This article provides technical guidelines for implementing a compliance risk analysis solution by using Azure Cognitive Search. The guidelines are based on real-world project experiences. Given the comprehensive scope of the solution and the need to adapt it to your specific use case, the article focuses on the essential and specific architectural and implementation aspects. It references step-by-step tutorials as appropriate.
Apache®, Apache Lucene®, and the flame logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Introduction
Every day, consultants and traders in financial institutions discuss, analyze, and decide on transactions worth millions of dollars. Fraudulent transactions, collusion, insider trading, and other misconduct by employees are significant risks for these institutions, both in terms of legal consequences and public image.
Compliance teams work to mitigate these risks. Part of their work is monitoring communications across multiple channels, including instant messaging, email, and work phone calls. Often the monitoring is cross-checked against business transaction data. The goal is to find signs of non-compliance, which are often hidden and subtle. This task is labor and attention intensive and involves sifting through high volumes of data. Although automated systems can help, the volume of overlooked risks can be quite high, which results in the need to review original communications.
Azure Cognitive Search can help you automate and improve the quality of risk assessment. It has built-in AI, extensible AI, and intelligent search capabilities. The compliance risk analysis solution presented in this article shows you how to identify risks, like misconduct of financial traders, by consolidating and analyzing content from various communication channels. The potential risks that can be identified in this unstructured content include signals of market manipulation, insider trading, mutual fund fraud, and others.
The solution architecture uses Azure Cognitive Services and Azure Cognitive Search. The scenario targets communication risks in the financial sector, but the design pattern transfers to other industries and sectors, such as government and health care. Organizations can adapt the architecture by developing and integrating risk assessment models that apply to their business scenarios. For example, the Wolters Kluwer demo app provides attorneys the ability to quickly find relevant information in Securities and Exchange Commission (SEC) filings and correspondence. It identifies risks related to financing, including cybersecurity and intellectual property risks.
Azure Cognitive Search has built-in AI and custom skills that improve business process performance and the productivity of compliance teams. It's especially useful for the following situations:
- There's a need to extract insights from large numbers of heterogeneous unstructured documents, such as financial reports, speech transcriptions, and emails.
- Risk management procedures for unstructured content aren't fully in place.
- Existing approaches are time and labor intensive and result in too many false alarms or in actual risks that are overlooked.
- There's a need to integrate diverse communication channels and data sources, including structured data, for a more comprehensive risk analysis.
- Data and domain knowledge is available to train machine learning models to identify risk signals in unstructured text. Alternatively, existing models can be integrated.
- It's required that the architecture can continually ingest and process newly available unstructured data, such as conversations and news, to improve the solution.
- Compliance analysts need an efficient tool for the identification and detailed analysis of risks. The tool must be a human-in-the-loop tool so that the analysts control the process and can flag possible incorrect predictions in order to improve the models.
Azure Cognitive Search is a cloud search service that has built-in AI capabilities that enrich all types of information to help you identify and explore relevant content at scale. You can use cognitive skills for vision and language or use custom machine learning models to uncover insights from all types of content. Azure Cognitive Search also offers semantic search capabilities that use advanced machine learning techniques to classify user intent and contextually rank the most relevant search results.
The following diagram shows a high-level view of how Azure Cognitive Search works, from data ingestion and indexing to making results available to the user.

Download a PowerPoint file of this architecture.
This article provides details about the solution for the risk analysis use case and other financial services scenarios like the Wolters Kluwer example mentioned earlier. It provides technical execution steps with referenced how-to documentation and a reference architecture. It includes best practices from organizational and technical perspectives. The design pattern assumes that you bring your own data and develop your own risk analysis models, suitable for your business context and requirements.
Tip
Check these resources for an introduction to Azure Cognitive Search and experience it in action:
Solution overview
The following diagram provides a high-level view of the risk analysis solution.

Download a PowerPoint file of this architecture.
To identify true-risk communications, content from heterogeneous communication channels is extracted and enriched by various machine learning models from Cognitive Services. Next, custom domain-specific models are applied to identify signs of market manipulation and other risks that appear in communications and interactions among people. All data is aggregated into a consolidated Azure Cognitive Search solution. The solution consists of a user-friendly app with risk identification and analysis capabilities. Application data is stored in a search index, and in a knowledge store if you need longer term storage.
The following illustration provides a conceptual overview of the solution architecture:

Download a PowerPoint file of this architecture.
Although each communication channel—for example, email, chats, and telephony—can be used in isolation to detect potential risks, better insights are achieved by combining channels and augmenting the content with complementary information such as market news.
The risk analysis solution uses several interfaces to integrate enterprise communications systems for data ingestion:
- Blob Storage is used as a general source for data in document format, such as email content, including attachments, transcripts of phone calls or chats, and news documents.
- Office 365 communication services like Microsoft Exchange Online and Microsoft Teams can be integrated by using Microsoft Graph Data Connect for bulk ingestion of email, chats, and other content. An Azure Cognitive Search interface for SharePoint in Microsoft 365 is also available.
- Voice communications such as phone calls are transcribed by using the Speech to Text service of Cognitive Services. The resulting transcriptions and metadata are then ingested by Azure Cognitive Search via Blob Storage.
These examples cover frequently used enterprise communication channels. However, the integration of additional channels is also possible and can use similar ingestion patterns.
After consolidation, the raw data is enriched by AI skills to detect structure and create text-based content out of previously unsearchable content types. For example:
- Financial reports in PowerPoint files or PDFs often contain embedded images instead of machine-readable text, in order to prevent changes. To process this kind of content, all images are analyzed by optical character recognition (OCR) by using the OCR cognitive skill.
- Content in various languages is translated into English or another language by using the Text Translation cognitive skill.
- Significant information like names of people and organizations are automatically extracted and can be used for powerful search queries by using the Entity Recognition cognitive skill. For example, a search can find all communications between James Doe and Mary Silva that discuss a particular company during a specified time period.
- Custom models are used to identify evidence of risk, such as insider trading, in communications. These domain-specific models can be based on keywords, utterances, or whole paragraphs. They use advanced natural language processing (NLP) technologies. Custom models are trained by using domain-specific data for the present use case.
After applying the Azure Cognitive Search AI enrichments and custom skills, the content is consolidated into a search index to support rich search and knowledge mining scenarios. Compliance analysts and other users use the front-end app to identify potential risk communications and perform drill-down searches for further analysis. Risk management is a dynamic process. Models are constantly improved in production and models for new risk types are added. Therefore, the solution needs to be modular. New risk types are automatically flagged in the UI as the set of models is extended.
The front-end app uses intelligent and semantic search queries to examine the content. The content can also be moved into a knowledge store for compliance retention or integration with other systems.
The building blocks of the solution are described in greater detail in the following sections.
Implementing a risk analysis solution is a multidisciplinary exercise that requires the involvement of key stakeholders from various domains. Based on our experiences, we recommend including the following roles to ensure a successful development and organizational adoption of the solution.

