 12k filas para training (punto de salida izquierdo) y otro con casi 3k filas para testing (punto de salida derecho), y puedes echar un vistazo a ambos, como siempre.
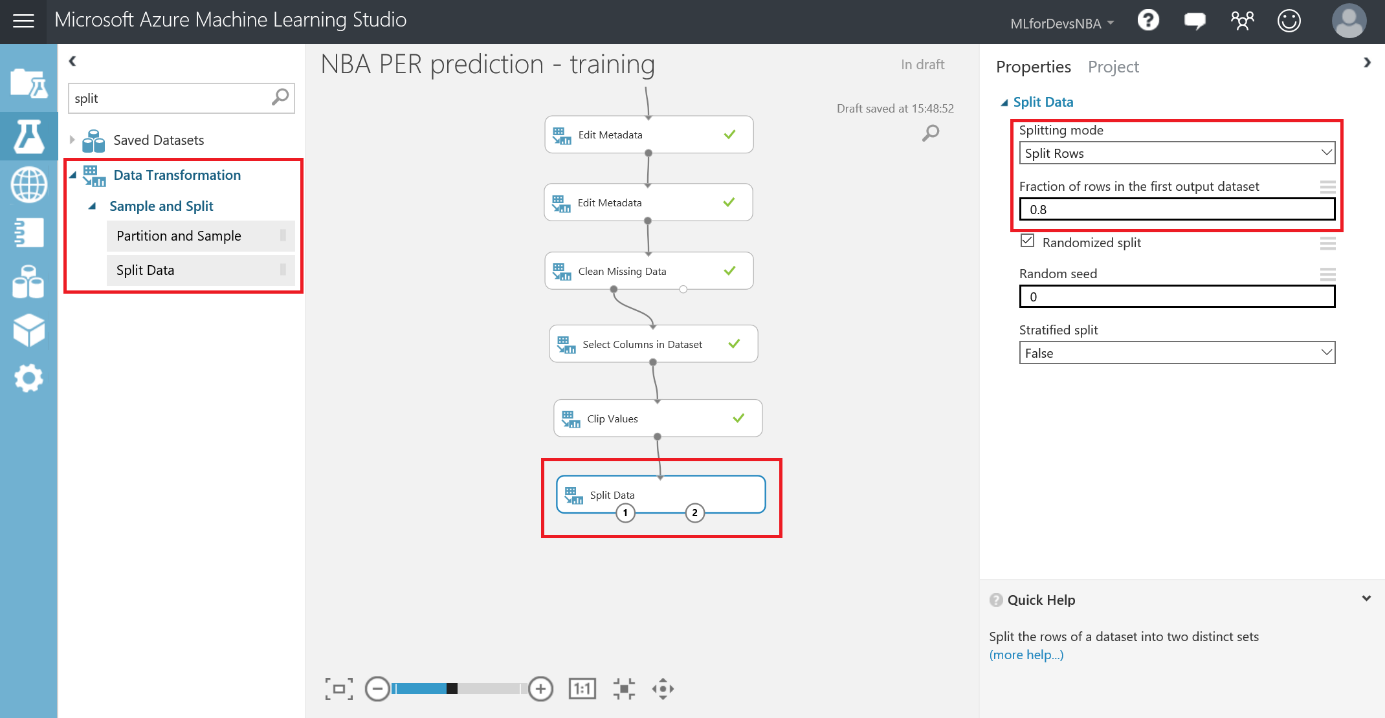
Una vez que tenemos ambos datasets listos, es hora de entrenar el modelo...o modelos en este caso, ya que vamos a utilizar dos algoritmos diferentes al mismo tiempo para compararlos. Para conseguir esto, necesitaremos dos módulos de "Train Model" (en la categoría "Machine Learning > Train" ), el módulo de algoritmo de la "Linear Regression" y el módulo de algoritmo de la "Neural Network Regression" (ambos bajo la categoría de "Machine Learning > Initialize Model > Regression" ).
