To train a model, start a training job. Only successfully completed jobs create a model. Training jobs expire after seven days, after this time you will no longer be able to retrieve the job details. If your training job completed successfully and a model was created, it won't be affected by the job expiring. You can only have one training job running at a time, and you can't start other jobs in the same project.
The training times can be anywhere from a few seconds when dealing with simple projects, up to a couple of hours when you reach the maximum limit of utterances.
Model evaluation is triggered automatically after training is completed successfully. The evaluation process starts by using the trained model to run predictions on the utterances in the testing set, and compares the predicted results with the provided labels (which establishes a baseline of truth). The results are returned so you can review the model’s performance.
Prerequisites
A successfully created project with a configured Azure blob storage account
Before you start the training process, labeled utterances in your project are divided into a training set and a testing set. Each one of them serves a different function.
The training set is used in training the model, this is the set from which the model learns the labeled utterances.
The testing set is a blind set that isn't introduced to the model during training but only during evaluation.
After the model is trained successfully, the model can be used to make predictions from the utterances in the testing set. These predictions are used to calculate evaluation metrics.
It is recommended to make sure that all your intents are adequately represented in both the training and testing set.
Orchestration workflow supports two methods for data splitting:
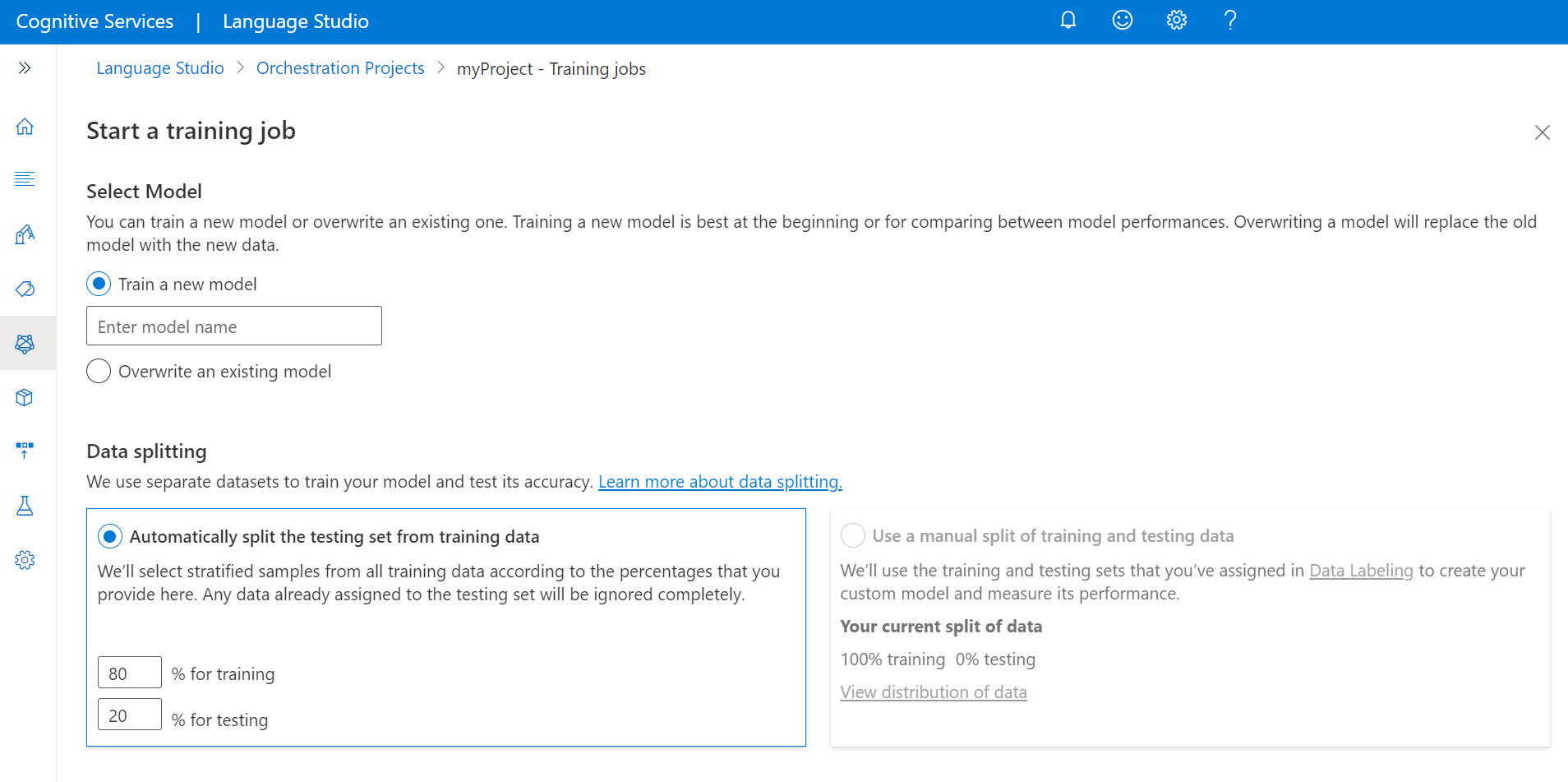
Automatically splitting the testing set from training data: The system will split your tagged data between the training and testing sets, according to the percentages you choose. The recommended percentage split is 80% for training and 20% for testing.
