Azure Cosmos DB – Tunable Consistency!

 By Theo van Kraay, Data and AI Solution Architect at Microsoft
By Theo van Kraay, Data and AI Solution Architect at Microsoft
There are a lot of good reasons to use Azure Cosmos DB, as it offers a uniquely ‘single pane of glass’ over the increasingly ‘polyglot persistence’ world of enterprise data. One of the innovative ways in which it does this is with the tunable consistency feature for persisting data (see here for the documented 5 levels of consistency):

It is important to consider the level of consistency in any distributed database, because of the way in which data replication is implemented. With data being spread out across many nodes in the underlying data store, high availability is made possible since the system can tolerate hardware failures and software updates. Cosmos DB can also replicate data to different geographical regions across the world with its unique turn-key global distribution capability, which allows applications to exploit data locality and reduce latency. However, when replication happens, there is obviously a period of time that elapses between data being “written” and all replicas being “consistent”.
So, why is “tunable consistency” important, and what is missing from databases that don’t have such a feature? To answer the question, it might help to look at the driver behind this very useful capability.
CAP theorem is an increasingly well-known theory in computer science, which states that it is impossible for a distributed data store to simultaneously provide more than two out of the following three guarantees:
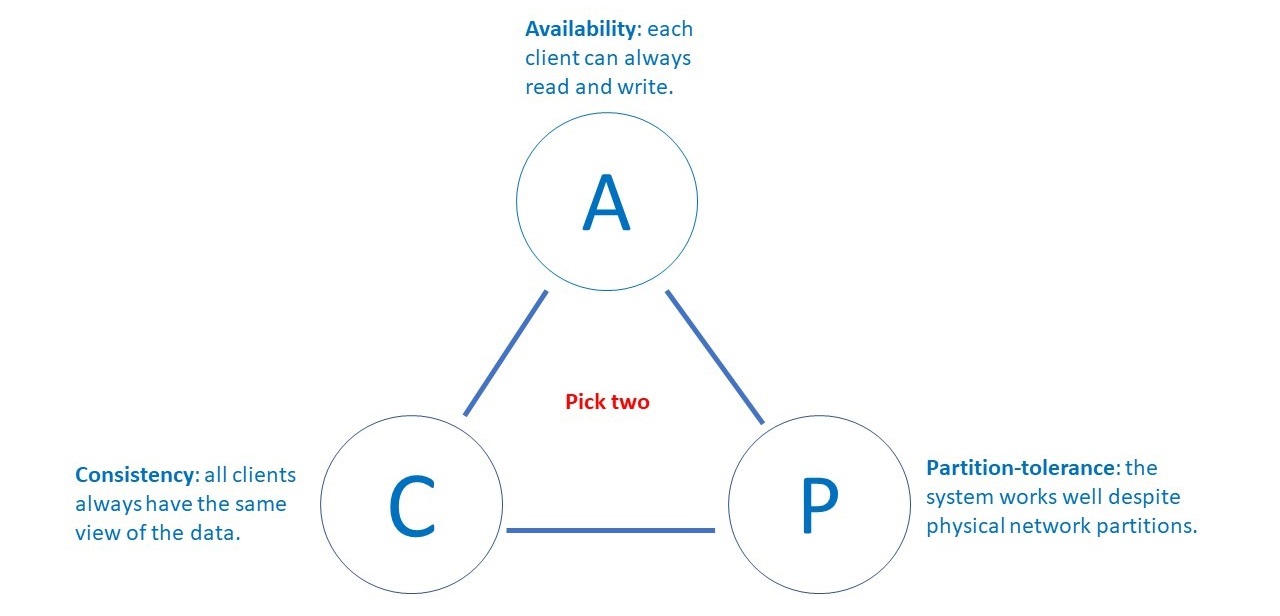
CAP Theorem is further extended by PACELC Theorem, which goes further in stating that a certain level of trade-off exists between availability and consistency, even without partitions, in a distributed system.
