Hyperscale service tier
Applies to: ![]() Azure SQL Database
Azure SQL Database
Azure SQL Database is based on SQL Server Database Engine architecture that is adjusted for the cloud environment to ensure high availability even in cases of infrastructure failures. There are three service tier choices in the vCore purchasing model for Azure SQL Database:
- General Purpose
- Business Critical
- Hyperscale
The Hyperscale service tier is suitable for all workload types. Its cloud-native architecture provides independently scalable compute and storage to support the widest variety of traditional and modern applications. Compute and storage resources in Hyperscale substantially exceed the resources available in the General Purpose and Business Critical tiers.
Note
- For details on the General Purpose and Business Critical service tiers in the vCore-based purchasing model, see General Purpose and Business Critical service tiers. For a comparison of the vCore-based purchasing model with the DTU-based purchasing model, see Compare vCore and DTU-based purchasing models of Azure SQL Database.
- The Hyperscale service tier is currently only available for Azure SQL Database, and not for Azure SQL Managed Instance.
What are the Hyperscale capabilities
The Hyperscale service tier in Azure SQL Database provides the following additional capabilities:
- Rapid scale up - you can, in constant time, scale up your compute resources to accommodate heavy workloads when needed, and then scale the compute resources back down when not needed.
- Rapid scale out - you can provision one or more read-only replicas for offloading your read workload and for use as hot-standbys.
- Automatic scale-up, scale-down, and billing for compute based on usage with serverless compute.
- Optimized price/performance for a group of Hyperscale databases with varying resource demands with elastic pools (in preview).
- Autoscaling storage with support for up to 100 TB of database or elastic pool size.
- Higher overall performance due to higher transaction log throughput and faster transaction commit times regardless of data volumes.
- Fast database backups (based on file snapshots) regardless of size with no I/O impact on compute resources.
- Fast database restores or copies (based on file snapshots) in minutes rather than hours or days.
The Hyperscale service tier removes many of the practical limits traditionally seen in cloud databases. Where most other databases are limited by the resources available in a single node, databases in the Hyperscale service tier have no such limits. With its flexible storage architecture, storage grows as needed. In fact, Hyperscale databases aren't created with a defined max size. A Hyperscale database grows as needed - and you're billed only for the storage capacity allocated. For read-intensive workloads, the Hyperscale service tier provides rapid scale-out by provisioning additional replicas as needed for offloading read workloads.
Additionally, the time required to create database backups or to scale up or down is no longer tied to the volume of data in the database. Hyperscale databases are backed up virtually instantaneously. You can also scale a database in the tens of terabytes up or down within minutes in the provisioned compute tier or use serverless to scale compute automatically. This capability frees you from concerns about being boxed in by your initial configuration choices.
For more information about the compute sizes for the Hyperscale service tier, see Service tier characteristics.
Who should consider the Hyperscale service tier
The Hyperscale service tier is intended for all customers who require higher performance and availability, fast backup and restore, and/or fast storage and compute scalability. This includes customers who are moving to the cloud to modernize their applications and customers who are already using other service tiers in Azure SQL Database. The Hyperscale service tier supports a broad range of database workloads, from pure OLTP to pure analytics. It's optimized for OLTP and hybrid transaction and analytical processing (HTAP) workloads.
Note
Elastic pools for Hyperscale are currently in preview.
Hyperscale pricing model
Note
Simplified pricing for Azure SQL Database Hyperscale has arrived! Review the new pricing tier for Azure SQL Database Hyperscale announcement, and for pricing change details, see Azure SQL Database Hyperscale – lower, simplified pricing!.
Hyperscale service tier is only available in vCore model. To align with the new architecture, the pricing model is slightly different from General Purpose or Business Critical service tiers:
Provisioned compute:
The Hyperscale compute unit price is per replica. Users might adjust the total number of high-availability secondary replicas from 0 to 4, depending on availability and scalability requirements, and create up to 30 named replicas to support various read scale-out workloads.