Una vez añadidos al experimento, necesitaremos conectar cada algoritmo con el punto de entrada izquierdo de un modulo "Train Model" y el dataset de training (el punto de salida izquierdo del modulo "Split Data" ) con el punto de entrada derecho de ambos módulos "Train Model" , quedando así nuestros experimento:
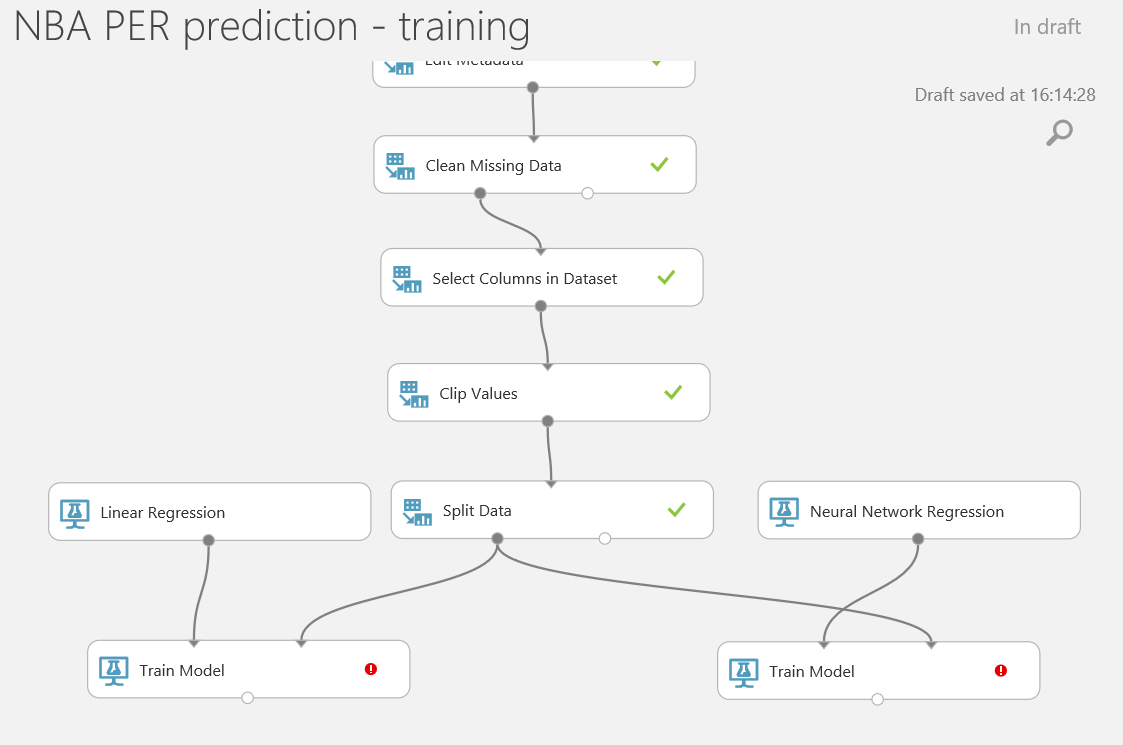
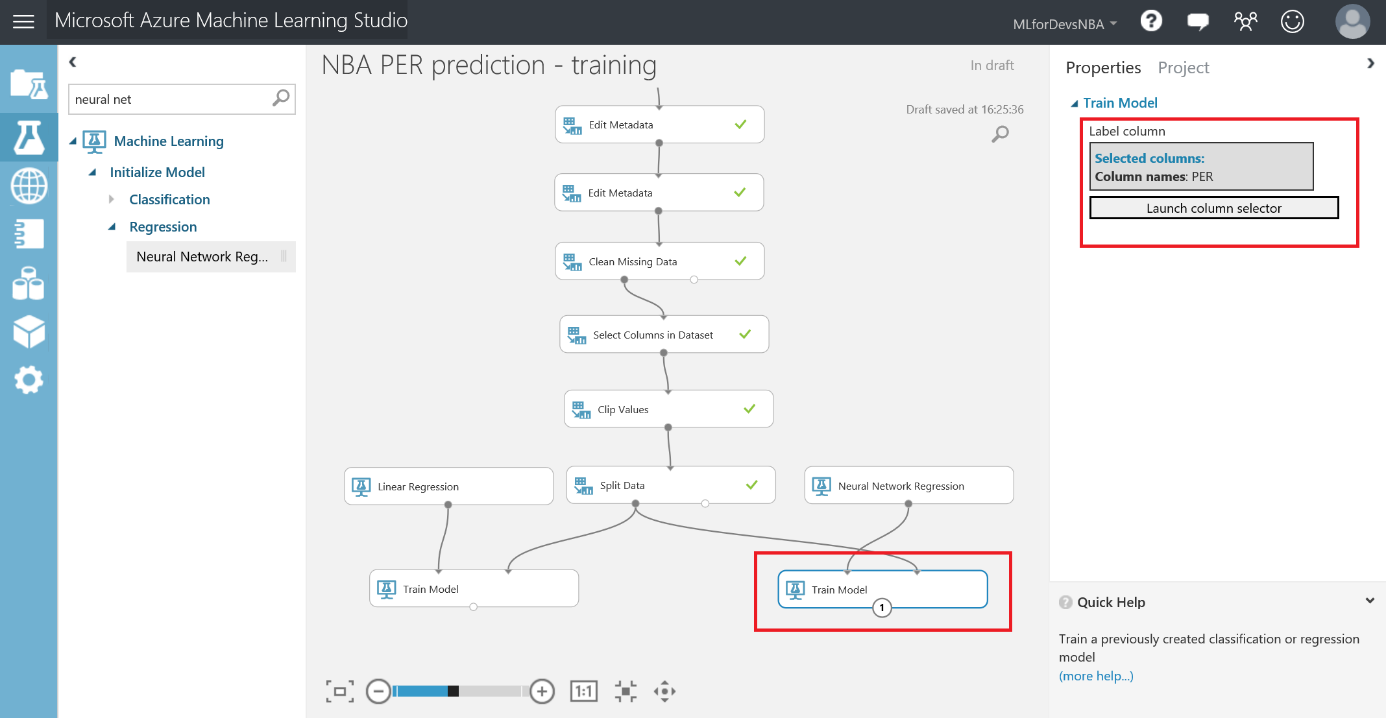
Para configurar ambos módulos de "Train Model", solo necesitas seleccionarlos y elegir la columna de la que generar la predicción (en este caso, PER) usando el column selector:
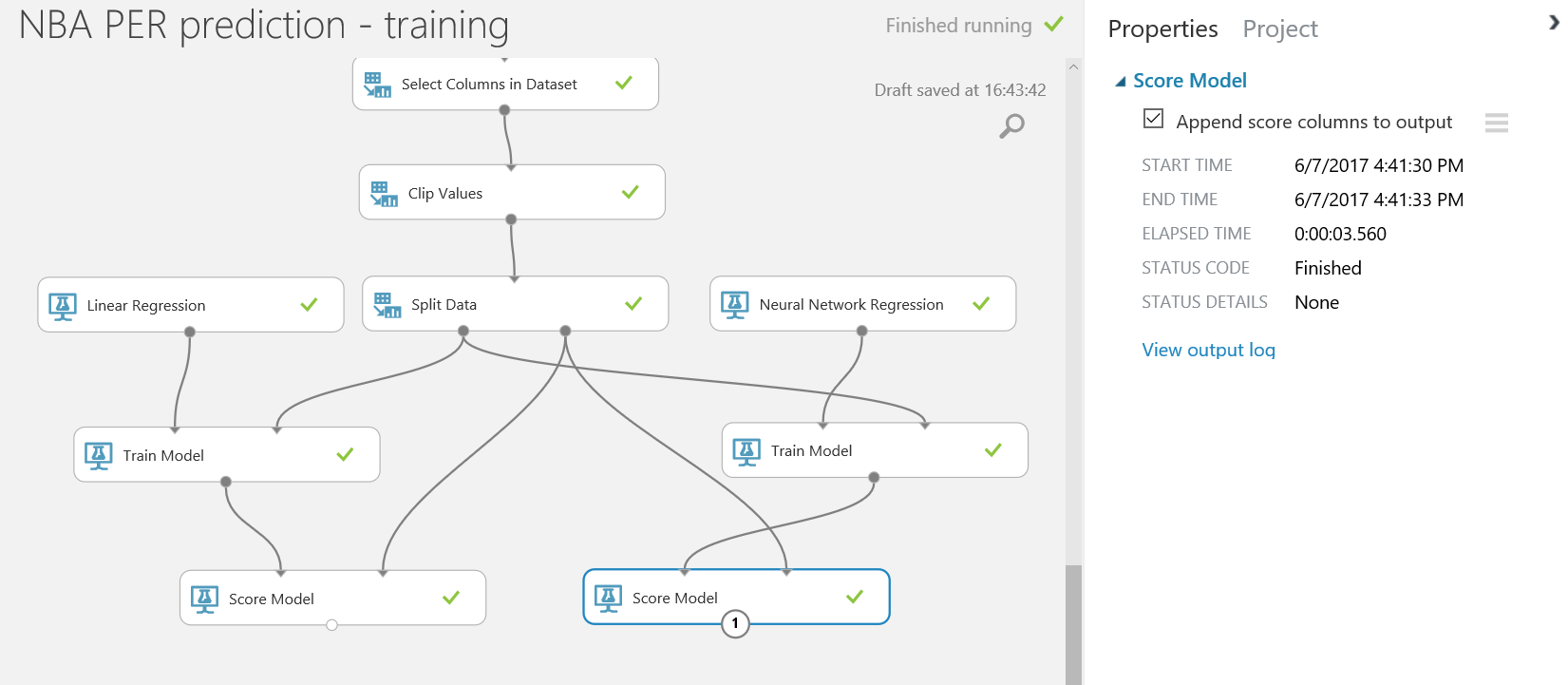
Tras ejecutar el experimento, con ambos modelos entrenados, vamos a evaluarlos puntuándolos con el testing dataset, el otro 20% de nuestros datos