Bottom line: in any distributed system, there is choice between consistency and availability. You can’t have both, and that’s just physics. So, what does this mean in real terms? Let’s look at a couple of extreme examples:
An e-Commerce Website
Let’s say I have an e-commerce system with orders coming in as transactions, and I have a component application that is looking at transactions periodically, and wants to update orders from “pending payment” to “processed payment”. If I were to get a “stale read” (because my written data isn’t “consistent” across all partitions), then I could end up accidentally charging the order twice or more. I absolutely cannot afford to wait for transactions to be eventually consistent across partitions in that scenario. In this situation, I really need “strong consistency”.
Here is another scenario at the opposite end of the spectrum:
A Social Media Website
Let’s say I’m on Facebook and I’m looking at wall posts. What’s actually important here is that I see pages really quickly. If reads are stale, it doesn’t matter all that much. What I’m more interested in here is for my application to not worry about locking reads until data is consistent (and thus slowing down read performance) but rather serving up my pages quickly, whether the data is absolutely up-to-date or not... as long as it’s “eventually” up-to-date. So in this scenario, I am much happier to go with “eventual consistency”.
So, in each scenario, as CAP Theorem mandates, we need to choose one or the other type of consistency. We can’t have both. The problem is that most databases (in fact all, apart from Cosmos DB) typically only offer one of these two types of consistency model: strong or eventual (and nothing in between). So, if you are not using Cosmos DB, not only do you have to manage the two types of scenarios in separate databases, but in the real world it turns out there is actually a “spectrum of consistency” for real business scenarios, rather than a hard binary choice between “strong” or “eventual”, and having only two options turns out to be a little restrictive. This is where Cosmos DB’s 5 consistency levels start to become very useful. Let’s go back to our Facebook example...