Serverless compute:
Serverless compute billing is based on usage. For more information, see Serverless compute tier for Azure SQL Database.
Storage:
You don't need to specify the max data size when configuring a Hyperscale database. In the Hyperscale tier, you're charged for storage for your database based on actual allocation. Storage is automatically allocated between 10 GB and 100 TB and grows in 10 GB increments as needed.
For more information about Hyperscale pricing, see Azure SQL Database Pricing.
Compare resource limits
The vCore-based service tiers are differentiated based on database availability, storage type, performance, and maximum storage size. These differences are described in the following table:
| ㅤ | General Purpose | Business Critical | Hyperscale |
|---|---|---|---|
| Best for | Offers budget-oriented balanced compute and storage options. | OLTP applications with high transaction rate and low I/O latency. Offers high resilience to failures and fast failovers using multiple hot standby replicas. | The widest variety of workloads. Autoscaling storage size up to 100 TB, fast vertical and horizontal compute scaling, fast database restore. |
| Compute size | 2 to 128 vCores | 2 to 128 vCores | 2 to 128 vCores 1 |
| Storage type | Premium remote storage (per instance) | Super-fast local SSD storage (per instance) | Decoupled storage with local SSD cache (per compute replica) |
| Storage size 1 | 1 GB – 4 TB | 1 GB – 4 TB | 10 GB – 100 TB |
| IOPS | 320 IOPS per vCore with 16,000 maximum IOPS | 4,000 IOPS per vCore with 327,680 maximum IOPS | 327,680 IOPS with max local SSD Hyperscale is a multi-tiered architecture with caching at multiple levels. Effective IOPS depends on the workload. |
| Memory/vCore | 5.1 GB | 5.1 GB | 5.1 GB or 10.2 GB |
| Availability | One replica, no read scale-out, zone-redundant HA | Three replicas, one read scale-out, zone-redundant HA | Multiple replicas, up to four read scale-out, zone-redundant HA |
| Backups | A choice of locally redundant (LRS), zone-redundant (ZRS), or geo-redundant (GRS) storage 1-35 days (seven days by default) retention, with up to 10 years of long-term retention available |
A choice of locally redundant (LRS), zone-redundant (ZRS), or geo-redundant (GRS) storage 1-35 days (seven days by default) retention, with up to 10 years of long-term retention available |
A choice of locally redundant (LRS), zone-redundant (ZRS), or geo-redundant (GRS) storage 1-35 days (seven days by default) retention, with up to 10 years of long-term retention available |
| Pricing/billing | vCore, reserved storage, and backup storage are charged. IOPS aren't charged. |
vCore, reserved storage, and backup storage are charged. IOPS aren't charged. |
vCore for each replica, allocated data storage, and backup storage are charged. IOPS aren't charged. |
| Discount models2 | Reserved instances Azure Hybrid Benefit3 Enterprise and Pay-As-You-Go Dev/Test subscriptions |
Reserved instances Azure Hybrid Benefit3 Enterprise and Pay-As-You-Go Dev/Test subscriptions |
Reserved instances Azure Hybrid Benefit3 Enterprise and Pay-As-You-Go Dev/Test subscriptions |
1 Hyperscale elastic pools overview in Azure SQL Database are currently in preview.
2 Simplified pricing for SQL Database Hyperscale arrived in December 2023. Review the Hyperscale pricing blog for details.
3 As of December 2023, Azure Hybrid Benefit isn't available for new Hyperscale databases, or in dev/test subscriptions. Existing Hyperscale single databases with provisioned compute can continue to use Azure Hybrid Benefit to save on compute costs until December 2026. For more information, review the Hyperscale pricing blog.