limpios. Busca el modulo "Score Model" en el menú de la izquierda (bajo la categoría de "Machine Learning > Score Model" ), y arrastra dos de ellos a tu canvas. En este caso, debemos conectar la salida de cada modulo "Train Model" a la entrada izquierda de cada módulo "Score Model" , y la segunda salida del módulo "Split Data" al punto de entrada derecho de ambos módulos de "Score Model" , quedando algo parecido a esto:
Ejecuta de nuevo el experimento y, una vez completado, podrás visualizar los resultados de las predicciones utilizando ambos algoritmos. Lo primero que puedes hacer para evaluar los resultados de su modelo es visualizar el conjunto de datos obtenido resultante y comparar el valor conocido (PER) con el valor predicho (etiquetas marcadas). Haz click con el botón derecho en el punto de salida de cualquier modulo "Score Model" y, con la ventana de visualización abierta, selecciona la columna "Scored Labels" (el valor predicho). En el panel derecho, selecciona la columna "PER" en la lista desplegable de "comparar con" y obtendrás el gráfico con el valor conocido y la predicción:
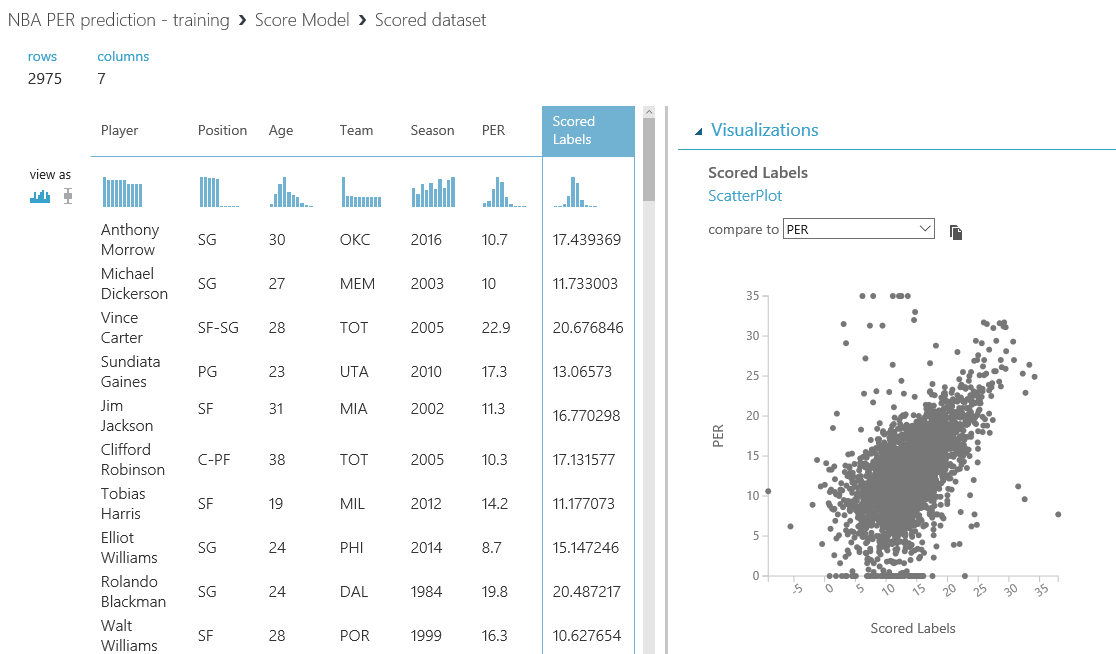
Como puedes ver, el resultado no se parece demasiado a diagonal en el gráfico mostrado, por lo que nuestro modelo no está funcionando muy bien. Por ejemplo, hay un montón de valores atípicos, el área cubierta es demasiado grande (mostrando que los resultados son muy dispersos y diferentes de la realidad)... Por lo tanto, todavía nos queda trabajo por hacer para mejorar nuestro modelo.