Tip
- Check out the documentation for more information about Azure AI Search.
Data Ingestion
This section explains how to consolidate heterogenous content into a single data source and then set up an initial collection of search assets that are derived from that source.
The development and implementation of an Azure Cognitive Search solution is frequently an incremental process. The addition of data sources, transformations, and augmentations is done in successive iterations, on top of baseline configurations.
The first step of an Azure Cognitive Search solution is creating a service instance in the Azure portal. Besides the search service itself, you need several search assets, including a search index, indexer, data source, and skillset. You can create a baseline configuration with little effort by using the Import data wizard of Azure Cognitive Search, which is in the Azure portal. This wizard, illustrated here, guides the user through the basic steps of creating and loading a simple search index that uses data from an external data source.

The creation of the search index by the Import data wizard has four steps:
- Connection to data: Connection to existing Blob Storage, for example, can be done effortlessly with a few clicks. A connection string is used for authentication. Other natively supported data sources include a variety of Azure Services such as Azure SQL Database, Azure Cosmos DB, and services like SharePoint Online. In this solution, Blob Storage is used to consolidate the heterogeneous content types.
- Addition of cognitive skills: In this optional step, built-in AI skills are added to the indexing process. They're applied to enrich the content that's read from the data source. For example, this step can extract the names and locations of people and organizations.
- Customization of target index: In this step, the developer configures the field entities for the index. A default index is provided, but fields can be added, deleted, or renamed. Example fields are: document title, description, URL, author, location, company, and stock ticker, and the types of operations that are possible on each of them.
- Creation of indexer: The last step configures an indexer, the component that runs regularly to update the contents of the search index. A key parameter is how often the indexer should run.
When the configurations are confirmed, a data source, a skillset, an indexer, and an index are created. For each of these components, a JSON definition is created. The JSON definitions provide enhanced customization and can be used to create the services programmatically via a REST API. The benefit is consistent and programmatic creation of assets in all subsequent development iterations. For this reason, we use JSON definitions to demonstrate the configuration of all assets. The section Automatic creation of search assets provides detailed explanations of how to use these definitions to programmatically create all assets.
In the configuration, Blob Storage is selected as the default data source. Even though communications can originate from multiple channels or sources, a generic approach for this solution pattern relies on all communications existing in Blob Storage and containing text and/or images. The following step will expand on the configuration of a data source JSON definition for Blob Storage.
Some patterns are referenced in this section to exemplify how to ingest Office 365 communications into Blob Storage, and how to transcribe audio calls by using the Speech to Text service.
Tip
How to implement:
Blob Storage
The following JSON definition shows the structure and information that's needed to configure Blob Storage as a data source for Azure Cognitive Search:
{
"name": "email-ds",
"description": "Datasource for emails.",
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=..."
},
"container": {
"name": "communications",
"query": "written_comms/emails"
}
}
The following fields are required
- Name: The name that's assigned to the data source.
- Type: Defines the data source as Blob Storage.
- Credentials: The connection string for Blob Storage.
- Container: The name of the container where the blobs are stored. A directory within the container can be specified so that multiple data sources can be created within the same container.
By default, the Blob Storage data source supports a wide range of document formats. For example, audio transcriptions are often stored in JSON files, emails are typically MSG or EML files, news or additional communication material are often in PDF, Word formats like DOC/DOCX/DOCM, or PowerPoint formats such as PPT/PPTX/PPTM, or HTML web pages.
To set up multiple data sources for communications in the same Blob Storage, you can use one of the following techniques:
- Give each data source its own container.
- Use the same container for all data sources, but give each data source its own directory in that container.
Microsoft Graph Data Connect
For Office 365 customers, Microsoft Graph Data Connect can be used to extract selected data from Microsoft Graph into Azure Storage, upstream of the Azure Cognitive Search solution. The data stored in Microsoft Graph includes data such as emails, meetings, chats, SharePoint documents, people, and tasks.
Note
The use of this mechanism is subject to a data consent process.