Compute resources
| Hardware configuration | CPU | Memory |
|---|---|---|
| Standard-series (Gen5) | Provisioned compute - Intel® E5-2673 v4 (Broadwell) 2.3 GHz, Intel® SP-8160 (Skylake)1, Intel® 8272CL (Cascade Lake) 2.5 GHz1, Intel® Xeon® Platinum 8370C (Ice Lake)1, AMD EPYC 7763v (Milan) processors - Provision up to 80 vCores (hyper-threaded) Serverless compute - Intel® E5-2673 v4 (Broadwell) 2.3 GHz, Intel® SP-8160 (Skylake)1, Intel® 8272CL (Cascade Lake) 2.5 GHz1, Intel® Xeon® Platinum 8370C (Ice Lake)1, AMD EPYC 7763v (Milan) processors - Autoscale up to 80 vCores (hyper-threaded) - The memory-to-vCore ratio dynamically adapts to memory and CPU usage based on workload demand and can be as high as 24 GB per vCore. For example, at a given point in time, a workload might use and be billed for 240 GB memory and only 10 vCores. |
Provisioned compute - 5.1 GB per vCore - Provision up to 625 GB Serverless compute - Autoscale up to 24 GB per vCore - Autoscale up to 240 GB max |
| Premium-series | - Intel® Xeon® Platinum 8370C (Ice Lake), AMD EPYC 7763v (Milan) processors - Provision up to 128 vCores (hyper-threaded) |
- 5.1 GB per vCore |
| Premium-series memory optimized | - Intel® Xeon® Platinum 8370C (Ice Lake), AMD EPYC 7763v (Milan) processors - Provision up to 80 vCores (hyper-threaded) |
- 10.2 GB per vCore |
1 In the sys.dm_user_db_resource_governance dynamic management view, hardware generation for databases using Intel® SP-8160 (Skylake) processors appears as Gen6, hardware generation for databases using Intel® 8272CL (Cascade Lake) appears as Gen7, and hardware generation for databases using Intel® Xeon® Platinum 8370C (Ice Lake) or AMD® EPYC® 7763v (Milan) appear as Gen8. For a given compute size and hardware configuration, resource limits are the same regardless of CPU type. For more information, see resource limits for single databases and elastic pools.
Serverless is only supported on Standard-series (Gen5) hardware.
Distributed functions architecture
Hyperscale separates the query processing engine from the components that provide long-term storage and durability for the data. This architecture allows you to smoothly scale storage capacity as far as needed (initial target is 100 TB), and the ability to scale compute resources rapidly.
The following diagram illustrates the functional Hyperscale architecture:
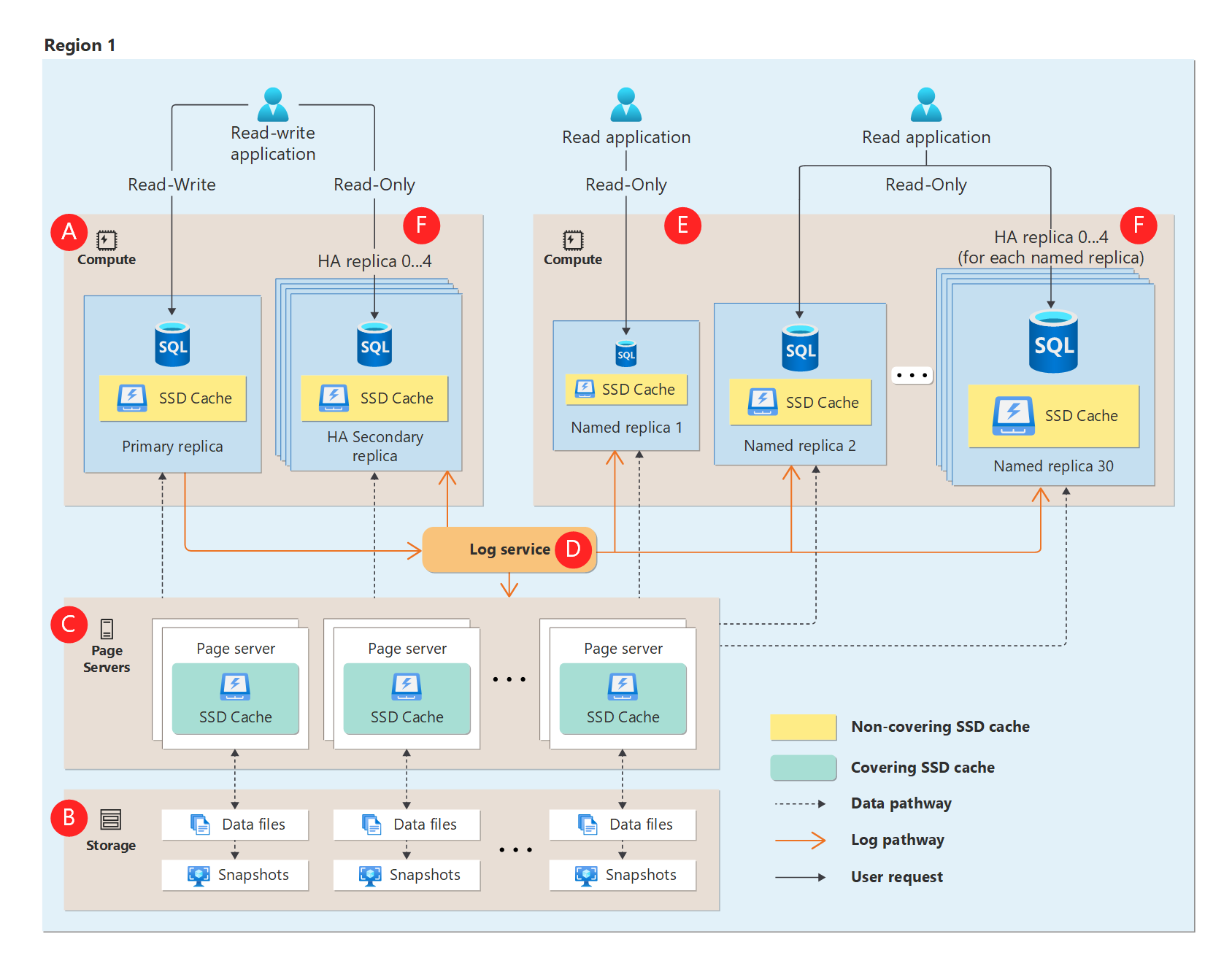
Learn more about the Hyperscale distributed functions architecture.
Scale and performance advantages
