How to use Text Analytics for health
Important
Text Analytics for health is a capability provided “AS IS” and “WITH ALL FAULTS.” Text Analytics for health is not intended or made available for use as a medical device, clinical support, diagnostic tool, or other technology intended to be used in the diagnosis, cure, mitigation, treatment, or prevention of disease or other conditions, and no license or right is granted by Microsoft to use this capability for such purposes. This capability is not designed or intended to be implemented or deployed as a substitute for professional medical advice or healthcare opinion, diagnosis, treatment, or the clinical judgment of a healthcare professional, and should not be used as such. The customer is solely responsible for any use of Text Analytics for health. The customer must separately license any and all source vocabularies it intends to use under the terms set for that UMLS Metathesaurus License Agreement Appendix or any future equivalent link. The customer is responsible for ensuring compliance with those license terms, including any geographic or other applicable restrictions.
Text Analytics for health now allows extraction of Social Determinants of Health (SDOH) and ethnicity mentions in text. This capability may not cover all potential SDOH and does not derive inferences based on SDOH or ethnicity (for example, substance use information is surfaced, but substance abuse is not inferred). All decisions leveraging outputs of the Text Analytics for health that impact individuals or resource allocation (including, but not limited to, those related to billing, human resources, or treatment managing care) should be made with human oversight and not be based solely on the findings of the model. The purpose of the SDOH and ethnicity extraction capability is to help providers improve health outcomes and it should not be used to stigmatize or draw negative inferences about the users or consumers of SDOH data, or patient populations beyond the stated purpose of helping providers improving health outcomes.
Text Analytics for health can be used to extract and label relevant medical information from unstructured texts such as doctors' notes, discharge summaries, clinical documents, and electronic health records. The service performs named entity recognition, relation extraction, entity linking, and assertion detection to uncover insights from the input text. For information on the returned confidence scores, see the transparency note.
Tip
If you want to test out the feature without writing any code, use the Language Studio.
There are two ways to call the service:
- A Docker container (synchronous)
- Using the web-based API and client libraries (asynchronous)
Development options
To use Text Analytics for health, you submit raw unstructured text for analysis and handle the API output in your application. Analysis is performed as-is, with no additional customization to the model used on your data. There are two ways to use Text Analytics for health:
| Development option | Description |
|---|---|
| Language studio | Language Studio is a web-based platform that lets you try entity linking with text examples without an Azure account, and your own data when you sign up. For more information, see the Language Studio website or language studio quickstart. |
| REST API or Client library (Azure SDK) | Integrate Text Analytics for health into your applications using the REST API, or the client library available in a variety of languages. For more information, see the Text Analytics for health quickstart. |
| Docker container | Use the available Docker container to deploy this feature on-premises. These docker containers enable you to bring the service closer to your data for compliance, security, or other operational reasons. |
Input languages
The Text Analytics for health supports English in addition to multiple languages that are currently in preview. You can use the hosted API or deploy the API in a container, as detailed under Text Analytics for health languages support.
Submitting data
To send an API request, you will need your Language resource endpoint and key.
Note
You can find the key and endpoint for your Language resource on the Azure portal. They will be located on the resource's Key and endpoint page, under resource management.
Analysis is performed upon receipt of the request. If you send a request using the REST API or client library, the results will be returned asynchronously. If you're using the Docker container, they will be returned synchronously.
When using this feature asynchronously, the API results are available for 24 hours from the time the request was ingested, and is indicated in the response. After this time period, the results are purged and are no longer available for retrieval.
Submitting a Fast Healthcare Interoperability Resources (FHIR) request
Fast Healthcare Interoperability Resources (FHIR) is the health industry communication standard developed by the Health Level Seven International (HL7) organization. The standard defines the data formats (resources) and API structure for exchanging electronic healthcare data. To receive your result using the FHIR structure, you must send the FHIR version in the API request body.
| Parameter Name | Type | Value |
|---|---|---|
| fhirVersion | string | 4.0.1 |
Getting results from the feature
Depending on your API request, and the data you submit to the Text Analytics for health, you will get:
Named entity recognition is used to perform a semantic extraction of words and phrases mentioned from unstructured text that are associated with any of the supported entity types, such as diagnosis, medication name, symptom/sign, or age.

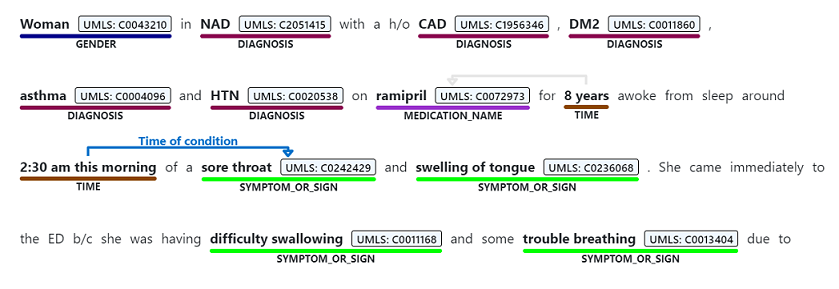

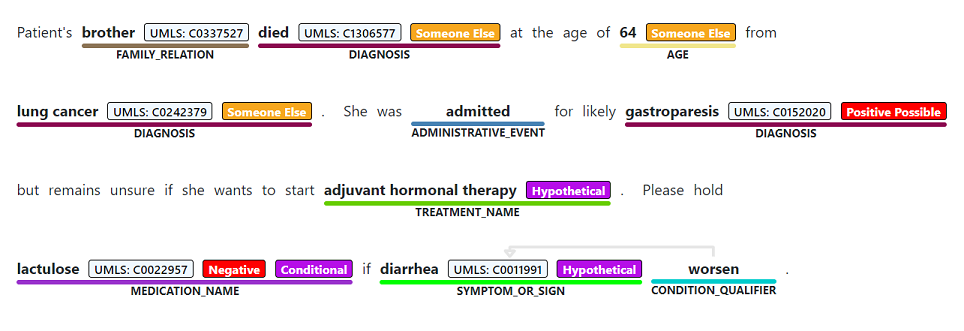
Service and data limits
For information on the size and number of requests you can send per minute and second, see the service limits article.
See also
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for