Download a PowerPoint file of this architecture.
The diagram shows the flow of data from Microsoft Graph. The process relies on Azure Data Factory capabilities to extract data from Microsoft Graph. There's granular security control, including consent and a governance model. The Data Factory pipeline is configured with the data types to extract, such as email messages and team chats, and a scope such as a user group and date range. The search is executed on a defined schedule at configurable intervals, and configured to drop the extracted data into Azure Storage. From there, the data is ingested into Azure Cognitive Search by an indexer.
Tip
The following articles include step-by-step instructions on how to set up an extraction of data from Microsoft Graph Data Connect into Azure Storage via Data Factory, for later ingestion into Azure Cognitive Search:
Speech-to-text reference architecture
Telephone conversations are an essential work tool at any financial services organization. They can be included in a risk analysis solution if there's access to the respective audio files. This section covers this situation.
Document cracking in Azure Cognitive Search is a set of processing steps that are executed by the indexer to extract text and images from the data source. For audio files, we need a way to extract transcriptions of these audio communications so that they're available for text-based processing.
The following diagram shows an audio ingestion and speech-to-text pipeline. The pipeline processes batches of audio files and stores the transcription files to Blob Storage, upstream of the Azure Cognitive Search solution.

Download a PowerPoint file of this architecture.
In this reference architecture, audio files are uploaded to Blob Storage via a client application. During this process, the application authenticates by using Microsoft Entra ID and calls the REST API to get a token for Blob Storage. Secure access to the REST API is provided by Azure API Management, and an Azure Key Vault provides secure storage of the secrets needed to generate the tokens, as well as account credentials.
After the files are uploaded, an Azure Event Grid trigger is emitted to invoke an Azure function. The function then processes the audio file by using the Cognitive Services Speech-to-Text API. The transcribed JSON document is then stored in a separate blob container, which can be ingested as a data source by Azure Cognitive Search.
Tip
Refer to the following article for details on integrating speech transcription:
Search solution
As described, multiple data sources such as emails, transcriptions, and news are created and then stored in Blob Storage. Each data source is then transformed and enriched in its own way. All the resulting output is mapped to the same index, consolidating data from all types of source documents.
The following diagram illustrates this approach. A custom indexer is configured for each of the available data sources, and all results feed one single search index.

The following sections explore the indexing engines and searchable indexes. They show how to configure an indexer and how to index JSON definitions to implement a searchable solution.
Indexers
An indexer orchestrates the extraction and enrichment of document content. An indexer definition includes details on the data source that's to be ingested, how to map the fields, and how to transform and enrich the data.
Because the mapping, transforming, and enriching varies by data type, there should be an indexer for each data source. For example, indexing emails can require OCR skills to process images and attachments, but transcriptions need only language-based skills.
These are the steps of the indexing process:
- Document cracking: Azure Cognitive Search opens and extracts the relevant content from documents. The extracted indexable content is a function of the data source and file formats. For example, for a file such as a PDF or Microsoft 365 file in Blob Storage, the indexer opens the file and extracts text, images, and metadata.
- Field mapping: The names of the fields that were extracted from the source are mapped into destination fields in a search index.
- Skillset execution: Built-in or custom AI processing is done in this step, as described in a later section.
- Output field mapping: The names of transformed or enriched fields are mapped to destination fields in an index.
The following snippet shows a segment of the email indexer JSON definition. This definition uses the information that's detailed in the steps and provides a detailed set of instructions to the indexing engine.
{
"name": "email-indexer",
"description": "",
"dataSourceName": "email-ds",
"skillsetName": "email-skillset",
"targetIndexName": "combined-index",
"disabled": null,
"schedule": {
"interval": "P1D",
"startTime": "2021-10-17T22:00:00Z"
},
"parameters": {
"batchSize": null,
"mixabilities": 50,
"maxFailedItemsPerBatch": 0,
"base64EncodeKeys": null,
"configuration": {
"imageAction": "generateNormalizedImages",
"dataToExtract": "contentAndMetadata",
"parsingMode": "default"
}
},
"fieldMappings": [
{
"sourceFieldName": "metadata_storage_path",
"targetFieldName": "metadata_storage_path",
"mappingFunction": {
"name": "base64Encode",
"parameters": null
}
}
],
"outputFieldMappings": [
{
"sourceFieldName": "/document/merged_content/people",
"targetFieldName": "people"
},
{
"sourceFieldName": "/document/merged_content/organizations",
"targetFieldName": "organizations"
},
In this example, the indexer is identified by the unique name email-indexer. This indexer refers to a data source named email-ds, and the AI enrichments are defined by the skillset named email-skillset. The outputs of the indexing process are stored in the index named combined-index. Additional details include a schedule set to daily, a maximum number of 50 failed items, and a configuration to generate normalized images and to extract content and metadata.
In the field mapping section, the metadata_storage_path field is encoded by using a base64encoder, to serve as a unique document key. In the output field mapping configuration (only partially displayed), the outputs of the enrichment process are mapped to the index schema.
If a new indexer is created for a new data source (for example, transcriptions), the bulk of the JSON definition is configured to align with the data source and skillset selection. However, the target index must be combined-index (provided that all field mappings are compatible). This is the technique that enables the index to consolidate results from multiple data sources.
Indexes and other structures
After the indexing process is done, the extracted and augmented documents are persisted in a searchable index and, optionally, in knowledge stores.
Searchable index: A searchable index corresponds to the required output that's always created as part of an indexing process and is occasionally also called a search catalog. To create an index, an index definition is required. It contains configurations (such as type, searchable, filterable, sortable, facetable, and retrievable) for all fields. These index field names need to align with the indexer field and output field mappings.
Multiple indexers can be assigned to the same index, so that the index consolidates communications from different datasets, such as emails or transcriptions. An index can then be queried by using either full-text search or semantic search.
Similar to indexers, indexes can be configured by using an index JSON definition. The following snippet corresponds to a segment of the combined-index JSON definition:
{ "name": "combined-index", "fields": [ { "name": "metadata_storage_path", "type": "Edm.String", "facetable": false, "filterable": false, "key": true, "retrievable": true, "searchable": false, "sortable": false, "analyzer": null, "indexAnalyzer": null, "searchAnalyzer": null, "synonymMaps": [], "fields": [] }, { "name": "people", "type": "Collection(Edm.String)", "facetable": true, "filterable": true, "retrievable": true, "searchable": true, "analyzer": "standard.lucene", "indexAnalyzer": null, "searchAnalyzer": null, "synonymMaps": [], "fields": [] },In this example, the index is identified by the unique name combined-index. The index definition is independent of any indexers, data sources, or skillsets. The fields define the schema of the index and, at the time of configuration, a user can configure the name and type of each field, as well as a set of properties, such as facetable, filterable.
In this snippet, two fields are included. Metadata_storage_path is a retrievable string that's used as document key. On the other hand, the people field is a collection of strings that can be facetable, filterable, retrievable, and searchable, and the full-text querying is processed by using a standard.lucene analyzer.
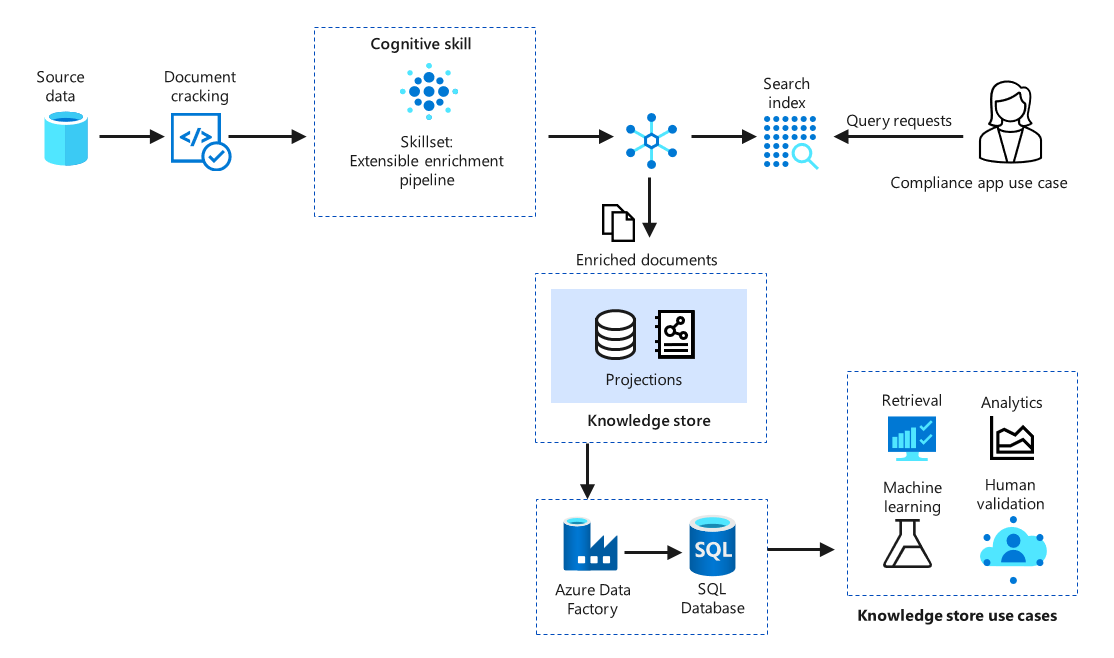
Knowledge store: A knowledge store can be an optional output, to be used for independent analysis and downstream processing in non-search scenarios like knowledge mining. The implementation of a knowledge store is defined within a skillset, where the enriched document or specific fields can be configured to be projected as tables or files.
The following illustration shows an implementation of a knowledge store:

Download a PowerPoint file of this architecture.
With an Azure Cognitive Search knowledge store, data can be persisted by using the following options (called projections):
- File projections enable extraction of content (for example, embedded images) as files. An example is diagrams or charts from financial reports that are exported in image file formats.
- Table projections support tabular reporting structures (for example, for analytics use cases). They can be used for storing aggregated information like risk scores for each document.
- Object projections extract content as JSON objects into Blob Storage. They can be used for the risk analysis solution if data needs to be retained in granular detail for compliance reasons. Risk scores can be archived by using this approach.
Because the structure of the search data is optimized for queries, it's generally not optimized for other purposes, like exporting to a knowledge store. You can use the Shaper Skill to restructure the data to suit your retention requirements before applying the projections.
In a knowledge store, the persisted content is stored in Azure Storage, either in table or blob storage.
There are several options for using data from a knowledge store. Azure Machine Learning can access the content for building machine learning models. Power BI can analyze the data and create visuals.
Financial organizations have existing policies and systems for long term compliance retention. Therefore, Azure Storage might not be the ideal target solution for this use case. After the data is saved in the knowledge store, Data Factory can export it to other systems such as databases.
Query engine
After an index is created, you can use Azure Cognitive Search to query it by using full-text and semantic searches.
- Full-text search is built on the Apache Lucene query engine and accepts terms or phrases that are passed in a search parameter in all searchable fields of the index. When matching terms are found, the query engine ranks the documents in order of relevance and returns the top results. Document ranking can be customized via scoring profiles, and results can be sorted by using index sortable fields.
- Semantic search provides a set of powerful features that improve the quality of search results by using semantic relevance and language understanding. When enabled, semantic search extends the search capability in the following ways:
- Semantic re-ranking uses the context or semantic meaning of a query to compute a new relevance score over existing results.
- Semantic highlights extracts sentences and phrases from a document that best summarize the content.
The User interface section includes an example of the power of semantic search. Semantic search is in public preview. More information on its capabilities can be found in the documentation.
Automatic creation of search assets
Developing a search solution is an iterative process. After you've deployed the Azure Cognitive Search infrastructure and the initial version of search assets like data source, index, indexer, and skillset, you continuously improve your solution (for example, by adding and configuring AI skills).
To ensure consistency and fast iterations, we recommend that you automate the process of creating the Azure Cognitive Search assets.
For our solution, we use the REST API of Azure Cognitive Search to deploy ten assets in an automated fashion, as shown in this illustration:

Because our solution requires different processing and AI enrichments for emails, transcriptions, and news documents, we create distinct data sources, indexers, and skillsets. However, we decided to use a single index for all channels to simplify the use of the risk analysis solution.
Each of the ten items has an associated JSON definition file to specify its configuration. See the example code boxes in this guide for explanations about the settings.
The JSON specifications are sent to Azure Cognitive Search via API requests made by the build-search-config.py script in the order shown. The following example illustrates how to create the email skillset that's specified in email-skillset.json:
url = f"https://{search_service}.search.windows.net/skillsets?api-version=2020-06-30-Preview"
headers = {'Content-type': 'application/json', 'api-key': cog_search_admin_key}
r = requests.post(url, data=open('email-skillset.json', 'rb'), headers=headers)
print(r)
- search_service is the name of the Azure Cognitive Search resource.
- cog_search_admin_key is the admin key. Using a query key isn't sufficient for management operations.
After all configuration requests have been performed and the index is loaded, a REST query determines whether the search solution responds properly. Note that there's a time delay before all assets are generated and the indexers have completed their initial runs. You might need to wait a few minutes before querying for the first time.
For information about how to use the Azure Cognitive Search REST API to programmatically create the configuration for indexing Blob Storage content, see: Tutorial: Use REST and AI to generate searchable content from Azure blobs.
Tip
AI enrichments
In the previous sections, we built the foundation of the risk analysis solution. Now it's time to focus on the processing of information from raw content into tangible business insights.
To make the content searchable, the communication content is passed through a pipeline of AI enrichments that use built-in skills and custom models for risk detection:

First, we look at how to use built-in skills based on the example skills 1 to 4 that we used for the risk analysis solution. Then, we see how to add a custom skill for integrating risk models (step 5). Finally, we see how to review and debug the pipeline of skills.
The following sections provide a conceptual introduction. For a hands-on experience, see the Microsoft Learn step-by-step guide.
Built-in AI enrichment skills
The pipeline of applied AI enrichments is called an Azure Cognitive Search skillset. The following built-in skills are used in the risk analysis solution:
Optical character recognition: Financial reports can include a significant amount of content that's embedded in images rather than text in order to prevent changes to the content. The following presentation shows an example from a Microsoft quarterly report:
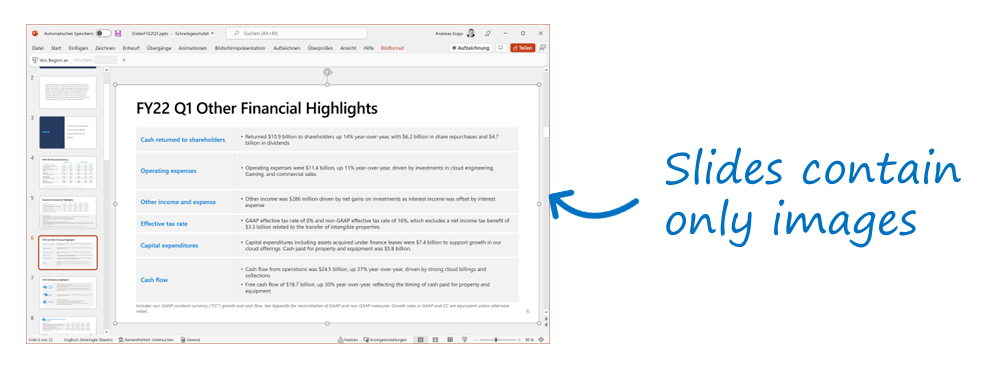
All slides of the deck contain only graphics content. To make use of the information, the OCR cognitive skill is used for emails (it's especially relevant for attachments) and market news documents. This ensures that search queries such as "capital expenditures" in the earlier example find the text from the slide even though the original content isn't machine-readable. Search relevance is improved further by semantic search in cases where users utilize deviating terms for "capital expenditures" that aren't contained in the text.
Language detection: In a global organization, support for machine translation is a common requirement. Assuming that the team of compliance analysts prefers to read and communicate consistently in English, for example, the solution needs to be able to translate the content accurately. The language detection cognitive skill is used to identify the language of the original document. This information is used to identify whether a translation to the desired target language is required and is also shown in the user interface to indicate the original language to the user.
Extract people and organizations: The Entity Recognition cognitive skill can identify persons, locations, organizations, and other entities in unstructured text. This information can be used to improve search or navigation (for example, filtering and faceting) across a large body of heterogenous content. For the risk analysis solution, extraction of people (for example, trader names) and organizations (for example, company names) were chosen.
The following example from the JSON definition of the skillset for emails provides details about the selected configuration:
"skills": [ { "@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill", "name": "Detect Entities", "description": "Detect people and organizations in emails", "context": "/document/merged_content", "categories": [ "Person", "Organization" ], "defaultLanguageCode": "en", "minimumPrecision": 0.85, "modelVersion": null, "inputs": [ { "name": "text", "source": "/document/merged_content" }, { "name": "languageCode", "source": "/document/original_language" } ], "outputs": [ { "name": "persons", "targetName": "people" }, { "name": "organizations", "targetName": "organizations" } ] },First, we specify the extraction of persons and organizations from the content. Other categories exist (for example, locations) and can be extracted if needed. However, we intentionally restricted extraction to these two entities to avoid overwhelming users with too much information at the beginning.
Because no AI solution provides 100% accuracy, there's always a risk of false positives (for example, organization names that aren't really organizations) and false negatives (for example, actual organizations are overlooked). Azure Cognitive Search provides controls to balance the signal-to-noise ratio in extracting entities. In our case, we set the minimum precision for detection to 0.85 to enhance the recognition relevance and reduce the noise.
In the next step, we specify the inputs and outputs for the skillset within the enriched document. Our input path points to merged_content, which includes the email and attachments. The attachments content includes text that was extracted by using OCR.
Finally, we define the output names people and organizations for the specified entities. Later, these are mapped to the search index as part of the indexer definition.
The definitions of the other skills follow a similar pattern, supplemented by skill-specific settings.
Translation: The actual translation of documents that contain foreign languages into English is performed in the next step. The Text Translation cognitive skill is used for conversion. Note that the translation charges are assessed whenever text is sent to the Translator Text API, even if the source and target language are the same. To avoid service charges in these circumstances, additional conditional cognitive skills are used to bypass translation in such cases.