I’m looking at my wall posts, and I’m not seeing everyone’s posts straight away, but that’s ok... I’m really none the wiser. However, there is a problem: sometimes my own posts aren’t showing up straight away when the page refreshes, so what do I do? I re-post... and what happens? I see my own post twice! Ok, no big deal, but it’s kind of annoying, isn’t it? Wouldn’t it be nice if I didn’t have to compromise the overall added read performance efficiency of eventual consistency for other people’s posts, but I am always guaranteed to see my own posts?
Enter “session” level consistency (or “read your own writes”):
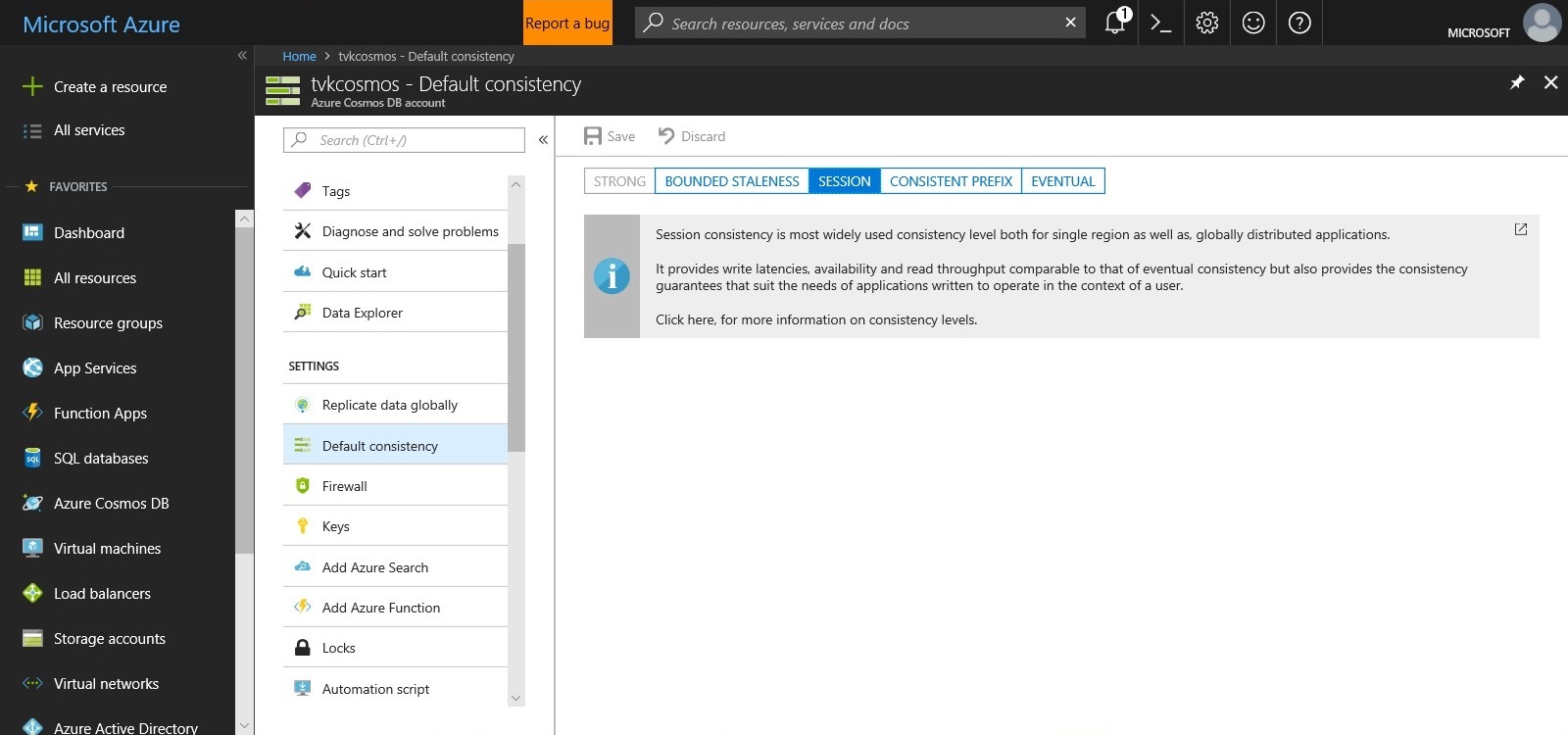
With this level of consistency, the database guarantees that clients will be able to read their own writes, by ensuring that the replica being read is consistent with the writes within that session (regardless of whether all replicas in the partition are consistent). In this way, throughput and latency savings are achieved while still providing strong “session level” consistency. A further way to simplify this concept in the social media scenario is as follows:
- I am guaranteed to see my own wall posts, which avoids accidental re-posting.
- I do not need to pay for the performance penalty of observing other users (e.g. Bob and Carol) – it’s possible to get stale reads from Bob and Carol’s data.
- I don’t have to suffer slow page loading times because Bob liked Carol’s post. I can see Bob and Carol’s posts pop up in the newsfeed later.
- Likewise, Bob and Carol do not need to pay the performance penalty of observing my writes straight away – they may see a stale copy of my data.
- Bob and Carol also don’t need to suffer slow page loading times because of me - they can see my posts pop up in the newsfeed later.