With the ability to rapidly spin up/down additional read-only compute nodes, the Hyperscale architecture allows significant read scale capabilities and can also free up the primary compute node for serving more write requests. Also, the compute nodes can be scaled up/down rapidly due to the shared-storage architecture of the Hyperscale architecture. Read-only compute nodes in Hyperscale are also available in the serverless compute tier, which automatically scales compute based on workload demand.
Create and manage Hyperscale databases
You can create and manage Hyperscale databases using the Azure portal, Transact-SQL, PowerShell, and the Azure CLI. For more information, see Quickstart: Create a Hyperscale database.
| Operation | Details | Learn more |
|---|---|---|
| Create a Hyperscale database | Hyperscale databases are available only using the vCore-based purchasing model. | Find examples to create a Hyperscale database in Quickstart: Create a Hyperscale database in Azure SQL Database. |
| Upgrade an existing database to Hyperscale | Migrating an existing database in Azure SQL Database to the Hyperscale tier is a size of data operation. | Learn how to migrate an existing database to Hyperscale. |
| Reverse migrate a Hyperscale database to the General Purpose service tier | If you previously migrated an existing Azure SQL Database to the Hyperscale service tier, you can reverse migrate the database to the General Purpose service tier within 45 days of the original migration to Hyperscale. If you wish to migrate the database to another service tier, such as Business Critical, first reverse migrate to the General Purpose service tier, then change the service tier. |
Learn how to reverse migrate from Hyperscale, including the limitations for reverse migration. |
Database high availability in Hyperscale
As in all other service tiers, Hyperscale guarantees data durability for committed transactions regardless of compute replica availability. The extent of downtime due to the primary replica becoming unavailable depends on the type of failover (planned vs. unplanned), whether zone redundancy is configured, and on the presence of at least one high-availability replica. In a planned failover (such as a maintenance event), the system either creates the new primary replica before initiating a failover, or uses an existing high-availability replica as the failover target. In an unplanned failover (such as a hardware failure on the primary replica), the system uses a high-availability replica as a failover target if one exists, or creates a new primary replica from the pool of available compute capacity. In the latter case, downtime duration is longer due to extra steps required to create the new primary replica.