Tip
You can use the Import data assistant from Azure Cognitive Search to start ingesting and enriching content quickly. Going forward, you benefit from creating skillsets and other Azure Cognitive Search assets in an automated fashion. The following article provides more information:
Custom AI enrichments for risk detection
Now that you've implemented the desired built-in skills from Azure Cognitive Search, let’s look at how to add custom models for risk analysis.
Identifying intended or actual misconduct in communication content is always context-dependent and requires extensive domain knowledge. A key objective of the risk analysis solution is to provide a way to flexibly integrate and apply custom risk models into the enrichment pipeline to uncover true risks for specific business scenarios.
Depending on the use case, the following conversation example might indicate a potential intended misconduct:

The following options can parse unstructured communication content to identify risks:
- Keyword-based approach: This technique uses a list of relevant keywords (for example, offline, special insights) to identify potential risks. This approach is easy to implement but can overlook risks if the formulations in the content don't match the keywords.
- Entity recognition-based approaches: A machine learning model is trained on short utterances (for example, sentences) to identify risks by using a language model. Expert knowledge is used to create a training set of representative examples with the corresponding risk classification (for example, market manipulation, insider trading). A key advantage of this technique is that risks are likely to be identified if the utterances have a similar semantic meaning but different formulations from the examples in the training set. The Azure Conversational language understanding service can be used for such purposes.
- Advanced NLP based approaches: Recent advances in neural networks make it possible to analyze longer segments of unstructured text, including classification and other NLP tasks. This approach can identify signals that are more subtle and that span several sentences or paragraphs. The downside of this approach is that typically much more training data is required compared to other techniques. Azure provides several options for training NLP models, including Custom Text Classification and Automated Machine Learning.
Any model that's provided as a REST web service can be integrated as a custom skill into the Azure Cognitive Search risk analysis solution. In our example, we integrate a set of Conversational Language Understanding models with an Azure function that acts as the interface between Azure Cognitive Search and the models. The following diagram illustrates this technique:

Download a PowerPoint file of this architecture.
Emails and transcriptions are scanned for risks after processing of the built-in skills. The custom skill provides the document type and its content to the Azure Functions app for preprocessing. The app is based on the published example and performs the following tasks:
- Determines which models to use: Organizations might use distinct models to identify several types of risks (for example, market manipulation, insider trading, mutual fund fraud). The Functions app activates the available models depending on the configured preferences.
- Preprocesses content: This task includes dropping attachment content and splitting the text into sentences to match the structure of the data that's used to train the risk models.
- Sends the tokenized content to the configured risk models: The risk models assign risk scores to each sentence.
- Aggregates and scores the results: This is done prior to returning them to the skillset. The document risk score is the highest risk of all its sentences. The identified top risk sentence is also returned for display in the UI. Also, document risks are classified based on the score as low, medium, or high risk.
- Writes information to the Azure Cognitive Search index: The information is used in the compliance analyst UI and in the knowledge store. It includes all communications content, the built-in enrichments, and the results of the custom risk models.
The following JSON example illustrates the interface definition between Azure Cognitive Search and the Functions app (which calls the risk models) as a custom skill:
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "apply-risk-models",
"description": "Obtain risk model results",
"context": "/document/content",
"uri": "https://risk-models.azurewebsites.net/api/luis-risks?...",
"httpMethod": "POST",
"timeout": "PT3M",
"batchSize": 100,
"degreeOfParallelism": null,
"inputs": [
{
"name": "text",
"source": "/document/mergedenglishtext"
},
{
"name": "doc_type",
"source": "/document/type"
}
],
"outputs": [
{
"name": "risk_average",
"targetName": "risk_average"
},
{
"name": "risk_models",
"targetName": "risk_models"
}
],
},
The URI specifies the web address of the Functions app that gets the following inputs from Azure Cognitive Search:
- text contains the content in English language.
- doc_type is used to distinguish between transcriptions, emails, and market news—they require different preprocessing steps.
After the Functions app receives the risk scores from the conversational language understanding feature of Azure Cognitive Service for Language, it returns the consolidated results to Azure Cognitive Search.
Financial services organizations need a modular approach for flexibly combining existing and new risk models. Therefore, no hard coding of specific models is performed. Instead, risk_models is a complex data type that returns details for each risk type (for example, inside trade) including the risk score and the identified sentence with the highest risk score. Compliance and traceability are key concerns for financial services organizations. However, risk models are constantly improved (for example, utilizing new training data), so the predictions for a document can change over time. To ensure traceability, the specific version of the risk model is also returned with each prediction.
The architecture can be reused to integrate more advanced NLP models (for example, to enable identification of more subtle risk signals that might span several utterances). The main adjustment is to match the preprocessing step in the Functions app to the preprocessing that was done for training the NLP model.
Tip
How to implement:
- This example from the documentation was used as starting point for building the risk analysis solution described in this guide.
- Use this guide to build and deploy a custom skill with Azure Machine Learning.
Debugging AI enrichment pipelines
Understanding the flow of information and AI enrichments can be challenging for large skillsets. Azure Cognitive Search provides helpful capabilities for debugging and visualizing the enrichment pipeline, including the inputs and outputs of the skills.