Pero, para no evaluar el modelo simplemente con la imagen de un gráfico, tenemos un módulo de "Evaluate model" en el menú de la izquierda, bajo la categoría "Machine Learning > Evaluate" , que nos dará más información sobre el rendimiento de nuestro modelo, con datos como el error absoluto medio y el coeficiente de determinación, entre otros. Simplemente conecta ambos módulos de "Score Model" con las entradas del modulo "Evaluate Model" , dejando nuestro experimento como sigue:
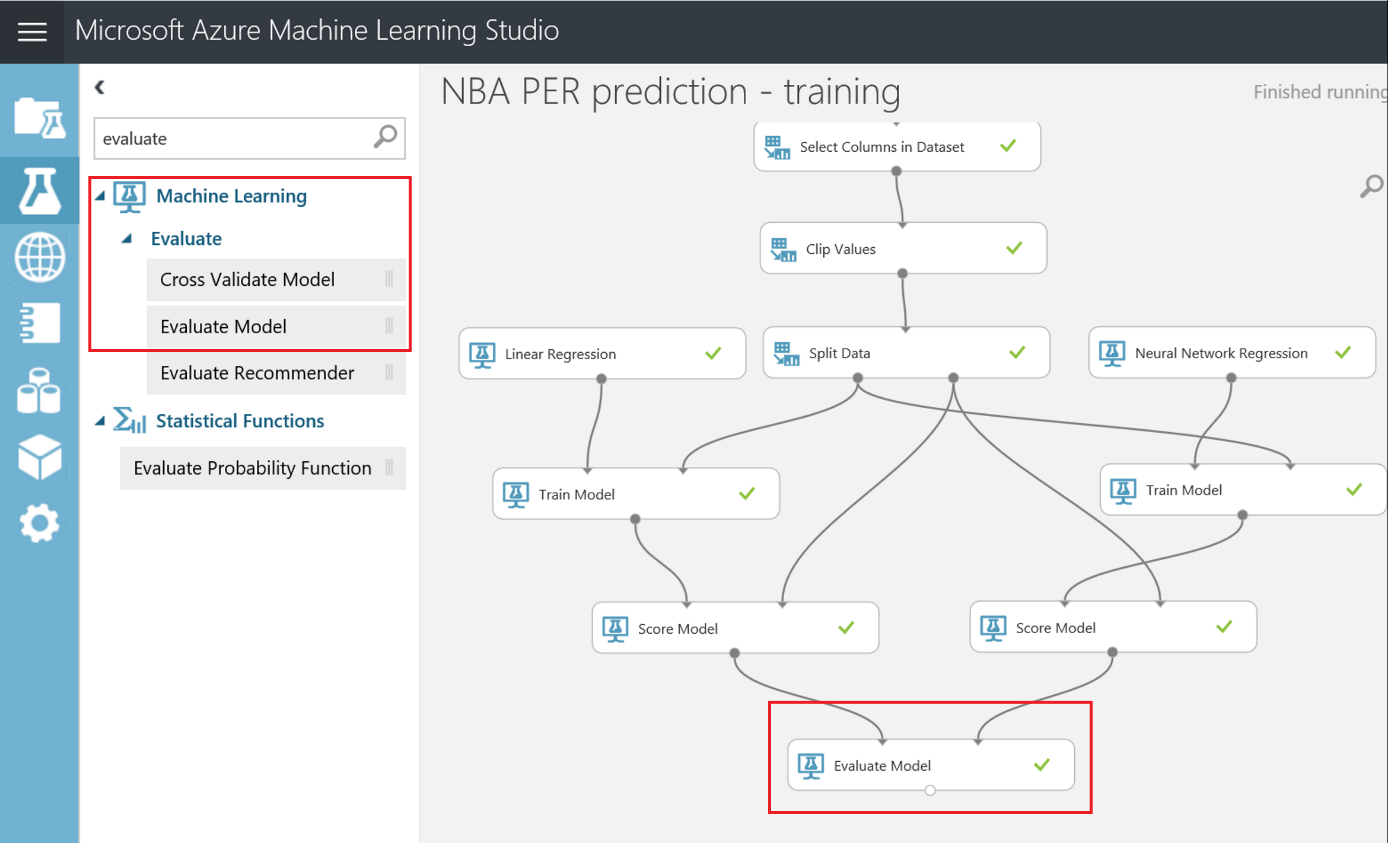
Vamos a comprobar estos valores haciendo click con el botón derecho en el punto de salida del módulo "Evaluate Model" y luego en "Visualizar" . Este último, el Coeficiente de Determinación, medirá el porcentaje de precisión que tiene nuestro modelo; así que, cuanto más alto, mejor!
