Automatically identify the spoken language with language identification model
Important
Due to the Azure Media Services retirement announcement, Azure AI Video Indexer announces Azure AI Video Indexer features adjustments. See Changes related to Azure Media Service (AMS) retirement to understand what this means for your Azure AI Video Indexer account. See the Preparing for AMS retirement: VI update and migration guide.
Azure AI Video Indexer supports automatic language identification (LID), which is the process of automatically identifying the spoken language from audio content. The media file is transcribed in the dominant identified language.
See the list of supported by Azure AI Video Indexer languages in supported languages.
Make sure to review the Guidelines and limitations section.
Choosing auto language identification on indexing
When indexing or reindexing a video using the API, choose the auto detect option in the sourceLanguage parameter.
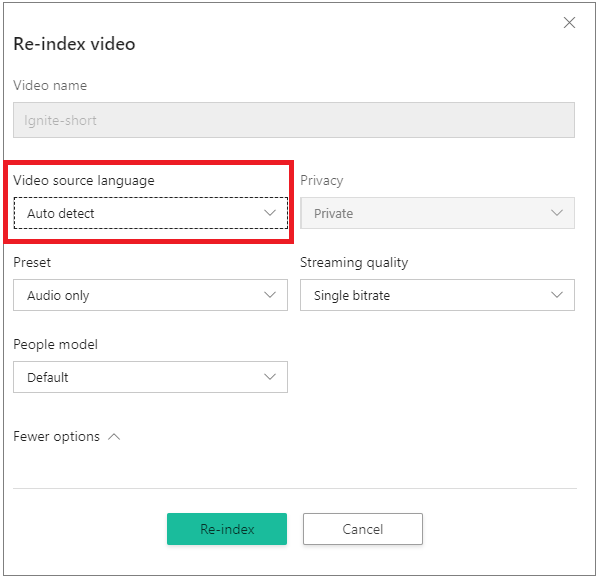
When using portal, go to your Account videos on the Azure AI Video Indexer home page and hover over the name of the video that you want to reindex. On the right-bottom corner, select the Re-index button. In the Re-index video dialog, choose Auto detect from the Video source language drop-down box.
Model output
Azure AI Video Indexer transcribes the video according to the most likely language if the confidence for that language is > 0.6. If the language can't be identified with confidence, it assumes the spoken language is English.
Model dominant language is available in the insights JSON as the sourceLanguage attribute (under root/videos/insights). A corresponding confidence score is also available under the sourceLanguageConfidence attribute.
"insights": {
"version": "1.0.0.0",
"duration": "0:05:30.902",
"sourceLanguage": "fr-FR",
"language": "fr-FR",
"transcript": [...],
. . .
"sourceLanguageConfidence": 0.8563
}
Guidelines and limitations
Automatic language identification (LID) supports the following languages:
See the list of supported by Azure AI Video Indexer languages in supported languages.
- If the audio contains languages other than the supported list, the result is unexpected.
- If Azure AI Video Indexer can't identify the language with a high enough confidence (greater than 0.6), the fallback language is English.
- Currently, there isn't support for files with mixed language audio. If the audio contains mixed languages, the result is unexpected.
- Low-quality audio may affect the model results.
- The model requires at least one minute of speech in the audio.
- The model is designed to recognize a spontaneous conversational speech (not voice commands, singing, and so on).
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for