The flowchart was extracted from Debug sessions tab of the Azure Cognitive Search resource in the Azure portal. It summarizes the flow of enrichments as the content is successively processed by the built-in skills and custom risk models in a skillset.
The processing flow in the skill graph is automatically generated by Azure Cognitive Search based on the input and output configurations of the skills. The graph also shows the degree of parallelism in processing.
A conditional skill is used to identify the document type (email, transcription, or news) because they're processed differently in later steps. Conditional skills are used to avoid translation charges for cases where the original and target languages are the same.
The built-in skills include OCR, language detection, entity detection, translation, and text merge, which is used to replace an embedded image with embedded OCR output in the original document.
The last skill in the pipeline is the integration of the conversational language understanding risk models via the Functions app.
Finally, the original and enriched fields are indexed and mapped to the Azure Cognitive Search index.
The following excerpt from a search response shows an example of the insights that can be obtained by using enriched content and semantic search. The query term is "how were capex" (short for "how did capital expenditures develop in the reporting period?").
{
"@search.captions" : [
{
"highlights" : "Cash flow from operations was $22.7 billion, up 2296 year-over-year, driven by strong cloud billings and collections Free cash flow of $16.3 billion, up 1796 year-over-year, reflecting higher<em> capital expenditures</em> to support our cloud business 6 includes non-GAAP constant currency CCC\") growth and cash flow."
}],
"sender_or_caller" : "Jim Smith",
"recipient" : "Mary Turner",
"metadata_storage_name" : "Reevaluate MSFT.msg",
"people" : ["Jim Smith", "Mary Turner", "Bill Ford", … ],
"organizations" : ["Microsoft", "Yahoo Finance", "Federal Reserve", … ],
"original_language" : "nl",
"translated_text" : "Here is the latest update about …",
"risk_average" : "high",
"risk_models" : [
{
"risk" : "Insider Trade",
"risk_score" : 0.7187,
"risk_sentence" : "Happy to provide some special insights to you. Let’s take this conversation offline.",
"risk_model_version" : "Inside Trade v1.3"
},
]
}
User interface
After a search solution is implemented, you can query the index directly by using the Azure portal. Although this option is good for learning, experimenting, and debugging, it’s not a good end user experience.
A customized user interface, focusing on the user experience, is useful to show the true value of the search solution and to make it possible for organizations to identify and review risk communications across a range of channels and sources.
The Knowledge Mining Solution Accelerator provides an Azure Cognitive Search UI template—a .NET Core MVC Web app—that can be used to quickly build a prototype to query and view the search results.
In a few steps, the template UI can be configured to connect and query the search index, rendering a simple web page to search and visualize the results. This template can be further customized to enhance the experience of retrieving and analyzing risk communications.
The following screenshot shows a sample user interface for our risk scenario, created by customizing the Azure Cognitive Search UI template. This UI shows a way to show the search solution by providing an intuitive view of cross channel communications and risk information.

The start page provides interaction with the search solution. It empowers the user to search, refine, visualize, and explore results:
- The initial results are retrieved from a search index and displayed in a tabular form, providing easy access to communications, and simplifying the comparison of results.
- Key communication details are available to the user, and documents from multiple channels (emails, transcriptions, news) are consolidated into a single view.
- Scores from the custom risk models are shown for each communication, where higher risks can be highlighted.
- A consolidated risk classification aggregates the scores from the custom risk models and is used to sort results based on the average risk level.
- A threshold slider provides the capability for the user to change the risk thresholds. Custom risk scores that exceed the threshold are highlighted.
- A date range selector provides the capability to widen the period of analysis, or to search for historical results.
- The search results can be refined by using a set of filters, such as language or type of document. These options are generated dynamically in the UI, as a function of the facetable fields configured in the index.
- A search bar provides the capability to search the index for specific terms or phrases.
- Semantic search is available. The user can switch between standard and semantic search.
- New communications can be uploaded and indexed directly via the user interface. A details page is also provided for each document:

The details page provides access to the content of the communication and to enrichments and metadata:
- The content that was extracted during the document cracking process is displayed. Some files such as PDFs can be viewed directly in the details page.
- The results of the custom risk models are summarized.
- Top people and organizations that are mentioned in the document are shown in this page.
- Additional metadata that was captured during the indexing process can be added and shown in additional tabs of the details page.
If non-English content is ingested, the user can review the content in either the original language or in English. The Transcript tab of the details page shows the original content and the translated content side by side. This demonstrates that, during the indexing process, both languages are persisted, allowing both to be consumed by the user interface.
Finally, the user can do semantic searches. The next example shows the top result where the expression "how were capex" (short for "how did capital expenditures develop in the reporting quarter?") was searched by using semantic search.