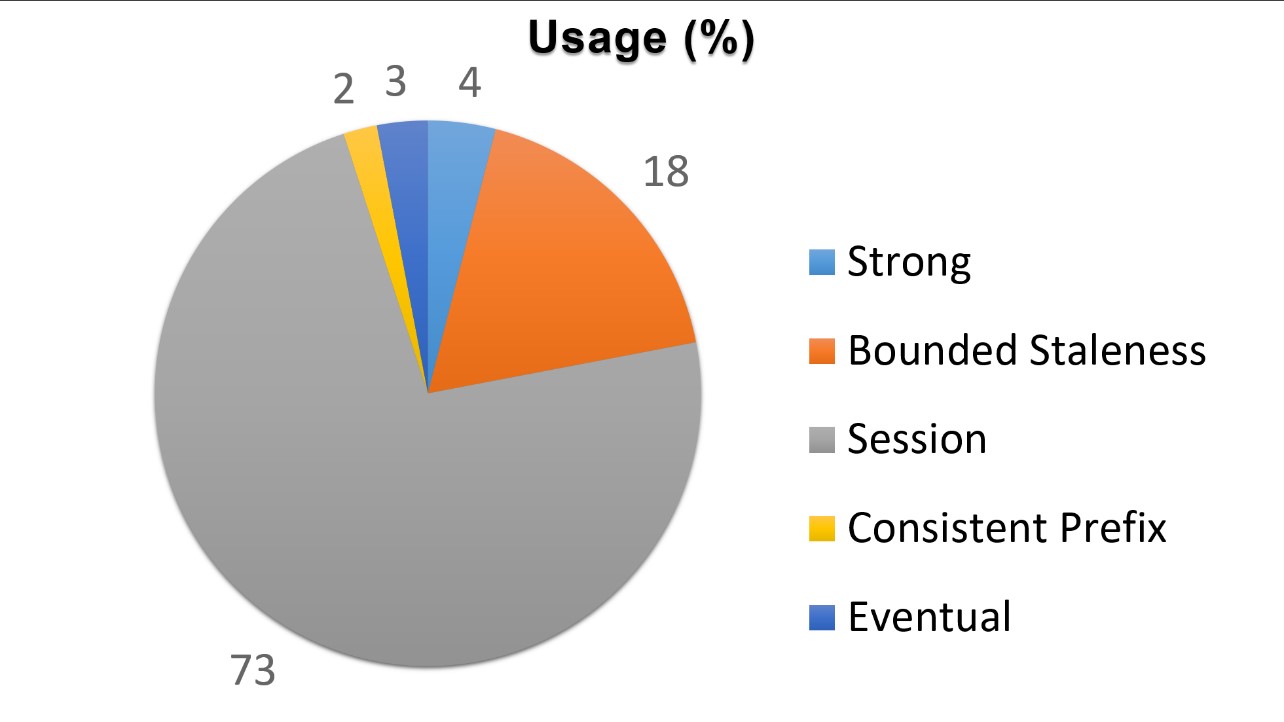
So ultimately reads are still fast, but there's no more duplicating my own posts… and the same goes for my friends! It is also worth noting that this setting, which is neither completely ‘strong’ or ‘eventual’ in the accepted sense, is actually the most popular consistency setting selected by Cosmos DB users:
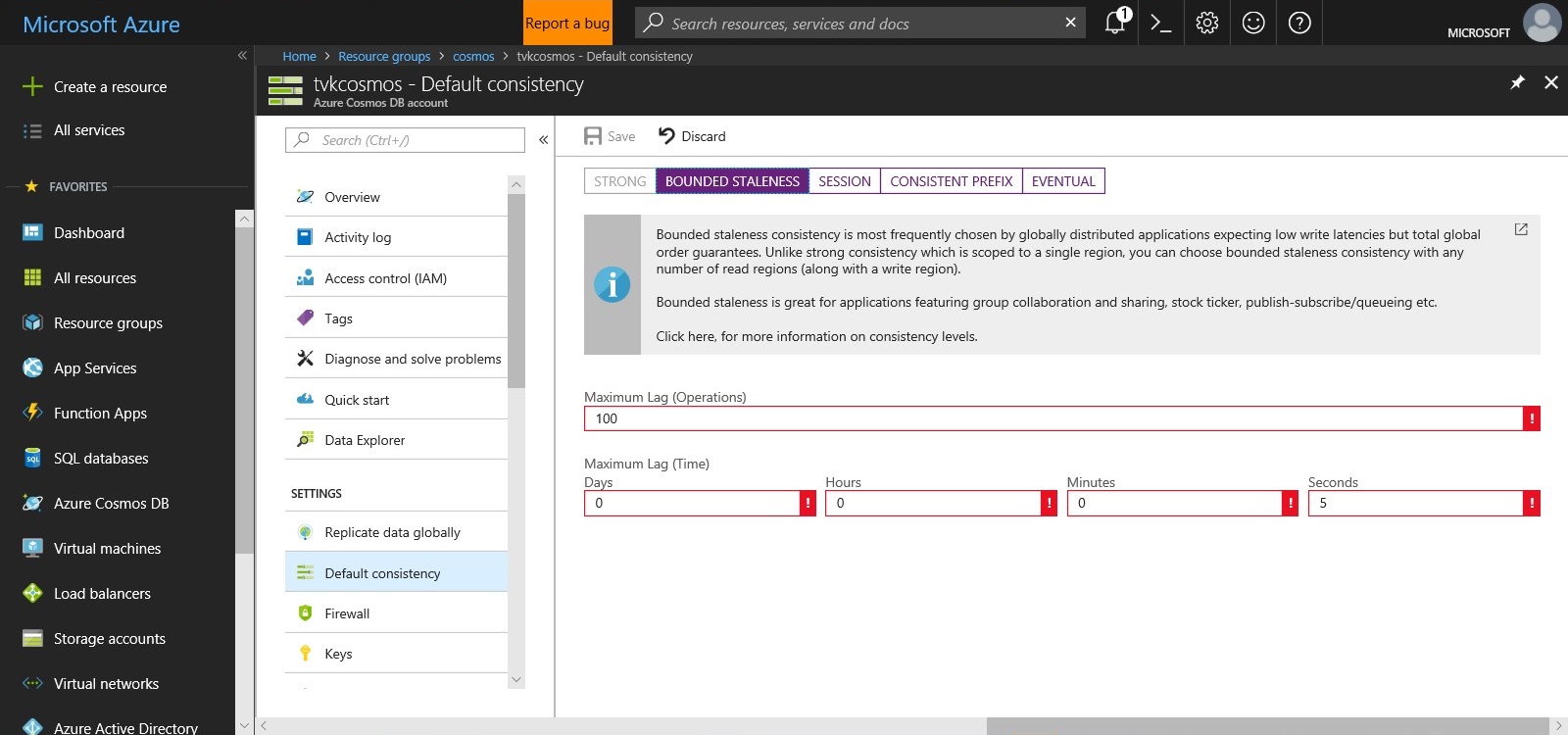
The potential benefits don’t stop there. Let’s go back to my e-Commerce site. Let’s say my order transactions aren’t just being polled by an internal application anymore, but are also being read by an array of external 3rd party order tracking services. Let’s also imagine that my application has increased significantly in scale and the critical business focus has shifted to monitoring of order status rather than updating order status quickly. My application might now be willing to accept a certain level of staleness for writes when updating payment status, but only within a certain metric of, let’s say, amount of time that a replica is allowed to lag behind, in favour of quicker read performance for the external parties so that everyone is able to see the overall status of a transaction at a point in time very quickly, accepting that data could be stale.
Enter bounded staleness in Cosmos DB! Here you can specify maximum lag times on replication:
Let’s look at one more scenario. Let’s say I have a really high throughput chat (messaging) application, and I want to take advantage of eventual consistency for reads because I want to make sure the messages are always available. Imagine we’re chatting about when to meet for dinner and the chat goes something like this:
Me: Let’s meet for dinner
You: Ok
Me: How about 7?
Me: Oh wait, I'm not sure
Me: How about 8?
You: Ok, see you then?
Me: Fine...
The problem here is that it’s possible, with eventual consistency, for those messages to come in out of order from the perspective of any given user. So you might end up meeting me at 7pm instead of 8pm! What’s the solution?
Enter “consistent prefix” consistency in Cosmos DB!
Here, Cosmos DB guarantees that replication always happens in order, regardless of lag.
Not only can you find compromises in scenarios at different levels, but with this ground breaking feature, you can do it in the same database, for the same set of business transactions, tuning as your business case changes.
---
If you’d like to learn more about Azure Cosmos DB, please visit the official website. You can also read up on other Cosmos DB use cases.
For latest news and announcements, please follow us @AzureCosmosDB and #CosmosDB