Note
If you choose the Automatically splitting the testing set from training data option, only the data assigned to training set will be split according to the percentages provided.
Use a manual split of training and testing data: This method enables users to define which utterances should belong to which set. This step is only enabled if you have added utterances to your testing set during labeling.
Note
You can only add utterances in the training dataset for non-connected intents only.
To start training your model from within the Language Studio:
Select Training jobs from the left side menu.
Select Start a training job from the top menu.
Select Train a new model and type in the model name in the text box. You can also overwrite an existing model by selecting this option and choosing the model you want to overwrite from the dropdown menu. Overwriting a trained model is irreversible, but it won't affect your deployed models until you deploy the new model.
Automatically splitting the testing set from training data: Your tagged utterances will be randomly split between the training and testing sets, according to the percentages you choose. The default percentage split is 80% for training and 20% for testing. To change these values, choose which set you want to change and type in the new value.
Note
If you choose the Automatically splitting the testing set from training data option, only the utterances in your training set will be split according to the percentages provided.
Use a manual split of training and testing data: Assign each utterance to either the training or testing set during the tagging step of the project.
Note
Use a manual split of training and testing data option will only be enabled if you add utterances to the testing set in the tag data page. Otherwise, it will be disabled.
Select the Train button.
Note
Only successfully completed training jobs will generate models.
Training can take some time between a couple of minutes and couple of hours based on the size of your tagged data.
You can only have one training job running at a time. You cannot start other training job wihtin the same project until the running job is completed.
Create a POST request using the following URL, headers, and JSON body to submit a training job.
Request URL
Use the following URL when creating your API request. Replace the placeholder values below with your own values.
Training mode. Only one mode for training is available in orchestration, which is standard.
standard
trainingConfigVersion
{CONFIG-VERSION}
The training configuration model version. By default, the latest model version is used.
2022-05-01
kind
percentage
Split methods. Possible values are percentage or manual. See how to train a model for more information.
percentage
trainingSplitPercentage
80
Percentage of your tagged data to be included in the training set. Recommended value is 80.
80
testingSplitPercentage
20
Percentage of your tagged data to be included in the testing set. Recommended value is 20.
20
Note
The trainingSplitPercentage and testingSplitPercentage are only required if Kind is set to percentage and the sum of both percentages should be equal to 100.
Once you send your API request, you will receive a 202 response indicating success. In the response headers, extract the operation-location value. It will be formatted like this:
Select the training job ID from the list, a side pane will appear where you can check the Training progress, Job status, and other details for this job.
Training could take sometime depending on the size of your training data and complexity of your schema. You can use the following request to keep polling the status of the training job until it is successfully completed.
Use the following GET request to get the status of your model's training progress. Replace the placeholder values below with your own values.
To cancel a training job from within Language Studio, go to the Train model page. Select the training job you want to cancel, and select Cancel from the top menu.
Create a POST request using the following URL, headers, and JSON body to cancel a training job.
Request URL
Use the following URL when creating your API request. Replace the placeholder values below with your own values.
Use the following header to authenticate your request.
Key
Value
Ocp-Apim-Subscription-Key
The key to your resource. Used for authenticating your API requests.
Once you send your API request, you will receive a 202 response indicating success, which means your training job has been canceled. A successful call results with an Operation-Location header used to check the status of the job.
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.