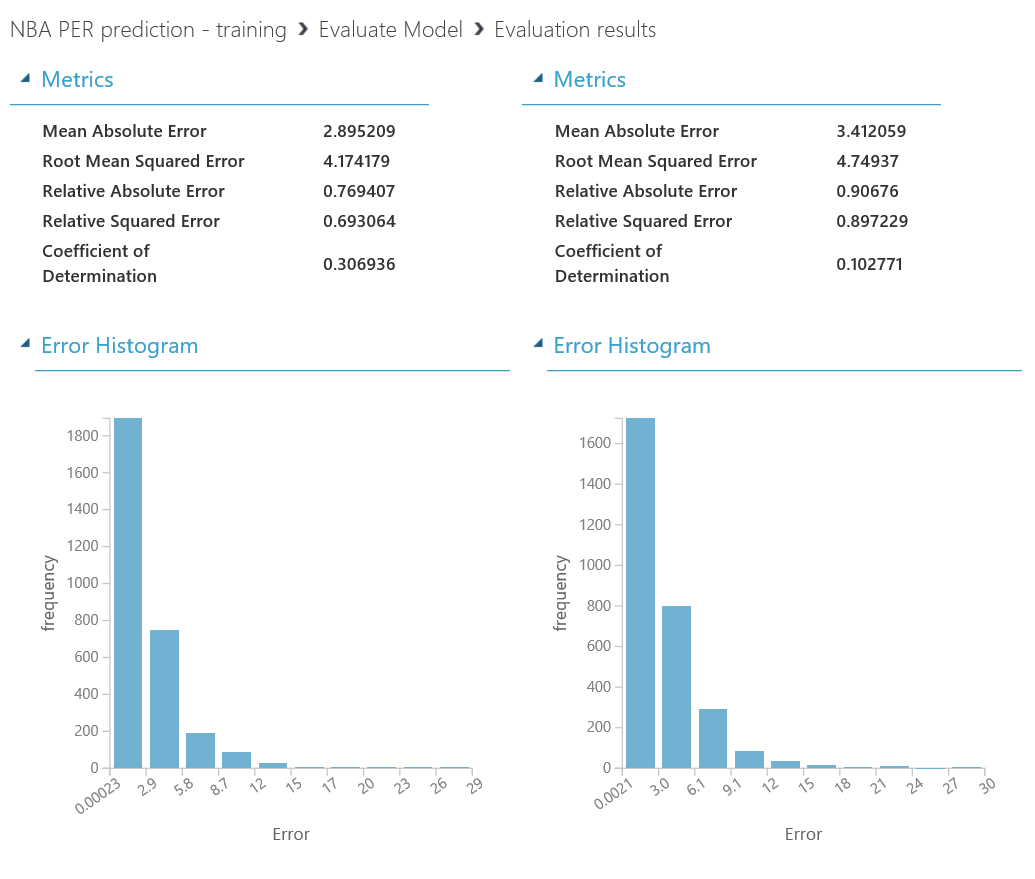
Como puedes ver, ambos algoritmos están rindiendo bastante mal, con solo un 30% y un 10% de precisión respectivamente, así que en el próximo capítulo veremos cómo mejorar nuestro modelo con algunos ajustes.
Un saludo,
Gorka Madariaga (@Gk_8)
Technical Evangelist