How to use the online transcription editor
The online transcription editor allows you to create or edit audio + human-labeled transcriptions for custom speech. The main use cases of the editor are as follows:
- You only have audio data, but want to build accurate audio + human-labeled datasets from scratch to use in model training.
- You already have audio + human-labeled datasets, but there are errors or defects in the transcription. The editor allows you to quickly modify the transcriptions to get best training accuracy.
The only requirement to use the transcription editor is to have audio data uploaded, with or without corresponding transcriptions.
You can find the Editor tab next to the Training and testing dataset tab on the main Speech datasets page.
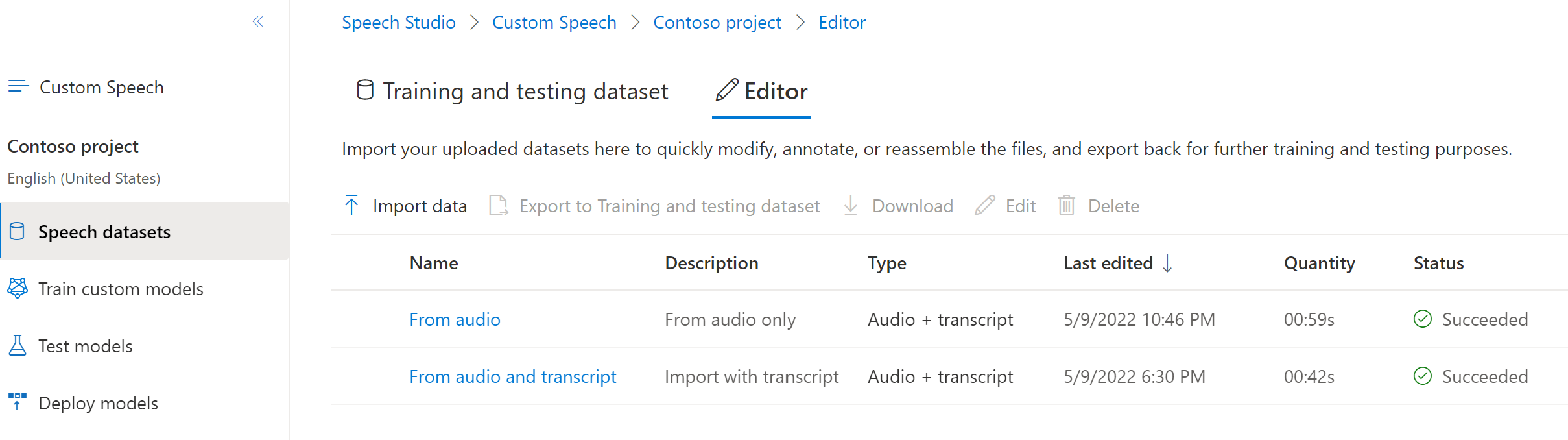
Datasets in the Training and testing dataset tab can't be updated. You can import a copy of a training or testing dataset to the Editor tab, add or edit human-labeled transcriptions to match the audio, and then export the edited dataset to the Training and testing dataset tab. Also note that you can't use a dataset that's in the Editor to train or test a model.
Import datasets to the Editor
To import a dataset to the Editor, follow these steps:
- Sign in to the Speech Studio.
- Select Custom speech > Your project name > Speech datasets > Editor.
- Select Import data
- Select datasets. You can select audio data only, audio + human-labeled data, or both. For audio-only data, you can use the default models to automatically generate machine transcription after importing to the editor.
- Enter a name and description for the new dataset, and then select Next.
- Review your settings, and then select Import and close to kick off the import process. After data is successfully imported, you can select datasets and start editing.
Note
You can also select a dataset from the main Speech datasets page and export them to the Editor. Select a dataset and then select Export to Editor.
Edit transcription to match audio
Once a dataset is imported to the Editor, you can start editing the dataset. You can add or edit human-labeled transcriptions to match the audio as you hear it. You don't edit any audio data.
To edit a dataset's transcription in the Editor, follow these steps:
- Sign in to the Speech Studio.
- Select Custom speech > Your project name > Speech datasets > Editor.
- Select the link to a dataset by name.
- From the Audio + text files table, select the link to an audio file by name.
- After you make edits, select Save.
If there are multiple files in the dataset, you can select Previous and Next to move from file to file. Edit and save changes to each file as you go.
The detail page lists all the segments in each audio file, and you can select the desired utterance. For each utterance, you can play and compare the audio with the corresponding transcription. Edit the transcriptions if you find any insertion, deletion, or substitution errors. For more information about word error types, see Test model quantitatively.
Export datasets from the Editor
Datasets in the Editor can be exported to the Training and testing dataset tab, where they can be used to train or test a model.
To export datasets from the Editor, follow these steps:
- Sign in to the Speech Studio.
- Select Custom speech > Your project name > Speech datasets > Editor.
- Select the link to a dataset by name.
- Select one or more rows from the Audio + text files table.
- Select Export to export all of the selected files as one new dataset.
The files are exported as a new dataset, and don't affect or replace other training or testing datasets.
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for