You can choose a maintenance window that allows you to make impactful maintenance events predictable and less disruptive for your workload.
For Hyperscale SLA, see SLA for Azure SQL Database.
Back up and restore
Back up and restore operations for Hyperscale databases are file-snapshot based. This enables these operations to be nearly instantaneous. Since Hyperscale architecture utilizes the storage layer for backup and restore, the processing burden and performance impact to compute replicas are reduced. Learn more in Hyperscale backups and storage redundancy.
Disaster recovery for Hyperscale databases
If you need to restore a Hyperscale database in Azure SQL Database to a region other than the one it's currently hosted in, as part of a disaster recovery operation or drill, relocation, or any other reason, the primary method is to do a geo-restore of the database. Geo-restore is only available when geo-redundant storage (RA-GRS) has been chosen for storage redundancy.
Learn more in restoring a Hyperscale database to a different region.
Known limitations
These are the current limitations of the Hyperscale service tier. We're actively working to remove as many of these limitations as possible.
| Issue | Description |
|---|---|
| Restore database from other service tiers | A non-Hyperscale database can't be restored as a Hyperscale database, and a Hyperscale database can't be restored as a non-Hyperscale database. For databases migrated to Hyperscale from other Azure SQL Database service tiers, pre-migration backups are kept for the duration of backup retention period of the source database, including long-term retention policies. Restoring a pre-migration backup within the backup retention period of the database is supported via the command line. You can restore these backups to any non-Hyperscale service tier. |
| Elastic Pools | Elastic pools are now in preview. |
| Migration of databases with In-Memory OLTP objects | Hyperscale supports a subset of In-Memory OLTP objects, including memory-optimized table types, table variables, and natively compiled modules. However, when any In-Memory OLTP objects are present in the database being migrated, migration from Premium and Business Critical service tiers to Hyperscale isn't supported. To migrate such a database to Hyperscale, all In-Memory OLTP objects and their dependencies must be dropped. After the database is migrated, these objects can be recreated. Durable and non-durable memory-optimized tables aren't currently supported in Hyperscale and must be changed to disk tables. |
| Shrink Database | DBCC SHRINKDATABASE, DBCC SHRINKFILE, or setting AUTO_SHRINK to ON at the database level, aren't currently supported for Hyperscale databases. |
| Database integrity check | DBCC CHECKDB isn't currently supported for Hyperscale databases. DBCC CHECKTABLE ('TableName') WITH TABLOCK and DBCC CHECKFILEGROUP WITH TABLOCK might be used as a workaround. See Data Integrity in Azure SQL Database for details on data integrity management in Azure SQL Database. |
| Elastic Jobs | Using a Hyperscale database as the Job database isn't supported. However, elastic jobs can target Hyperscale databases in the same way as any other database in Azure SQL Database. |
| Data Sync | Using a Hyperscale database as a Hub or Sync Metadata database isn't supported. However, a Hyperscale database can be a member database in a Data Sync topology. |
| Hyperscale service tier premium-series hardware | Premium-series and memory-optimized premium-series hardware doesn't currently support the serverless compute tier. |
| Regional availability | Hyperscale service tier premium-series and premium-series memory-optimized hardware is available in limited Azure regions. For a list, see Hyperscale premium-series availability. |
Related content
- Frequently asked questions about Hyperscale
- Compare vCore and DTU-based purchasing models of Azure SQL Database
- Resource management in Azure SQL Database
- Resource limits for single databases using the vCore purchasing model
- Features comparison: Azure SQL Database and Azure SQL Managed Instance
- Hyperscale distributed functions architecture
- How to manage a Hyperscale database
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for