An equivalent search in full-text mode results in the search query searching for an exact match for "capex", which does not appear in the document. The semantic capability, however, makes it possible for the query engine to identify that "capex" relates to "capital expenditures", so that this communication is identified as the most relevant. Moreover, semantic search generates semantic highlights (12), summarizing the document with the most relevant sentences.
Best Practices
This section summarizes organizational and technical best practices for developing your compliance risk analysis solution.
Involve required stakeholders: Implementing a risk analysis solution is a multidisciplinary exercise that involves key stakeholders from various domains. Expect to include the project-related roles that were introduced previously and other roles that are affected by the solution.
Ensure adequate adoption and change management: Automating risk analysis practices will likely introduce significant changes in how employees work. Although the solution adds value, changes to any workflow can be challenging, leading to long adoption periods and, possibly, resistance. Best practices suggest that you should involve affected employees early. Consider the Prosci ADKAR adoption model, which focuses on five key steps of a technology adoption journey: Awareness, Desire, Knowledge, Ability, and Reinforcement.
Use multiple channels to uncover risks: Each communication channel (for example, email, chats, telephony) can be studied in isolation to detect potential risks. However, better insights are achieved by combining heterogeneous channels of formal (for example, email) and less formal (for example, chats) communications. Furthermore, integrating complementary information (for example, market news, company reports, SEC filings) can provide additional context for the compliance analyst (for example, about a specific initiative of a company).
Start simple and iterate: Azure Cognitive Search provides a comprehensive set of built-in AI enrichments based on various Cognitive Services. It might be tempting to add many of these capabilities right away. However, the number of entities or key phrases that can be extracted, if not controlled properly, can overwhelm the end user. Starting with a reduced set of skills or entities can help both users and developers understand which ones add the most value.
Responsible innovation: The development of AI solutions demands a high level of responsibility from all that are involved. Microsoft takes the responsible use of artificial intelligence very seriously and has developed a framework of core design principles:
- Fairness
- Reliability and safety
- Privacy and security
- Inclusiveness
- Transparency and accountability
The evaluation of employee communications requires special attention and raises ethical concerns. In some countries/regions, automated monitoring of employees is subject to strict legal restrictions. For all these reasons, make responsible innovation a cornerstone of your project plan. Microsoft offers several frameworks and tools for this purpose. For more information, refer to the Tip box at the end of this section.
Automate your development iterations: The Import data wizard makes it easy to get started, but for more complex solutions and productive use cases, we recommend that you create assets such as data sources, indexers, indexes, and skillsets in code. Automation dramatically speeds up development cycles and ensures a consistent deployment to production. The assets are specified in JSON format. You can copy JSON definitions from the portal, modify them as needed, and then provide them in the request body of calls to the Azure Cognitive Search REST APIs.
Select the appropriate NLP approach for risk analysis: Ways to identify risks in unstructured text range from basic keyword search and entity extraction to powerful modern NLP architectures. The best choice depends on the amount and quality of existing training data for the specific use case. If training data is limited, you can train an utterances-based model by using the conversational language understanding feature of Azure Cognitive Service for Language. Existing conversations can be reviewed to identify and label sentences that indicate relevant risk types. Sometimes tens of samples are enough to train a model with good results.
In cases where the risk signs are more subtle and span several sentences, training a state-of-the-art NLP model is likely the better choice. However, this approach typically requires significantly more training data. We recommend using, whenever possible, the real-world data when the solution is in production, to adjust for potential mispredictions and to continuously retrain the model to improve its performance over time.
Adapt the UI based on your specific requirements: A rich user interface can make available all the added value of Azure Cognitive Search and the AI enrichments. Although the Azure AI Search UI Template provides an easy and quick way to implement an initial web application, it probably has to be adapted to integrate additional features. It also needs to accommodate the types of communications that are processed, the types of AI enrichments that are used, and any additional business requirements. Continuous collaboration and iteration between front-end developers, business stakeholders, and end users will help enhance the value of the solution by optimizing the user experience of finding and reviewing relevant communications.
Optimize costs for translation services: By default, all documents flow through the AI enrichment pipeline. This means that English language documents are passed to the translation service even though no actual translation is needed. However, because the content is processed by the Translation API, charges nevertheless apply. In our solution, we use language detection in conjunction with conditional skills to avoid translation in these cases. If the detected language of the original document isn't English, the content is copied to a specific field for non-English content and then passed to the translation service. If the document is in English, this field is empty and no translation charges are generated. Finally, all content (originally English or translated) is merged into a common field for further processing. You can also enable caching to reuse existing enrichments.
Ensure availability and scalability of your production environment: After you move from proof of concept to production planning, you need to consider availability and scalability to ensure the reliability and performance of your search solution. Instances of the search service are called replicas and are used to load-balance query operations. Add replicas for high availability and increased query performance. Use partitions to manage the scalability of your solution. Partitions represent physical storage and have specific size and I/O characteristics. Refer to the documentation for more guidance about how to manage capacity and other service management considerations.
Tip
Refer to the following resources for more details about the best practices discussed in this section:
Conclusion
This guide provides comprehensive guidance for setting up a solution that uses AI to look for signs of fraud. The approach is applicable to other regulated industries like healthcare or government.
You can extend the architecture to include other data sources and AI capabilities, such as:
- Ingesting structured data, such as market data (for example, stock quotes) and transaction information.
- Attaching classification models that are designed to extract content from paper-based sources, by using capabilities such as the Azure Form Recognizer and the Azure Read API.
- Ingesting social networking information by using Azure Language Studio capabilities to categorize and filter relevant topics, or Azure Sentiment Analysis to capture opinion trends.
- Using Microsoft Graph to assemble and consolidate information from Microsoft 365, such as interpersonal interactions, companies that people work with, or information that they access. When you save this data in Azure Storage, you can easily search it.
The technology that underlies the solution, Azure Cognitive Search, is the best choice because it supports knowledge mining, catalog search and in-app search. It’s simple to deploy and to connect to multiple data sources and to provide built-in and extensible AI for content processing. It has capabilities like semantic search that are powered by deep learning, capabilities that can infer user intent and display and rank the most relevant results.
Contributors
This article is maintained by Microsoft. It was originally written by the following contributors.
Principal authors:
- Andreas Kopp | Senior Cloud Solution Architect
- João Pedro Martins | Senior Cloud Solution Architect Manager
- Carlos Alexandre Santos | Senior Cloud Solution Architect
To see non-public LinkedIn profiles, sign in to LinkedIn.